





PostgreSQL开发技术基础:过程与函数
扩展SQL
PostgreSQL是可扩展的。PostgreSQL和标准关系型数据库系统的一个关键不同是PostgreSQL在其目录中存储更多信息:不只是有关表和列的信息,还有关于数据类型、函数、访问方法等等的信息。这些表可以被用户修改,并且因为PostgreSQL的操作是基于这些表的,所以PostgreSQL可以被用户扩展。
PostgreSQL服务器能够通过动态库(载入)把用户编写的代码结合到它自身中。
类型系统
基础类型
容器类型
域
伪类型 (Pseudo-Types)
有一些用于特殊目的“伪类型”。伪类型不能作为表列或者容器类型的组件出现,但是它们能被用于声明函数的参数和结果类型。这在类型系统中提供了一种机制来标识函数的特殊分类。
any
anyelement
anyarray
anyrange
cstring
internal
fdw_handler
record
trigger
event_trigger
pg_ddl_command
void
unknown
多态类型
在伪类型当中,有一些比较重要的有用的类型属于多态类型。允许单个函数定义对许多不同的数据类型进行操作,具体数据类型由特定调用中实际传递给它的数据类型确定。主要是any打头的那些伪类型。
用户定义的函数
1) 查询语言函数(用SQL编写的函数)
2) 过程语言函数(PL/pgSQL或PL/Tcl等编写的函数),过程语言并不内建在PostgreSQL服务器中,它们通过可装载模块提供。
3) 内部函数
内部函数由 C 编写并且已经被静态链接到PostgreSQL 服务器中。该函数定义的“主体”指定该函数的 C 语言名称, 它必须和声明 SQL 函数所用的名称一样(为了向后兼容性的原因,也接受空 主体,那时会认为 C 语言函数名与 SQL 函数名相同)。
通常,所有存在于服务器中的内部函数都在数据库集簇的初始化(见 第 19.2 节)期间被声明,但是用户可以使用
CREATE FUNCTION
为一个内部函数创建 额外的别名。在CREATE FUNCTION
中用 语言名internal
来声明内部函数。例如,要为sqrt
函数创建一个别名:
1CREATE FUNCTION square_root(double precision) RETURNS double precision
2 AS 'dsqrt'
3 LANGUAGE internal
4 STRICT;
大部分内部函数应该被声明为“STRICT”
C语言函数
以动态库的方式实现 ,参考:http://postgres.cn/docs/14/xfunc-c.html
用户定义的过程
1CREATE PROCEDURE insert_data(a integer, b integer)
2LANGUAGE SQL
3AS $$
4INSERT INTO t1 VALUES (a);
5INSERT INTO t1 VALUES (b);
6$$;
7
8CALL insert_data(1, 2);
用CALL来调用,不能用select
过程和函数可以统称为例程(routine)。可以直接用drop来删除,不用考虑是哪一类型。不过没有CREATE routine命令.
1mydb=# drop routine square_root;
2DROP ROUTINE
3mydb=# drop routine insert_data;
4DROP ROUTINE
5ALTER ROUTINE insert_data(integer, integer) RENAME TO insert_d;
查询语言函数
(refer: http://postgres.cn/docs/14/xfunc-sql.html)
过程语言概览
PostgreSQL允许使用除了 SQL 和 C 之外的其他语言编写用户定义的函数。这些其他的语言通常被称作过程语言(PL)。对于一个用过程语言编写的函数,数据库服务器没有关于如何解释该函数的源文本的内建知识。因此,这个任务被交给一个了解语言细节的特殊处理器。该处理器能够自己处理所有的解析、语法分析、执行工作,或者它可以作为一种PostgreSQL和编程语言既有实现之间的“粘合剂”。
PostgreSQL 允许用户自定义的函数,它可以用各种过程语言编写。数据库服务器是没 有任何内建的知识获知如何解析该函数的源文本的。实际上这些任务都传递给一个知 道如何处理这些细节的句柄(handler )处理。
PostgreSQL 当前支持多个标准的过程语言:
PL/pgSQL
PL/Tcl
PL/Perl
PL/Python
PL/Java
PL/Ruby
其它语言可以由用户自定义
1postgres=# select * from pg_language;
2 oid | lanname | lanowner | lanispl | lanpltrusted | lanplcallfoid | laninline | lanvalidator | lanacl
3-------+----------+----------+---------+--------------+---------------+-----------+--------------+--------
4 12 | internal | 10 | f | f | 0 | 0 | 2246 |
5 13 | c | 10 | f | f | 0 | 0 | 2247 |
6 14 | sql | 10 | f | t | 0 | 0 | 2248 |
7 14476 | plpgsql | 10 | t | t | 14473 | 14474 | 14475 |
8(4 rows)
安装过程 语言的过程 见: P126
https://download.postgresql.org/pub/repos/yum/14/redhat/rhel-8-x86_64/
1yum install postgresql14-plpython3
2yum install postgresql14-plpython3-14.4 //具体的14的子版本
3
4mydb=# \dx
5 List of installed extensions
6 Name | Version | Schema | Description
7------------+---------+------------+-------------------------------------------
8 plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
9 plpython3u | 1.0 | pg_catalog | PL/Python3U untrusted procedural language
10(2 rows)
1使用pl/Python的一个简单示例:
2create extension if not exists plpython3u;
3
4create function pymax (a integer, b integer)
5returns integer
6as $$
7 if a > b:
8 return a;
9 return b;
10$$ language plpython3u;
11
12select pymax(1,99);
13mydb2=# select pymax(1,99);
14 pymax
15-------
16 99
17(1 row)
6.0 Language SQL与PL/pgSQL
在后续介绍之前,有必要知道SQL和PL/pgSQL之间的一些区别
https://www.dovov.com/postgresqlsqlplpgsql.html
https://stackoverflow.com/questions/24755468/difference-between-language-sql-and-language-plpgsql-in-postgresql-functions
(language SQL与language plpgsql的区别)
PL PgSQL是基于SQL的特定于PostgreSQL的过程语言 。它有循环,variables,错误/exception处理等等。并不是所有的SQL都是有效的PL PgSQL,正如你发现的那样,例如,你不能在没有
INTO
或RETURN QUERY
情况下使用SELECT
。PL PgSQL也可以在DO
块中用于一次性程序。
sql
函数只能使用纯SQL,但通常效率更高,写起来更简单,因为您不需要BEGIN ... END;
块等.SQL函数可以内联,这对于PL PgSQL来说是不正确的。人们经常使用PL PgSQL,因为它们习惯于程序思考。在大多数情况下,当你认为你需要PL PgSQL时,你可能不需要。recursionCTE,横向查询等通常满足大多数需求。
6.1 PL/pgSQL
6.1.1 概览
PL/pgSQL是 PostgreSQL 数据库系统的一个可装载的过程语言 。
PL/pgSQL 有一些特性:
可用于创建函数和触发器过程
为 SQL 语言增加控制结构
可以执行复杂的计算 ,
继承所有用户定义类型,函数和操作符
可以定义为被服务器信任的语言 ,
容易使用
6.1.2 PL/pgSQL和执行计划
当函数第一次被调用的时候(在每个会话中),PL/pgSQL 调用句柄产生一个二进制 指令树
该指令树完全转换了 PL/pgSQL 语句结构, 但是在函数内使用到的独立的 SQL 表 达式和 SQL 命令并未立即转换
在每个函数中用到的表达式和 SQL 命令在函数里首次使用的时候,PL/pgSQL 解释 器创建一个准备好的执行规划
随后对该表达式或者命令的访问都将在数据库连接的整个生命周期内使用已准备 好的规划。
6.1.3 PL/pgSQL结构
PL/pgSQL是一种块结构(block-structured)的语言。函数定义的所有文本都必须是一个 块。一个块用下面的方法定义:
1[ <<Label>> ]
2[ DECLARE
3 declarations ] -- 声明部分
4BEGIN
5 statements
6END [ label ];
块中的每个声明和每条语句都是用一个分号终止的, 如果一个子块在另外一个块里, 那么 END 后面必须有个分号,如上所述;不过结束函数体的最后的 END 可以不要这 个分号。提示:BEGIN后边是不需要分号的
所有的关键字和标识符(identifiers)可以大小写混用。如果没有双引号,标识 符默认转换为小写。
在 PL/pgSQL中有两种注释
-- 单行注释
/* 多行注释 */
在块前面的位于声明部分的变量会在每次块载入的时候(不是每次函数被调 用的时候)被初始化为默认值。
一个示例如下:
1CREATE FUNCTION somefunc() RETURNS integer AS $$
2<< outerblock >>
3DECLARE
4 quantity integer := 30;
5BEGIN
6 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 30
7 quantity := 50;
8 --
9 -- 创建一个子块
10 --
11 DECLARE
12 quantity integer := 80;
13 BEGIN
14 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 80
15 RAISE NOTICE 'Outer quantity here is %', outerblock.quantity; -- Prints 50
16 END;
17 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 50
18 RETURN quantity;
19END;
20$$ LANGUAGE plpgsql;
6.1.4 声明
在一个块中使用的所有变量必须在该块的声明小节中声明(唯一的例外是在一个整数范围上迭代的FOR
循环变量会被自动声明为一个整数变量,并且相似地在一个游标结果上迭代的FOR
循环变量会被自动地声明为一个记录变量)。
PL/pgSQL变量可以是任意 SQL 数据类型,例如integer
、varchar
和char
。 如:
1user_id integer;
2quantity numeric(5);
3url varchar;
4myrow tablename%ROWTYPE;
5myfield tablename.columnname%TYPE;
6arow RECORD;
声明的语法如下:
1name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
如果给定DEFAULT
子句,它会指定进入该块时分 配给该变量的初始值。如果没有给出DEFAULT
子句, 则该变量被初始化为SQL空值。CONSTANT
选项阻止该变量在初始化之后被赋值,这样它的值在块的持续期内保持不变。
一个变量的默认值会在每次进入该块时被计算并且赋值给该变量(不是每次函数调用只计算一次)。因此,例如将now()
赋值给类型为timestamp
的一个变量将会导致该变量具有当前函数调用的时间,而不是该函数被预编译的时间。
1quantity integer DEFAULT 32;
2url varchar := 'http://mysite.com';
3user_id CONSTANT integer := 10;
声明函数参数
传递给函数的参数被命名为标识符$1
、$2
等等。可选地,能够为$*
n*
参数名声明别名来增加可读性。不管是别名还是数字标识符都能用来引用参数值。
有两种方式来创建一个别名。比较好的方式是在CREATE FUNCTION
命令中为参数给定一个名称。例如:
1CREATE FUNCTION sales_tax(subtotal real) RETURNS real AS $$
2BEGIN
3 RETURN subtotal * 0.06;
4END;
5$$ LANGUAGE plpgsql;
name ALIAS FOR
1CREATE FUNCTION sales_tax(real) RETURNS real AS $$
2DECLARE
3 subtotal ALIAS FOR $1;
4BEGIN
5 RETURN subtotal * 0.06;
6END;
7$$ LANGUAGE plpgsql;
当一个PL/pgSQL函数被声明为带有输出参数,输出参数可以用普通输入参数相同的方式被给定$*
n*
名称以及可选的别名。一个输出参数实际上是一个最初为 NULL 的变量,它应当在函数的执行期间被赋值。该参数的最终值就是要被返回的东西。例如,sales-tax 例子也可以用这种方式来做,也可以返回多值。
1CREATE FUNCTION sales_tax(subtotal real, OUT tax real) AS $$
2BEGIN
3 tax := subtotal * 0.06;
4END;
5$$ LANGUAGE plpgsql;
6
7select sales_tax(12345);
8
9CREATE FUNCTION sum_n_product(x int, y int, OUT sum int, OUT prod int) AS $$
10BEGIN
11 sum := x + y;
12 prod := x * y;
13END;
14$$ LANGUAGE plpgsql;
15-- 这实际上为该函数的结果创建了一个匿名记录类型。如果给定了一个RETURNS子句,它必须RETURNS record。
16mydb2=# select sum_n_product(1, 2);
17 sum_n_product
18---------------
19 (3,2)
20(1 row)
声明一个PL/pgSQL函数的另一种方式是用RETURNS TABLE
,例如:
1CREATE FUNCTION extended_sales(p_itemno int)
2RETURNS TABLE(quantity int, total numeric) AS $$
3BEGIN
4 RETURN QUERY SELECT s.quantity, s.quantity * s.price FROM sales AS s
5 WHERE s.itemno = p_itemno;
6END;
7$$ LANGUAGE plpgsql;
当PL/pgSQL函数的返回类型被声明为多态类型时,一个特殊的参数 $0
已创建。它的数据类型是函数的实际返回类型,从实际输入类型推导出来。 $0
被初始化为空并且不能被该函数修改,因此它能够被用来保持可能需要的返回值,不过这不是必须的。 $0
也可以被给定一个别名。例如,这个函数工作在任何具有一个+
操作符的数据类型上:
通过声明一个或多个输出参数为多态类型可以得到同样的效果。在这种情况下,不使用特殊的$0
参数,输出参数本身就用作相同的目的。例如:
1CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement)
2RETURNS anyelement AS $$
3DECLARE
4 result ALIAS FOR $0;
5BEGIN
6 result := v1 + v2 + v3;
7 RETURN result;
8END;
9$$ LANGUAGE plpgsql;
10----- ==>
11CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement,
12 OUT sum anyelement)
13AS $$
14BEGIN
15 sum := v1 + v2 + v3;
16END;
17$$ LANGUAGE plpgsql;
在实践中,使用anycompatible
类型系列声明多态函数可能更有用,以便将输入参数自动提升为公共类型。例如:
1CREATE FUNCTION add_three_values(v1 anycompatible, v2 anycompatible, v3 anycompatible)
2RETURNS anycompatible AS $$
3BEGIN
4 RETURN v1 + v2 + v3;
5END;
6$$ LANGUAGE plpgsql;
7SELECT add_three_values(1, 2, 4.7);
Alias
1newname ALIAS FOR oldname;
可以为任意变量声明一个别名,而不只是函数参数。其主要实际用途是为预先决定了名称的变量分配一个不同的名称,例如在一个触发器过程中的NEW
或OLD
。 例子:
1DECLARE
2 prior ALIAS FOR old;
3 updated ALIAS FOR new;
因为ALIAS
创造了两种不同的方式来命名相同的对象,如果对其使用不加限制就会导致混淆。最好只把它用来覆盖预先决定的名称。
复制类型 (Copying types)
1variable%TYPE
%TYPE
提供了一个变量或表列的数据类型。你可以用它来声明将保持数据库值的变量。例如,如果你在users
中有一个名为user_id
的列。要定义一个与users.user_id
具有相同数据类型的变量:user_id users.user_id%TYPE;
通过使用%TYPE
,你不需要知道你要引用的结构的实际数据类型,而且最重要地,如果被引用项的数据类型在未来被改变(例如你把user_id
的类型从integer
改为real
),你不需要改变你的函数定义。
%TYPE
在多态函数中特别有价值,因为内部变量所需的数据类型能在两次调用时改变。可以把%TYPE
应用在函数的参数或结果占位符上来创建合适的变量。
行类型(Row Type)
1name table_name%ROWTYPE;
2name composite_type_name;
一个组合类型的变量被称为一个行变量(或行类型变量)。这样一个变量可以保持一个SELECT
或FOR
查询结果的一整行,前提是查询的列集合匹配该变量被声明的类型。该行值的各个域可以使用通常的点号标记访问,例如rowvar.field
。
通过使用table_name%ROWTYPE
标记,一个行变量可以被声明为具有和一个现有表或视图的行相同的类型。它也可以通过给定一个组合类型名称来声明(因为每一个表都有一个相关联的具有相同名称的组合类型,所以在PostgreSQL中实际上写不写%ROWTYPE
都没有关系。但是带有%ROWTYPE
的形式可移植性更好)。
一个函数的参数可以是组合类型(完整的表行)。在这种情况下,相应的标识符n;使用这种风格的同一个例子看起来是:¨G12G当一个PL/pgSQL函数被声明为带有输出参数,输出参数可以用普通输入参数相同的方式被给定¨C123Cn¨C124C名称以及可选的别名。一个输出参数实际上是一个最初为NULL的变量,它应当在函数的执行期间被赋值。该参数的最终值就是要被返回的东西。例如,sales−tax例子也可以用这种方式来做,也可以返回多值。¨G13G声明一个PL/pgSQL函数的另一种方式是用¨C125C,例如:¨G14G当PL/pgSQL函数的返回类型被声明为多态类型时,一个特殊的参数¨C126C已创建。它的数据类型是函数的实际返回类型,从实际输入类型推导出来。¨C127C被初始化为空并且不能被该函数修改,因此它能够被用来保持可能需要的返回值,不过这不是必须的。¨C128C也可以被给定一个别名。例如,这个函数工作在任何具有一个¨C129C操作符的数据类型上:通过声明一个或多个输出参数为多态类型可以得到同样的效果。在这种情况下,不使用特殊的¨C130C参数,输出参数本身就用作相同的目的。例如:¨G15G在实践中,使用¨C131C类型系列声明多态函数可能更有用,以便将输入参数自动提升为公共类型。例如:¨G16G¨K173K¨G17G可以为任意变量声明一个别名,而不只是函数参数。其主要实际用途是为预先决定了名称的变量分配一个不同的名称,例如在一个触发器过程中的¨C132C或¨C133C。例子:¨G18G因为¨C134C创造了两种不同的方式来命名相同的对象,如果对其使用不加限制就会导致混淆。最好只把它用来覆盖预先决定的名称。¨K174K¨G19G¨C135C提供了一个变量或表列的数据类型。你可以用它来声明将保持数据库值的变量。例如,如果你在¨C136C中有一个名为¨C137C的列。要定义一个与¨C138C具有相同数据类型的变量:useridusers.userid通过使用¨C139C,你不需要知道你要引用的结构的实际数据类型,而且最重要地,如果被引用项的数据类型在未来被改变(例如你把¨C140C的类型从¨C141C改为¨C142C),你不需要改变你的函数定义。¨C143C在∗∗多态函数中特别有价值∗∗,因为内部变量所需的数据类型能在两次调用时改变。可以把¨C144C应用在函数的参数或结果占位符上来创建合适的变量。¨K175K¨G20G一个组合类型的变量被称为一个∗行∗变量(或∗行类型∗变量)。这样一个变量可以保持一个¨C145C或¨C146C查询结果的一整行,前提是查询的列集合匹配该变量被声明的类型。该行值的各个域可以使用通常的点号标记访问,例如¨C147C。通过使用∗¨C148C∗¨C149C标记,一个行变量可以被声明为具有和一个现有表或视图的行相同的类型。它也可以通过给定一个组合类型名称来声明(因为每一个表都有一个相关联的具有相同名称的组合类型,所以在PostgreSQL中实际上写不写¨C150C都没有关系。但是带有¨C151C的形式可移植性更好)。一个函数的参数可以是组合类型(完整的表行)。在这种情况下,相应的标识符n将是一个行变量,并且可以从中选择域,例如$1.user_id
。
1CREATE FUNCTION merge_fields(t_row table1) RETURNS text AS $$
2DECLARE
3 t2_row table2%ROWTYPE;
4BEGIN
5 SELECT * INTO t2_row FROM table2 WHERE ... ;
6 RETURN t_row.f1 || t2_row.f3 || t_row.f2 || t2_row.f4;
7END;
8$$ LANGUAGE plpgsql;
9
10SELECT merge_fields(t.*) FROM table1 t WHERE ... ;
记录类型
1name RECORD;
记录变量和行类型变量类似,但是它们没有预定义的结构。它们采用在一个SELECT
或FOR
命令期间为其赋值的行的真实行结构。注意RECORD
并非一个真正的数据类型,只是一个占位符。我们也应该认识到当一个PL/pgSQL函数被声明为返回类型record
,这与一个记录变量并不是完全相同的概念,即便这样一个函数可能会用一个记录变量来保持其结果。
PL/pgSQL变量的排序规则
当一个PL/pgSQL函数有一个或多个可排序数据类型的参数时,为每一次函数调用都会基于赋值给实参的排序规则来确定出一个排序规则,如果一个排序规则被成功地确定(即在参数之间隐式排序规则没有冲突),那么所有的可排序参数会被当做隐式具有那个排序规则。这将在函数中影响行为受到排序规则影响的操作。例如,考虑
1CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
2BEGIN
3 RETURN a < b;
4END;
5$$ LANGUAGE plpgsql;
6
7SELECT less_than(text_field_1, text_field_2) FROM table1;
8SELECT less_than(text_field_1, text_field_2 COLLATE "C") FROM table1;
less_than
的第一次使用将会采用text_field_1
和text_field_2
共同的排序规则进行比较,而第二次使用将采用C
排序规则。
此外,被确定的排序规则也被假定为任何可排序数据类型本地变量的排序规则。因此,当这个函数被写为以下形式时,它工作将不会有什么不同。
1CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
2DECLARE
3 local_a text := a;
4 local_b text := b;
5BEGIN
6 RETURN local_a < local_b;
7END;
8$$ LANGUAGE plpgsql;
通过在一个可排序数据类型的本地变量的声明中包括COLLATE
选项,可以为它指定一个不同的排序规则,例如
1DECLARE
2 local_a text COLLATE "en_US";
还有,如果一个函数想要强制在一个特定操作中使用一个特定排序规则,当然可以在该函数内部写一个显式的COLLATE
子句。例如:
1CREATE FUNCTION less_than_c(a text, b text) RETURNS boolean AS $$
2BEGIN
3 RETURN a < b COLLATE "C";
4END;
5$$ LANGUAGE plpgsql;
这会覆盖表达式中使用的表列、参数或本地变量相关的排序规则,就像在纯 SQL 命令中发生的一样。
PL/pgSQL 表达式
PL/pgSQL语句中用到的所有表达式会被服务器的主SQL执行器处理。例如,当你写一个这样的PL/pgSQL语句时
1IF expression THEN ...
PL/pgSQL将通过给主 SQL 引擎发送一个查询
1SELECT expression
来计算该表达式。在构造该SELECT
命令时,PL/pgSQL变量名的每一次出现会被参数所替换。这允许SELECT
的查询计划仅被准备一次并且被重用于之后的对于该变量不同值的计算。因此,在一个表达式第一次被使用时实际发生的本质上是一个PREPARE
命令。例如,如果我们已经声明了两个整数变量x
和y
,并且我们写了
1IF x < y THEN ...
在现象之后发生的等效于
1PREPARE statement_name(integer, integer) AS SELECT $1 < $2;
并且然后为每一次IF
语句的执行,这个预备语句都会被EXECUTE
,执行时使用变量的当前值作为参数值。通常这些细节对于一个PL/pgSQL用户并不重要,但是在尝试诊断一个问题时了解它们很有用。
PL/pgSQL基本语句
赋值
为一个PL/pgSQL变量赋一个值可以被写为:
1variable { := | = } expression;
正如以前所解释的,这样一个语句中的表达式被以一个 SQL SELECT
命令被发送到主数据库引擎的方式计算。 该表达式必须得到一个单一值(如果该变量是一个行或记录变量, 它可能是一个行值)。该目标变量可以是一个简单变量( 可以选择用一个块名限定)、一个行或记录变量的域或是一个简单 变量或域的数组元素。 等号(=
)可以被用来代替 PL/SQL-兼容的 :=
。
如果该表达式的结果数据类型不匹配变量的数据类型,该值将被强制转换。
1tax := subtotal * 0.06;
2my_record.user_id := 20;
执行一个没有结果的命令
对于任何不返回行的 SQL 命令(例如没有一个RETURNING
子句的INSERT
),你可以通过把该命令直接写在一个 PL/pgSQL 函数中执行它。 任何出现在该命令文本中的PL/pgSQL变量名被当作一个参数,并且接着该变量的当前值被提供为运行时该参数的值。
有时候计算一个表达式或SELECT
查询但抛弃其结果是有用的,例如调用一个有副作用但是没有有用的结果值的函数。在PL/pgSQL中要这样做,可使用PERFORM
语句:
1PERFORM query;
这会执行query
并且丢弃掉结果。以写一个SQL SELECT
命令相同的方式写该query
,并且将初始的关键词SELECT
替换为PERFORM
。对于WITH
查询,使用PERFORM
并且接着把该查询放在圆括号中(在这种情况中,该查询只能返回一行)。PL/pgSQL变量将被替换到该查询中,正像对不返回结果的命令所作的那样,并且计划被以相同的方式被缓存。
1PERFORM create_mv('cs_session_page_requests_mv', my_query);
执行一个有单一行结果的查询
一个产生单一行(可能有多个列)的 SQL 命令的结果可以被赋值给一个记录变量、行类型变量或标量变量列表。
1SELECT select_expressions INTO [STRICT] target FROM ...;
2INSERT ... RETURNING expressions INTO [STRICT] target;
3UPDATE ... RETURNING expressions INTO [STRICT] target;
4DELETE ... RETURNING expressions INTO [STRICT] target;
其中target
可以是一个记录变量、一个行变量或一个有逗号分隔的简单变量和记录/行域列表。
如果STRICT
没有在INTO
子句中被指定,那么target
将被设置为该查询返回的第一个行,或者在该查询不返回行时设置为空(注意除非使用了ORDER BY
,否则“第一行”的界定并不清楚)
1SELECT * INTO myrec FROM emp WHERE empname = myname;
2IF NOT FOUND THEN
3 RAISE EXCEPTION 'employee % not found', myname;
4END IF;
如果指定了STRICT
选项,该查询必须刚好返回一行或者将会报告一个运行时错误,该错误可能是NO_DATA_FOUND
(没有行)或TOO_MANY_ROWS
(多于一行)。成功执行一个带STRICT
的命令总是会将FOUND
置为真。
1BEGIN
2 SELECT * INTO STRICT myrec FROM emp WHERE empname = myname;
3 EXCEPTION
4 WHEN NO_DATA_FOUND THEN
5 RAISE EXCEPTION 'employee % not found', myname;
6 WHEN TOO_MANY_ROWS THEN
7 RAISE EXCEPTION 'employee % not unique', myname;
8END;
1CREATE FUNCTION get_userid(username text) RETURNS int
2AS $$
3#print_strict_params on
4DECLARE
5userid int;
6BEGIN
7 SELECT users.userid INTO STRICT userid
8 FROM users WHERE users.username = get_userid.username;
9 RETURN userid;
10END;
11$$ LANGUAGE plpgsql;
STRICT
选项完全匹配 Oracle PL/SQL 的SELECT INTO
和相关语句的行为。
PL/pgSQL 执行动态命令
很多时候你将想要在PL/pgSQL函数中产生动态命令,也就是每次执行中会涉及到不同表或不同数据类型的命令。PL/pgSQL通常对于命令所做的缓存计划尝试在这种情境下无法工作。要处理这一类问题,需要提供EXECUTE
语句:
1EXECUTE command-string [ INTO [STRICT] target ] [ USING expression [, ... ] ];
在计算得到的命令字符串中,不会做PL/pgSQL变量的替换。任何所需的变量值必须在命令字符串被构造时被插入其中,或者你可以使用下面描述的参数。 命令字符串可以使用参数值,它们在命令中用$1
、$2
等引用。这些符号引用在USING
子句中提供的值。这种方法常常更适合于把数据值作为文本插入到命令字符串中:它避免了将该值转换为文本以及转换回来的运行时负荷,并且它更不容易被 SQL 注入攻击,因为不需要引用或转义。一个例子是:
1EXECUTE 'SELECT count(*) FROM mytable WHERE inserted_by = $1 AND inserted <= $2'
2 INTO c
3 USING checked_user, checked_date;
需要注意的是,参数符号只能用于数据值 — 如果想要使用动态决定的表名或列名,你必须将它们以文本形式插入到命令字符串中。例如,如果前面的那个查询需要在一个动态选择的表上执行,你可以这么做:
1EXECUTE 'SELECT count(*) FROM '
2 || quote_ident(tabname)
3 || ' WHERE inserted_by = $1 AND inserted <= $2'
4 INTO c
5 USING checked_user, checked_date;
一种更干净的方法是为表名或者列名使用format()
的 %I
规范(被新行分隔的字符串会被串接起来):
1EXECUTE format('SELECT count(*) FROM %I '
2 'WHERE inserted_by = $1 AND inserted <= $2', tabname)
3 INTO c
4 USING checked_user, checked_date;
在动态查询中引用值, 如:动态值需要被小心地处理,因为它们可能包含引号字符。一个使用 format()
的例子(这假设你用美元符号引用了函数 体,因此引号不需要被双写)
1EXECUTE format('UPDATE tbl SET %I = $1 '
2 'WHERE key = $2', colname) USING newvalue, keyvalue;
3EXECUTE 'UPDATE tbl SET '
4 || quote_ident(colname)
5 || ' = '
6 || quote_literal(newvalue)
7 || ' WHERE key = '
8 || quote_literal(keyvalue);
为了安全,在进行一个动态查询中的插入之前,包含列或表标识符的表达式应该通过quote_ident
被传递。如果表达式包含在被构造出的命令中应该是字符串的值时,它应该通过quote_literal
被传递。这些函数采取适当的步骤来分别返回被封闭在双引号或单引号中的文本,其中任何嵌入的特殊字符都会被正确地转义。
动态 SQL 语句也可以使用format
函数来安全地构造。例如:
1EXECUTE format('UPDATE tbl SET %I = %L '
2 'WHERE key = %L', colname, newvalue, keyvalue);
%I
等效于quote_ident
并且 %L
等效于quote_nullable
。 format
函数可以和 USING
子句一起使用:
1EXECUTE format('UPDATE tbl SET %I = $1 WHERE key = $2', colname)
2 USING newvalue, keyvalue;
这种形式更好,因为变量被以它们天然的数据类型格式处理,而不是无 条件地把它们转换成文本并且通过%L
引用它们。这也效率 更高。
获得结果状态
有好几种方法可以判断一条命令的效果。第一种方法是使用GET DIAGNOSTICS
命令,其形式如下:
1GET [ CURRENT ] DIAGNOSTICS variable { = | := } item [ , ... ];
这条命令允许检索系统状态指示符。每个item
是一个关键字, 它标识一个要被赋予给指定变量
的状态值(变量应具有正确的数据类型来接收状态值), 如:
1GET DIAGNOSTICS integer_var = ROW_COUNT;
可用的诊断项
| 名称 | 类型 | 描述 |
|---|---|---|
ROW_COUNT | bigint | 最近的SQL命令处理的行数 |
PG_CONTEXT | text | 描述当前调用栈的文本行 |
第二种判断命令效果的方法是检查一个名为FOUND
的boolean
类型的特殊变量。在每一次PL/pgSQL函数调用时,FOUND
开始都为假。它的值会被下面的每一种类型的语句设置:
如果一个
SELECT INTO
语句赋值了一行,它将把FOUND
设置为真,如果没有返回行则将之设置为假。如果一个
PERFORM
语句生成(并且抛弃)一行或多行,它将把FOUND
设置为真,如果没有产生行则将之设置为假。如果
UPDATE
、INSERT
以及DELETE
语句影响了至少一行,它们会把FOUND
设置为真,如果没有影响行则将之设置为假。如果一个
FETCH
语句返回了一行,它将把FOUND
设置为真,如果没有返回行则将之设置为假。如果一个
MOVE
语句成功地重定位了游标,它将会把FOUND
设置为真,否则设置为假。如果一个
FOR
或FOREACH
语句迭代了一次或多次,它将会把FOUND
设置为真,否则设置为假。当循环退出时,FOUND
用这种方式设置;在循环执行中,尽管FOUND
可能被循环体中的其他语句的执行所改变,但它不会被循环语句修改。如果查询返回至少一行,
RETURN QUERY
和RETURN QUERY EXECUTE
语句会把FOUND
设为真, 如果没有返回行则设置为假。
其他的PL/pgSQL语句不会改变FOUND
的状态。尤其需要注意的一点是:EXECUTE
会修改GET DIAGNOSTICS
的输出,但不会修改FOUND
的输出。
FOUND
是每个PL/pgSQL函数的局部变量;任何对它的修改只影响当前的函数。
DO NOTHING
有时一个什么也不做的占位语句也很有用。例如,它能够指示 if/then/else 链中故意留出的空分支。可以使用NULL
语句达到这个目的:
1NULL;
例如,下面的两段代码是等价的:
1BEGIN
2 y := x / 0;
3EXCEPTION
4 WHEN division_by_zero THEN
5 NULL; -- 忽略错误
6END;
7
8BEGIN
9 y := x / 0;
10EXCEPTION
11 WHEN division_by_zero THEN -- 忽略错误
12END;
究竟使用哪一种取决于各人的喜好。 注意:在 Oracle 的 PL/SQL 中,不允许出现空语句列表,并且因此在这种情况下必须使用NULL
语句。而PL/pgSQL允许你什么也不写。
6.1.5 PL/pgSQL控制结构
从函数返回
从函数中返回数据:RETURN
和RETURN NEXT
。
Return
语法为: Return Expression。带有一个表达式的RETURN
用于终止函数并把expression
的值返回给调用者。这种形式被用于不返回集合的PL/pgSQL函数。如果一个函数返回一个标量类型,表达式的结果将被自动转换成函数的返回类型。但是要返回一个复合(行)值,你必须写一个正好产生所需列集合的表达式。这可能需要使用显式造型。如果你声明函数返回void
,一个RETURN
语句可以被用来提前退出函数;但是不要在RETURN
后面写一个表达式。 e.g.
1-- 返回一个标量类型的函数
2RETURN 1 + 2;
3RETURN scalar_var;
4
5-- 返回一个组合类型的函数
6RETURN composite_type_var;
7RETURN (1, 2, 'three'::text); -- 必须把列造型成正确的类型
Return NEXT和Return QUERY
1RETURN NEXT expression;
2RETURN QUERY query;
3RETURN QUERY EXECUTE command-string [ USING expression [, ... ] ];
当一个PL/pgSQL函数被声明为返回SETOF *
sometype*
,那么遵循的过程则略有不同。在这种情况下,要返回的个体项被用一个RETURN NEXT
或者RETURN QUERY
命令的序列指定,并且接着会用一个不带参数的最终RETURN
命令来指示这个函数已经完成执行。RETURN NEXT
可以被用于标量和复合数据类型;对于复合类型,将返回一个完整的结果“表”。RETURN QUERY
将执行一个查询的结果追加到一个函数的结果集中。在一个单一的返回集合的函数中,RETURN NEXT
和RETURN QUERY
可以被随意地混合,这样它们的结果将被串接起来。
RETURN NEXT
和RETURN QUERY
实际上不会从函数中返回 — 它们简单地向函数的结果集中追加零或多行。然后会继续执行PL/pgSQL函数中的下一条语句。随着后继的RETURN NEXT
和RETURN QUERY
命令的执行,结果集就建立起来了。最后一个RETURN
(应该没有参数)会导致控制退出该函数(或者你可以让控制到达函数的结尾)。 RETURN QUERY
有一种变体RETURN QUERY EXECUTE
,它可以动态指定要被执行的查询。可以通过USING
向计算出的查询字符串插入参数表达式,这和在EXECUTE
命令中的方式相同。 如果你声明函数带有输出参数,只需要写不带表达式的RETURN NEXT
。在每一次执行时,输出参数变量的当前值将被保存下来用于最终返回为结果的一行。注意为了创建一个带有输出参数的集合返回函数,在有多个输出参数时,你必须声明函数为返回SETOF record
;或者如果只有一个类型为sometype
的输出参数时,声明函数为SETOF sometype
。
下面是一个使用RETURN NEXT
的函数例子:
1CREATE TABLE foo (fooid INT, foosubid INT, fooname TEXT);
2INSERT INTO foo VALUES (1, 2, 'three');
3INSERT INTO foo VALUES (4, 5, 'six');
4
5CREATE OR REPLACE FUNCTION get_all_foo() RETURNS SETOF foo AS
6$BODY$
7DECLARE
8 r foo%rowtype;
9BEGIN
10 FOR r IN
11 SELECT * FROM foo WHERE fooid > 0
12 LOOP
13 -- 这里可以做一些处理
14 RETURN NEXT r; -- 返回 SELECT 的当前行
15 END LOOP;
16 RETURN;
17END;
18$BODY$
19LANGUAGE plpgsql;
20
21SELECT * FROM get_all_foo();
使用RETURN QUERY
的函数的例子:
1CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS
2$BODY$
3BEGIN
4 RETURN QUERY SELECT flightid
5 FROM flight
6 WHERE flightdate >= $1
7 AND flightdate < ($1 + 1);
8
9 -- 因为执行还未结束,我们可以检查是否有行被返回
10 -- 如果没有就抛出异常。
11 IF NOT FOUND THEN
12 RAISE EXCEPTION 'No flight at %.', $1;
13 END IF;
14 RETURN;
15 END;
16$BODY$
17LANGUAGE plpgsql;
18
19-- 返回可用的航班或者在没有可用航班时抛出异常。
20SELECT * FROM get_available_flightid(CURRENT_DATE);
注意: 目前RETURN NEXT
和RETURN QUERY
的实现在从函数返回之前会把整个结果集都保存起来。这意味着如果一个PL/pgSQL函数生成一个非常大的结果集,性能可能会很差:数据将被写到磁盘上以避免内存耗尽,但是函数本身在整个结果集都生成之前不会退出。将来的PL/pgSQL版本可能会允许用户定义没有这种限制的集合返回函数。目前,数据开始被写入到磁盘的时机由配置变量work_mem控制。拥有足够内存来存储大型结果集的管理员可以考虑增大这个参数。
从过程中返回
过程没有返回值。因此,过程的结束可以不用RETURN
语句。 如果想用一个RETURN
语句提前退出代码,只需写一个没有表达式的RETURN
。 如果过程有输出参数,那么输出参数最终的值会被返回给调用者。
调用存储过程
PL/pgSQL函数,存储过程或DO
块可以使用 CALL
调用存储过程。输出参数的处理方式与纯SQL中CALL
的工作方式不同。存储过程的每个INOUT
参数必须和CALL
语句中的变量对应, 并且无论存储过程返回什么,都会在返回后赋值给该变量。例如:
1CREATE PROCEDURE triple(INOUT x int)
2LANGUAGE plpgsql
3AS $$
4BEGIN
5 x := x * 3;
6END;
7$$;
8
9DO $$
10DECLARE myvar int := 5;
11BEGIN
12 CALL triple(myvar);
13 RAISE NOTICE 'myvar = %', myvar; -- prints 15
14END;
15$$;
条件
IF
和CASE
语句让你可以根据某种条件执行二选其一的命令。PL/pgSQL有三种形式的IF
:
IF … THEN … END IFIF … THEN … ELSE … END IFIF … THEN … ELSIF … THEN … ELSE … END IF
以及两种形式的CASE
:
CASE … WHEN … THEN … ELSE … END CASECASE WHEN … THEN … ELSE … END CASE
IF-THEN
1IF boolean-expression THEN
2 statements
3END IF;
IF-THEN
语句是IF
的最简单形式。如果条件为真,在THEN
和END IF
之间的语句将被执行。否则,将忽略它们。 e.g.
1IF v_user_id <> 0 THEN
2 UPDATE users SET email = v_email WHERE user_id = v_user_id;
3END IF;
IF-THEN-ELSE
1IF boolean-expression THEN
2 statements
3ELSE
4 statements
5END IF;
IF-THEN-ELSE
语句对IF-THEN
进行了增加,它让你能够指定一组在条件不为真时应该被执行的语句(注意这也包括条件为 NULL 的情况)。 e.g.
1IF parentid IS NULL OR parentid = ''
2THEN
3 RETURN fullname;
4ELSE
5 RETURN hp_true_filename(parentid) || '/' || fullname;
6END IF;
7
8IF v_count > 0 THEN
9 INSERT INTO users_count (count) VALUES (v_count);
10 RETURN 't';
11ELSE
12 RETURN 'f';
13END IF;
IF-THEN-ELSIF
1IF boolean-expression THEN
2 statements
3[ ELSIF boolean-expression THEN
4 statements
5[ ELSIF boolean-expression THEN
6 statements
7 ...
8]
9]
10[ ELSE
11 statements ]
12END IF;
有时会有多于两种选择。IF-THEN-ELSIF
则提供了一个简便的方法来检查多个条件。IF
条件会被一个接一个测试,直到找到第一个为真的。然后执行相关语句,然后控制会被交给END IF
之后的下一个语句(后续的任何IF
条件不会被测试)。如果没有一个IF
条件为真,那么ELSE
块(如果有)将被执行。e.g.
1IF number = 0 THEN
2 result := 'zero';
3ELSIF number > 0 THEN
4 result := 'positive';
5ELSIF number < 0 THEN
6 result := 'negative';
7ELSE
8 -- 嗯,唯一的其他可能性是数字为空
9 result := 'NULL';
10END IF;
关键词ELSIF
也可以被拼写成ELSEIF
。
另一个可以完成相同任务的方法是嵌套IF-THEN-ELSE
语句,如下例:
1IF demo_row.sex = 'm' THEN
2 pretty_sex := 'man';
3ELSE
4 IF demo_row.sex = 'f' THEN
5 pretty_sex := 'woman';
6 END IF;
7END IF;
不过,这种方法需要为每个IF
都写一个匹配的END IF
,因此当有很多选择时,这种方法比使用ELSIF
要麻烦得多。
简单CASE
1CASE search-expression
2 WHEN expression [, expression [ ... ]] THEN
3 statements
4 [ WHEN expression [, expression [ ... ]] THEN
5 statements
6 ... ]
7 [ ELSE
8 statements ]
9END CASE;
CASE
的简单形式提供了基于操作数等值判断的有条件执行。search-expression
会被计算(一次)并且一个接一个地与WHEN
子句中的每个expression
比较。如果找到一个匹配,那么相应的statements
会被执行,并且接着控制会被交给END CASE
之后的下一个语句(后续的WHEN
表达式不会被计算)。如果没有找到匹配,ELSE
语句
会被执行。但是如果ELSE
不存在,将会抛出一个CASE_NOT_FOUND
异常。
这里是一个简单的例子:
1CASE x
2 WHEN 1, 2 THEN
3 msg := 'one or two';
4 ELSE
5 msg := 'other value than one or two';
6END CASE;
搜索CASE
1CASE
2 WHEN boolean-expression THEN
3 statements
4 [ WHEN boolean-expression THEN
5 statements
6 ... ]
7 [ ELSE
8 statements ]
9END CASE;
CASE
的搜索形式基于布尔表达式真假的有条件执行。每一个WHEN
子句的boolean-expression
会被依次计算,直到找到一个得到真
的。然后相应的statements
会被执行,并且接下来控制会被传递给END CASE
之后的下一个语句(后续的WHEN
表达式不会被计算)。如果没有找到为真的结果,ELSE
statements
会被执行。但是如果ELSE
不存在,那么将会抛出一个CASE_NOT_FOUND
异常。
这里是一个例子:
1CASE
2 WHEN x BETWEEN 0 AND 10 THEN
3 msg := 'value is between zero and ten';
4 WHEN x BETWEEN 11 AND 20 THEN
5 msg := 'value is between eleven and twenty';
6END CASE;
简单循环
总体上使用LOOP
、EXIT
、CONTINUE
、WHILE
、FOR
和FOREACH
语句,你可以安排PL/pgSQL重复一系列命令。
LOOP
1[ <<label>> ]
2LOOP
3 statements
4END LOOP [ label ];
LOOP
定义一个无条件的循环,它会无限重复直到被EXIT
或RETURN
语句终止。可选的label
可以被EXIT
和CONTINUE
语句用在嵌套循环中指定这些语句引用的是哪一层循环。
EXIT
1EXIT [ label ] [ WHEN boolean-expression ];
如果没有给出label
,那么最内层的循环会被终止,然后跟在END LOOP
后面的语句会被执行。如果给出了label
,那么它必须是当前或者更高层的嵌套循环或者语句块的标签。然后该命名循环或块就会被终止,并且控制会转移到该循环/块相应的END
之后的语句上。
如果指定了WHEN
,只有boolean-expression
为真时才会发生循环退出。否则,控制会转移到EXIT
之后的语句。
EXIT
可以被用在所有类型的循环中,它并不限于在无条件循环中使用。
在和BEGIN
块一起使用时,EXIT
会把控制交给块结束后的下一个语句。需要注意的是,一个标签必须被用于这个目的;一个没有被标记的EXIT
永远无法被认为与一个BEGIN
块匹配(这种状况从PostgreSQL 8.4 之前的发布就已经开始改变。这可能允许一个未被标记的EXIT
匹配一个BEGIN
块)。
1LOOP
2 -- 一些计算
3 IF count > 0 THEN
4 EXIT; -- 退出循环
5 END IF;
6END LOOP;
7
8LOOP
9 -- 一些计算
10 EXIT WHEN count > 0; -- 和前一个例子相同的结果
11END LOOP;
12
13<<ablock>>
14BEGIN
15 -- 一些计算
16 IF stocks > 100000 THEN
17 EXIT ablock; -- 导致从 BEGIN 块中退出
18 END IF;
19 -- 当stocks > 100000时,这里的计算将被跳过
20END;
CONTINUE
1CONTINUE [ label ] [ WHEN boolean-expression ];
如果没有给出label
,最内层循环的下一次迭代会开始。也就是,循环体中剩余的所有语句将被跳过,并且控制会返回到循环控制表达式(如果有)来决定是否需要另一次循环迭代。如果label
存在,它指定应该继续执行的循环的标签。
如果指定了WHEN
,该循环的下一次迭代只有在boolean-expression
为真时才会开始。否则,控制会传递给CONTINUE
后面的语句。
CONTINUE
可以被用在所有类型的循环中,它并不限于在无条件循环中使用。
1LOOP
2 -- 一些计算
3 EXIT WHEN count > 100;
4 CONTINUE WHEN count < 50;
5 -- 一些用于 count IN [50 .. 100] 的计算
6END LOOP;
WHILE
1[ <<label>> ]
2WHILE boolean-expression LOOP
3 statements
4END LOOP [ label ];
只要boolean-expression
被计算为真,WHILE
语句就会重复一个语句序列。在每次进入到循环体之前都会检查该表达式。
1WHILE amount_owed > 0 AND gift_certificate_balance > 0 LOOP
2 -- 这里是一些计算
3END LOOP;
4
5WHILE NOT done LOOP
6 -- 这里是一些计算
7END LOOP;
FOR (整型变体)
1[ <<label>> ]
2FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
3 statements
4END LOOP [ label ];
这种形式的FOR
会创建一个在一个整数范围上迭代的循环。变量name
会自动定义为类型integer
并且只在循环内存在(任何该变量名的现有定义在此循环内都将被忽略)。给出范围上下界的两个表达式在进入循环的时候计算一次。如果没有指定BY
子句,迭代步长为 1,否则步长是BY
中指定的值,该值也只在循环进入时计算一次。如果指定了REVERSE
,那么在每次迭代后步长值会被减除而不是增加。
整数FOR
循环的一些例子:
1FOR i IN 1..10 LOOP
2 -- 我在循环中将取值 1,2,3,4,5,6,7,8,9,10
3END LOOP;
4
5FOR i IN REVERSE 10..1 LOOP
6 -- 我在循环中将取值 10,9,8,7,6,5,4,3,2,1
7END LOOP;
8
9FOR i IN REVERSE 10..1 BY 2 LOOP
10 -- 我在循环中将取值 10,8,6,4,2
11END LOOP;
如果下界大于上界(或者在REVERSE
情况下是小于),循环体根本不会被执行。而且不会抛出任何错误。
如果一个label
被附加到FOR
循环,那么整数循环变量可以用一个使用那个label
的限定名引用。
通过查询结果循环
使用一种不同类型的FOR
循环,你可以通过一个查询的结果进行迭代并且操纵相应的数据。语法是:
1[ <<label>> ]
2FOR target IN query LOOP
3 statements
4END LOOP [ label ];
target
是一个记录变量、行变量或者逗号分隔的标量变量列表。target
被连续不断被赋予来自query
的每一行,并且循环体将为每一行执行一次。下面是一个例子:
1CREATE FUNCTION refresh_mviews() RETURNS integer AS $$
2DECLARE
3 mviews RECORD;
4BEGIN
5 RAISE NOTICE 'Refreshing all materialized views...';
6
7 FOR mviews IN
8 SELECT n.nspname AS mv_schema,
9 c.relname AS mv_name,
10 pg_catalog.pg_get_userbyid(c.relowner) AS owner
11 FROM pg_catalog.pg_class c
12 LEFT JOIN pg_catalog.pg_namespace n ON (n.oid = c.relnamespace)
13 WHERE c.relkind = 'm'
14 ORDER BY 1
15 LOOP
16
17 -- Now "mviews" has one record with information about the materialized view
18
19 RAISE NOTICE 'Refreshing materialized view %.% (owner: %)...',
20 quote_ident(mviews.mv_schema),
21 quote_ident(mviews.mv_name),
22 quote_ident(mviews.owner);
23 EXECUTE format('REFRESH MATERIALIZED VIEW %I.%I', mviews.mv_schema, mviews.mv_name);
24 END LOOP;
25
26 RAISE NOTICE 'Done refreshing materialized views.';
27 RETURN 1;
28END;
29$$ LANGUAGE plpgsql;
如果循环被一个EXIT
语句终止,那么在循环之后你仍然可以访问最后被赋予的行值。
在这类FOR
语句中使用的query
可以是任何返回行给调用者的 SQL 命令:最常见的是SELECT
,但你也可以使用带有RETURNING
子句的INSERT
、UPDATE
或DELETE
。一些EXPLAIN
之类的功能性命令也可以用在这里。
FOR-IN-EXECUTE
语句是在行上迭代的另一种方式:
1[ <<label>> ]
2FOR target IN EXECUTE text_expression [ USING expression [, ... ] ] LOOP
3 statements
4END LOOP [ label ];
这个例子类似前面的形式,只不过源查询被指定为一个字符串表达式,在每次进入FOR
循环时都会计算它并且重新规划。这允许程序员在一个预先规划好了的命令的速度和一个动态命令的灵活性之间进行选择,就像一个纯EXECUTE
语句那样。在使用EXECUTE
时,可以通过USING
将参数值插入到动态命令中。
另一种指定要对其结果迭代的查询的方式是将它声明为一个游标。后边有相应介绍。
通过数组循环
FOREACH
循环很像一个FOR
循环,但不是通过一个 SQL 查询返回的行进行迭代,它通过一个数组值的元素来迭代(通常,FOREACH
意味着通过一个组合值表达式的部件迭代;用于通过除数组之外组合类型进行循环的变体可能会在未来被加入)。在一个数组上循环的FOREACH
语句是:
1[ <<label>> ]
2FOREACH target [ SLICE number ] IN ARRAY expression LOOP
3 statements
4END LOOP [ label ];
如果没有SLICE
,或者如果没有指定SLICE 0
,循环会通过计算expression
得到的数组的个体元素进行迭代。target
变量被逐一赋予每一个元素值,并且循环体会为每一个元素执行。这里是一个通过整数数组的元素循环的例子:
1CREATE FUNCTION sum(int[]) RETURNS int8 AS $$
2DECLARE
3 s int8 := 0;
4 x int;
5BEGIN
6 FOREACH x IN ARRAY $1
7 LOOP
8 s := s + x;
9 END LOOP;
10 RETURN s;
11END;
12$$ LANGUAGE plpgsql;
13
14select sum(array[1,2,3]);
元素会被按照存储顺序访问,而不管数组的维度数。尽管target
通常只是一个单一变量,当通过一个组合值(记录)的数组循环时,它可以是一个变量列表。在那种情况下,对每一个数组元素,变量会被从组合值的连续列赋值。
通过一个正SLICE
值,FOREACH
通过数组的切片而不是单一元素迭代。SLICE
值必须是一个不大于数组维度数的整数常量。target
变量必须是一个数组,并且它接收数组值的连续切片,其中每一个切片都有SLICE
指定的维度数。这里是一个通过一维切片迭代的例子:
1CREATE FUNCTION scan_rows(int[]) RETURNS void AS $$
2DECLARE
3 x int[];
4BEGIN
5 FOREACH x SLICE 1 IN ARRAY $1
6 LOOP
7 RAISE NOTICE 'row = %', x;
8 END LOOP;
9END;
10$$ LANGUAGE plpgsql;
11
12SELECT scan_rows(ARRAY[[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
13
14NOTICE: row = {1,2,3}
15NOTICE: row = {4,5,6}
16NOTICE: row = {7,8,9}
17NOTICE: row = {10,11,12}
捕获错误
默认情况下,PL/pgSQL函数中发生的任何错误都会中止函数和周围事务的执行。你可以使用一个带有EXCEPTION
子句的BEGIN
块俘获错误并且从中恢复。其语法是BEGIN
块通常的语法的一个扩展:(https://www.postgresql.org/docs/14/errcodes-appendix.html, http://postgres.cn/docs/14/errcodes-appendix.html)
1[ <<label>> ]
2[ DECLARE
3 declarations ]
4BEGIN
5 statements
6EXCEPTION
7 WHEN condition [ OR condition ... ] THEN
8 handler_statements
9 [ WHEN condition [ OR condition ... ] THEN
10 handler_statements
11 ... ]
12END;
如果没有发生错误,这种形式的块只是简单地执行所有statements
, 并且接着控制转到END
之后的下一个语句。但是如果在statements
内发生了一个错误,则会放弃对statements
的进一步处理,然后控制会转到EXCEPTION
列表。系统会在列表中寻找匹配所发生错误的第一个condition
。如果找到一个匹配,则执行对应的handler_statements
,并且接着把控制转到END
之后的下一个语句。如果没有找到匹配,该错误就会传播出去,就好像根本没有EXCEPTION
一样:错误可以被一个带有EXCEPTION
的闭合块捕捉,如果没有EXCEPTION
则中止该函数的处理。
condition
的名字可以是附录 A中显示的任何名字。一个分类名匹配其中所有的错误。特殊的条件名OTHERS
匹配除了QUERY_CANCELED
和ASSERT_FAILURE
之外的所有错误类型(虽然通常并不明智,还是可以用名字捕获这两种错误类型)。条件名是大小写无关的。一个错误条件也可以通过SQLSTATE
代码指定,例如以下是等价的:
1WHEN division_by_zero THEN ...
2WHEN SQLSTATE '22012' THEN ...
如果在选中的handler_statements
内发生了新的错误,那么它不能被这个EXCEPTION
子句捕获,而是被传播出去。一个外层的EXCEPTION
子句可以捕获它。
当一个错误被EXCEPTION
捕获时,PL/pgSQL函数的局部变量会保持错误发生时的值,但是该块中所有对持久数据库状态的改变都会被回滚。例如,考虑这个片段:
1INSERT INTO mytab(firstname, lastname) VALUES('Tom', 'Jones');
2BEGIN
3 UPDATE mytab SET firstname = 'Joe' WHERE lastname = 'Jones';
4 x := x + 1;
5 y := x / 0;
6EXCEPTION
7 WHEN division_by_zero THEN
8 RAISE NOTICE 'caught division_by_zero';
9 RETURN x;
10END;
当控制到达对y
赋值的地方时,它会带着一个division_by_zero
错误失败。这个错误将被EXCEPTION
子句捕获。而在RETURN
语句中返回的值将是x
增加过后的值。但是UPDATE
命令的效果将已经被回滚。不过,在该块之前的INSERT
将不会被回滚,因此最终的结果是数据库包含Tom Jones
但不包含Joe Jones
。
提示:进入和退出一个包含EXCEPTION
子句的块要比不包含EXCEPTION
的块开销大的多。因此,只在必要的时候使用EXCEPTION
。
e.g. UPDATE/INSERT的异常
这个例子使用异常处理来酌情执行UPDATE
或 INSERT
。我们推荐应用使用带有 ON CONFLICT DO UPDATE
的INSERT
而不是真正使用这种模式。下面的例子主要是为了展示 PL/pgSQL如何控制流程:
1CREATE TABLE db (a INT PRIMARY KEY, b TEXT);
2
3CREATE FUNCTION merge_db(key INT, data TEXT) RETURNS VOID AS
4$$
5BEGIN
6 LOOP
7 -- 首先尝试更新键
8 UPDATE db SET b = data WHERE a = key;
9 IF found THEN
10 RETURN;
11 END IF;
12 -- 不在这里,那么尝试插入该键
13 -- 如果其他某人并发地插入同一个键,
14 -- 我们可能得到一个唯一键失败
15 BEGIN
16 INSERT INTO db(a,b) VALUES (key, data);
17 RETURN;
18 EXCEPTION WHEN unique_violation THEN
19 -- 什么也不做,并且循环再次尝试 UPDATE
20 END;
21 END LOOP;
22END;
23$$
24LANGUAGE plpgsql;
25
26SELECT merge_db(1, 'david');
27SELECT merge_db(1, 'dennis');
这段代码假定unique_violation
错误是INSERT
造成,并且不是由该表上一个触发器函数中的INSERT
导致。如果在该表上有多于一个唯一索引,也可能会发生不正确的行为,因为不管哪个索引导致该错误它都将重试该操作。通过接下来要讨论的特性来检查被捕获的错误是否为所预期的会更安全。
得到有关某个错误的信息
异常处理器经常被用来标识发生的特定错误。有两种方法来得到PL/pgSQL中当前异常的信息:特殊变量和GET STACKED DIAGNOSTICS
命令。 在一个异常处理器内,特殊变量SQLSTATE
包含了对应于被抛出异常的错误代码(可能的错误代码列表见表 A.1)。特殊变量SQLERRM
包含与该异常相关的错误消息。这些变量在异常处理器外是未定义的。
在一个异常处理器内,我们也可以用GET STACKED DIAGNOSTICS
命令检索有关当前异常的信息,该命令的形式为:
1GET STACKED DIAGNOSTICS variable { = | := } item [ , ... ];
每个item
是一个关键词,它标识一个被赋予给指定变量
(应该具有接收该值的正确数据类型)的状态值。表 43.2中显示了当前可用的状态项。
错误诊断项
| 名称 | 类型 | 描述 |
|---|---|---|
RETURNED_SQLSTATE | text | 该异常的 SQLSTATE 错误代码 |
COLUMN_NAME | text | 与异常相关的列名 |
CONSTRAINT_NAME | text | 与异常相关的约束名 |
PG_DATATYPE_NAME | text | 与异常相关的数据类型名 |
MESSAGE_TEXT | text | 该异常的主要消息的文本 |
TABLE_NAME | text | 与异常相关的表名 |
SCHEMA_NAME | text | 与异常相关的模式名 |
PG_EXCEPTION_DETAIL | text | 该异常的详细消息文本(如果有) |
PG_EXCEPTION_HINT | text | 该异常的提示消息文本(如果有) |
PG_EXCEPTION_CONTEXT | text | 描述产生异常时调用栈的文本行 |
如果异常没有为一个项设置值,将返回一个空字符串。
1DECLARE
2 text_var1 text;
3 text_var2 text;
4 text_var3 text;
5BEGIN
6 -- 某些可能导致异常的处理
7 ...
8EXCEPTION WHEN OTHERS THEN
9 GET STACKED DIAGNOSTICS text_var1 = MESSAGE_TEXT,
10 text_var2 = PG_EXCEPTION_DETAIL,
11 text_var3 = PG_EXCEPTION_HINT;
12END;
获得执行位置信息
GET DIAGNOSTICS
命令检索有关当前执行状态的信息(反之上文讨论的GET STACKED DIAGNOSTICS
命令会把有关执行状态的信息报告成一个以前的错误)。它的PG_CONTEXT
状态项可用于标识当前执行位置。状态项PG_CONTEXT
将返回一个文本字符串,其中有描述该调用栈的多行文本。第一行会指向当前函数以及当前正在执行GET DIAGNOSTICS
的命令。第二行及其后的行表示调用栈中更上层的调用函数。例如:
1CREATE OR REPLACE FUNCTION outer_func() RETURNS integer AS $$
2BEGIN
3 RETURN inner_func();
4END;
5$$ LANGUAGE plpgsql;
6
7CREATE OR REPLACE FUNCTION inner_func() RETURNS integer AS $$
8DECLARE
9 stack text;
10BEGIN
11 GET DIAGNOSTICS stack = PG_CONTEXT;
12 RAISE NOTICE E'--- Call Stack ---\n%', stack;
13 RETURN 1;
14END;
15$$ LANGUAGE plpgsql;
16
17SELECT outer_func();
18
19NOTICE: --- Call Stack ---
20PL/pgSQL function inner_func() line 5 at GET DIAGNOSTICS
21PL/pgSQL function outer_func() line 3 at RETURN
22CONTEXT: PL/pgSQL function outer_func() line 3 at RETURN
23 outer_func
24 ------------
25 1
26(1 row)
GET STACKED DIAGNOSTICS ... PG_EXCEPTION_CONTEXT
返回同类的栈跟踪,但是它描述检测到错误的位置而不是当前位置。
错误码及错误信息和异常信息
(https://www.postgresql.org/docs/14/errcodes-appendix.html, http://postgres.cn/docs/14/errcodes-appendix.html)
PostgreSQL服务器发出的所有消息都被赋予了五个字符错误代码,这遵循 SQL 标准对“SQLSTATE”代码的习惯。需要知道发生了什么错误条件的应用通常应该测试错误代码, 而不是查看文本形式的错误消息。
根据标准,错误代码的前两个字符表示错误类别,而后三个字符表示在该类别内的一种特定情况。因此, 那些不能识别特定错误代码的应用仍然可以从错误类别中推断要做什么。
PostgreSQL错误代码
| 错误代码 | 情况名称 |
|---|---|
| Class 00 — Successful Completion | |
00000 | successful_completion |
| Class 01 — Warning | |
01000 | warning |
0100C | dynamic_result_sets_returned |
01008 | implicit_zero_bit_padding |
01003 | null_value_eliminated_in_set_function |
01007 | privilege_not_granted |
01006 | privilege_not_revoked |
01004 | string_data_right_truncation |
01P01 | deprecated_feature |
| Class 02 — No Data (this is also a warning class per the SQL standard) | |
02000 | no_data |
02001 | no_additional_dynamic_result_sets_returned |
| Class 03 — SQL Statement Not Yet Complete | |
03000 | sql_statement_not_yet_complete |
| Class 08 — Connection Exception | |
08000 | connection_exception |
08003 | connection_does_not_exist |
08006 | connection_failure |
08001 | sqlclient_unable_to_establish_sqlconnection |
08004 | sqlserver_rejected_establishment_of_sqlconnection |
08007 | transaction_resolution_unknown |
08P01 | protocol_violation |
| Class 09 — Triggered Action Exception | |
09000 | triggered_action_exception |
| Class 0A — Feature Not Supported | |
0A000 | feature_not_supported |
| Class 0B — Invalid Transaction Initiation | |
0B000 | invalid_transaction_initiation |
| Class 0F — Locator Exception | |
0F000 | locator_exception |
0F001 | invalid_locator_specification |
| Class 0L — Invalid Grantor | |
0L000 | invalid_grantor |
0LP01 | invalid_grant_operation |
| Class 0P — Invalid Role Specification | |
0P000 | invalid_role_specification |
| Class 0Z — Diagnostics Exception | |
0Z000 | diagnostics_exception |
0Z002 | stacked_diagnostics_accessed_without_active_handler |
| Class 20 — Case Not Found | |
20000 | case_not_found |
| Class 21 — Cardinality Violation | |
21000 | cardinality_violation |
| Class 22 — Data Exception | |
22000 | data_exception |
2202E | array_subscript_error |
22021 | character_not_in_repertoire |
22008 | datetime_field_overflow |
22012 | division_by_zero |
22005 | error_in_assignment |
2200B | escape_character_conflict |
22022 | indicator_overflow |
22015 | interval_field_overflow |
2201E | invalid_argument_for_logarithm |
22014 | invalid_argument_for_ntile_function |
22016 | invalid_argument_for_nth_value_function |
2201F | invalid_argument_for_power_function |
2201G | invalid_argument_for_width_bucket_function |
22018 | invalid_character_value_for_cast |
22007 | invalid_datetime_format |
22019 | invalid_escape_character |
2200D | invalid_escape_octet |
22025 | invalid_escape_sequence |
22P06 | nonstandard_use_of_escape_character |
22010 | invalid_indicator_parameter_value |
22023 | invalid_parameter_value |
22013 | invalid_preceding_or_following_size |
2201B | invalid_regular_expression |
2201W | invalid_row_count_in_limit_clause |
2201X | invalid_row_count_in_result_offset_clause |
2202H | invalid_tablesample_argument |
2202G | invalid_tablesample_repeat |
22009 | invalid_time_zone_displacement_value |
2200C | invalid_use_of_escape_character |
2200G | most_specific_type_mismatch |
22004 | null_value_not_allowed |
22002 | null_value_no_indicator_parameter |
22003 | numeric_value_out_of_range |
2200H | sequence_generator_limit_exceeded |
22026 | string_data_length_mismatch |
22001 | string_data_right_truncation |
22011 | substring_error |
22027 | trim_error |
22024 | unterminated_c_string |
2200F | zero_length_character_string |
22P01 | floating_point_exception |
22P02 | invalid_text_representation |
22P03 | invalid_binary_representation |
22P04 | bad_copy_file_format |
22P05 | untranslatable_character |
2200L | not_an_xml_document |
2200M | invalid_xml_document |
2200N | invalid_xml_content |
2200S | invalid_xml_comment |
2200T | invalid_xml_processing_instruction |
22030 | duplicate_json_object_key_value |
22031 | invalid_argument_for_sql_json_datetime_function |
22032 | invalid_json_text |
22033 | invalid_sql_json_subscript |
22034 | more_than_one_sql_json_item |
22035 | no_sql_json_item |
22036 | non_numeric_sql_json_item |
22037 | non_unique_keys_in_a_json_object |
22038 | singleton_sql_json_item_required |
22039 | sql_json_array_not_found |
2203A | sql_json_member_not_found |
2203B | sql_json_number_not_found |
2203C | sql_json_object_not_found |
2203D | too_many_json_array_elements |
2203E | too_many_json_object_members |
2203F | sql_json_scalar_required |
| Class 23 — Integrity Constraint Violation | |
23000 | integrity_constraint_violation |
23001 | restrict_violation |
23502 | not_null_violation |
23503 | foreign_key_violation |
23505 | unique_violation |
23514 | check_violation |
23P01 | exclusion_violation |
| Class 24 — Invalid Cursor State | |
24000 | invalid_cursor_state |
| Class 25 — Invalid Transaction State | |
25000 | invalid_transaction_state |
25001 | active_sql_transaction |
25002 | branch_transaction_already_active |
25008 | held_cursor_requires_same_isolation_level |
25003 | inappropriate_access_mode_for_branch_transaction |
25004 | inappropriate_isolation_level_for_branch_transaction |
25005 | no_active_sql_transaction_for_branch_transaction |
25006 | read_only_sql_transaction |
25007 | schema_and_data_statement_mixing_not_supported |
25P01 | no_active_sql_transaction |
25P02 | in_failed_sql_transaction |
25P03 | idle_in_transaction_session_timeout |
| Class 26 — Invalid SQL Statement Name | |
26000 | invalid_sql_statement_name |
| Class 27 — Triggered Data Change Violation | |
27000 | triggered_data_change_violation |
| Class 28 — Invalid Authorization Specification | |
28000 | invalid_authorization_specification |
28P01 | invalid_password |
| Class 2B — Dependent Privilege Descriptors Still Exist | |
2B000 | dependent_privilege_descriptors_still_exist |
2BP01 | dependent_objects_still_exist |
| Class 2D — Invalid Transaction Termination | |
2D000 | invalid_transaction_termination |
| Class 2F — SQL Routine Exception | |
2F000 | sql_routine_exception |
2F005 | function_executed_no_return_statement |
2F002 | modifying_sql_data_not_permitted |
2F003 | prohibited_sql_statement_attempted |
2F004 | reading_sql_data_not_permitted |
| Class 34 — Invalid Cursor Name | |
34000 | invalid_cursor_name |
| Class 38 — External Routine Exception | |
38000 | external_routine_exception |
38001 | containing_sql_not_permitted |
38002 | modifying_sql_data_not_permitted |
38003 | prohibited_sql_statement_attempted |
38004 | reading_sql_data_not_permitted |
| Class 39 — External Routine Invocation Exception | |
39000 | external_routine_invocation_exception |
39001 | invalid_sqlstate_returned |
39004 | null_value_not_allowed |
39P01 | trigger_protocol_violated |
39P02 | srf_protocol_violated |
39P03 | event_trigger_protocol_violated |
| Class 3B — Savepoint Exception | |
3B000 | savepoint_exception |
3B001 | invalid_savepoint_specification |
| Class 3D — Invalid Catalog Name | |
3D000 | invalid_catalog_name |
| Class 3F — Invalid Schema Name | |
3F000 | invalid_schema_name |
| Class 40 — Transaction Rollback | |
40000 | transaction_rollback |
40002 | transaction_integrity_constraint_violation |
40001 | serialization_failure |
40003 | statement_completion_unknown |
40P01 | deadlock_detected |
| Class 42 — Syntax Error or Access Rule Violation | |
42000 | syntax_error_or_access_rule_violation |
42601 | syntax_error |
42501 | insufficient_privilege |
42846 | cannot_coerce |
42803 | grouping_error |
42P20 | windowing_error |
42P19 | invalid_recursion |
42830 | invalid_foreign_key |
42602 | invalid_name |
42622 | name_too_long |
42939 | reserved_name |
42804 | datatype_mismatch |
42P18 | indeterminate_datatype |
42P21 | collation_mismatch |
42P22 | indeterminate_collation |
42809 | wrong_object_type |
428C9 | generated_always |
42703 | undefined_column |
42883 | undefined_function |
42P01 | undefined_table |
42P02 | undefined_parameter |
42704 | undefined_object |
42701 | duplicate_column |
42P03 | duplicate_cursor |
42P04 | duplicate_database |
42723 | duplicate_function |
42P05 | duplicate_prepared_statement |
42P06 | duplicate_schema |
42P07 | duplicate_table |
42712 | duplicate_alias |
42710 | duplicate_object |
42702 | ambiguous_column |
42725 | ambiguous_function |
42P08 | ambiguous_parameter |
42P09 | ambiguous_alias |
42P10 | invalid_column_reference |
42611 | invalid_column_definition |
42P11 | invalid_cursor_definition |
42P12 | invalid_database_definition |
42P13 | invalid_function_definition |
42P14 | invalid_prepared_statement_definition |
42P15 | invalid_schema_definition |
42P16 | invalid_table_definition |
42P17 | invalid_object_definition |
| Class 44 — WITH CHECK OPTION Violation | |
44000 | with_check_option_violation |
| Class 53 — Insufficient Resources | |
53000 | insufficient_resources |
53100 | disk_full |
53200 | out_of_memory |
53300 | too_many_connections |
53400 | configuration_limit_exceeded |
| Class 54 — Program Limit Exceeded | |
54000 | program_limit_exceeded |
54001 | statement_too_complex |
54011 | too_many_columns |
54023 | too_many_arguments |
| Class 55 — Object Not In Prerequisite State | |
55000 | object_not_in_prerequisite_state |
55006 | object_in_use |
55P02 | cant_change_runtime_param |
55P03 | lock_not_available |
55P04 | unsafe_new_enum_value_usage |
| Class 57 — Operator Intervention | |
57000 | operator_intervention |
57014 | query_canceled |
57P01 | admin_shutdown |
57P02 | crash_shutdown |
57P03 | cannot_connect_now |
57P04 | database_dropped |
57P05 | idle_session_timeout |
| Class 58 — System Error (errors external to PostgreSQL itself) | |
58000 | system_error |
58030 | io_error |
58P01 | undefined_file |
58P02 | duplicate_file |
| Class 72 — Snapshot Failure | |
72000 | snapshot_too_old |
| Class F0 — Configuration File Error | |
F0000 | config_file_error |
F0001 | lock_file_exists |
| Class HV — Foreign Data Wrapper Error (SQL/MED) | |
HV000 | fdw_error |
HV005 | fdw_column_name_not_found |
HV002 | fdw_dynamic_parameter_value_needed |
HV010 | fdw_function_sequence_error |
HV021 | fdw_inconsistent_descriptor_information |
HV024 | fdw_invalid_attribute_value |
HV007 | fdw_invalid_column_name |
HV008 | fdw_invalid_column_number |
HV004 | fdw_invalid_data_type |
HV006 | fdw_invalid_data_type_descriptors |
HV091 | fdw_invalid_descriptor_field_identifier |
HV00B | fdw_invalid_handle |
HV00C | fdw_invalid_option_index |
HV00D | fdw_invalid_option_name |
HV090 | fdw_invalid_string_length_or_buffer_length |
HV00A | fdw_invalid_string_format |
HV009 | fdw_invalid_use_of_null_pointer |
HV014 | fdw_too_many_handles |
HV001 | fdw_out_of_memory |
HV00P | fdw_no_schemas |
HV00J | fdw_option_name_not_found |
HV00K | fdw_reply_handle |
HV00Q | fdw_schema_not_found |
HV00R | fdw_table_not_found |
HV00L | fdw_unable_to_create_execution |
HV00M | fdw_unable_to_create_reply |
HV00N | fdw_unable_to_establish_connection |
| Class P0 — PL/pgSQL Error | |
P0000 | plpgsql_error |
P0001 | raise_exception |
P0002 | no_data_found |
P0003 | too_many_rows |
P0004 | assert_failure |
| Class XX — Internal Error | |
XX000 | internal_error |
XX001 | data_corrupted |
XX002 | index_corrupted |
6.2 游标
和一次执行整个查询不同,可以建立一个游标来封装该查询,并且接着一次读取该查询结果的一些行。这样做的原因之一是在结果中包含大量行时避免内存不足(不过,PL/pgSQL用户通常不需要担心这些,因为FOR
循环在内部会自动使用一个游标来避免内存问题)。一种更有趣的用法是返回一个函数已经创建的游标的引用,允许调用者读取行。这提供了一种有效的方法从函数中返回大型行集。
声明游标变量
所有在PL/pgSQL中对游标的访问都会通过游标变量,它总是特殊的数据类型refcursor
。创建游标变量的一种方法是把它声明为一个类型为refcursor
的变量。另外一种方法是使用游标声明语法,通常是:
1name [ [ NO ] SCROLL ] CURSOR [ ( arguments ) ] FOR query;
(为了对Oracle的兼容性,可以用IS
替代FOR
)。如果指定了SCROLL
,那么游标可以反向滚动;如果指定了NO SCROLL
,那么反向取的动作会被拒绝;如果二者都没有被指定,那么能否进行反向取就取决于查询。如果指定了arguments
, 那么它是一个逗号分隔的*
name* *
datatype*
对的列表, 它们定义在给定查询中要被参数值替换的名称。实际用于替换这些名字的值将在游标被打开之后指定。
1DECLARE
2 curs1 refcursor;
3 curs2 CURSOR FOR SELECT * FROM tenk1;
4 curs3 CURSOR (key integer) FOR SELECT * FROM tenk1 WHERE unique1 = key;
所有这三个变量都是refcursor
类型,但是第一个可以用于任何查询,而第二个已经被绑定了一个完全指定的查询,并且最后一个被绑定了一个参数化查询。(游标被打开时,key
将被一个整数参数值替换)。变量curs1
被称为未绑定,因为它没有被绑定到任何特定查询。
打开游标
在一个游标可以被用来检索行之前,它必需先被打开(这是和 SQL 命令DECLARE CURSOR
等效的操作)。PL/pgSQL有三种形式的OPEN
命令,其中两种用于未绑定游标变量,另外一种用于已绑定的游标变量。
Open For Query
1OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR query;
该游标变量被打开并且被给定要执行的查询。游标不能是已经打开的,并且它必需已经被声明为一个未绑定的游标变量(也就是声明为一个简单的refcursor
变量)。该查询必须是一条SELECT
或者其它返回行的东西(例如EXPLAIN
)。该查询会按照其它PL/pgSQL中的 SQL 命令同等的方式对待:先代换PL/pgSQL变量名,并且执行计划会被缓存用于可能的重用。当一个PL/pgSQL变量被替换到游标查询中时,替换的值是在OPEN
时它所具有的值。对该变量后续的改变不会影响游标的行为。对于一个已经绑定的游标,SCROLL
和NO SCROLL
选项具有相同的含义。
1OPEN curs1 FOR SELECT * FROM foo WHERE key = mykey;
Open For Execute
1OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR EXECUTE query_string
2 [ USING expression [, ... ] ];
打开游标变量并且执行指定的查询。该游标不能是已打开的,并且必须已经被声明为一个未绑定的游标变量(也就是声明为一个简单的refcursor
变量)。该查询以和EXECUTE
中相同的方式被指定为一个字符串表达式。照例,这提供了灵活性,因此查询计划可以在两次运行之间变化(见第 43.11.2 节),并且它也意味着在该命令字符串上还没有完成变量替换。正如EXECUTE
,可以通过format()
和USING
将参数值插入到动态命令中。SCROLL
和NO SCROLL
选项具有和已绑定游标相同的含义。
一个例子:
1OPEN curs1 FOR EXECUTE format('SELECT * FROM %I WHERE col1 = $1',tabname) USING keyvalue;
在这个例子中,表名被通过format()
插入到查询中。 col1
的比较值被通过一个USING
参数插入, 所以它不需要引用。
打开一个已绑定的游标
1OPEN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ];
这种形式的OPEN
被用于打开一个游标变量,它的查询是在声明时绑定的。该游标不能是已经打开的。当且仅当该游标被声明为接收参数时,才必需出现一个实际参数值表达式的列表。这些值将被替换到命令中。
一个已绑定游标的查询计划总是被认为是可缓存的,在这种情况中没有EXECUTE
的等效形式。注意SCROLL
和NO SCROLL
不能在OPEN
中指定,因为游标的滚动行为已经被确定。
使用位置或命名记号可以传递参数值。在位置记号中,所有参数都必须按照顺序指定。在命名记号中,每一个参数的名字被使用:=
指定以将它和参数表达式分隔开。类似于第 4.3 节中描述的调用函数,也允许混合位置和命名记号。
例子(这些例子使用上面例子中的游标声明):
1OPEN curs2;
2OPEN curs3(42);
3OPEN curs3(key := 42);
因为在一个已绑定游标的查询上已经完成了变量替换,实际有两种方式将值传到游标中:给OPEN
一个显式参数,或者在查询中隐式引用一个PL/pgSQL变量。不过,只有在已绑定游标之前声明的变量才将会被替换到游标中。在两种情况下,要被传递的值都是在OPEN
时确定的。例如,得到上例中curs3
相同效果的另一种方式是
1DECLARE
2 key integer;
3 curs4 CURSOR FOR SELECT * FROM tenk1 WHERE unique1 = key;
4BEGIN
5 key := 42;
6 OPEN curs4;
使用游标
一旦一个游标已经被打开,那么就可以用这里描述的语句操作它。
这些操作不需要发生在打开该游标开始操作的同一个函数中。你可以从一个函数返回一个refcursor
值,并且让调用者在该游标上操作(在内部,refcursor
值只是一个包含该游标活动查询的所谓入口的字符串名称。这个名字可以被传递、赋予给其它refcursor
变量等等,而不用担心扰乱入口)。
所有入口会在事务的结尾被隐式地关闭。因此一个refcursor
值只能在该事务结束前用于引用一个打开的游标。
Fetch Cursor
1FETCH [ direction { FROM | IN } ] cursor INTO target;
就像SELECT INTO
一样,FETCH
从游标中检索下一行到目标中,目标可以是一个行变量、记录变量或者逗号分隔的简单变量列表。如果没有下一行,目标会被设置为 NULL。与SELECT INTO
一样,可以检查特殊变量FOUND
来看一行是否被获得。
direction
子句可以是 SQL FETCH命令中允许的任何变体,除了那些能够取得多于一行的。即它可以是 NEXT
、 PRIOR
、 FIRST
、 LAST
、 ABSOLUTE
count
、 RELATIVE
count
、 FORWARD
或者 BACKWARD
。 省略direction
和指定NEXT
是一样的。在使用count
的形式中,count
可以是任意的整数值表达式(与SQL命令FETCH
不一样,FETCH
仅允许整数常量)。除非游标被使用SCROLL
选项声明或打开,否则要求反向移动的direction
值很可能会失败。
cursor
必须是一个引用已打开游标入口的refcursor
变量名。
1FETCH curs1 INTO rowvar;
2FETCH curs2 INTO foo, bar, baz;
3FETCH LAST FROM curs3 INTO x, y;
4FETCH RELATIVE -2 FROM curs4 INTO x;
Move Cursor
1MOVE [ direction { FROM | IN } ] cursor;
MOVE
重新定位一个游标而不检索任何数据。MOVE
的工作方式与FETCH
命令很相似,但是MOVE
只是重新定位游标并且不返回至移动到的行。与SELECT INTO
一样,可以检查特殊变量FOUND
来看要移动到的行是否存在。 e.g.
1MOVE curs1;
2MOVE LAST FROM curs3;
3MOVE RELATIVE -2 FROM curs4;
4MOVE FORWARD 2 FROM curs4;
UPDATE/DELETE WHERE CURRENT OF
1UPDATE table SET ... WHERE CURRENT OF cursor;
2DELETE FROM table WHERE CURRENT OF cursor;
当一个游标被定位到一个表行上时,使用该游标标识该行就可以对它进行更新或删除。对于游标的查询可以是什么是有限制的(尤其是不能有分组),并且最好在游标中使用FOR UPDATE
。详见DECLARE参考页。 e.g.
1UPDATE foo SET dataval = myval WHERE CURRENT OF curs1;
Close Cursor
1CLOSE cursor;
CLOSE
关闭一个已打开游标的底层入口。这样就可以在事务结束之前释放资源,或者释放掉该游标变量以便再次打开。
Return Cursor
PL/pgSQL函数可以向调用者返回游标。这对于返回多行或多列(特别是巨大的结果集)很有用。要想这么做,该函数打开游标并且把该游标的名字返回给调用者(或者简单的使用调用者指定的或已知的入口名打开游标)。调用者接着可以从游标中取得行。游标可以由调用者关闭,或者是在事务关闭时自行关闭。
用于一个游标的入口名可以由编程者指定或者自动生成。要指定一个入口名,只需要在打开refcursor
变量之前简单地为它赋予一个字符串。OPEN
将把refcursor
变量的字符串值用作底层入口的名字。不过,如果refcursor
变量为空,OPEN
会自动生成一个与任何现有入口不冲突的名称,并且将它赋予给refcursor
变量。
注意:一个已绑定的游标变量被初始化为表示其名称的字符串值,因此入口的名字和游标变量名相同,除非在打开游标之前通过赋值覆盖了这个名字。但是一个未绑定的游标变量最初默认为空值,因此它会收到一个自动生成的唯一名字,除非被覆盖。
调用者提供游标名字:
1CREATE TABLE test (col text);
2INSERT INTO test VALUES ('123');
3
4CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
5BEGIN
6 OPEN $1 FOR SELECT col FROM test;
7 RETURN $1;
8END;
9' LANGUAGE plpgsql;
10
11BEGIN;
12SELECT reffunc('funccursor');
13FETCH ALL IN funccursor;
14COMMIT;
自动游标名生成:
1CREATE FUNCTION reffunc2() RETURNS refcursor AS '
2DECLARE
3 ref refcursor;
4BEGIN
5 OPEN ref FOR SELECT col FROM test;
6 RETURN ref;
7END;
8' LANGUAGE plpgsql;
9
10-- 需要在一个事务中使用游标。
11BEGIN;
12SELECT reffunc2();
13
14 reffunc2
15--------------------
16 <unnamed cursor 1>
17(1 row)
18
19FETCH ALL IN "<unnamed cursor 1>";
20COMMIT;
从一个函数中返回多个游标:
1CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
2BEGIN
3 OPEN $1 FOR SELECT * FROM table_1;
4 RETURN NEXT $1;
5 OPEN $2 FOR SELECT * FROM table_2;
6 RETURN NEXT $2;
7END;
8$$ LANGUAGE plpgsql;
9
10-- 需要在一个事务中使用游标。
11BEGIN;
12
13SELECT * FROM myfunc('a', 'b');
14
15FETCH ALL FROM a;
16FETCH ALL FROM b;
17COMMIT;
通过一个游标的结果循环
有一种FOR
语句的变体,它允许通过游标返回的行进行迭代。语法是:
1[ <<label>> ]
2FOR recordvar IN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ] LOOP
3 statements
4END LOOP [ label ];
该游标变量必须在声明时已经被绑定到某个查询,并且它不能已经被打开。FOR
语句会自动打开游标,并且在退出循环时自动关闭游标。当且仅当游标被声明要使用参数时,才必须出现一个实际参数值表达式的列表。这些值会被替换到查询中,采用OPEN
期间的方式。
变量recordvar
会被自动定义为record
类型,并且只存在于循环内部(循环中该变量名任何已有定义都会被忽略)。每一个由游标返回的行都会被陆续地赋值给这个记录变量并且执行循环体。
6.3 事务管理
在由CALL
命令调用的过程中以及匿名代码块(DO
命令)中,可以用命令COMMIT
和ROLLBACK
结束事务。在一个事务被使用这些命令结束后,一个新的事务会被自动开始,因此没有单独的START TRANSACTION
命令(注意BEGIN
和END
在PL/pgSQL中有不同的含义)
1CREATE PROCEDURE transaction_test1()
2LANGUAGE plpgsql
3AS $$
4BEGIN
5 FOR i IN 0..9 LOOP
6 INSERT INTO test1 (a) VALUES (i);
7 IF i % 2 = 0 THEN
8 COMMIT;
9 ELSE
10 ROLLBACK;
11 END IF;
12 END LOOP;
13END;
14$$;
15
16CALL transaction_test1();
新事务开始时具有默认事务特征,如事务隔离级别。在循环中提交事务的情况下,可能需要以与前一个事务相同的特征来自动启动新事务。 命令COMMIT AND CHAIN
和ROLLBACK AND CHAIN
可以完成此操作。
只有在从顶层调用的CALL
或DO
中才能进行事务控制,在没有任何其他中间命令的嵌套CALL
或DO
调用中也能进行事务控制。例如,如果调用栈是CALL proc1()
→ CALL proc2()
→ CALL proc3()
,那么第二个和第三个过程可以执行事务控制动作。但是如果调用栈是CALL proc1()
→ SELECT func2()
→ CALL proc3()
,则最后一个过程不能做事务控制,因为中间有SELECT
。
对于游标循环有特殊的考虑。看看这个例子:
1CREATE PROCEDURE transaction_test2()
2LANGUAGE plpgsql
3AS $$
4DECLARE
5 r RECORD;
6BEGIN
7 FOR r IN SELECT * FROM test2 ORDER BY x LOOP
8 INSERT INTO test1 (a) VALUES (r.x);
9 COMMIT;
10 END LOOP;
11END;
12$$;
13
14CALL transaction_test2();
通常,游标会在事务提交时被自动关闭。但是,一个作为循环的组成部分创建的游标会自动被第一个COMMIT
或ROLLBACK
转变成一个可保持游标。这意味着该游标在第一个COMMIT
或ROLLBACK
处会被完全计算出来,而不是逐行被计算。该游标在循环后仍会被自动删除,因此这通常对用户是不可见的。
有非只读命令(UPDATE ... RETURNING
)驱动的游标循环中不允许有事务命令。
事务在一个具有异常处理部分的块中不能被结束。
6.4 错误和消息
报告错误和消息
使用RAISE
语句报告消息以及抛出错误。
1RAISE [ level ] 'format' [, expression [, ... ]] [ USING option = expression [, ... ] ];
2RAISE [ level ] condition_name [ USING option = expression [, ... ] ];
3RAISE [ level ] SQLSTATE 'sqlstate' [ USING option = expression [, ... ] ];
4RAISE [ level ] USING option = expression [, ... ];
5RAISE ;
level
选项指定了错误的严重性。允许的级别有DEBUG
、LOG
、INFO
、NOTICE
, WARNING
以及EXCEPTION
,默认级别是EXCEPTION
。EXCEPTION
会抛出一个错误(通常会中止当前事务)。其他级别仅仅是产生不同优先级的消息。不管一个特定优先级的消息是被报告给客户端、还是写到服务器日志、亦或是二者同时都做,这都由log_min_messages和client_min_messages配置变量控制。详见第 20 章。
如果有level
, 在它后面可以写一个format
( 它必须是一个简单字符串而不是表达式)。该格式字符串指定要被报告的 错误消息文本。在格式字符串后面可以跟上可选的要被插入到该消息的 参数表达式。在格式字符串中,%
会被下一个可选参数 的值所替换。写%%
可以发出一个字面的 %
。参数的数量必须匹配格式字符串中%
占位符的数量,否则在函数编译期间就会发生错误。
在这个例子中,v_job_id
的值将替换字符串中的%
:
1RAISE NOTICE 'Calling cs_create_job(%)', v_job_id;
通过写一个后面跟着option
= expression
项的USING
,可以为错误报告附加一些额外信息。每一个expression
可以是任意字符串值的表达式。允许的option
关键词是:
MESSAGE设置错误消息文本。这个选项可以被用于在
USING
之前包括一个格式字符串的RAISE
形式。DETAIL提供一个错误的细节消息。
HINT提供一个提示消息。
ERRCODE指定要报告的错误代码(SQLSTATE),可以用附录 A中所示的条件名,或者直接作为一个五字符的 SQLSTATE 代码。
COLUMN
CONSTRAINT
DATATYPE
TABLE
SCHEMA
提供一个相关对象的名称。
这个例子将用给定的错误消息和提示中止事务:
1RAISE EXCEPTION 'Nonexistent ID --> %', user_id
2 USING HINT = 'Please check your user ID';
3
这两个例子展示了设置 SQLSTATE 的两种等价的方法:
1RAISE 'Duplicate user ID: %', user_id USING ERRCODE = 'unique_violation';
2RAISE 'Duplicate user ID: %', user_id USING ERRCODE = '23505';
还有第二种RAISE
语法,在其中主要参数是要被报告的条件名或 SQLSTATE,例如:
1RAISE division_by_zero;
2RAISE SQLSTATE '22012';
在这种语法中,USING
能被用来提供一个自定义的错误消息、细节或提示。另一种做前面的例子的方法是
1RAISE unique_violation USING MESSAGE = 'Duplicate user ID: ' || user_id;
仍有另一种变体是写RAISE USING
或者RAISE *
level* USING
并且把所有其他东西都放在USING
列表中。
RAISE
的最后一种变体根本没有参数。这种形式只能被用在一个BEGIN
块的EXCEPTION
子句中,它导致当前正在被处理的错误被重新抛出。
注意:当用 SQLSTATE 代码指定一个错误代码时,你不会受到预定义错误代码的限制,而是可以选择任何由五位以及大写 ASCII 字母构成的错误代码,只有00000
不能使用。我们推荐尽量避免抛出以三个零结尾的错误代码,因为这些是分类代码并且只能用来捕获整个类别。
检查断言
ASSERT
语句是一种向 PL/pgSQL函数中插入调试检查的方便方法。
1ASSERT condition [ , message ];
condition
是一个布尔 表达式,它被期望总是计算为真。如果确实如此, ASSERT
语句不会再做什么。但如果结果是假 或者空,那么将发生一个ASSERT_FAILURE
异常(如果在计算 condition
时发生错误, 它会被报告为一个普通错误)。
如果提供了可选的message
, 它是一个结果(如果非空)被用来替换默认错误消息文本 “assertion failed”的表达式(如果 condition
失败)。 message
表达式在 断言成功的普通情况下不会被计算。
通过配置参数plpgsql.check_asserts
可以启用或者禁用断言测试, 这个参数接受布尔值且默认为on
。如果这个参数为off
, 则ASSERT
语句什么也不做。
注意ASSERT
是为了检测程序的 bug,而不是 报告普通的错误情况。如果要报告普通错误,请使用前面介绍的 RAISE
语句。
6.5 触发器函数
数据改变触发器
PL/pgSQL可以被用来在数据更改或者数据库事件上定义触发器函数。触发器函数用CREATE FUNCTION
命令创建,它被声明为一个没有参数并且返回类型为trigger
(对于数据更改触发器)或者event_trigger
(对于数据库事件触发器)的函数。名为PG_*
something*
的特殊局部变量将被自动创建用以描述触发该调用的条件。
一个数据更改触发器被声明为一个没有参数并且返回类型为trigger
的函数。注意,如下所述,即便该函数准备接收一些在CREATE TRIGGER
中指定的参数 — 这类参数通过TG_ARGV
传递,也必须把它声明为没有参数。
当一个PL/pgSQL函数当做触发器调用时,在顶层块会自动创建一些特殊变量。它们是:
NEW数据类型是
RECORD
;该变量为行级触发器中的INSERT
/UPDATE
操作保持新数据行。在语句级别的触发器以及DELETE
操作,这个变量是null。OLD数据类型是
RECORD
;该变量为行级触发器中的UPDATE
/DELETE
操作保持新数据行。在语句级别的触发器以及INSERT
操作,这个变量是null。TG_NAME数据类型是
name
;该变量包含实际触发的触发器名。TG_WHEN数据类型是
text
;是值为BEFORE
、AFTER
或INSTEAD OF
的一个字符串,取决于触发器的定义。TG_LEVEL数据类型是
text
;是值为ROW
或STATEMENT
的一个字符串,取决于触发器的定义。TG_OP数据类型是
text
;是值为INSERT
、UPDATE
、DELETE
或TRUNCATE
的一个字符串,它说明触发器是为哪个操作引发。TG_RELID数据类型是
oid
;是导致触发器调用的表的对象 ID。TG_RELNAME数据类型是
name
;是导致触发器调用的表的名称。现在已经被废弃,并且可能在未来的一个发行中消失。使用TG_TABLE_NAME
替代。TG_TABLE_NAME数据类型是
name
;是导致触发器调用的表的名称。TG_TABLE_SCHEMA数据类型是
name
;是导致触发器调用的表所在的模式名。TG_NARGS数据类型是
integer
;在CREATE TRIGGER
语句中给触发器函数的参数数量。TG_ARGV[]数据类型是
text
数组;来自CREATE TRIGGER
语句的参数。索引从 0 开始记数。非法索引(小于 0 或者大于等于tg_nargs
)会导致返回一个空值。
一个触发器函数必须返回NULL
或者是一个与触发器为之引发的表结构完全相同的记录/行值。
BEFORE
引发的行级触发器可以返回一个空来告诉触发器管理器跳过对该行剩下的操作(即后续的触发器将不再被引发,并且不会对该行发生INSERT
/UPDATE
/DELETE
)。如果返回了一个非空值,那么对该行值会继续操作。返回不同于原始NEW
的行值将修改将要被插入或更新的行。因此,如果该触发器函数想要触发动作正常成功而不修改行值,NEW
(或者另一个相等的值)必须被返回。要修改将被存储的行,可以直接在NEW
中替换单一值并且返回修改后的NEW
,或者构建一个全新的记录/行来返回。在一个DELETE
上的前触发器情况下,返回值没有直接效果,但是它必须为非空以允许触发器动作继续下去。注意NEW
在DELETE
触发器中是空值,因此返回它通常没有意义。在DELETE
中的常用方法是返回OLD
.
INSTEAD OF
触发器(总是行级触发器,并且可能只被用于视图)能够返回空来表示它们没有执行任何更新,并且对该行剩余的操作可以被跳过(即后续的触发器不会被引发,并且该行不会被计入外围INSERT
/UPDATE
/DELETE
的行影响状态中)。否则一个非空值应该被返回用以表示该触发器执行了所请求的操作。对于INSERT
和UPDATE
操作,返回值应该是NEW
,触发器函数可能对它进行了修改来支持INSERT RETURNING
和UPDATE RETURNING
(这也将影响被传递给任何后续触发器的行值,或者被传递给带有ON CONFLICT DO UPDATE
的INSERT
语句中一个特殊的EXCLUDED
别名引用)。对于DELETE
操作,返回值应该是OLD
。
一个AFTER
行级触发器或一个BEFORE
或AFTER
语句级触发器的返回值总是会被忽略,它可能也是空。不过,任何这些类型的触发器可能仍会通过抛出一个错误来中止整个操作。
一个触发器函数的例子:
这个例子触发器保证:任何时候一个行在表中被插入或更新时,当前用户名和时间也会被标记在该行中。并且它会检查给出了一个雇员的姓名以及薪水是一个正值。
1CREATE TABLE emp (
2 empname text,
3 salary integer,
4 last_date timestamp,
5 last_user text
6);
7
8CREATE FUNCTION emp_stamp() RETURNS trigger AS $emp_stamp$
9 BEGIN
10 -- 检查给出了 empname 以及 salary
11 IF NEW.empname IS NULL THEN
12 RAISE EXCEPTION 'empname cannot be null';
13 END IF;
14 IF NEW.salary IS NULL THEN
15 RAISE EXCEPTION '% cannot have null salary', NEW.empname;
16 END IF;
17
18 -- 谁会倒贴钱为我们工作?
19 IF NEW.salary < 0 THEN
20 RAISE EXCEPTION '% cannot have a negative salary', NEW.empname;
21 END IF;
22
23 -- 记住谁在什么时候改变了工资单
24 NEW.last_date := current_timestamp;
25 NEW.last_user := current_user;
26 RETURN NEW;
27 END;
28$emp_stamp$ LANGUAGE plpgsql;
29
30CREATE TRIGGER emp_stamp BEFORE INSERT OR UPDATE ON emp
31 FOR EACH ROW EXECUTE FUNCTION emp_stamp();
另一种记录对表的改变的方法涉及到创建一个新表来为每一个发生的插入、更新或删除保持一行。这种方法可以被认为是对一个表的改变的审计。例 43.4展示了PL/pgSQL中一个审计触发器函数的例子。
一个用于审计的 PL/pgSQL 触发器函数
这个例子触发器保证了在emp
表上的任何插入、更新或删除一行的动作都被记录(即审计)在emp_audit
表中。当前时间和用户名会被记录到行中,还有在其上执行的操作类型。
1CREATE TABLE emp (
2 empname text NOT NULL,
3 salary integer
4);
5
6CREATE TABLE emp_audit(
7 operation char(1) NOT NULL,
8 stamp timestamp NOT NULL,
9 userid text NOT NULL,
10 empname text NOT NULL,
11 salary integer
12);
13
14CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
15 BEGIN
16 --
17 -- 在 emp_audit 中创建一行来反映 emp 上执行的动作,
18 -- 使用特殊变量 TG_OP 来得到操作。
19 --
20 IF (TG_OP = 'DELETE') THEN
21 INSERT INTO emp_audit SELECT 'D', now(), user, OLD.*;
22 ELSIF (TG_OP = 'UPDATE') THEN
23 INSERT INTO emp_audit SELECT 'U', now(), user, NEW.*;
24 ELSIF (TG_OP = 'INSERT') THEN
25 INSERT INTO emp_audit SELECT 'I', now(), user, NEW.*;
26 END IF;
27 RETURN NULL; -- 因为这是一个 AFTER 触发器,结果被忽略
28 END;
29$emp_audit$ LANGUAGE plpgsql;
30
31CREATE TRIGGER emp_audit
32AFTER INSERT OR UPDATE OR DELETE ON emp
33 FOR EACH ROW EXECUTE FUNCTION process_emp_audit();
34
前一个例子的一种变体使用一个视图将主表连接到审计表来展示每一项最后被修改是什么时间。这种方法还是记录了对于表修改的完整审查跟踪,但是也提供了审查跟踪的一个简化视图,只为每一个项显示从审查跟踪生成的最后修改时间戳。例 43.5展示了在PL/pgSQL中一个视图上审计触发器的例子。
一个用于审计的 PL/pgSQL 视图触发器函数
这个例子在视图上使用了一个触发器让它变得可更新,并且确保视图中一行的任何插入、更新或删除被记录(即审计)在emp_audit
表中。当前时间和用户名会被与执行的操作类型一起记录,并且该视图会显示每一行的最后修改时间。
1CREATE TABLE emp (
2 empname text PRIMARY KEY,
3 salary integer
4);
5
6CREATE TABLE emp_audit(
7 operation char(1) NOT NULL,
8 userid text NOT NULL,
9 empname text NOT NULL,
10 salary integer,
11 stamp timestamp NOT NULL
12);
13
14CREATE VIEW emp_view AS
15 SELECT e.empname,
16 e.salary,
17 max(ea.stamp) AS last_updated
18 FROM emp e
19 LEFT JOIN emp_audit ea ON ea.empname = e.empname
20 GROUP BY 1, 2;
21
22CREATE OR REPLACE FUNCTION update_emp_view() RETURNS TRIGGER AS $$
23 BEGIN
24 --
25 -- 执行 emp 上所要求的操作,并且在 emp_audit 中创建一行来反映对 emp 的改变。
26 --
27 IF (TG_OP = 'DELETE') THEN
28 DELETE FROM emp WHERE empname = OLD.empname;
29 IF NOT FOUND THEN RETURN NULL; END IF;
30
31 OLD.last_updated = now();
32 INSERT INTO emp_audit VALUES('D', user, OLD.*);
33 RETURN OLD;
34 ELSIF (TG_OP = 'UPDATE') THEN
35 UPDATE emp SET salary = NEW.salary WHERE empname = OLD.empname;
36 IF NOT FOUND THEN RETURN NULL; END IF;
37
38 NEW.last_updated = now();
39 INSERT INTO emp_audit VALUES('U', user, NEW.*);
40 RETURN NEW;
41 ELSIF (TG_OP = 'INSERT') THEN
42 INSERT INTO emp VALUES(NEW.empname, NEW.salary);
43
44 NEW.last_updated = now();
45 INSERT INTO emp_audit VALUES('I', user, NEW.*);
46 RETURN NEW;
47 END IF;
48 END;
49$$ LANGUAGE plpgsql;
50
51CREATE TRIGGER emp_audit
52INSTEAD OF INSERT OR UPDATE OR DELETE ON emp_view
53 FOR EACH ROW EXECUTE FUNCTION update_emp_view();
54
触发器的一种用法是维护一个表的另一个汇总表。作为结果的汇总表可以用来在特定查询中替代原始表 — 通常会大量减少运行时间。这种技术常用于数据仓库中,在其中被度量或被观察数据的表(称为事实表)可能会极度大。例 43.6展示了PL/pgSQL中一个为数据仓库事实表维护汇总表的触发器函数的例子。
一个 PL/pgSQL 用于维护汇总表的触发器函数
这里详述的模式有一部分是基于 Ralph Kimball 所作的The Data Warehouse Toolkit中的Grocery Store例子。
1--
2-- 主表 - 时间维度和销售事实。
3--
4CREATE TABLE time_dimension (
5 time_key integer NOT NULL,
6 day_of_week integer NOT NULL,
7 day_of_month integer NOT NULL,
8 month integer NOT NULL,
9 quarter integer NOT NULL,
10 year integer NOT NULL
11);
12CREATE UNIQUE INDEX time_dimension_key ON time_dimension(time_key);
13
14CREATE TABLE sales_fact (
15 time_key integer NOT NULL,
16 product_key integer NOT NULL,
17 store_key integer NOT NULL,
18 amount_sold numeric(12,2) NOT NULL,
19 units_sold integer NOT NULL,
20 amount_cost numeric(12,2) NOT NULL
21);
22CREATE INDEX sales_fact_time ON sales_fact(time_key);
23
24--
25-- 汇总表 - 按时间汇总销售
26--
27CREATE TABLE sales_summary_bytime (
28 time_key integer NOT NULL,
29 amount_sold numeric(15,2) NOT NULL,
30 units_sold numeric(12) NOT NULL,
31 amount_cost numeric(15,2) NOT NULL
32);
33CREATE UNIQUE INDEX sales_summary_bytime_key ON sales_summary_bytime(time_key);
34
35--
36-- 在 UPDATE、INSERT、DELETE 时修改汇总列的函数和触发器。
37--
38CREATE OR REPLACE FUNCTION maint_sales_summary_bytime() RETURNS TRIGGER
39AS $maint_sales_summary_bytime$
40 DECLARE
41 delta_time_key integer;
42 delta_amount_sold numeric(15,2);
43 delta_units_sold numeric(12);
44 delta_amount_cost numeric(15,2);
45 BEGIN
46
47 -- 算出增量/减量数。
48 IF (TG_OP = 'DELETE') THEN
49
50 delta_time_key = OLD.time_key;
51 delta_amount_sold = -1 * OLD.amount_sold;
52 delta_units_sold = -1 * OLD.units_sold;
53 delta_amount_cost = -1 * OLD.amount_cost;
54
55 ELSIF (TG_OP = 'UPDATE') THEN
56
57 -- 禁止更改 the time_key 的更新-
58 -- (可能不会太麻烦,因为大部分的更改是用 DELETE + INSERT 完成的)。
59 IF ( OLD.time_key != NEW.time_key) THEN
60 RAISE EXCEPTION 'Update of time_key : % -> % not allowed',
61 OLD.time_key, NEW.time_key;
62 END IF;
63
64 delta_time_key = OLD.time_key;
65 delta_amount_sold = NEW.amount_sold - OLD.amount_sold;
66 delta_units_sold = NEW.units_sold - OLD.units_sold;
67 delta_amount_cost = NEW.amount_cost - OLD.amount_cost;
68
69 ELSIF (TG_OP = 'INSERT') THEN
70
71 delta_time_key = NEW.time_key;
72 delta_amount_sold = NEW.amount_sold;
73 delta_units_sold = NEW.units_sold;
74 delta_amount_cost = NEW.amount_cost;
75
76 END IF;
77
78
79 -- 插入或更新带有新值的汇总行。
80 <<insert_update>>
81 LOOP
82 UPDATE sales_summary_bytime
83 SET amount_sold = amount_sold + delta_amount_sold,
84 units_sold = units_sold + delta_units_sold,
85 amount_cost = amount_cost + delta_amount_cost
86 WHERE time_key = delta_time_key;
87
88 EXIT insert_update WHEN found;
89
90 BEGIN
91 INSERT INTO sales_summary_bytime (
92 time_key,
93 amount_sold,
94 units_sold,
95 amount_cost)
96 VALUES (
97 delta_time_key,
98 delta_amount_sold,
99 delta_units_sold,
100 delta_amount_cost
101 );
102
103 EXIT insert_update;
104
105 EXCEPTION
106 WHEN UNIQUE_VIOLATION THEN
107 -- 什么也不做
108 END;
109 END LOOP insert_update;
110
111 RETURN NULL;
112
113 END;
114$maint_sales_summary_bytime$ LANGUAGE plpgsql;
115
116CREATE TRIGGER maint_sales_summary_bytime
117AFTER INSERT OR UPDATE OR DELETE ON sales_fact
118 FOR EACH ROW EXECUTE FUNCTION maint_sales_summary_bytime();
119
120INSERT INTO sales_fact VALUES(1,1,1,10,3,15);
121INSERT INTO sales_fact VALUES(1,2,1,20,5,35);
122INSERT INTO sales_fact VALUES(2,2,1,40,15,135);
123INSERT INTO sales_fact VALUES(2,3,1,10,1,13);
124SELECT * FROM sales_summary_bytime;
125DELETE FROM sales_fact WHERE product_key = 1;
126SELECT * FROM sales_summary_bytime;
127UPDATE sales_fact SET units_sold = units_sold * 2;
128SELECT * FROM sales_summary_bytime;
129
AFTER
也可以利用传递表来观察被触发语句更改的整个行集合。CREATE TRIGGER
命令会为一个或者两个传递表分配名字,然后函数可以引用那些名字,就好像它们是只读的临时表一样。例 43.7展示了一个例子。
用传递表进行审计
这个例子产生和例 43.4相同的结果,但并未使用一个为每一行都触发的触发器,而是在把相关信息收集到一个传递表中之后用了一个只为每个语句引发一次的触发器。当调用语句修改了很多行时,这种方法明显比行触发器方法快。注意我们必须为每一种事件建立一个单独的触发器声明,因为每种情况的REFERENCING
子句必须不同。但是这并不能阻止我们使用单一的触发器函数(实际上,使用三个单独的函数会更好,因为可以避免在TG_OP
上的运行时测试)。
1CREATE TABLE emp (
2 empname text NOT NULL,
3 salary integer
4);
5
6CREATE TABLE emp_audit(
7 operation char(1) NOT NULL,
8 stamp timestamp NOT NULL,
9 userid text NOT NULL,
10 empname text NOT NULL,
11 salary integer
12);
13
14CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
15 BEGIN
16 --
17 -- 在emp_audit中创建行来反映在emp上执行的操作,
18 -- 利用特殊变量TG_OP来区分操作。
19 --
20 IF (TG_OP = 'DELETE') THEN
21 INSERT INTO emp_audit
22 SELECT 'D', now(), user, o.* FROM old_table o;
23 ELSIF (TG_OP = 'UPDATE') THEN
24 INSERT INTO emp_audit
25 SELECT 'U', now(), user, n.* FROM new_table n;
26 ELSIF (TG_OP = 'INSERT') THEN
27 INSERT INTO emp_audit
28 SELECT 'I', now(), user, n.* FROM new_table n;
29 END IF;
30 RETURN NULL; -- 由于这是一个AFTER触发器,所以结果被忽略
31 END;
32$emp_audit$ LANGUAGE plpgsql;
33
34CREATE TRIGGER emp_audit_ins
35 AFTER INSERT ON emp
36 REFERENCING NEW TABLE AS new_table
37 FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
38CREATE TRIGGER emp_audit_upd
39 AFTER UPDATE ON emp
40 REFERENCING OLD TABLE AS old_table NEW TABLE AS new_table
41 FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
42CREATE TRIGGER emp_audit_del
43 AFTER DELETE ON emp
44 REFERENCING OLD TABLE AS old_table
45 FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
46
事件触发器
PL/pgSQL可以被用来定义事件触发器。PostgreSQL要求一个可以作为事件触发器调用的函数必须被声明为没有参数并且返回类型为event_trigger
。
当一个PL/pgSQL函数被作为一个事件触发器调用,在顶层块中会自动创建一些特殊变量。它们是:
TG_EVENT数据类型是
text
;它是一个表示引发触发器的事件的字符串。TG_TAG数据类型是
text
;它是一个变量,包含了该触发器为之引发的命令标签。PL/pgSQL中一个事件触发器函数的例子。 这个例子触发器在受支持命令每一次被执行时会简单地抛出一个
NOTICE
消息。
1CREATE OR REPLACE FUNCTION snitch() RETURNS event_trigger AS $$
2BEGIN
3 RAISE NOTICE 'snitch: % %', tg_event, tg_tag;
4END;
5$$ LANGUAGE plpgsql;
6
7CREATE EVENT TRIGGER snitch ON ddl_command_start EXECUTE FUNCTION snitch();
6.5 存储过程与函数区别
PostgreSQL 11 版本一个重量级新特性是对存储过程的支持,同时支持存储过程嵌入事务
尽管PostgreSQL提供函数可以实现大多数存储过程的功能,但函数不支持部分提交。而存储过程可以实现
1create table t2 (id int, col2 varchar(64));
2CREATE OR REPLACE PROCEDURE p_insert_data2(id integer, name character varying)
3AS $$
4BEGIN
5 INSERT INTO public.t2 VALUES (id, name);
6 if id % 2 = 0 then
7 commit;
8 else
9 rollback;
10 end if;
11END;
12$$ LANGUAGE plpgsql;
13
14call p_insert_data2(5, 'jkdalsjfd');
15call p_insert_data2(6, 'jkdalsjfd');
16
17CREATE OR REPLACE function f_insert_data2(id integer, name character varying) returns integer
18AS $$
19BEGIN
20 INSERT INTO public.t2 VALUES (id, name);
21 if id % 2 = 0 then
22 commit;
23 else
24 rollback;
25 end if;
26 return id;
27END;
28$$ LANGUAGE plpgsql;
29
30mydb=# select f_insert_data2(1, 'wang');
31ERROR: invalid transaction termination
32CONTEXT: PL/pgSQL function f_insert_data2(integer,character varying) line 7 at ROLLBACK
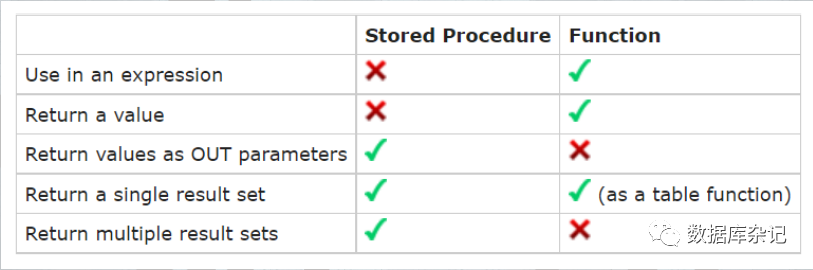
6.6 函数的调试插件或工具
plpgsql_check:主动检查、被动检查 (参考:digoal/blog/202008/20200814_02.md)
pldbgapi:调试函数
pldebugger:调试函数
piggly:plpgsql 代码覆盖测试工具
pg_linegazer:Transparent code coverage for PL/pgSQL,针对PLPGSQL的TDE
pgora-osql:oracle pl/sql 代码兼容插件, 类似plpgsql一样, 作为PG的一种新的存储过 程语言.
plprofiler:类perf火焰图,分析慢code
6.7 WITH使用(Common Table Expressions, CTE)
公共表表达式是一种更好的临时表. 用于较大查询的辅助语句. 用于只在一个查询中存在的临时表。在WITH
子句中的每一个辅助语句可以是一个SELECT
、INSERT
、UPDATE
或DELETE
,并且WITH
子句本身也可以被附加到一个主语句,主语句也可以是SELECT
、INSERT
、UPDATE
或DELETE
。 (ref: http://postgres.cn/docs/14/queries-with.html)
WITH中的SELECT
来一个简单的示例:
1WITH t AS (
2 SELECT generate_series(1, 5)
3)
4SELECT * FROM t;
辅助语句t用于取数,然后用于主查询。
WITH
中SELECT
的基本价值是将复杂的查询分解称为简单的部分。一个例子:
1WITH regional_sales AS (
2 SELECT region, SUM(amount) AS total_sales
3 FROM orders
4 GROUP BY region
5), top_regions AS (
6 SELECT region
7 FROM regional_sales
8 WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
9)
10SELECT region,
11 product,
12 SUM(quantity) AS product_units,
13 SUM(amount) AS product_sales
14FROM orders
15WHERE region IN (SELECT region FROM top_regions)
16GROUP BY region, product;
它只显示在高销售区域每种产品的销售总额。WITH
子句定义了两个辅助语句regional_sales
和top_regions
,其中regional_sales
的输出用在top_regions
中而top_regions
的输出用在主SELECT
查询。这个例子可以不用WITH
来书写,但是我们必须要用两层嵌套的子SELECT
。使用这种方法要更简单些。
可选的RECURSIVE
修饰符将WITH
从单纯的句法便利变成了一种在标准SQL中不能完成的特性。通过使用RECURSIVE
,一个WITH
查询可以引用它自己的输出。一个非常简单的例子是计算从1到100的整数合的查询:
WITH RECURSIVE: e.g.
1WITH RECURSIVE t(n) AS (
2 VALUES (1)
3 UNION ALL
4 SELECT n+1 FROM t WHERE n < 100
5)
6SELECT sum(n) FROM t;
7
8zdb-> select sum(n) from t;
9 5050
10(1 row)
一个递归WITH
查询的通常形式总是一个非递归项,然后是UNION
(或者UNION ALL
),再然后是一个递归项,其中只有递归项能够包含对于查询自身输出的引用。
一个实例:
1表testarea:
2CREATE TABLE testarea(id int, name varchar(32), parentid int);
3INSERT INTO testarea VALUES
4(1, '中国', 0),
5(2, '辽宁', 1),
6(3, '山东', 1),
7(4, '沈阳', 2),
8(5, '大连', 2),
9(6, '济南', 3),
10(7, '和平区', 4),
11(8, '沈河区', 4),
12(9, '北京', 1),
13(10, '海淀区', 9),
14(11, '朝阳区', 9),
15(12, '苏家坨', 10);
当id = 7时,想得到完整的地名:中国辽宁沈阳和平区;当id =12时,想得到中国北京海淀区苏家坨。
可以使用查询查到id为7以及以上的所有父节点,如下:
1WITH RECURSIVE r AS (
2 SELECT * FROM testarea WHERE id = 7
3 UNION ALL
4 SELECT a.* FROM testarea a, r WHERE a.id = r.parentid
5)
6SELECT * FROM r ORDER BY id;
7
8mydb-# SELECT * FROM r ORDER BY id;
9 id | name | parentid
10----+--------+----------
11 1 | 中国 | 0
12 2 | 辽宁 | 1
13 4 | 沈阳 | 2
14 7 | 和平区 | 4
15(4 rows)
接下来可以将name字段值进行合并。利用string_agg()函数可以达到目的。如取id=12的完整名称。
1WITH RECURSIVE r AS (
2 SELECT * FROM testarea WHERE id = 12
3 UNION ALL
4 SELECT a.* FROM testarea a, r WHERE a.id = r.parentid
5)
6SELECT string_agg(name, '') FROM (SELECT * FROM r ORDER BY id) t;
7 string_agg
8----------------------
9 中国北京海淀区苏家坨
上边,利用string_agg()将id=12及其所有父结点按序拼接到一起,组成最后的结果。
tablefunc (插件) 扩展
上边的递归语法,可以用类似connect by的形式来表达。为了与Oracle语法兼容,PostgreSQL自带tablefunc扩展。
1create extension tablefunc;
http://postgres.cn/docs/14/tablefunc.html 基本语法 如下:
1connectby ( relname text,
2 keyid_fld text,
3 parent_keyid_fld text
4 [, orderby_fld text ],
5 start_with text,
6 max_depth integer
7 [, branch_delim text ] )
8 →
9setof record
10
11Produces a representation of a hierarchical tree structure.
产生一个层次树结构的表达。
参数解释:
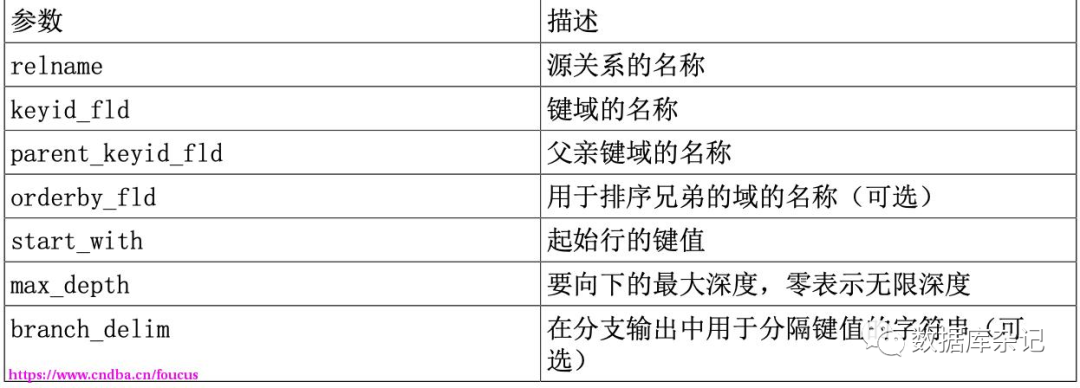
1select * from connectby('testarea', 'id', 'parentid', '1', 0, ',') AS t(keyid int, parent_keyid int, level int, branch text);
2 keyid | parent_keyid | level | branch
3-------+--------------+-------+-----------
4 1 | | 0 | 1
5 2 | 1 | 1 | 1,2
6 4 | 2 | 2 | 1,2,4
7 7 | 4 | 3 | 1,2,4,7
8 8 | 4 | 3 | 1,2,4,8
9 5 | 2 | 2 | 1,2,5
10 3 | 1 | 1 | 1,3
11 6 | 3 | 2 | 1,3,6
12 9 | 1 | 1 | 1,9
13 10 | 9 | 2 | 1,9,10
14 12 | 10 | 3 | 1,9,10,12
15 11 | 9 | 2 | 1,9,11
16(12 rows)
WITH中的DML语句
你可以在WITH
中使用数据修改语句(INSERT
、UPDATE
或DELETE
)。这允许你在同一个查询中执行多个不同操作。一个例子:
1WITH moved_rows AS (
2 DELETE FROM products
3 WHERE
4 "date" >= '2010-10-01' AND
5 "date" < '2010-11-01'
6 RETURNING *
7)
8INSERT INTO products_log
9SELECT * FROM moved_rows;
这个查询实际上将products
中的行移动到products_log
。WITH
中的DELETE
删除来自products
的指定行,以RETURNING
子句返回被删除的内容,然后主查询读该输出并将它插入到products_log
。
WITH
中的子语句和其他子语句以及主查询被并发执行。因此在使用WITH
中的数据修改语句时,无法预知实际更新顺序。所有的语句都使用同一个snapshot执行(参见第 13 章),因此它们不能“看见”目标表上另一个执行的效果。这减轻了行更新的实际顺序的不可预见性的影响,并且意味着RETURNING
数据是在不同WITH
子语句和主查询之间传达改变的唯一方法。其例子
1WITH t AS (
2 UPDATE products SET price = price * 1.05
3 RETURNING *
4)
5SELECT * FROM products;
外层SELECT
可以返回在UPDATE
动作之前的原始价格,而在
1WITH t AS (
2 UPDATE products SET price = price * 1.05
3 RETURNING *
4)
5SELECT * FROM t;
外部SELECT
将返回更新过的数据。
6.8 窗口函数
PG从8.4开始支持窗口函数。在Oracle中叫分析函数。属于几个高级使用特性之一。Window functions提供了跨越与当前查询行相关的行集执行计算的能力。
窗口函数特点
PostgreSQL从8.4开始支持窗口函数
不同RDBMS系统中的名称
– Oracle - 分析函数
– Microsoft SQL SERVER – 开窗函数
– DB2 - OLAP函数
– MySQL – 窗口函数
窗口函数的语法
一个窗口函数调用表示在一个查询选择的行的某个部分上应用一个聚集函数。和非窗口聚集函数调用不同,这不会被约束为将被选择的行分组为一个单一的输出行 — 在查询输出中每一个行仍保持独立。不过,窗口函数能够根据窗口函数调用的分组声明(
PARTITION BY
列表)访问属于当前行所在分组中的所有行。一个窗口函数调用的语法是下列之一:1function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER window_name
2function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
3function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER window_name
4function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )其中
window_definition
的语法是1[ existing_window_name ]
2[ PARTITION BY expression [, ...] ]
3[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
4[ frame_clause ]可选的
frame_clause
是下列之一1{ RANGE | ROWS | GROUPS } frame_start [ frame_exclusion ]
2{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end [ frame_exclusion ]其中
frame_start
和frame_end
可以是下面形式中的一种1UNBOUNDED PRECEDING
2offset PRECEDING
3CURRENT ROW
4offset FOLLOWING
5UNBOUNDED FOLLOWING而
frame_exclusion
可以是下列之一1EXCLUDE CURRENT ROW
2EXCLUDE GROUP
3EXCLUDE TIES
4EXCLUDE NO OTHERS这里,
expression
表示任何自身不含有窗口函数调用的值表达式。 refer: http://postgres.cn/docs/14/sql-expressions.html#SYNTAX-WINDOW-FUNCTIONSOVER,PARTITION BY,ORDER BY
– OVER子句决定如何将查询的行进行拆分以便给窗口函数处理
– OVER子句内的PARTITION BY列表指定将行划分成组或分区, 组或分区共享相同的 PARTITION BY表达式的值
– OVER内的ORDER BY来控制行的顺序
窗口函数的使用特点
– 在和当前行相关的一组表行上执行计算
– 窗口函数总是在语句的最后才执行
– 可以对窗口函数使用聚合函数和排名函数
– 聚合函数每个分组返回唯一行,而窗口函数每个分组返回多行
– 窗口函数只能在SELECT列或者查询语句中的ORDER BY子句中
– 包含DISTINCT子句的聚合函数不能作为窗口函数 ERROR: DISTINCT is not implemented for window functions
通用窗口函数
11. row_number` () → `bigint
返回其分区内的当前行数,从1开始计数。
12. rank` () → `bigint
返回当前行的排名,包含间隔; 即对等组中第一行的row_number
。
13. dense_rank` () → `bigint
返回当前行的排名,不包括间隔;这个功能有效地计数对等组。
14. percent_rank` () → `double precision
返回当前行的相对排名,即(rank
- 1) (总的分区行数 - 1)。因此,该值的范围从0到1(包含在内)。
15. cume_dist` () → `double precision
返回累积分布,也就是(当前行之前或对等的分区行数)/(总的分区行数)。取值范围为1/N
到 1。
16. ntile` ( *`num_buckets`* `integer` ) → `integer
返回一个从1到参数值的整数,并将分区划分为尽可能相等的值。
17. lag` ( *`value`* `anyelement` [, *`offset`* `integer` [, *`default`* `anyelement` ]] ) → `anyelement
返回分区中在当前行之前offset
行的value
;如果没有这样的行,则返回default
(必须与value
具有相同的类型)。 offset
和default
都是针对当前行求值的。如果省略,offset
默认为1,default
为NULL
。
18. lead` ( *`value`* `anyelement` [, *`offset`* `integer` [, *`default`* `anyelement` ]] ) → `anyelement
返回分区中在当前行之后offset
行的value
; 如果没有这样的行,则返回default
(必须与value
具有相同的类型)。 offset
和default
都是针对当前行求值的。如果省略,offset
默认为1,default
为NULL
。
19. first_value` ( *`value`* `anyelement` ) → `anyelement
返回在窗口框架的第一行求得的value
。
110. last_value` ( *`value`* `anyelement` ) → `anyelement
返回在窗口框架的最后一行求得的value
。
111. nth_value` ( *`value`* `anyelement`, *`n`* `integer` ) → `anyelement
返回在窗口框架的第n
行求得的value
(从1开始计数);如果没有这样的行,则返回NULL
。
所有函数都依赖于相关窗口定义的ORDER BY
子句指定的排序顺序。 仅考虑ORDER BY
列时不能区分的行被称为是同等行。 定义的这四个排名函数(包括 cume_dist
),对于对等组的所有行的答案相同。
综合示例
1CREATE TABLE empsalary (empno int primary key,
2 depname varchar(64),
3 gender char(1),
4 age int,
5 city varchar(32),
6 manager int,
7 salary int
8);
查询每个员工的工资和在TA的部门的平均薪水
1select empno, depname, salary, avg(salary) over (partition by depname) from empsalary;
2
3empno | depname | salary | avg
4-------+-----------+--------+--------------------
5 11 | develop | 21300 | 17383.333333333333
6 1 | develop | 27000 | 17383.333333333333
7 2 | develop | 10000 | 17383.333333333333
8 3 | develop | 11000 | 17383.333333333333
9 4 | develop | 13000 | 17383.333333333333
10 5 | develop | 22000 | 17383.333333333333
11 0 | global | 55080 | 55080.000000000000
12 7 | personnel | 11500 | 16750.000000000000
13 6 | personnel | 22000 | 16750.000000000000
14 8 | sales | 35000 | 25116.666666666667
15 9 | sales | 20050 | 25116.666666666667
16 10 | sales | 20300 | 25116.666666666667
17(12 rows)
18查询各部门中薪水低于20000的人数(GROUP BY)
1select empno, depname, salary, count(*) over (partition by depname) from empsalary where salary < 20000;
2empno | depname | salary | count
3-------+-----------+--------+-------
4 2 | develop | 10000 | 3
5 3 | develop | 11000 | 3
6 4 | develop | 13000 | 3
7 7 | personnel | 11500 | 1
8(4 rows)基础上按照部门中每个人的薪水降序排列
1select empno, depname, salary, count(*) over (partition by depname) from empsalary where salary < 20000 order by depname, salary desc;
2-------+-----------+--------+-------
3 4 | develop | 13000 | 3
4 3 | develop | 11000 | 3
5 2 | develop | 10000 | 3
6 7 | personnel | 11500 | 1
7(4 rows)
8select empno, depname, salary, count(*) over (partition by depname order by salary desc) from empsalary where salary < 20000;
9empno | depname | salary | count
10-------+-----------+--------+-------
11 4 | develop | 13000 | 1
12 3 | develop | 11000 | 2
13 2 | develop | 10000 | 3
14 7 | personnel | 11500 | 1
15(4 rows)
16
17加上行号:员工在各部门薪水降序排名
1SELECT empno, depname, salary, rank() over (partition by depname order by salary desc) from empsalary;
2empno | depname | salary | rank
3-------+-----------+--------+------
4 1 | develop | 27000 | 1
5 5 | develop | 22000 | 2
6 11 | develop | 21300 | 3
7 4 | develop | 13000 | 4
8 3 | develop | 11000 | 5
9 2 | develop | 10000 | 6
10 0 | global | 55080 | 1
11 6 | personnel | 22000 | 1
12 7 | personnel | 11500 | 2
13 8 | sales | 35000 | 1
14 10 | sales | 20300 | 2
15 9 | sales | 20050 | 3
16(12 rows)
17
18rank函数并不总是返回连续整数,而dense_rank函数始终具有连续的排名。例如头两位雇员的薪水一样多,他们的rank和dense_rank 都为1,但薪水仅次于他们的雇员dense_rank为2,而rank则会为3按薪水降序排序,并计与上(下)一位的薪水差额
1select empno, depname, salary, (salary - lag(salary) OVER(PARTITION BY depname ORDER BY salary DESC)) from empsalary;
2empno | depname | salary | ?column?
3-------+-----------+--------+----------
4 1 | develop | 27000 |
5 5 | develop | 22000 | -5000
6 11 | develop | 21300 | -700
7 4 | develop | 13000 | -8300
8 3 | develop | 11000 | -2000
9 2 | develop | 10000 | -1000
10 0 | global | 55080 |
11 6 | personnel | 22000 |
12 7 | personnel | 11500 | -10500
13 8 | sales | 35000 |
14 10 | sales | 20300 | -14700
15 9 | sales | 20050 | -250
16(12 rows)按部门分组,按薪水排序,并计算比最高薪水和最低薪水的差额
1select empno, depname, salary, (salary - first_value(salary) OVER w), (salary - last_value(salary) OVER w) from empsalary window w as (partition by depname order by salary desc);
2empno | depname | salary | ?column? | ?column?
3-------+-----------+--------+----------+----------
4 1 | develop | 27000 | 0 | 0
5 5 | develop | 22000 | -5000 | 0
6 11 | develop | 21300 | -5700 | 0
7 4 | develop | 13000 | -14000 | 0
8 3 | develop | 11000 | -16000 | 0
9 2 | develop | 10000 | -17000 | 0
10 0 | global | 55080 | 0 | 0
11 6 | personnel | 22000 | 0 | 0
12 7 | personnel | 11500 | -10500 | 0
13 8 | sales | 35000 | 0 | 0
14 10 | sales | 20300 | -14700 | 0
15 9 | sales | 20050 | -14950 | 0
16(12 rows)注意
first_value
、last_value
和nth_value
只考虑“窗口帧”内的行,它默认情况下包含从分区的开始行直到当前行的最后一个同等行。 这对last_value
可能不会给出有用的结果,有时对nth_value
也一样。 你可以通过向OVER
子句增加一个合适的帧声明(RANGE
或GROUPS
)来重定义帧。
SQL 标准为
lead
、lag
、first_value
、last_value
和nth_value
定义了一个RESPECT NULLS
或IGNORE NULLS
选项。 这在PostgreSQL中没有实现:行为总是与标准的默认相同,即RESPECT NULLS
。 同样,标准中用于nth_value
的FROM FIRST
或FROM LAST
选项没有实现:只有支持默认的FROM FIRST
行为(你可以通过反转ORDER BY
的排序达到FROM LAST
的结果)。
row_number(), rank(), dense_rank() 排名的细微区别
1CREATE TABLE score(id serial primary key,
2 subject varchar(64),
3 student varchar(32),
4 score int
5);
6
7insert into score (subject, student, score) values
8('Chinese', 'Rob', 70),
9('Chinese', 'Leon', 70),
10('Chinese', 'Lucy', 80),
11('Chinese', 'Jane', 65),
12('Math', 'Rob', 80),
13('Math', 'Leon', 99),
14('Math', 'Lucy', 65),
15('Math', 'Jane', 83),
16('English', 'Rob', 90),
17('English', 'Leon', 75),
18('English', 'Lucy', 90),
19('English', 'Jane', 60);
20
21-- row_number(), rank(), dense_rank() 排名
22-- 一直连续,值递增
23select row_number() over (partition by subject order by score desc), * from score;
24-- 可以相同,有断值
25select rank() over (partition by subject order by score desc), * from score;
26-- 可以相同,值连续
27select dense_rank() over (partition by subject order by score desc), * from score;参考:
[1] https://www.postgresql.org/docs/15/sql.html
