




PostgreSQL SQL的基础使用及技巧
基本目录
1、数据类型总体介绍
2、简单查询
2.1、标识符及关键字、常量的转义
3、简单SQL
3.1、基础SQL
4、数据类型(Basic)
4.1、Boolean型
4.2、case when, then, else ,end
4.3、nullif与coalesce
4.4、模式匹配:
4.5、字符串类型
4.6、数值型
4.7、序列函数
4.8、日期/时间类型
4.9、数组类型
4.10、域和组合类型(domain, composite)
4.11、聚集函数
4.12、设置返回集合函数
4.13、Object ID (oid Type)
4.14、约束
4.15、Unique Key的生成
5、数据类型(Advanced)
5.1、二进制数据类型(bytea)
5.2、位串类型
5.3、枚举类型
5.4、几何类型
5.5、网络地址类型
5.6、XML类型
5.7、JSON类型
5.8、Range(范围类型)
5.9、复合类型
5.10、伪类型
6、使用视图
7、建立数据库用户
8、用户授权及角色管理
7.1、 普通授权
7.2、引入schema
7.3、表和列权限解读
9、索引
1、数据类型总体介绍
refer to: https://www.postgresql.org/docs/14/datatype.html
| Name | Aliases | Description |
|---|---|---|
bigint | int8 | signed eight-byte integer |
bigserial | serial8 | autoincrementing eight-byte integer |
bit [ (*n *) ] | fixed-length bit string | |
bit varying [ (*n *) ] | varbit [ (*n *) ] | variable-length bit string |
boolean | bool | logical Boolean (true/false) |
box | rectangular box on a plane | |
bytea | binary data (“byte array”) | |
character [ (*n *) ] | char [ (*n *) ] | fixed-length character string |
character varying [ (*n *) ] | varchar [ (*n *) ] | variable-length character string |
cidr | IPv4 or IPv6 network address | |
circle | circle on a plane | |
date | calendar date (year, month, day) | |
double precision | float8 | double precision floating-point number (8 bytes) |
inet | IPv4 or IPv6 host address | |
integer | int, int4 | signed four-byte integer |
interval [ *fields * ] [ (*p *) ] | time span | |
json | textual JSON data | |
jsonb | binary JSON data, decomposed | |
line | infinite line on a plane | |
lseg | line segment on a plane | |
macaddr | MAC (Media Access Control) address | |
macaddr8 | MAC (Media Access Control) address (EUI-64 format) | |
money | currency amount | |
numeric [ (*p *, *s *) ] | decimal [ (*p *, *s *) ] | exact numeric of selectable precision |
path | geometric path on a plane | |
pg_lsn | PostgreSQL Log Sequence Number | |
pg_snapshot | user-level transaction ID snapshot | |
point | geometric point on a plane | |
polygon | closed geometric path on a plane | |
real | float4 | single precision floating-point number (4 bytes) |
smallint | int2 | signed two-byte integer |
smallserial | serial2 | autoincrementing two-byte integer |
serial | serial4 | autoincrementing four-byte integer |
text | variable-length character string | |
time [ (*p *) ] [ without time zone ] | time of day (no time zone) | |
time [ (*p *) ] with time zone | timetz | time of day, including time zone |
timestamp [ (*p *) ] [ without time zone ] | date and time (no time zone) | |
timestamp [ (*p *) ] with time zone | timestamptz | date and time, including time zone |
tsquery | text search query | |
tsvector | text search document | |
txid_snapshot | user-level transaction ID snapshot (deprecated; see pg_snapshot) | |
uuid | universally unique identifier | |
xml | XML data |
2、简单查询
2.1、标识符及关键字、常量的转义
关键字
select word from pg_get_keywords();
为避免一些不必要的麻烦,不要用关键字去定义数据库对象的名字。它会给PG的解析造成潜在的问题。尤其是在生产环境中,不要给自己制造麻烦。
转义
$$或者, 之间的串不用转义
internals=> select $$fkjdsafjaf'''<xml][['''\\$$;?column?---------------------------fkjdsafjaf'''<xml][['''\\(1 row)internals=> select $tag$fkjdsafjaf''''''\\$$;$tag$;?column?-----------------------fkjdsafjaf''''''\\$$;(1 row)
E前缀,C风格的转义符
mydb=> select E'\tabcd';?column?--------------abcd
位串常量,二进制使用B前缀,16进制采用X作前缀
mydb=> select B'1001'::int;int4------9mydb=> select X'0B'::int;int4------11
3、简单SQL
3.1、基础SQL
建表
CREATE TABLE table_name ( col_1 data_type, col_2 data_type, … col_n data_type );CREATE TABLE departments(department_id integer primary key,name varchar(50));
删表
DROP TABLE [IF EXISTS] name [, name2, ...] [CASCADE];
更改表
see: https://www.postgresql.org/docs/14/sql-altertable.html
ALTER TABLE [IF EXISTS] name {action}action:ADD [ COLUMN ] [ IF NOT EXISTS ] column_name data_typeDROP [ COLUMN ] [ IF EXISTS ] column_name [ RESTRICT | CASCADE ]ALTER [ COLUMN ] column_name [ SET DATA ] TYPE data_type [ COLLATE collation ] [ USING expression ]ALTER [ COLUMN ] column_name SET DEFAULT expressionALTER [ COLUMN ] column_name DROP DEFAULTALTER [ COLUMN ] column_name { SET | DROP } NOT NULLALTER [ COLUMN ] column_name ADD GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY [ ( sequence_options ) ]CLUSTER ON index_name
插入数据
INSERT INTO table [ ( column [, ...] ) ]{ DEFAULT VALUES | VALUES ( { expression | DEFAULT }[, ...] ) | query }e.g.INSERT INTO departments (department_id, name)VALUES (1, 'Development');-- 插入多行INSERT INTO emp (empno, ename, job) VALUES(2,'JOHN', 'MANAGER'),(3, 'MARY', 'CLERK'),(4, 'HARRY', 'MANAGER');
see: https://vladmihalcea.com/postgresql-multi-row-insert-rewritebatchedinserts-property/
https://jdbc.postgresql.org/documentation/head/connect.html
very important property: reWriteBatchedInserts = true
SELECT数据
SELECT column_1, column_2 , … column_nFROM tableWHERE conditionORDER BY column_listSELECT department_id, nameFROM departmentsWHERE department_id = 1ORDER BY name;
使用列和表别名(alias)
提升复杂SQL语句的可读性
减少代码输入
e.g.SELECT ename, dnameFROM emp e, dept dWHERE e.deptno = d.deptno;
更新数据
UPDATE [ ONLY ] table SET column = {expression | DEFAULT}[,...][ FROM fromlist ][ WHERE condition ]UPDATE departments SET name='DEVELOPMENT'WHERE department_id=1;
删除数据
DELETE FROM [ ONLY ] table [ WHERE condition ]DELETE FROM departments WHERE department_id = 2;TRUNCATE 快速清空表中数据
使用SQL函数
可以在 SELECT 语句以及WHERE 中使用
• 包括
– String Functions – Format Functions – Date & Time Fuctions – Aggregate Functions
例如:
SELECT lower(name) FROM departments;SELECT * FROM departments WHERE lower(name) = 'development';
4、数据类型(Basic)
PostgreSQL 拥有大量的内置的数据类型用来存储不同类型的数据。
标准类型(Standard) – Boolean and Logic – Strings - char(n), varchar(n), varchar2(n) and text – Numbers - integer, floating point, numeric, number – Date/time - timestamp(), date, time(), interval(), datetime 扩展类型(Extended) – Geometric - point, line, box, etc – Network - inet, cidr, macaddr – Bit - bit, bit varying 数组和符合类型(Arrays and Composite types) 系统类型(System types)
4.1、Boolean型
Postgres 提供了标准的SQL类型boolean。boolean 只能有如下两种状态中 的一种: “true” or “false”. 第三种, “unknown”, 可以用SQL null 值表示.
TRUE, 't', 'true', 'y', 'yes', '1’ FALSE, 'f', 'false', 'n', 'no', '0’ 使用关键字 TRUE 和 FALSE 是首选的(它是SQL兼容的( SQL-compliant)).
mydb=> create table t(id int, col2 boolean);CREATE TABLEmydb=> insert into t values(1, 't'), (2, FALSE), (3, 'y'), (4, 'no');INSERT 0 4mydb=> select * from t;id | col2----+------1 | t2 | f3 | t4 | f
关于NULL值,一个重要的开关:transform_null_equals, 默认值 是false.
mydb=> create table t(id int, col2 boolean);CREATE TABLEmydb=> insert into t values(1, 't'), (2, FALSE), (3, 'y'), (4, 'no');INSERT 0 4mydb=> select * from t;id | col2----+------1 | t2 | f3 | t4 | f(4 行记录)mydb=> set transform_null_equals=true;SETmydb=> select * from t where col2=null;id | col2----+------(0 行记录)mydb=> insert into t values(5, null);INSERT 0 1mydb=> select * from t where col2=null;id | col2----+------5 |(1 行记录)mydb=> set transform_null_equals=false;SETmydb=> select * from t where col2=null;id | col2----+------(0 行记录)
将 transform_null_equals 设置为 on 就会使得 x = NULL 转换为 x IS NULL
a IS DISTINCT FROM b 等价于 a != b,除非 a 或 b 有一个为空,那就返回TRUE。如果a和b 都是 null, 他将返回FALSE. 这将使null的比较变的更简单。
4.2、case when, then, else ,end
mydb=> select id, case when col2 then 'col2 is true' else 'col2 is false' end as col from t;id | col----+---------------1 | col2 is true2 | col2 is false3 | col2 is true4 | col2 is false5 | col2 is false(5 行记录)
4.3、nullif与coalesce
coalesce: 取第一个非空值,
NULLIf(a, b)与它相反. 当*value1
和value2
相等时,NULLIF
:如果 a与b相等,返回一个空值。 否则它返回value1
*。
mydb=> select coalesce(null, null, 'default');coalesce----------defaultmydb=> select nullif(2, 1) a, nullif(2, 2) b;a | b---+---2 |(1 行记录)
4.4、模式匹配:
like 或 ~~, ilike 或 ~~*, escape '\_' , escape '\%' 来限制通配符
mydb=> select 'abc' like 'a%', 'abc' ~~ 'a%';?column? | ?column?----------+----------t | tmydb=> select 'abc' ilike 'aB%', 'abc' ~~* 'Ab%';?column? | ?column?----------+----------t | t
通配符:_ 相当于 ?, % 相当于 *
mydb=> insert into t123 values(3, 'abc_%dddd', 'abc_%ddef');INSERT 0 1mydb=> select * from t123;id | col2 | col3----+----------------------------------+-----------1 | abc | abc2 | abc | abc3 | abc_%dddd | abc_%ddef(3 行记录)mydb=> select * from t123 where col2 like 'abc\_%' escape '\';id | col2 | col3----+----------------------------------+-----------3 | abc_%dddd | abc_%ddef(1 行记录)
注意escape的用法. 表示它后边的_是不用作通配的
正则匹配
string ~ regex, ~* : 大小写不敏感, !~, !~*: 不匹配
mydb=> select 'postgres' ~ 'gre';?column?----------t(1 行记录)mydb=> select 'postgres' ~ 'gret';?column?----------f(1 行记录)mydb=> select 'postgres' ~ 'g[a-z]*';?column?----------t(1 行记录)
string [NOT] SIMILAR to pattern [ESCAPE escape-character]
与like类似,用的是like方式的模式匹配
mydb=> select 'postgres' similar to '%g%';?column?----------t
4.5、字符串类型
char(n)类型:
mydb=> create table t123(id int, col2 char(32), col3 varchar(32));CREATE TABLEmydb=> insert into t123 values(1, 'abc', 'abc'), (2, 'abc ', 'abc ');INSERT 0 2mydb=> select * from t123;id | col2 | col3----+----------------------------------+------1 | abc | abc2 | abc | abc(2 行记录)mydb=> select * from t123 where col2='abc';id | col2 | col3----+----------------------------------+------1 | abc | abc2 | abc | abc(2 行记录)mydb=> select * from t123 where col2='abc ';id | col2 | col3----+----------------------------------+------1 | abc | abc2 | abc | abc(2 行记录)
拼接,最大最小值
mydb=> select 'a' || 'b', greatest('a', 'b', 'c'), least('a', 'b', 'c');?column? | greatest | least----------+----------+-------ab | c | a(1 行记录)
大小写及各种长度:
octet_length:字节数, bit_length:位数, char_length, character_length: 相同,都是字符数
mydb=> select upper('a'), lower('ABC'), length('ABC'), character_length('ABC'), char_length('ABC'), octet_length('ABC'), bit_length('ABC');-[ RECORD 1 ]----+----upper | Alower | abclength | 3character_length | 3char_length | 3octet_length | 3bit_length | 24
pad填充: lpad, rpad(string, length[, fill])
mydb=> select lpad('abc', 8, 'd'), rpad('abc', 8, 'xy');lpad | rpad----------+----------dddddabc | abcxyxyx
trim: ltrim, rtrim, btrim(string[, characters])
删除字符串左边或右边或两边的characters字符 (默认是空格)
mydb=> select ltrim('abc','a'), rtrim('abc', 'bc'), btrim(' abcba ', ' ');ltrim | rtrim | btrim-------+-------+-------bc | a | abcba(1 行记录)
position函数: position(substring in string), 对比strpos
mydb=> select position('b' in 'abc');position----------2(1 行记录)mydb=> select strpos('abc', 'b');strpos--------2(1 行记录)
substring函数:
substring(string [ from start][ for run])
substring(string from pattern)
substring(string from pattern for escape)
substr(string, from, count)
mydb=> sELECT substring('EnterpriseDB' from 8 for 5);substring-----------iseDBmydb=> sELECT substring('EnterpriseDB' from 8 );substring-----------iseDB
4.6、数值型
Integers:
– int/integer/int4, smallint/int2, bigint/int8
– bigint 依赖于编译器的支持,因此不一定能在所有的平台上运行。
– bigint, int2, int4 and int8 是 Postgres扩展
Serial:
可以定义列 NOT NULL, serial, biserial, serial4, serial8
mydb=> create table t12(id bigserial, id2 serial, id3 serial8, col2 varchar(32));CREATE TABLEmydb=> \d t12数据表 "public.t12"栏位 | 类型 | 校对规则 | 可空的 | 预设------+-----------------------+----------+----------+----------------------------------id | bigint | | not null | nextval('t12_id_seq'::regclass)id2 | integer | | not null | nextval('t12_id2_seq'::regclass)id3 | bigint | | not null | nextval('t12_id3_seq'::regclass)col2 | character varying(32) | | |mydb=> insert into t12 (col2) values('abc'), ('abcd');INSERT 0 2mydb=> select * from t12;id | id2 | id3 | col2----+-----+-----+------1 | 1 | 1 | abc2 | 2 | 2 | abcdCREATE TABLE s(s serial);NOTICE: CREATE TABLE will create implicit sequence "s_s_seq" for serialcolumn "s.s"\d s...s | integer | not null default nextval('s_s_seq'::regclass)
Floating Point
– real, double precision
– 它依赖于编译器,CPU, 和 OS 支持, 在不同的安装中细节会有不同
– real 通常有 6 位精度,范围至少在 1E-37 和 1E+37之间
– double通常有 15 位精度,范围至少在 1E-307 和 1E+308之间
– 特殊值 : Infinity, -Infinity, NaN
– SQL 标准表示法 float(p) 用于声明一个的数值类型,它以P(二进 制位表示的最低可接受精度,在7.4以前,P是一个十进制的位)。P取值在1到24之间表示一个real的精度,在25到53之间表示 double的精度。如果有其他值将会返回错误。
– 如果没有定义float的precision,等价于 double的precision
Numeric
– 允许是任意 precision (所有位的个数) 和 scale (小数位数)
– 可以存储多达1000位的数值,但非常慢
– numeric(p, s) 定义了最大的 precision (须 > 0) 和最大的 scale (须 >= 0)
– numeric(p)是一个scale为0的 numeric
– 如果在numeric中没有定义任何的 precision 或者 scale,那他将允 许存储任意precision 和 scale的数值。这种形式不会将输入数值强 制转化成任何特定精度的值
– 如果一个要存储的数值的scale比声明的scale大, 那么系统将尝试 四舍五入该数值到指定的scale。如果小数点左边的数据位数超过 了声明的precision减去scale , 那么抛出一个错误。
– 数据在物理存储时其前后不带任何的0
– 允许 NaN
mydb=> create table t1(s numeric, col2 numeric(6,2));CREATE TABLEmydb=> insert into t1 values(487394743789748975979878979.1234155, 1234.12);INSERT 0 1mydb=> select * from t1;s | col2-------------------------------------+---------487394743789748975979878979.1234155 | 1234.12(1 行记录)mydb=> insert into t1 values(134145, 143325.11);ERROR: numeric field overflow描述: A field with precision 6, scale 2 must round to an absolute value less than 10^4.
数值类型操作符
• +, -, *, , % (also mod()), ^ (also power())
• |/ (prefix) square root (also sqrt()) 平方根
• ||/ (prefix) cube root (also cbrt()) 立方根
• ! (suffix), ! – factorial 阶乘• @ (prefix) - absolute value (also abs()) 绝对值
mydb=> SELECT |/ 25, 5 !, @ -5;?column? | ?column? | ?column?----------+----------+----------5 | 120 | 5mydb=# select ||/125, |/625, @ -5, 2^3;?column? | ?column? | ?column? | ?column?----------+----------+----------+----------5 | 25 | 5 | 8(1 row)
数值函数
• ceil/ceiling, floor
• exp (exponential), ln, log
• greatest, least
• random, setseed
• round, truncate
• sign
• to_number
• degrees(radians), radians(degrees)
• cos, acos, sin, asin
• cot (cotangent), tan, atan
• atan2(x, y) = atan(x/y)
4.7、序列函数
• nextval() – 输出 sequence的下一个值
• currval() -输出 sequence的当前值
• setval() –设置 sequence将要输出的下一个值
mydb=> create table t(id serial);CREATE TABLEmydb=> select currval('t_id_seq');ERROR: currval of sequence "t_id_seq" is not yet defined in this sessionmydb=> select nextval('t_id_seq');nextval---------1mydb=> select setval('t_id_seq', 10);setval--------10(1 行记录)mydb=> select nextval('t_id_seq');nextval---------11(1 行记录)mydb=> select currval('t_id_seq');currval---------11
4.8、日期/时间类型
日期/时间类型是最常用的几种数据类型之一,除包括不同日期/时间范围和精度的类 型外,还包括了时间间隔类型。
4.8.1、日期/时间类型介绍
1)、日期/时间类型列表
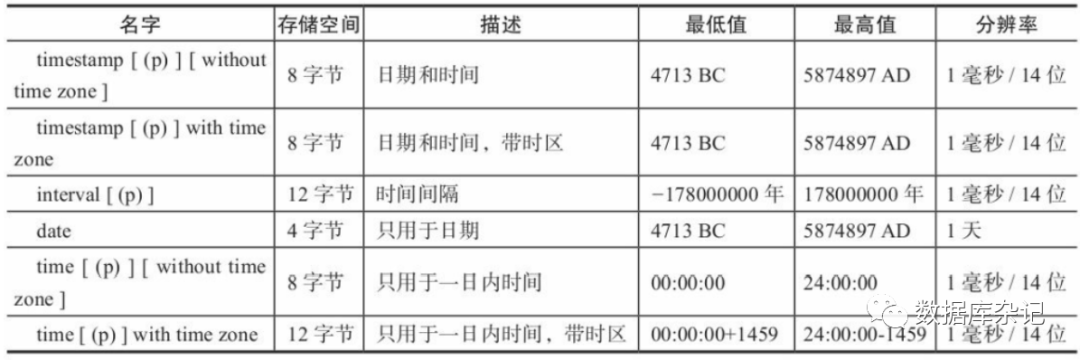
需要注意的是,PostgreSQL中的时间类型可以精确到秒以下,而MySQL中的时间类 型只能精确到秒。time、timestamp、interval接受一个可选的精度值p以指明秒域中小数部 分的位数。如果没有明确的默认精度,对于timestamp和interval类型,p的取值范围是0~6 。
timestamp数值是以双精度浮点数的方式存储的,它以2000-01-01午夜之前或之后的秒 数存储。可以想象,在2000-01-01前后几年的日期中精度是可以达到微秒的,而在更远一 些的日子,精度可能达不到微秒,但达到毫秒是没有问题的。
也可以改变编译选项使timestamp以八字节整数的方式存储,那么微秒的精度就可以 在数值的全部范围内得到保证,不过这样一来八位整数的时间戳范围就缩小到了4713 BC 到294276 AD之间。此外,这个编译选项也决定了time和interval数值是保存成浮点数还是 八字节整数。同样,在以浮点数存储的时候,随着时间间隔的增加,interval数值的精度 也会降低。
4.8.2、日期的输入
在SQL中,任何日期或者时间的文本输入都需要由“日期/时间”类型加单引号括起来 的字符串组成,语法如下:
type [ (p) ] 'value'
日期和时间的输入几乎可以是任何合理的格式,包括ISO-8601格式、SQL-兼容格式 、传统的Postgres格式及其他形式。对于一些格式,日期输入中的月和日可能会使人产生 疑惑,因此系统支持自定义这些字段的顺序。如果DateStyle参数默认为“MDY”,则表示 按“月-日-年”的格式进行解析,如果参数设置为“DMY”,则按照“日-月-年”的格式进行解 析,设置为,“YMD”表示按照“年-月-日”的格式进行解析。示例如下:
internals=> create table tdate(col1 date);CREATE TABLEinternals=> insert into tdate values(date '12-10-2010');INSERT 0 1internals=> select * from tdate;col1------------2010-12-10(1 row)internals=> show datestyle;DateStyle-----------ISO, MDY(1 row)internals=> set datestyle='YMD';SETinternals=> insert into tdate values(date '2010-12-11');INSERT 0 1internals=> select * from tdate;col1------------2010-12-102010-12-11(2 rows)
更多的日期输入示例:
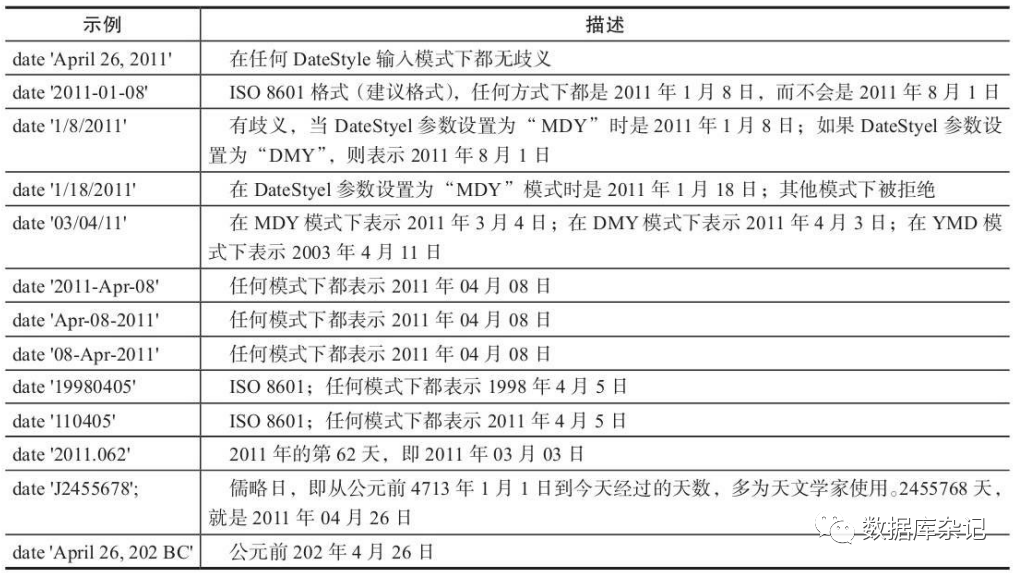
对于中国人来说,使用“/”作为时间和日期分隔符容易产生歧义,最好使用“-”,然后 以“年-月-日”的格式输入日期。
4.8.3、时间输入
输入时间时需要注意时区的输入。time被认为是time without time zone的类型,这样 即使字符串中有时区也会被怱略,示例如下:
internals=> select time '04:05:06';time----------04:05:06(1 row)internals=> select time '04:05:06 PST';time----------04:05:06(1 row)internals=> select time with time zone'04:05:06 PST';timetz-------------04:05:06-08(1 row)
时间字符串可以使用冒号作分隔符,即输入格式为“hh:mm:ss”,如“10:23:45”,也可 以不用分隔符,如“102345”表示10点23分45秒。
更多的时间类型的输入示例:
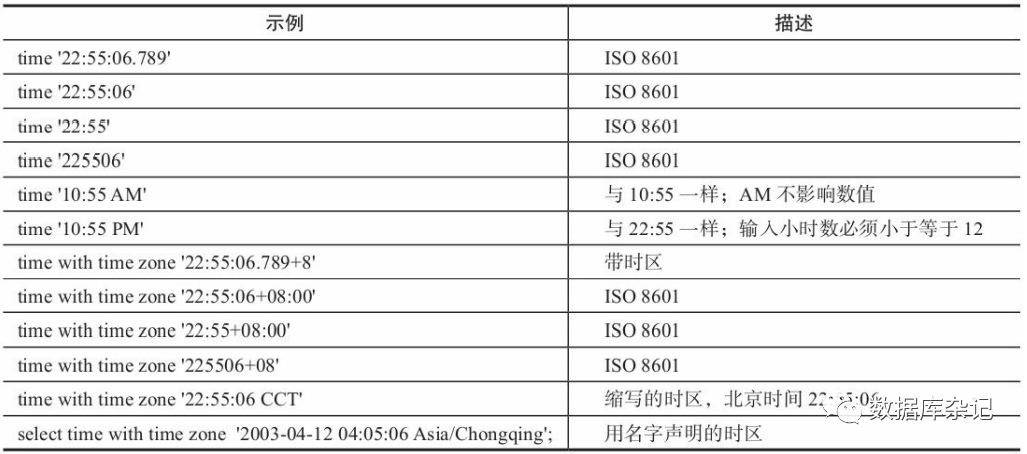
最好不要用时区缩写来表示时区,因为这样有可能给阅读者带来困扰,如CST 时间有可能有以下几种含义:
Central Standard Time (USA) UT-6:00,即美国标准时间 Central Standard Time (Australia) UT+9:30,即澳大利亚标准时间。 China Standard Time UT+8:00,即中国标准时间。 Cuba Standard Time UT-4:00,即古巴标准时间。
这么多的时区都叫CST,是不是让人困惑?CST在PostgreSQL中代表Central Standard Time (USA) UT-6:00,缩写可以查询视图“pg_timezone_abbrevs”:
internals=> select * from pg_timezone_abbrevs where abbrev='CST';abbrev | utc_offset | is_dst--------+------------+--------CST | -06:00:00 | f(1 row)
在输入的时间后加“AT TIME ZONE”可以转换或指定时区:
internals=> SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40-05' AT TIME ZONE '+08:00';timezone---------------------2001-02-16 17:38:40(1 row)
4.8.4、特殊值
为方便起见,PostgreSQL中用了一些特殊的字符串输入值表示特定的意义。
日期时间输入的特殊值
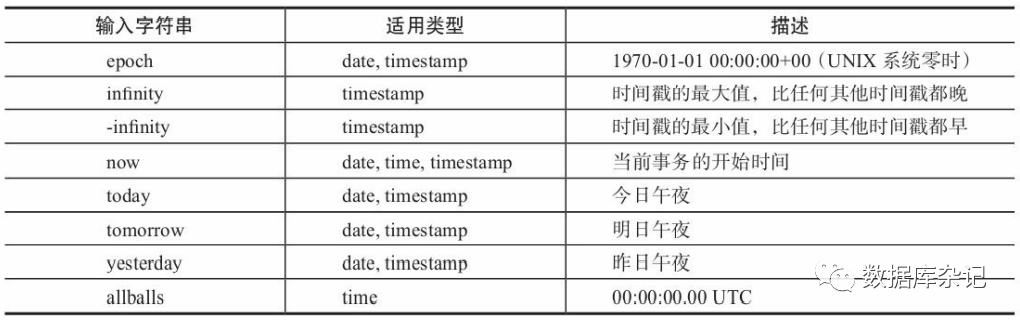
4.8.5、函数和操作符列表
日期、时间和inteval类型数值之间可以进行加减乘除运算,具体见表
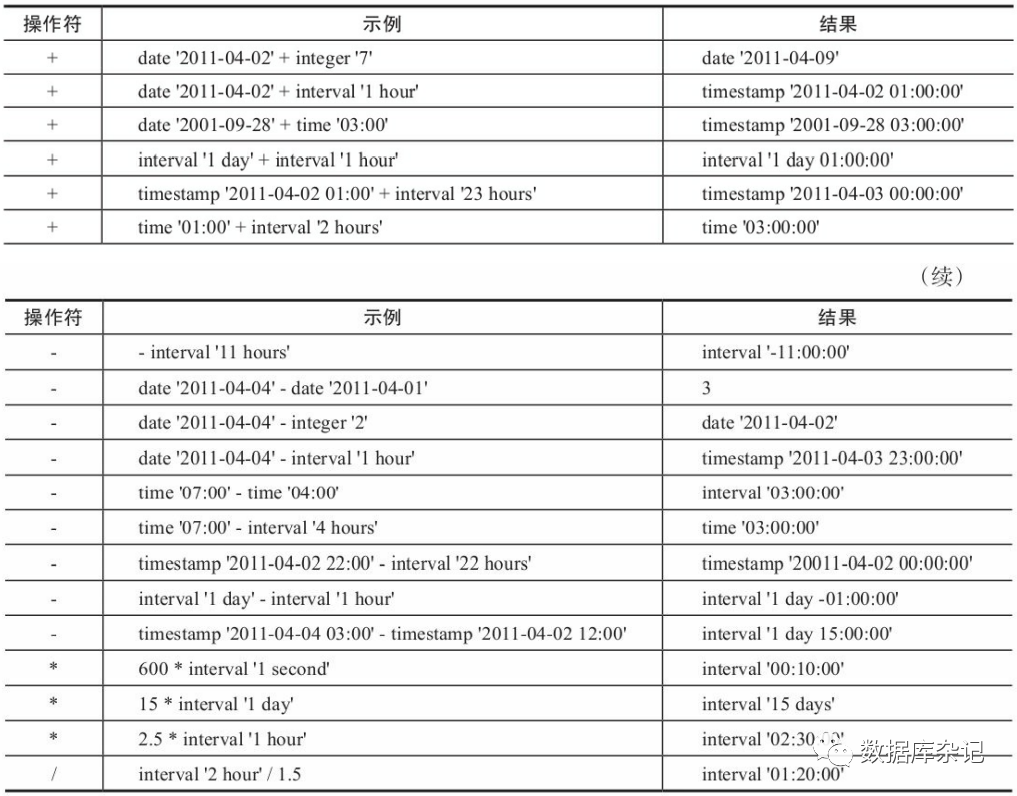
日期、时间和inteval类型的函数见后表。
除了以上函数以外,PostgreSQL还支持SQL的OVERLAPS操作符,如下:
(start1, end1) OVERLAPS (start2, end2)(start1, length1) OVERLAPS (start2, length2)
上面的表达式在两个时间域(用它们的终点定义)重叠的时候生成真值。终点可以用 一对日期、时间、时间戳来声明;或者是后面跟着一个表示时间间隔的日期、时间、时间 戳,示例如下:
internals=> SELECT (DATE'2001-02-16',DATE'2001-12-21') OVERLAPS (DATE'2001-10-30',DATE'2002-10-30');overlaps----------t(1 row)internals=> SELECT (DATE'2001-02-16',INTERVAL'100days') OVERLAPS (DATE'2001-10-30',DATE'2002-10-30');overlaps----------f(1 row)
4.8.6、时间函数
PostgreSQL提供了许多用于返回当前日期和时间的函数。下面的函数都是按照当前事 务开始的时间返回结果的:
·CURRENT_DATE。·CURRENT_TIME。·CURRENT_TIMESTAMP。·CURRENT_TIME(precision)。·CURRENT_TIMESTAMP(precision)。·LOCALTIME。·LOCALTIMESTAMP。·LOCALTIME(precision)。·LOCALTIMESTAMP(precision)。·now()。·transaction_timestamp()。
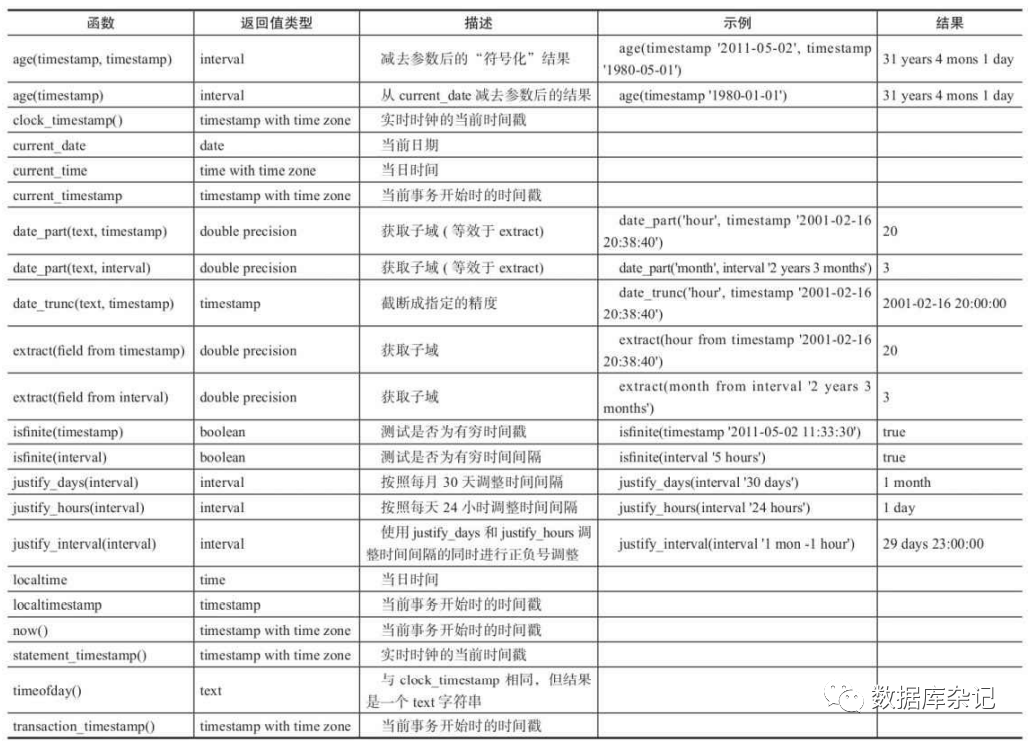
其中,CURRENT_TIME和CURRENT_TIMESTAMP返回带时区的值;LOCALTIME 和LOCALTIMESTAMP返回不带时区的值。CURRENT_TIME、CURRENT_TIMESTAMP、LOCALTIME、LOCALTIMESTAMP 可以选择性地给予一个精度参数,该精度会导致结果的秒数域被四舍五入到指定的小数位 。如果没有精度参数,将给予所能得到的全部精度。示例如下:
internals=> begin;BEGINinternals=*> SELECT CURRENT_TIME;current_time--------------------09:59:14.281203+08(1 row)internals=*> SELECT CURRENT_DATE;current_date--------------2022-12-11(1 row)internals=*> SELECT CURRENT_TIMESTAMP;current_timestamp-------------------------------2022-12-11 09:59:14.281203+08(1 row)internals=*> SELECT CURRENT_TIMESTAMP(2);current_timestamp---------------------------2022-12-11 09:59:14.28+08(1 row)internals=*> SELECT LOCALTIMESTAMP;localtimestamp----------------------------2022-12-11 09:59:14.281203(1 row)internals=*> end;COMMIT
因为这些函数全部是按照当前事务开始的时间返回结果的,所以它们的值在整个事务 运行期间都不会改变。PostgreSQL这样做是为了允许一个事务在“当前时间”上有连贯的概 念,这样同一个事务里的多个修改就可以保持同样的时间戳了。
PostgreSQL同样也提供了返回实时时间值的函数,它们的返回值会在事务中随时间的 推移而不断变化。这些函数列表如下:
·statement_timestamp()。·clock_timestamp()。·timeofday()。
now()函数、CURRENT_TIMESTAMP函数和transaction_timestamp()函数是等效的。不过,transaction_timestamp()的命名更准确地表明了其含义。statement_timestamp()返回当 前语句开始时刻的时间戳。statement_timestamp()和transaction_timestamp()在一个事务的第 一条命令里的返回值相同,但是在随后的命令中返回结果却不一定相同。clock_timestamp ()返回实时时钟的当前时间戳,因此它的值甚至在同一条SQL命令中都会变化。timeofday( )相当于clock_timestamp(),也返回实时时钟的当前时间戳,但它返回的是一个text字符串 ,而不是timestamp with time zone值。
所有日期/时间类型还接受特殊的文本值“now”,用于声明当前的日期和时间(重申:乃当前事务开始的时间)。因此,下面3个语句都返回相同的结果:
·SELECT CURRENT_TIMESTAMP。·SELECT now()。·SELECT TIMESTAMP with time zone 'now'
示例如下:
internals=> begin;BEGINinternals=*> SELECT CURRENT_TIMESTAMP;current_timestamp-------------------------------2022-12-11 10:01:39.771957+08(1 row)internals=*> SELECT now();now-------------------------------2022-12-11 10:01:39.771957+08(1 row)internals=*> SELECT TIMESTAMP with time zone 'now';timestamptz-------------------------------2022-12-11 10:01:39.771957+08(1 row)internals=*> end;COMMIT
4.8.7、extract和date_part函数
extract函数格式如下:extract (field FROM source)
extract函数从日期/时间数值中抽取子域,比如年、小时等,其返回类型为double preci sion的数值。source必须是一个timestamp或time或interval类型的值表达式,此外,类型为d ate的表达式可自动转换为timestamp,因此source也可以用date类型。field是一个标识符或 者字符串,它指定从源数据中抽取的域。
extract函数示例:
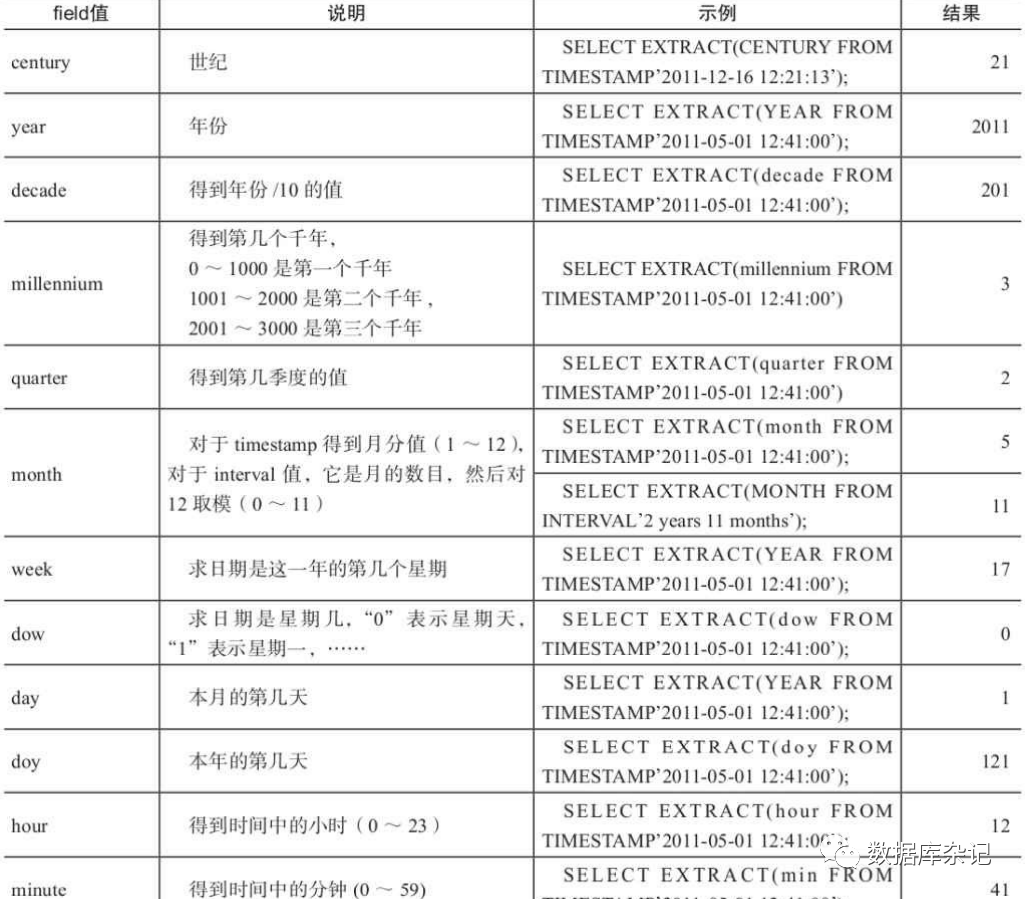
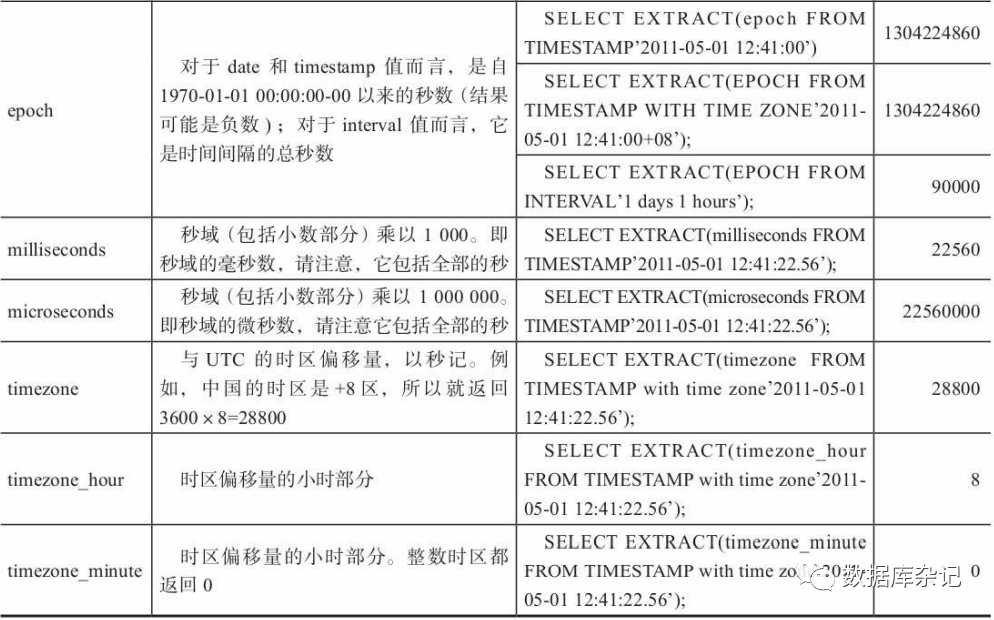

4.9、数组类型
PostgreSQL支持表的字段使用定长或可变长度的一维或多维数组,数组的类型可以是任何数据库内建的类型、用户自定义的类型、枚举类型及组合类型。但目前还不支持domain类型。
4.9.1、数组类型的声明
现举例说明数组类型是如何声明的:
CREATE TABLE testtab04(id int, col1 int[], col2 int[10], col3 text[][]);CREATE TABLE
数组类型的定义就是通过在数组元素类型名后面附加方括 号“[]”来实现的。方括号中可以给一个长度数字,也可以不给,同时也可以定义多维数组 。多维数组是通过加多对方括号来实现的。实际上,在目前的PostgreSQL实现中,如果在 定义数组类型中填一个数组长度的数字,这个数字是无效的,不会限制数组的长度;定义 时指定数组维度也是没有意义的,数组的维度实际上也是根据实际插入的数据来确定的。也就是说,下面两个声明的意义是相同的。
CREATE TABLE testtab04(id int, col1 int[], col2 int[10], col3 text[][]);CREATE TABLE testtab04(id int, col1 int[10], col2 int[], col3 text[]);
4.9.2、数组值的输入
通过几个例子来说明如何输入数组类型的数据,示例如下:
create table testtab05(id int, col1 int[]);CREATE TABLEinsert into testtab05 values(1,'{1,2,3}');INSERT 0 1insert into testtab05 values(2,'{4,5,6}');INSERT 0 1select * from testtab05;id | col1----+---------1 | {1,2,3}2 | {4,5,6}(2 rows)
上面的例子是输入一个整数类型的数组,那么字符串类型的数组数据又应如何输入呢 ?示例如下:
create table testtab06(id int, col1 text[]);insert into testtab06 values(1,'{how,howe,howl}');
从上面的例子中可以看出,数组的输入值是使用单引号加大括号来表示的。各个元素 值之间是用逗号分隔的。实际上,是否使用逗号分隔各个元素值与元素类型有关,在Post greSQL中,每个类型都定义的分隔符如下:
select typname, typdelim from pg_type where typname in ('int4','int8','bool','char','box');typname | typdelim---------+----------bool | ,char | ,int8 | ,int4 | ,box | ;(5 rows)
在PostgreSQL中,除了box类型的分隔符为分号以外,其他的类型基本上都使用逗号 作为分隔符。box类型使用分号作为分隔符,示例如下:
create table testtab08(id int, col1 box[]);insert into testtab08 values(1, '{((1,1),(2,2)); ((3,3),(4,4)); ((1,2),(7,9))}');select * from testtab08;id | col1----+---------------------------------------1 | {(2,2),(1,1);(4,4),(3,3);(7,9),(1,2)}
上面输入的字符串内容中是没有空格的,在有空格时,又该如何输入呢?示例如下:
insert into testtab06 values(2,'{how many,how mach,how old}');
那么字符串中有逗号时怎么办呢?这时可以使用双引号,示例如下:
insert into testtab06 values(4,'{"who, what", "CO.,LTD."}');
如果字符串中有单引号怎么办呢?这时可以使用两个连接的单引号表示一个单引号:
insert into testtab06 values(3,'{"who''s bread", "It''s ok"}');
如果输入的字符串中有括号“{”和“}”怎么办呢?只需要把它们放到双引号中即可:
insert into testtab06 values(5,'{"{os,dba}", "{dba,os}"}');
如果输入的字符串中有双引号怎么办呢?需要在双引号前加反斜扛,示例如下:
insert into testtab06 values(6,'{os\"dba}');
要将一个数组元素的值设为“NULL”,直接写上“NULL”即可(与大小写无关)。要 将一个数组元素的值设为字符串“"NULL"”,那么就必须加上双引号。
除了上面介绍的方法以外,还可以使用ARRAY构造器语法输入数据,数组构造器是 一个表达式,它从自身的成员元素上构造一个数组值。简单的数组构造器由关键字“ARR AY”、一个左方括弧“[”、一个或多个表示数组元素值的表达式(用逗号分隔)、一个右 方括弧“]”组成。示例如下:
insert into testtab06 values(6,ARRAY['os','dba']);insert into testtab06 values(6,ARRAY['os"dba','123"456']);insert into testtab06 values(6,ARRAY['os''dba','123''456']);
多维数组的示例如下:
create table testtab07(id int, col1 text[][]);insert into testtab07 values(1,ARRAY[['os','dba'],['dba','os']]);
在向多维数组中插入值时,各维度元素的个数必须相同,否则会报如下错误:
insert into testtab07 values(2, '{{a,b},{c,d,e}}');ERROR: malformed array literal: "{{a,b},{c,d,e}}"LINE 1: insert into testtab07 values(2, '{{a,b},{c,d,e}}');^DETAIL: Multidimensional arrays must have sub-arrays with matching dimensions.
上面的第一个“{a,b}”中有两个元素,而第二个“{c,d,e}”中有3个元素,这是不行的, 元素个数必须相同,此时就得补空值,SQL语句如下:
insert into testtab07 values(2, '{{a,b,null},{c,d,e}}');select * from testtab07;id | col1----+----------------------1 | {{os,dba},{dba,os}}2 | {{a,b,NULL},{c,d,e}}(2 rows)
默认情况下,PostgreSQL数据库中数组的下标是从1开始的,但也可以指定下标的开 始值,示例如下:
create table test02(id int[]);insert into test02 values('[2:4]={1,2,3}');select id[2],id[3],id[4] from test02;id | id | id----+----+----1 | 2 | 3(1 row)
从上面的例子中可以看出,指定数组上下标的格式如下:
'[下标:上标]=[元素值1,元素值2,元素值3,....]'
4.9.3、访问数组
访问数组的示例
create table testtab08(id int, col1 text[]);insert into testtab08 values(1,'{aa,bb,cc,dd}');insert into testtab08 values(2,'{ee,ff,gg,hh}');select * from testtab08;id | col1----+---------------1 | {aa,bb,cc,dd}2 | {ee,ff,gg,hh}(2 rows)
访问数组中的元素时在方括号内加数字就可以了,就像C 语言中一样。但需要注意的是,在PostgreSQL中,数组的下标默认是从1开始的,而不是 像C语言中从0开始,当然也可以创建从0(实际可以是任意数字)开始的数组,示例如下 :
create table test02(id int[]);insert into test02 values('[0:2]={1,2,3}');select id[0],id[1],id[2] from test02;id | id | id----+----+----1 | 2 | 3(1 row)
还可以使用数组切片,示例如下:
select id, col1[1:2] from testtab08;id | col1----+---------1 | {aa,bb}2 | {ee,ff}(2 rows)
二维数组的访问示例如下:
create table testtab09(id int, col1 int[][]);insert into testtab09 values(1,'{{1,2,3},{4,5,6},{7,8,9}}');select id,col1[1][1],col1[1][2],col1[2][1],col1[2][2] from testtab09;id | col1 | col1 | col1 | col1----+------+------+------+------1 | 1 | 2 | 4 | 5(1 row)
在对二维数组进行访问时,如果只使用一个下标是否能返回其中一维的全部元素?示 例如下:
select id,col1[1] from testtab09;id | col1----+------1 |(1 row)
从上面的运行结果来看,答案是不行的,其返回结果为空。实际上,如果想返回多维 数组中某一维的全部元素,可以使用切片,切片的起始位置与结束位置相同即可,示例如 下:
select id,col1[1:1] from testtab09;id | col1----+-----------1 | {{1,2,3}}(1 row)
当我们把单个下标和切片混用时,下面的结果是否会让人看不懂?
select id, col1[3][1:2] from testtab09;id | col1----+---------------------1 | {{1,2},{4,5},{7,8}}(1 row)
以一般的理解来看,“col1[3]”表示“{7,8,9}”,然后取切片“[1:2]”应该返回“{7,8}”,为 何返回的是“{{1,2},{4,5},{7,8}}”呢?原来PostgreSQL中规定,只要出现一个冒号,其他的 单个下标隐含表示的都是从1开始的切片,下标的数据表示切片的结束值,“col1[3][1:2]” 中的“col[3]”实际上表示的是“col1[1:3]”,这样这个表达式实际上就是“col1[1:3][1:2]”了, 如此得到这样的结果也就很好理解了。同样,也更容易理解下面的结果:
select id, col1[1:2][2] from testtab09;id | col1----+---------------1 | {{1,2},{4,5}}(1 row)
其中“col1[1:2][2]”实际上等价于“col1[1:2][1:2]”
4.9.4、修改数组
数组值可以整个被替换,也可以只替换数组中的单个元素。
1)、替换整个数组值的示例如下:
select * from testtab09;id | col1----+---------------------------1 | {{1,2,3},{4,5,6},{7,8,9}}(1 row)update testtab09 set col1='{{10,11,12},{13,14,15},{16,17,18}}' where id=1;UPDATE 1select * from testtab09;id | col1----+------------------------------------1 | {{10,11,12},{13,14,15},{16,17,18}}(1 row)
2)、只修改数组中的某个元素值的示例如下:
update testtab09 set col1[2][1]=100 where id=1;UPDATE 1select * from testtab09;id | col1----+-------------------------------------1 | {{10,11,12},{100,14,15},{16,17,18}}(1 row)
3)、注意,不能直接修改多维数组中某一维的值:
update testtab09 set col1[3]=100 where id=1;ERROR: wrong number of array subscriptsupdate testtab09 set col1[3]='{200,300}' where id=1;ERROR: invalid input syntax for type integer: "{200,300}"LINE 1: update testtab09 set col1[3]='{200,300}' where id=1;^
4.9.5、数组的操作符
1)、普通比较操作符
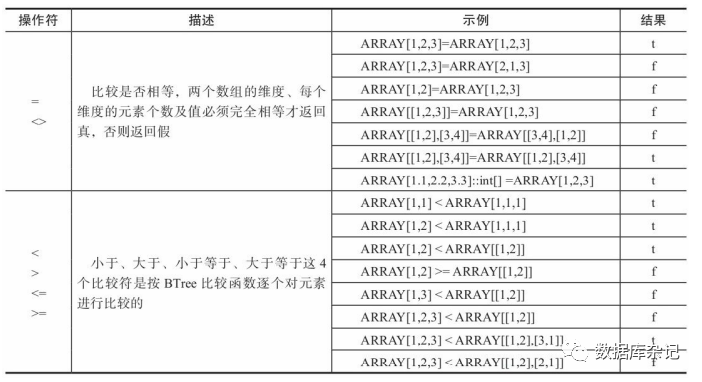
2)、集合比较操作符
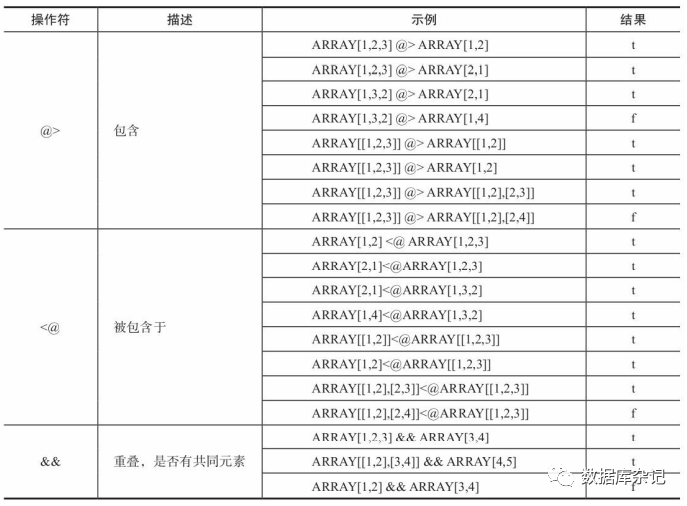
从表中可以看出,不同维度之间的数组也可以进行“包含”“重叠”等集合比较操作,这 些操作与元素的顺序及维度基本无关,实际上可以认为,在做集合比较时,不管数组中的 元素在哪一维,都可以把它们全部当成集合中的一个元素,而与数组的维度无关。
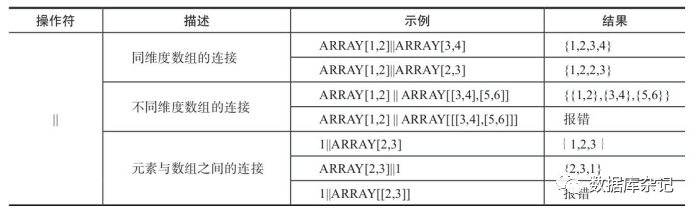
3)、连接操作符"||"
4.9.6、数组的函数
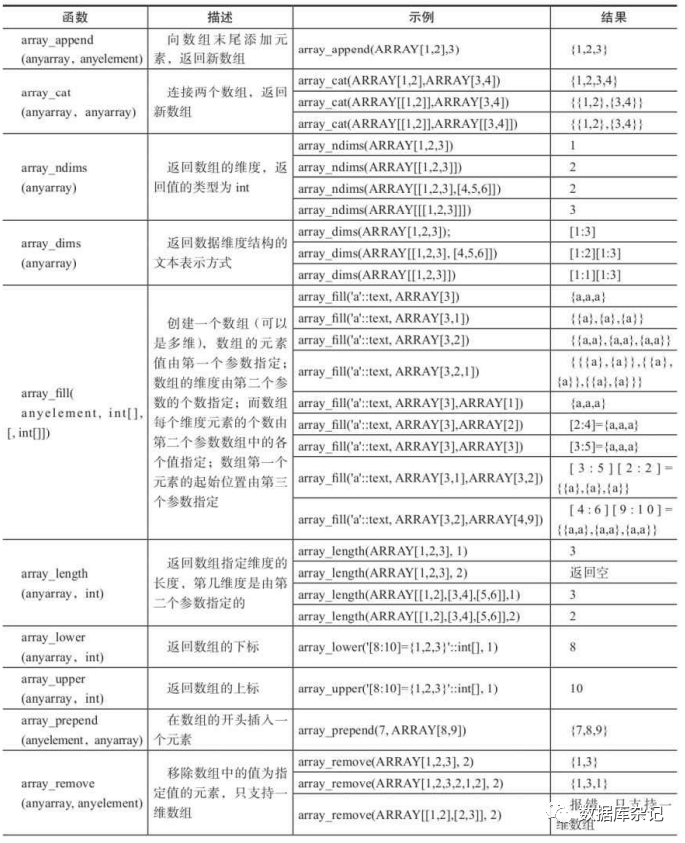
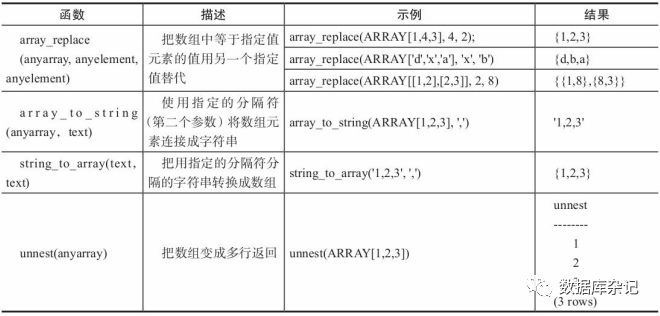
数组还有一个聚合函数array_agg,其使用方法如下。首先建如下测试表:
create table test03(id int, v int);insert into test03 values(1,1);insert into test03 values(1,2);insert into test03 values(1,3);insert into test03 values(2,20);insert into test03 values(2,21);insert into test03 values(2,22);insert into test03 values(3,31);insert into test03 values(3,32);insert into test03 values(3,33);select * from test03;id | v----+----1 | 11 | 21 | 32 | 202 | 212 | 223 | 313 | 323 | 33(9 rows)
然后就可以使用array_agg聚合函数了:
select id, array_agg(v) from test03 group by id;id | array_agg----+------------3 | {31,32,33}2 | {20,21,22}1 | {1,2,3}(3 rows)
4.10、域和组合类型(domain, composite)
4.10.1、域domain:
是已存在的数据类型的别名。虽可以额外定义约束。支持性不太好。plpgsql不检查约束。不能使用到一些系统中。
mydb=> create domain MYINT bigint constraint MYINT_C NOT null;CREATE DOMAINmydb=> create table t(id MYINT primary key, col2 varchar(32));CREATE TABLEmydb=> insert into t values(134, 'abc');INSERT 0 1mydb=> \dmydb=> \d tid | myint | | not null |col2 | character varying(32) | | |
4.10.2、组合类型:(as是必须的)
mydb=> create type shape as (x int, y int, x2 int, y2 int);CREATE TYPEmydb=> create table t (id int primary key, col2 shape);CREATE TABLEmydb=> insert into t values(1, (1,2,3,4));INSERT 0 1mydb=> select * from t;1 | (1,2,3,4)
如果没有AS, DB会认为你在创建一个新的数据类型。
4.11、聚集函数
• 从一系列的输入值中计算出某个单一的值• 忽略 NULLs (如果所有的输入是NULL则返回 NULL)• avg, count, max, min, stddev, sum, variance• bit_and, bit_or – 所有非空输入值按位”与/或”• bool_and, every -如果所有输入值都是真,则为真,否则为假• bool_or -如果至少有一个输入值为真,则为真,否则为假
4.12、设置返回集合函数
generate_series(start, stop[, step]) -生成一个数值序列,从 start 到 stop,步长为 step (默认为1)
mydb=> select * from generate_series(1,3,5) s;1mydb=> select * from generate_series(1,10,5) s;16mydb=> select * from generate_series(1,16,5) s;161116
4.13、Object ID (oid Type)
内部使用,用于标识内部对象。
可以在用户定义的表中使用,但不推荐。
别名类型对查找一个对象的OID非常方便。
– reg* ,其中 *可以是class, type, oper, operator, proc 或 者procedure
– regoperator 和 regprocedure 接收参数类型
SELECT 'pg_catalog.abs'::regproc;ERROR: more than one function named "abs"SELECT 'abs(int)'::regproc;ERROR: function "abs(int)" does not existSELECT 'abs(int)'::regprocedure;regprocedure--------------abs(integer)
4.14、约束
check constraints not-null constraints unique constraints pk constraints foreign keys constraints
CREATE TABLE dept(DEPTNO numeric(2) CONSTRAINT PK_DEPT PRIMARY KEY,DNAME VARCHAR(14) ,LOC VARCHAR(13) ) ;CREATE TABLE emp(empno numeric(4) NOT NULL,ename varchar(10),job varchar(9),mgr numeric(4),hiredate timestamp,sal numeric(7,2),comm numeric(7,2),deptno numeric(2),CONSTRAINT emp_pk PRIMARY KEY (empno),CONSTRAINT emp_ref_dept_fk FOREIGN KEY (deptno)REFERENCES dept (deptno) ON UPDATE NO ACTIONON DELETE NO ACTION,CONSTRAINT emp_sal_ck CHECK (sal > 0));
注意pg里头没有varchar2, 也没有datetime类型。(page 77)
4.15、Unique Key的生成
CREATE [TEMPORARY | TEMP] SEQUENCE name [INCREMENT [ BY ] increment] [ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
mydb=> CREATE TABLE dept(DEPTNO numeric(2) PRIMARY KEY, DNAME VARCHAR(14),LOC VARCHAR(13)) ;CREATE TABLEmydb=> CREATE SEQUENCE department_id_seq;CREATE SEQUENCEmydb=> insert into dept values(nextval('department_id_seq'), 'ABC', 'loc of ABC');INSERT 0 1
5、数据类型(Advanced)
5.1、二进制数据类型(bytea)
PostgreSQL中只有一种二进制类型:bytea类型。此数据类型允许存储二进制字符串 ,对应MySQL和Oracle中的blob类型。Oracle中的raw类型也可以用该类型取代。
二进制字符串是一个字节序列。二进制字符串和普通字符串的区别有两个:第一,二 进制字符串完全可以存储字节零值,以及其他“不可打印”的字节(定义在32到126范围之 外的字节)。普通字符串不允许字节零值,而且也不允许存储那些不符合选定的字符集编 码的非法字节值或者字节序列。第二,对二进制字符串的处理实际上就是对字节的处理, 而对字符串的处理,则取决于区域设置。简单说,二进制字符串适于存储那些程序员认为 是“原始字节”的数据,比如图片内容,而字符串则适合存储文本。
如何在SQL语句的文本串中输 入bytea数值呢?答案是使用转义。通常来说,要转义一个字节值,需要把它的数值转换 成对应的三位八进制数,并且加两个前导反斜杠。
5.1.1 文本的转义表示
1)、39, 单引号:
postgres=# select E'\''::bytea, E'\''::text;bytea | text-------+------\x27 | '(1 row)
2)、92, 反斜杠:
postgres=# select E'\\\\'::bytea, E'\\134'::bytea, E'\\'::text, E'\134'::text;bytea | bytea | text | text-------+-------+------+------\x5c | \x5c | \ | \(1 row)
3)、0~31以及127到255 不可打印字符
postgres=# select E'\001\002'::bytea;bytea--------\x0102(1 row)postgres=# create table t2(id bytea);CREATE TABLEpostgres=# insert into t2 values(E'\\001\\002');INSERT 0 1postgres=# select * from t2;id--------\x0102(1 row)
5.1.2、二进制数据类型的相关函数
1)、string||string, 返回bytea类型, 字符串拼接
postgres=# select E'\\001'::bytea || E'\\117'::bytea;?column?----------\x014f(1 row)
2)、从字符串中抽取:get_bit(string, offset), 返回int
postgres=# select E'os\\000dba'::bytea, get_bit(E'os\\000dba'::bytea, 45);bytea | get_bit----------------+---------\x6f7300646261 | 1(1 row)
3)、get_byte(string, offset), 抽取字节
postgres=# select E'os\\000dba'::bytea, get_byte(E'os\\000dba'::bytea, 4);bytea | get_byte----------------+----------\x6f7300646261 | 98(1 row)
4)、octet_length(string), 二进制字节数
postgres=# select E'os\\000dba'::bytea, octet_length(E'os\\000dba'::bytea);bytea | octet_length----------------+--------------\x6f7300646261 | 6(1 row)
5)、position(substring in string) 子串位置
postgres=# select E'os\\000dba'::bytea, position(E's'::bytea in E'os\\000dba'::bytea);bytea | position----------------+----------\x6f7300646261 | 2(1 row)
6)、set_bit(string, offset, newvalue), 设置某个位置的位
postgres=# select E'os\\000dba'::bytea, set_bit( E'os\\000dba'::bytea, 17, 1);bytea | set_bit----------------+----------------\x6f7300646261 | \x6f7302646261(1 row)
7)、set_byte(string, offset, newvalue), 设置某个位置的字节值
postgres=# select E'os\\000dba'::bytea, set_byte( E'os\\000dba'::bytea, 3, 48);bytea | set_byte----------------+----------------\x6f7300646261 | \x6f7300306261(1 row)
8)、substring(string, [from int][for int]) 提取子字符串
postgres=# select E'os\\000dba'::bytea, substring( E'os\\000dba'::bytea, 0, 4);bytea | substring----------------+-----------\x6f7300646261 | \x6f7300(1 row)postgres=# select E'os\\000dba'::bytea, substring( E'os\\000dba'::bytea from 0 for 4);bytea | substring----------------+-----------\x6f7300646261 | \x6f7300(1 row)
9)、trim([both] bytea from string) 从串的开头和结尾去掉bytea的内容
postgres=# select E'\\000osdba\\000'::bytea, trim(E'\\000' from E'\\000osdba\\000'::bytea);bytea | btrim------------------+--------------\x006f7364626100 | \x6f73646261(1 row)
5.2、位串类型
位串类型是可以存放一系列二进制位的类型,相对于二进制类型来说,此类型在做一 些位操作更方便、更直观。位串就是一串由1和0组成的字符串。PostgreSQL中可以直观地显式操作二进制位。
下面是两种SQL位类型:
bit(n) bit varying(n)
其中n是一个正整数。bit(n)类型的数据必须准确匹配长度n,试图存储短一些或者长一些的数据都是错误的 。bit varying(n)类型的数据是最长为n的变长类型,更长的串会被拒绝。写一个没有长度的bit等效于bit(1),没有长度的bit varying表示没有长度限制。
如果明确地把一个位串值转换成bit(n),那么它的右边将被截断,或者在右边补齐0到 刚好为n位,而不会抛出任何错误。类似地,如果明确地把一个位串数值转换成bit varying (n),而其超过n位,那么它的右边将被截断。
5.2.1、使用示例
db1=# create table t3 (a bit(3), b bit varying(5));CREATE TABLE
插入数据
db1=# INSERT INTO t3 VALUES (B'101', B'00');INSERT 0 1-- 超长即会报错db1=# INSERT INTO t3 VALUES (B'10', B'001111');ERROR: bit string length 2 does not match type bit(3)db1=# INSERT INTO t3 VALUES (B'111', B'001111');ERROR: bit string too long for type bit varying(5)
经过转换
db1=# INSERT INTO t3 VALUES (B'111', B'001111'::bit varying(5));INSERT 0 1db1=# INSERT INTO t3 VALUES (B'11'::bit(3), B'001111'::bit varying(5));INSERT 0 1db1=# select * from t3;a | b-----+-------101 | 00111 | 00111110 | 00111(3 rows)
5.2.2、位串类型函数
1)、操作符
参考下表:

2)、操作函数
下列SQL标准函数既可以用于字符串,也可以用于位串:
length
bit_length
octet_length
position
substring
overlay
overlay ( bits bit PLACING newsubstring bit FROM start integer [ FOR count integer ] ] ) → bitoverlay(B'01010101010101010' placing B'11111' from 2 for 3) → 0111110101010101010
下列函数既支持二进制字符串,也可用于位串:
get_bit set_bit
当用于位串时,上述函数的位数将以串(最左边)的第一位作为0位。另外,可以在整数和bit之间进行转换。示例如下:
db1=# select 32::bit(5);bit-------00000(1 row)db1=# select 32::bit(6);bit--------100000(1 row)db1=# select 66::bit(10), 66::bit(3), (-66)::bit(12);bit | bit | bit------------+-----+--------------0001000010 | 010 | 111110111110(1 row)十进制到2进制:db1=# select 96::bit(8), 255::bit(8);bit | bit----------+----------01100000 | 11111111(1 row)十六进制到2进制:db1=# select x'ff'::bit(8), x'AB12'::bit(16);bit | bit----------+------------------11111111 | 1010101100010010(1 row)十六进制到10进制:db1=# select X'ff'::int, x'1000'::int;int4 | int4------+------255 | 4096(1 row)十进制到十六进制:db1=# select to_hex(255), to_hex(4096);to_hex | to_hex--------+--------ff | 1000(1 row)
5.3、枚举类型
枚举类型是包含一系列有序的静态值集合的一个数据类型,等于某些编程语言中的enum类型。
与MySQL不一样,在PostgreSQL中要使用枚举类型需要先使用CREATE TYPE来创建 此枚举类型。示例如下。先建一个名为“week”的枚举类型,并建一张测试表:
5.3.1、简单示例:
CREATE TYPE week AS ENUM ('Sun','Mon','Tues','Wed','Thur','Fri', 'Sat');CREATE TABLE duty(person text, weekday week);INSERT INTO duty values('张三', 'Sun');INSERT INTO duty values('李四', 'Mon');INSERT INTO duty values('王二', 'Tues');INSERT INTO duty values('赵五', 'Wed');
查询下数据:
SELECT * FROM duty WHERE weekday = 'Sun';person | weekday--------+---------张三 | Sun(1 row)-- 如果输入的字符串不在枚举类型之间,则会报错:db1=# SELECT * FROM duty WHERE weekday = 'Sun1';ERROR: invalid input value for enum week: "Sun1"LINE 1: SELECT * FROM duty WHERE weekday = 'Sun1';^
5.3.2、在psql中可以使用“\dT”命令查看枚举类型的定义:
db1=# \dT+ weekList of data typesSchema | Name | Internal name | Size | Elements | Owner | Access privileges | Description--------+------+---------------+------+----------+----------+-------------------+-------------public | week | week | 4 | Sun +| postgres | || | | | Mon +| | || | | | Tues +| | || | | | Wed +| | || | | | Thur +| | || | | | Fri +| | || | | | Sat | | |(1 row)
直接查询表“pg_enum”也可以看到枚举类型的定义:
db1=# select * from pg_enum;oid | enumtypid | enumsortorder | enumlabel-------+-----------+---------------+-----------31332 | 31330 | 1 | Sun31334 | 31330 | 2 | Mon31336 | 31330 | 3 | Tues31338 | 31330 | 4 | Wed31340 | 31330 | 5 | Thur31342 | 31330 | 6 | Fri31344 | 31330 | 7 | Sat(7 rows)
5.3.3、枚举类型说明
在枚举类型中,值的顺序是创建枚举类型时定义的顺序。所有的比较标准运算符及相 关的聚集函数都可支持枚举类型。示例如下:
SELECT min(weekday), max(weekday) FROM duty;min | max-----+-----Sun | Wed(1 row)db1=# SELECT * FROM duty where weekday = (SELECT max(weekday) FROM duty);person | weekday--------+---------赵五 | Wed(1 row)
每个枚举类型都是独立的,不能与其他枚举类型混用。一个枚举值在磁盘上占4字节空间。一个枚举值的文本标签长度由NAMEDATALEN 设置并编译到PostgreSQL中,且是以标准编译的方式进行的,也就意味着,一个枚举值的文本标签长度至多是63字节。
注意:枚举类型的值对大小写是敏感的,如“Mon”不等于“mon”。标签中的空格也是一样, 如“Mon”(“Mon”后有一个空格)不等于“Mon”。
5.3.4、枚举类型的函数
1)、enum_first(anyenum): 返回枚举类型的第一个值
2)、enum_last(anyenum): 返回枚举类型的第一个值
3)、enum_range(anyenum): 返回枚举类型所有值列表
4)、enum_range(anyenum, anyenum): 有序数组,返回两个枚举值之间的枚举值. 第1个参数为null时,从第1个值记起。第2个参数为空时,会以枚举值最后一个值结束
db1=# select enum_first('Mon'::week), enum_last('Tues'::week), enum_range('Sun'::week);enum_first | enum_last | enum_range------------+-----------+---------------------------------Sun | Sat | {Sun,Mon,Tues,Wed,Thur,Fri,Sat}(1 row)db1=# select enum_range(null, 'Tues'::week), enum_range('Tues'::week, null);enum_range | enum_range----------------+-------------------------{Sun,Mon,Tues} | {Tues,Wed,Thur,Fri,Sat}(1 row)
除了两个参数形式的enum_range外,其余函数会忽略传递给它们的具体值,因为它们 只关心声明的数据类型。使用null加上类型转换也会得到相同的结果,示例如下:
db1=# select enum_first(null::week), enum_last(null::week);enum_first | enum_last------------+-----------Sun | Sat(1 row)
5.4、几何类型
PostgreSQL数据库提供了点、线、矩形、多边形等几何类型,其他数据库大都没有这些类型。
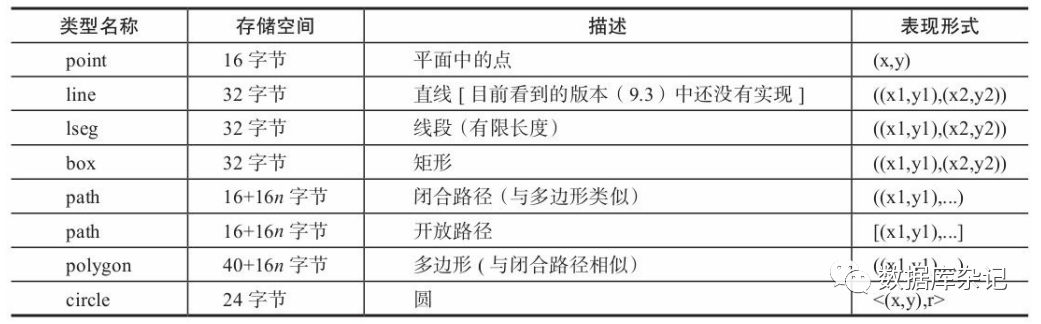
5.4.1、几何类型概况
PostgreSQL主要支持一些二维的几何数据类型。最基本的类型是“point”,它是其他类 型的基础。
5.4.2、几何类型的输入
可以使用下面的格式输入几何类型:类型名称 '表现形式'
也可以使用类型转换,形式如下:'表现形式'::类型名称
下面用例子说明如何输入这些几何类型。
点的示例:
internals=> select '1,1'::point;point-------(1,1)(1 row)internals=> select '(1,1)'::point;point-------(1,1)(1 row)
线段的示例:
internals=> select '(1,1),(2,2)'::lseg, '((1,1),(2,2))'::lseg,'[(1,1),(2,2)]'::lseg;lseg | lseg | lseg---------------+---------------+---------------[(1,1),(2,2)] | [(1,1),(2,2)] | [(1,1),(2,2)](1 row)internals=> select lseg '1,1,2,2',lseg '(1,1),(2,2)', lseg '((1,1),(2,2))',lseg '[(1,1),(2,2)]';lseg | lseg | lseg | lseg---------------+---------------+---------------+---------------[(1,1),(2,2)] | [(1,1),(2,2)] | [(1,1),(2,2)] | [(1,1),(2,2)](1 row)
矩形的示例如下:
internals=> select box '1,1,2,2', box '(1,1),(2,2)', box '((1,1),(2,2))';box | box | box-------------+-------------+-------------(2,2),(1,1) | (2,2),(1,1) | (2,2),(1,1)(1 row)
注意,矩形类型不能使用类似线段类型中的中括号输入方法,示例如下:
internals=> select box '[(1,1),(2,2)]';ERROR: invalid input syntax for type box: "[(1,1),(2,2)]"LINE 1: select box '[(1,1),(2,2)]';^
路径的示例如下:
internals=> select path '1,1,2,2,3,3,4,4', path '(1,1),(2,2),(3,3),(4,4)', path '((1,1),(2,2),(3,3),(4,4))';path | path | path---------------------------+---------------------------+---------------------------((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4))(1 row)internals=> select path '[(1,1),(2,2),(3,3),(4,4)]';path---------------------------[(1,1),(2,2),(3,3),(4,4)](1 row)internals=> select '1,1,2,2,3,3,4,4'::path, '(1,1),(2,2),(3,3),(4,4)'::path, '((1,1),(2,2),(3,3),(4,4))'::path, '[(1,1),(2,2),(3,3),(4,4)]'::path;path | path | path | path---------------------------+---------------------------+---------------------------+---------------------------((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4)) | [(1,1),(2,2),(3,3),(4,4)](1 row)
注意:在路径中方括号“[]”表示开放路径,而圆括号“()”表示闭合路径。闭合路径是指 最后一个点与第一个点是连接在一起的。
多边形的示例如下
internals=> select polygon '1,1,2,2,3,3,4,4',polygon '(1,1),(2,2),(3,3),(4,4)', polygon '((1,1),(2,2),(3,3),(4,4))';polygon | polygon | polygon---------------------------+---------------------------+---------------------------((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4))(1 row)internals=> select polygon '[(1,1),(2,2),(3,3),(4,4)]';ERROR: invalid input syntax for type polygon: "[(1,1),(2,2),(3,3),(4,4)]"LINE 1: select polygon '[(1,1),(2,2),(3,3),(4,4)]';^internals=> select '1,1,2,2,3,3,4,4'::polygon,'(1,1),(2,2),(3,3),(4,4)'::polygon, '((1,1),(2,2),(3,3),(4,4))'::polygon;polygon | polygon | polygon---------------------------+---------------------------+---------------------------((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4)) | ((1,1),(2,2),(3,3),(4,4))(1 row)
注意,多边形类型的输入方法中不能使用中括号“[]”:
圆型的示例如下
internals=> select circle '1,1,5', circle '((1,1),5)',circle '<(1,1),5>';circle | circle | circle-----------+-----------+-----------<(1,1),5> | <(1,1),5> | <(1,1),5>(1 row)internals=> select '1,1,5'::circle, '((1,1),5)'::circle,'<(1,1),5>'::circle;circle | circle | circle-----------+-----------+-----------<(1,1),5> | <(1,1),5> | <(1,1),5>(1 row)
注意,圆型原来老版本不能使用下面的输入方式, 现在又可以了:
internals=> select circle '(1,1),5';circle-----------<(1,1),5>(1 row)internals=> select '(1,1),5'::circle;circle-----------<(1,1),5>(1 row)
5.4.3、几何类型的操作符
对于几何类型,PostgreSQL提供了丰富的操作符,具体如下。
+:平移。
-:平移。
*:缩放/旋转。
/:缩放/旋转。
#:对于两个线段,计算出交点,而对于两个矩形,计算出相关的矩形。
#:对于路径或多边形,则计算出顶点数。
@-@:计算出长度或周长。
@@:计算中心点。
##:第一个和第二个操作数的最近点。
<->:计算间距。
&&:是否重叠,有一个共同点为真。
<<:是否严格在左。
>>:是否严格在右。
&<:没有延展到右边。
&>:没有延展到左边。
<<|:严格在下。
|>>:严格在上。
&<|:没有延展到上面。
|&>:没有延展到下面。
<^:在下面(允许接触)。
>^:在上面(允许接触)。
?#:是否相交。
?-:是否水平或水平对齐。
?|:是否竖直或竖直对齐。
?-|:两个对象是否垂直。
?||:两个对象是否平行。
@>:是否包含。
<@:包含或在其上。
~=:是否相同。
下面通过示例详细讲解这些运算符。
1、平移运算符“+”“-”及缩放/旋转运算符“*”“/
这4个运算符都是二元运算符,运算符左值的类型可以是“point”“box”“path”“circle”, 运算符的右值只能是“point”。下面来看看相关示例。
对于点与点之间,相当于把点看成一个复数,点和点之间的加减乘除相当于两个复数 之间的加减乘除,示例如下:
internals=> select point '(1,2)' + point '(10,20)';?column?----------(11,22)(1 row)internals=> select point '(1,2)' - point '(10,20)';?column?----------(-9,-18)(1 row)internals=> select point '(1,2)' * point '(10,20)';?column?----------(-30,40)(1 row)internals=> select point '(1,2)' point '(10,20)';?column?----------(0.1,0)(1 row)
对于矩形与点之间,示例如下:
internals=> select box '((0,0),(1,1))' + point '(2,2)';?column?-------------(3,3),(2,2)(1 row)internals=> select box '((0,0),(1,1))' - point '(2,2)';?column?-----------------(-1,-1),(-2,-2)(1 row)
对于路径与点之间,示例如下:
internals=> select path '(0,0),(1,1),(2,2)' + point '(10,20)';?column?---------------------------((10,20),(11,21),(12,22))(1 row)internals=> select path '(0,0),(1,1),(2,2)' - point '(10,20)';?column?-------------------------------((-10,-20),(-9,-19),(-8,-18))(1 row)
对于圆与点之间,示例如下:
internals=> select circle '((0,0),1)' + point '10,20';?column?-------------<(10,20),1>(1 row)internals=> select circle '((0,0),1)' - point '10,20';?column?---------------<(-10,-20),1>(1 row)
对于乘法,如果乘数的y值为0,比如“point 'x,0'”,则相当于几何对象缩放x倍,具体 示例如下:
internals=> select point '(1,2)' * point '(2,0)';?column?----------(2,4)(1 row)internals=> select point '(1,2)' * point '(3,0)';?column?----------(3,6)(1 row)internals=> select circle '((0,0),1)' * point '(3,0)';?column?-----------<(0,0),3>(1 row)internals=> select circle '((1,1),1)' * point '(3,0)';?column?-----------<(3,3),3>(1 row)
如果乘数为“point '0,1'”,则相当于几何对象逆时针旋转90度,而如果乘数为“point '0,- 1'”,则表示顺时针旋转90度,示例如下:
internals=> select point '(1,2)' * point '(0,1)';?column?----------(-2,1)(1 row)internals=> select point '(1,2)' * point '(0,-1)'internals-> ;?column?----------(2,-1)(1 row)internals=> select circle '((0,0),1)' * point '(0,1)';?column?-----------<(0,0),1>(1 row)internals=> select circle '((1,1),1)' * point '(0,1)';?column?------------<(-1,1),1>(1 row)
2、运算符“#”
运算符“#”有以下几种用法:
对于两个线段,计算出交点。
对于两个矩形,计算出相交的矩形。
对于路径或多边形,则计算出顶点数。
两个线段的示例如下:
internals=> select lseg '(0,0), (2,2)' # lseg '(0,2), (2,0)';?column?----------(1,1)(1 row)
如果两个线段没有相交,则返回空:
internals=> select lseg '(0,0), (1,1)' # lseg '(2,2), (3,3)';?column?----------(1 row)
两个矩形的示例如下:
internals=> select box '(0,0), (2,2)' # box '(1,0), (3,1)';?column?-------------(2,1),(1,0)(1 row)
路径或多边形的示例如下:
internals=> select # path '(1,1), (2,2), (3,3)';?column?----------3(1 row)internals=> select # polygon '(1,1), (2,2), (3,3)';?column?----------3(1 row)
3、运算符“@-@”
运算符“@-@”为一元运算符,参数的类型只能为“lseg”“path”。一般用于计算几何对 象的长度,下面来看看相关示例。
计算线段长度的示例如下:
internals=> select @-@ lseg '(0,0), (1,1)';?column?--------------------1.4142135623730951(1 row)
计算path长度的示例如下:
internals=> select @-@ path '(0,0), (2,2)', @-@ path '(0,0), (1,1),(2,2)';?column? | ?column?-------------------+-------------------5.656854249492381 | 5.656854249492381(1 row)
注意,开放式路径与闭合路径的长度是不一样的,示例如下:
internals=> select @-@ path '[(0,0), (1,1),(0,1)]';?column?-------------------2.414213562373095(1 row)internals=> select @-@ path '(0,0), (1,1),(0,1)';?column?-------------------3.414213562373095(1 row)
4、运算符“@@”
运算符“@@”为一元运算符,用于计算中心点,示例如下
internals=> select @@ circle '<(1,1), 2>';?column?----------(1,1)(1 row)internals=> select @@ box '(0,0), (1,1)';?column?-----------(0.5,0.5)(1 row)internals=> select @@ lseg '(0,0), (1,1)';?column?-----------(0.5,0.5)(1 row)
5、运算符“##”
运算符“##”为二元运算符,用于计算两个几何对象上距离最近的点,示例如下
internals=> select point '(0,0)' ## lseg '((2,0),(0,2))';?column?----------(1,1)(1 row)internals=> select point '(0,0)' ## box '((1,1),(2,2))';?column?----------(1,1)(1 row)internals=> select lseg '(1,0),(0,1.5)' ## lseg'((2,0),(0,2))';?column?-------------(0.25,1.75)(1 row)
6、运算符“<->”
运算符“<->”为二元运算符,用于计算两个几何对象之间的间距,示例如下:
internals=> select lseg '(0,1),(1,0)' <-> lseg'((0,2),(2,0))';?column?--------------------0.7071067811865476(1 row)internals=> select circle '((0,0),1)' <-> circle '((3,0),1)';?column?----------1(1 row)internals=> select circle '((0,0),1)' <-> circle '((2,2),1)';?column?--------------------0.8284271247461903(1 row)
对于两个矩形来说,它们之间的间距实际上是中心点之间的距离:
internals=> select box '((0,0),(1,1))' <-> box '((2,0),(4,1))';?column?----------2.5(1 row)internals=> select box '((0,0),(1,1))' <-> box '((1,1),(2,2))';?column?--------------------1.4142135623730951(1 row)
7、运算符“&&”
运算符“&&”为二元运算符,用于计算两个几何对象之间是否重叠,只要有一个共同 点,返回结果即为真,示例如下:
internals=> select box '((0,0),(1,1))' && box '((1,1),(2,2))';?column?----------t(1 row)internals=> select box '((0,0),(1,1))' && box '((2,2),(3,3))';?column?----------f(1 row)internals=> select circle '((0,0),1)' && circle '((1,1),1)';?column?----------t(1 row)internals=> select circle '((0,0),1)' && circle '((2,2),1)';?column?----------f(1 row)internals=> select polygon '(0,0),(2,2),(0,2)' && polygon '(0,1),(1,1),(2,0)';?column?----------t(1 row)
8、判断两个对象相对位置的运算符
判断左右位置的运算符有4个,具体如下。
<<:是否严格在左。
>>:是否严格在右。
&<:没有延展到右边。
&>:没有延展到左边。
判断上下位置的运算符有6个,具体如下:
<<|:严格在下。 |>>:严格在上。 &<|:没有延展到上面。 |&>:没有延展到下面。 <^:在下面(允许接触)。 >^:在上面(允许接触)。
判断两个对象相对位置的其他运算符如下:
?#:是否相交。 ?-:是否水平或水平对齐。 ?|:是否竖直或竖直对齐。 ?-|:两个对象是否垂直。 ?||:两个对象是否平行。 @>:是否包含。 <@:包含或在其上。
相关示例:
internals=> select box '((0,0),(1,1))' << box '((1.1,1.1),(2,2))';?column?----------t(1 row)internals=> select polygon '(0,0),(0,1),(1,0)' << polygon '(0,1.1),(1.1,1.1),(1.1,0)';?column?----------f(1 row)internals=> select polygon '(0,0),(0,1),(1,0)' << polygon '(1.1,0),(1.1,1),(2,0)';?column?----------t(1 row)internals=> select circle '((0,0),1)' << circle '((1,1),1)';?column?----------f(1 row)internals=> select circle '((0,0),1)' << circle '((3,3),1)';?column?----------t(1 row)
9、判断两个几何对象是否相同的运算符“~="
对于多边形,如果表示的起点不同,但实现上它们是两个相同的多边形,那么相应的 判断代码如下:
internals=> select polygon '((0,0),(1,1))' ~= polygon '((1,1),(0,0))';?column?----------t(1 row)internals=> select polygon '((0,0),(1,1),(1,0))' ~= polygon '((1,1),(0,0),(1,0))';?column?----------t(1 row)
对于矩形,示例代码如下:
internals=> select box '(0,0),(1,1)' ~= box '(1,1),(0,0)';?column?----------t(1 row)
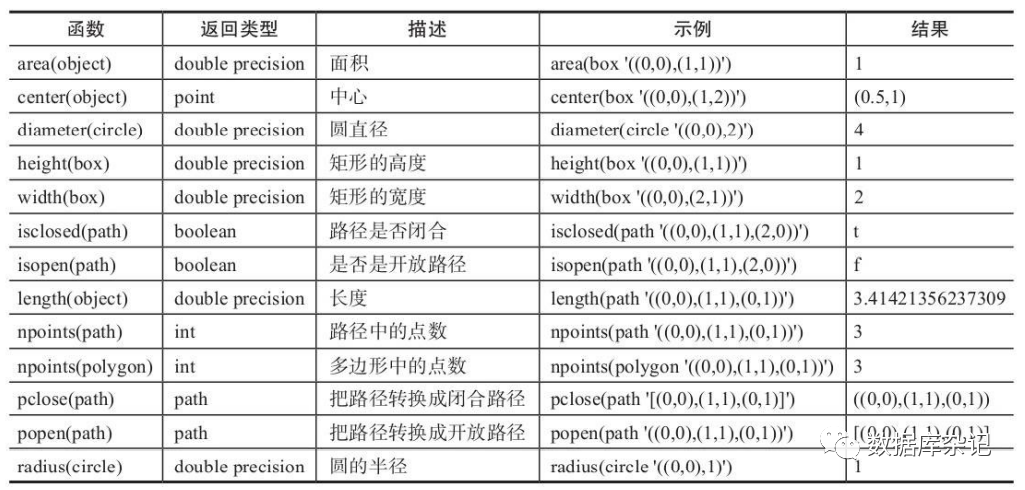
5.4.4、几何类型的函数
相关函数列表如下:
不同的几何类型间还可以进行互相转换,相关的转换函数如下表:
5.5、网络地址类型
PostgreSQL为IPv4、IPv6以及以太网MAC地址都提供了特有的类型,使用这些类型存储IP地址、MAC地址相对于用字符串存储这些类型来说,不容易产生歧义,同时提供了 相应的函数让IP地址的运算更方便。
PostgreSQL提供了专门的数据类型来存储IPv4、IPv6和MAC地址。这比使用字符串效 果更好一些,因为使用这些类型有助于更好地做检测。
5.5.1、网络地址类型概况
PostgreSQL提供了专门的数据类型来存储IPv4、IPv6和MAC地址。这比使用字符串效 果更好一些,因为使用这些类型有助于更好地做检测。
网络地址类型列表

5.5.2、inet与cidr类型
inet和cidr类型都可以用于存储一个IPv4或IPv6的地址,示例如下:
internals=> select '192.168.1.100'::inet;inet---------------192.168.1.100(1 row)internals=> select '192.168.1.100'::cidr;cidr------------------192.168.1.100/32(1 row)
这两种类型输入IPv4地址的格式相同,具体如下:
x.x.x.x/masklen
其掩码可以省略,格式如下: x.x.x.x
注意,掩码的长度都是用一个数字表示的,不能使用如下格式:
internals=> select '198.168.1.100/255.255.255.0'::cidr;ERROR: invalid input syntax for type cidr: "198.168.1.100/255.255.255.0"LINE 1: select '198.168.1.100/255.255.255.0'::cidr;^internals=> select '198.168.1.100 255.255.255.0'::inet;ERROR: invalid input syntax for type inet: "198.168.1.100 255.255.255.0"LINE 1: select '198.168.1.100 255.255.255.0'::inet;
IPv6地址的输入格式如下:ipv6_addr/masklen
其中ipv6_addr可以使用标准的IPv6地址表示方式,即分为8组,每组为4个十六进制数 的形式,具体格式如下:
DA70:0000:0000:0000:ABCD:0000:00F7:0003
如果觉得上面的表示方法太长,还可以使用零压缩法缩短输入。如果几个连续段位的 值都是“0”,那么这些“0”就可以简单地以“::”来表示,上面的输入就可以压缩表示如下:
DA70::ABCD:0000:00F7:0003
需要注意的是,只能简化连续为“0”的组,每个组中间和后面的“0”都要保留,比如“D A70”最后的这个“0”不能简化,并且这种简化方式只能用一次,上例中“ABCD”后面的“00 00”就不能再进行简化了。这个限制是为了能准确还原被压缩的“0”,不然就无法确定每个 “::”究竟代表多少个“0”。不过,各组前导的“0”是可以省略的,如“DA70::ABCD:0000:00F 7:0003”与“DA70::ABCD:0000:F7:3”是相同的。
以下几个IPv6地址都是等价的:
DA70:0000:0000:0000:ABCD:0000:00F7:0003DA70:0000::ABCD:0000:00F7:0003DA70::ABCD:0000:00F7:0003DA70:0000:0000:0000:ABCD::00F7:0003DA70::ABCD:0:F7:3
一个IPv6地址可以将一个IPv4地址内嵌进去,这样就把IPv6的地址写成了IPv6地址和I Pv4地址混合的形式。IPv6内嵌IPv4的方式有两种:
IPv4映像地址。 IPv4兼容地址。
IPv4映像地址格式如下:::ffff:192.168.1.100
这个地址仍然是一个IPv6地址,是“::ffff:c0a8:164”的另一种写法。IPv4兼容地址的写法如下:::192.168.1.100
, 这个地址仍然是一个IPv6地址,它是“::c0a8:164”的另一种写法。
inet与cidr的区别:
对于inet来说,如果子网掩码是32并且地址是IPv4,那么它不表示任何子网,所表示 的只是一台主机的地址,示例如下:
internals=> select '192.168.1.100/32'::inet;inet---------------192.168.1.100(1 row)
同样,IPv6地址长度是128位,因此在inet中128位的掩码也表明是一个主机地址,而 不是一个子网地址:
internals=> select '::10.2.3.4/128'::inet;inet------------::10.2.3.4(1 row)
而cidr总是显示出掩码,示例如下:
internals=> select '198.168.1.100'::cidr;cidr------------------198.168.1.100/32(1 row)internals=> select '198.168.1.100/32'::cidr;cidr------------------198.168.1.100/32(1 row)
cidr总是对地址与掩码之间的关系进行检查,如果不正确会报错,示例如下:
internals=> select '192.168.1.100/16'::inet;inet------------------192.168.1.100/16(1 row)internals=> select '192.168.1.100/16'::cidr;ERROR: invalid cidr value: "192.168.1.100/16"LINE 1: select '192.168.1.100/16'::cidr;^DETAIL: Value has bits set to right of mask.
5.5.3、macaddr类型
macaddr类型用于存储以太网的MAC地址,可以接受多种自定义格式,示例如下:
'00:e0:4c:75:7d:5a''00-e0-4c-75-7d-5a''00e04c-757d5a''00e04c:757d5a''00e0.4c75.7d5a''00e04c757d5a'
上面声明的是同一个MAC地址。对于数据位中的“a”到“f”,大小写都可以。输出总是 上面的第一种形式,示例如下:
internals=> select '00e04c757d5a'::macaddr;macaddr-------------------00:e0:4c:75:7d:5a(1 row)internals=> select '00e04c:757d5a'::macaddr;macaddr-------------------00:e0:4c:75:7d:5a(1 row)internals=> select '00-e0-4c-75-7d-5a'::macaddr;macaddr-------------------00:e0:4c:75:7d:5a(1 row)
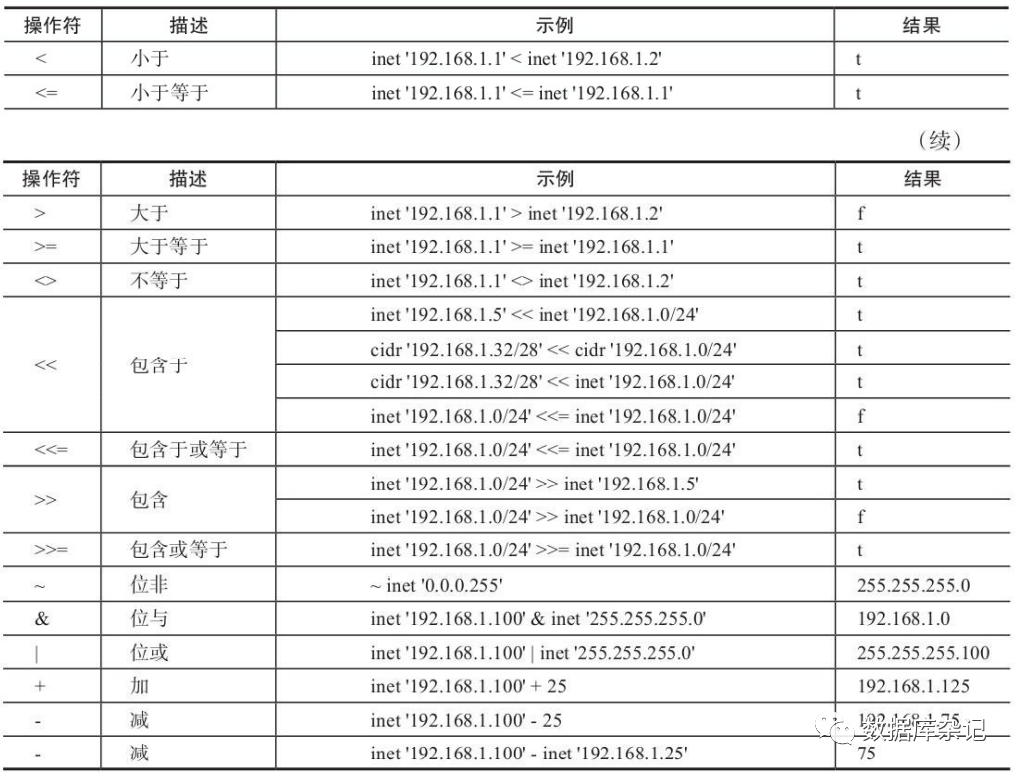
5.5.4、网络地址类型的操作符
1)、cidr和inet类型的操作符
macaddr类型支持一些简单的比较运算符和位运算符
2)、macaddr类型支持的操作符

5.5.5、网络地址类型的函数
1)、可以用于cidr类型和inet类型的函数
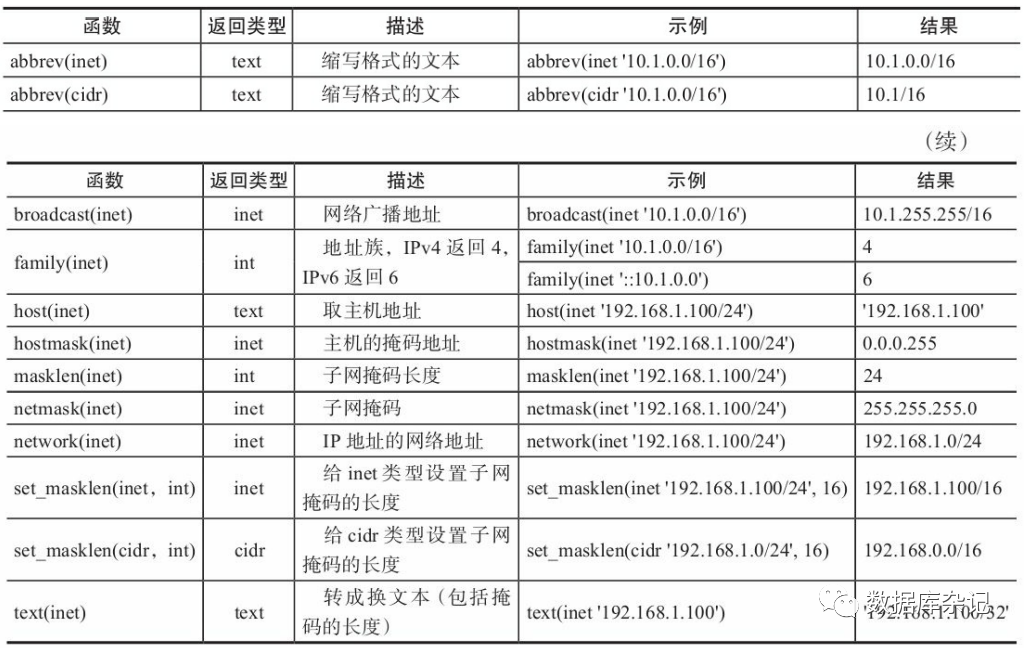
2)、可用于macaddr类型的函数
只有一个trunc(macaddr),此函数把MAC地址的后3个字节 置为0,示例如下:
internals=> select trunc(macaddr '00e04c757d5a');trunc-------------------00:e0:4c:00:00:00(1 row)
5.6、XML类型
xml类型可用于存储XML数据。使用字符串类型(如text类型)也可以存储XML数据 ,但text类型不能保证其中存储的是合法的XML数据,通常需要由应用程序来负责保证所 输入数据的正确性,这会增加应用程序的开发难度,而使用xml类型就不存在此类问题, 数据库会对输入的数据进行检查,使不符合XML标准的数据不能存放到数据库中,同时 还提供了函数对其类型进行安全性检查。注意,要使用xml数据类型,在编译PostgreSQL源码时必须使用以下参数:
configure --with-libxml
5.6.1、XML类型的输入
与其他类型类似,可以使用下面两种语法来输入xml类型的数据:
xml '<osdba>hello world</osdba>''<osdba>hello world</osdba>'::xml
示例如下:
internals=> select xml '<osdba>hello world</osdba>';xml----------------------------<osdba>hello world</osdba>(1 row)internals=> select '<osdba>hello world</osdba>'::xml;xml----------------------------<osdba>hello world</osdba>(1 row)
xml中存储的XML数据有以下两种:
由XML标准定义的documents 由XML标准定义的content片段
content片段可以有多个顶级元素或character节点。但documents只能有一个顶级元素。可以使用“xmlvalue IS DOCUMENT”来判断一个特定的XML值是一个documents还是conten t片段。
PostgreSQL的xmloptions参数用来指定输入的数据是documents还是content片段,默认 情况下此值为content片段,所以输入的xml可以有多个顶级元素,但如果我们把此参数设 置成“document”,将不能输入有多个顶级元素的内容,示例如下:
internals=> show xmloption;xmloption-----------content(1 row)internals=> select xml '<a>a</a><b>b</b>';xml------------------<a>a</a><b>b</b>(1 row)internals=> SET xmloption TO document;SETinternals=> select xml '<a>a</a><b>b</b>';ERROR: invalid XML documentLINE 1: select xml '<a>a</a><b>b</b>';^DETAIL: line 1: Extra content at the end of the document<a>a</a><b>b</b>^
也可以通过函数xmlparse由字符串数据来产生xml类型的数据,使用xmlparse函数是S QL标准中将字串转换成xml的唯一方法。
函数xmlparse的语法如下:
XMLPARSE ( { DOCUMENT | CONTENT } value)
此函数中的参数“DOCUMENT”和“CONTENT”表示指定XML数据的类型。
示例如下:
internals=> SELECT xmlparse (document '<?xml version="1.0"?><person><name>John</name><sex>F</sex></person>');xmlparse------------------------------------------------<person><name>John</name><sex>F</sex></person>(1 row)internals=> SELECT xmlparse (content '<person><name>John</name><sex>F</sex></person>');xmlparse------------------------------------------------<person><name>John</name><sex>F</sex></person>(1 row)
5.6.2、XML字符集问题
PostgreSQL数据库在客户端与服务器之间传递数据时,会自动进行字符集的转换。如 果客户端的字符集与服务端不一致,PostgreSQL会自动进行字符集转换。但也正是因为这 一特性,用户在传递XML数据时需要格外注意。我们知道,对于XML文件来说,可以通 过类似“encoding="XXX"”的方式指定自己文件的字符集,但当这些数据在PostgreSQL之间 传递时,PostgreSQL会把其原始内容的字符集变成数据库服务端的字符集,这会导致一系 列问题,因为这意味着XML数据中的字符集编码声明在客户端和服务器之间传递时,可 能变得无效。为了应对该问题,提交输入到xml类型的字符串中的编码声明将会被忽略, 同时内容的字符集会被认为是当前数据库服务器的字符集。
正确处理XML字符集的方式是,将XML数据的字符串在当前客户端中编码成当前客 户端的字符集,在发送到服务端后,再转换成服务端的字符集进行存储。当查询xml类型 的值时,此数据又会被转换成客户端的字符集,所以客户端收到的XML数据的字符集就 是客户端的字符集。
所以通常来说,如果XML数据的字符集编码、客户端字符集编码以及服务器字符集 编码完全一致,那么用PostgreSQL来处理XML数据将会大大减少字符集问题,并且处理 效率也会很高。通常XML数据都是以UTF-8编码格式进行处理的,因此把PostgreSQL数据 库服务器端编码也设置成UTF-8将是一种不错的选择。
5.6.3、XML类型函数
1)、生成XML内容的函数
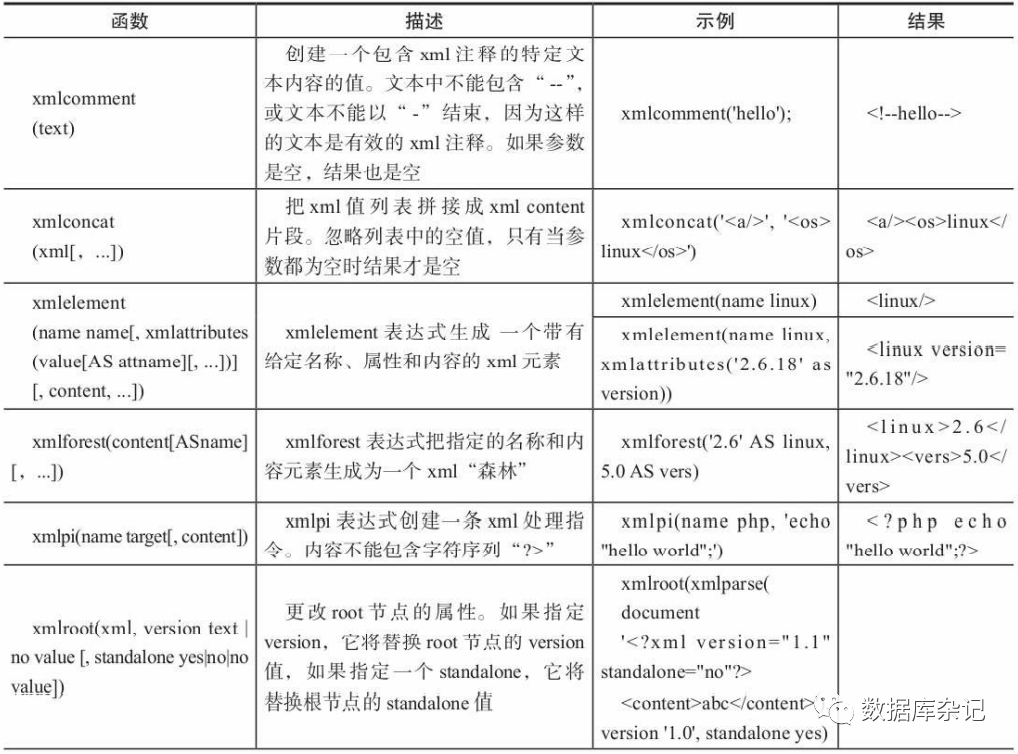
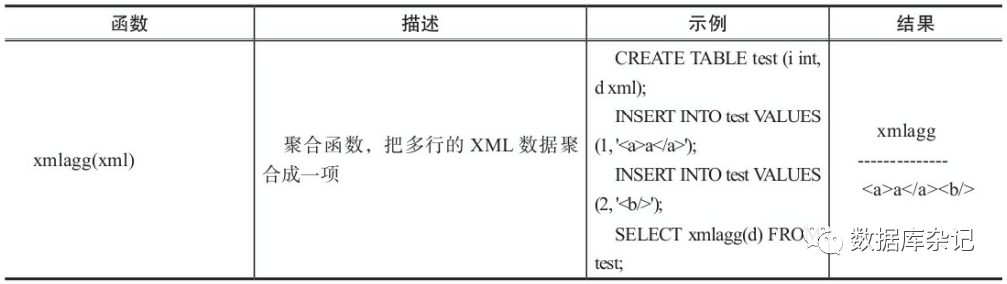
PostgreSQL中提供了xpath函数来计算XPath1.0表达式的结果。XPath是W3C的一个标 准,它最主要的目的是在XML1.0或XML1.1文档节点树中定位节点。目前有XPath1.0和XP ath2.0两个版本。其中XPath1.0是1999年成为W3C标准的,而XPath2.0标准的确立是在200 7年,目前PostgreSQL只支持XPath1.0的表达式。
xpath函数的定义如下:xpath(xpath, xml[, nsarray])
此函数的第一个参数是一个XPath1.0表达式,第二个参数是一个xml类型的值,第三 个参数是一个命名空间的数组映射。该数组应该是一个二维数组,第二维的长度等于2, 即包含两个元素。
示例如下:
SELECT xpath('/my:a/text()', '<my:a xmlns:my="http://example.com">test</my:a>',ARRAY[ARRAY['my','http://example.com']]);xpath--------{test}(1 row)
处理默认命名空间的访问示例如下:
SELECT xpath('//mydefns:b/text()', '<a xmlns="http://example.com"><b>test</b></a>',ARRAY[ARRAY['mydefns', 'http://example.com']]);xpath--------{test}(1 row)
2)、内容导出相关函数
PostgreSQL还提供了把数据库中的内容导出成XML数据的以下函数:
·table_to_xmlschema(tbl regclass,nulls boolean,tableforest boolean,targetns text)。·query_to_xmlschema(query text,nulls boolean,tableforest boolean,targetns text)。·cursor_to_xmlschema(cursor refcursor,nulls boolean,tableforest boolean,targetns text)。·table_to_xml_and_xmlschema(tbl regclass,nulls boolean,tableforest boolean,targetnstext)。·query_to_xml_and_xmlschema(query text,nulls boolean,tableforest boolean,targetns text)。·schema_to_xml(schema name,nulls boolean,tableforest boolean,targetns text)。·schema_to_xmlschema(schema name,nulls boolean,tableforest boolean,targetns text) 。·schema_to_xml_and_xmlschema(schema name,nulls boolean,tableforest boolean,targetns text)。·database_to_xml(nulls boolean,tableforest boolean,targetns text)。·database_to_xmlschema(nulls boolean,tableforest boolean,targetns text)。·database_to_xml_and_xmlschema(nulls boolean,tableforest boolean,targetns text)。
下面来举例说明这几个函数的使用方法。
首先创建一张测试表。
CREATE TABLE test01(id int, note text);INSERT INTO test01 select seq, repeat(seq::text, 2) from generate_series(1,5) as t(seq);
下面来看其中第一个函数table_to_xmlschema的使用方法:
internals=> select table_to_xmlschema('test01'::regclass, true, true, 'tangspace');table_to_xmlschema--------------------------------------------------------------------------------------------------<xsd:schema +xmlns:xsd="http://www.w3.org/2001/XMLSchema" +targetNamespace="tangspace" +elementFormDefault="qualified"> ++<xsd:simpleType name="INTEGER"> +<xsd:restriction base="xsd:int"> +<xsd:maxInclusive value="2147483647"/> +<xsd:minInclusive value="-2147483648"/> +</xsd:restriction> +</xsd:simpleType> ++<xsd:simpleType name="UDT.internals.pg_catalog.text"> +<xsd:restriction base="xsd:string"> +</xsd:restriction> +</xsd:simpleType> ++<xsd:complexType name="RowType.internals.public.test01"> +<xsd:sequence> +<xsd:element name="id" type="INTEGER" nillable="true"></xsd:element> +<xsd:element name="note" type="UDT.internals.pg_catalog.text" nillable="true"></xsd:element>+</xsd:sequence> +</xsd:complexType> ++<xsd:element name="test01" type="RowType.internals.public.test01"/> ++</xsd:schema>(1 row)
从上面的结果中可以看出,此函数把表的定义转换成了xml格式。
再来看第二个函数query_to_xmlschema的使用方法:
internals=> select query_to_xmlschema('SELECT * FROM test01', true, true, 'tangspace');query_to_xmlschema--------------------------------------------------------------------------------------------------<xsd:schema +xmlns:xsd="http://www.w3.org/2001/XMLSchema" +targetNamespace="tangspace" +elementFormDefault="qualified"> ++<xsd:simpleType name="INTEGER"> +<xsd:restriction base="xsd:int"> +<xsd:maxInclusive value="2147483647"/> +<xsd:minInclusive value="-2147483648"/> +</xsd:restriction> +</xsd:simpleType> ++<xsd:simpleType name="UDT.internals.pg_catalog.text"> +<xsd:restriction base="xsd:string"> +</xsd:restriction> +</xsd:simpleType> ++<xsd:complexType name="RowType"> +<xsd:sequence> +<xsd:element name="id" type="INTEGER" nillable="true"></xsd:element> +<xsd:element name="note" type="UDT.internals.pg_catalog.text" nillable="true"></xsd:element>+</xsd:sequence> +</xsd:complexType> ++<xsd:element name="row" type="RowType"/> ++</xsd:schema>(1 row)
从上面的结果中可以看到query_to_xmlschema把查询结果中行的定义转成了xml格式。
cursor_to_xmlschema函数与前两个函数的意义相同,这里不再赘述。我们再来看看函数table_to_xml_and_xmlschema和query_to_xml_and_xmlschema的使用 方法:
internals=> select table_to_xml_and_xmlschema('test01'::regclass, true, true, 'tangspace');table_to_xml_and_xmlschema--------------------------------------------------------------------------------------------------<xsd:schema +xmlns:xsd="http://www.w3.org/2001/XMLSchema" +targetNamespace="tangspace" +elementFormDefault="qualified"> ++<xsd:simpleType name="INTEGER"> +<xsd:restriction base="xsd:int"> +<xsd:maxInclusive value="2147483647"/> +<xsd:minInclusive value="-2147483648"/> +</xsd:restriction> +</xsd:simpleType> ++<xsd:simpleType name="UDT.internals.pg_catalog.text"> +<xsd:restriction base="xsd:string"> +</xsd:restriction> +</xsd:simpleType> ++<xsd:complexType name="RowType.internals.public.test01"> +<xsd:sequence> +<xsd:element name="id" type="INTEGER" nillable="true"></xsd:element> +<xsd:element name="note" type="UDT.internals.pg_catalog.text" nillable="true"></xsd:element>+</xsd:sequence> +</xsd:complexType> ++<xsd:element name="test01" type="RowType.internals.public.test01"/> ++</xsd:schema> ++<test01 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangspace"> +<id>1</id> +<note>11</note> +</test01> ++<test01 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangspace"> +<id>2</id> +<note>22</note> +</test01> ++<test01 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangspace"> +<id>3</id> +<note>33</note> +</test01> ++<test01 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangspace"> +<id>4</id> +<note>44</note> +</test01> ++<test01 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangspace"> +<id>5</id> +<note>55</note> +</test01> ++(1 row)
从上面的运行结果中可以看出,table_to_xml_and_xmlschema函数与table_to_xmlsche ma函数的唯一不同之处在于把表中的数据也导出到xml中了。query_to_xml_and_xmlschem a函数与table_to_xml_and_xmlschema的差异这里不再赘述。
下面来看看函数schema_to_xml、schema_to_xmlschema和schema_to_xml_and_xmlsche ma的使用方法:
internals=> select schema_to_xml('public', true, true, 'tangnamespace');schema_to_xml--------------------------------------------------------------------------------------<public xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="tangnamespace">++<t> +<id>1</id> +<col2>true</col2> +</t> ++<t> +<id>2</id> +<col2>false</col2> +</t> ++<t> +<id>3</id> +<col2>true</col2> +</t> ++<t> +<id>4</id> +<col2>false</col2> +</t> ++<t> +<id>5</id> +<col2 xsi:nil="true"/> +</t> +</public> +(1 row)
从上面的运行结果中可以看出,schema_to_xml把一个schema中的数据全部导成了xml 格式。可以想象,schema_to_xmlschema只是导出了schema的定义,而schema_to_xml_and_x mlschema则是导出了全部定义及数据。另外3个函数database_to_xml、database_to_xmlschema、database_to_xml_and_xmlsche ma只针对某个数据库对象,这里不再赘述。
5.7、JSON类型
5.7.1、JSON类型简介
JSON数据类型可以用来存储JSON(JavaScript Object Notation)数据,而JSON数据格 式是在RFC 4627中定义的。当然也可以使用text、varchar等类型来存储JSON数据,但使 用这些通用的字符串格式将无法自动检测字符串是否为合法的JSON数据。而且,JSON数 据类型还可以使用丰富的函数。
JSON数据类型是从PostgreSQL 9.3版本开始提供的,在9.3版本中只有一种类型JSON ,在PostgreSQL 9.4版本中又提供了一种更高效的类型JSONB,这两种类型在使用上几乎 完全一致,两者主要区别是,JSON类型是把输入的数据原封不动地存放到数据库中(当 然在存储前会做JSON的语法检查),使用时需要重新解析数据,而JSONB类型是在存储 时就把JSON解析成二进制格式,使用时就无须再次解析,所以JSONB在使用时性能会更 高。另外,JSONB支持在其上建索引,而JSON则不支持,这是JSONB类型一个很大的优 点。
而JSONB类型则恰恰相反,既不会保留多余的空格,也不会保留key的顺序和重复 的key。
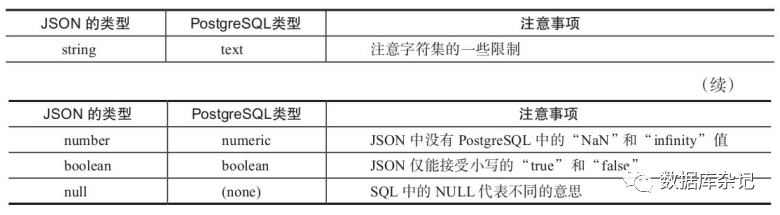
当把一个JSON类型的字符串转换成JSONB类型时,JSON字符串内的数据类型实际上 被转换成了PostgreSQL数据库中的类型,两者的映射关系见下表。需要注意的是,如果 是在JSONB中,不能输入超出PostgreSQL的numeric数据类型范围的值。
5.7.2、JSON类型的输入与输出
这里举例来说明JSON类型的使用方法。首先来看单个值的示例,具体如下:
select '9'::json, '"osdba"'::json, 'true'::json, 'null'::json;json | json | json | json------+---------+------+------9 | "osdba" | true | null(1 row)
当然也可以使用把类型名放在单引号的字符串前面的格式,示例如下:
select json '"osdba"', json '9', json 'true', json 'null';json | json | json | json---------+------+------+------"osdba" | 9 | true | null
使用JSONB类型也一样,示例如下:
select jsonb '"osdba"', jsonb '9', jsonb 'true', jsonb 'null';jsonb | jsonb | jsonb | jsonb---------+-------+-------+-------"osdba" | 9 | true | null
JSON中使用数组及其它各种类型的示例如下:
SELECT '[9, true, "osdba", null]'::json, '[9, true, "osdba", null]'::jsonb;json | jsonb--------------------------+--------------------------[9, true, "osdba", null] | [9, true, "osdba", null]SELECT json '{"name": "osdba", "age": 40, "sex": true, "money" : 250.12}';json-------------------------------------------------------------{"name": "osdba", "age": 40, "sex": true, "money" : 250.12}select json '{"p" : 1.6735777674525e-27}';json-----------------------------{"p" : 1.6735777674525e-27}select jsonb '{"p" : 1.6735777674525e-27}';jsonb---------------------------------------------------{"p": 0.0000000000000000000000000016735777674525}
从上面的示例中可以看出,JSONB类型内部存储的是numeric类型,而不再是浮点数。
5.7.3、JSON类型的操作符
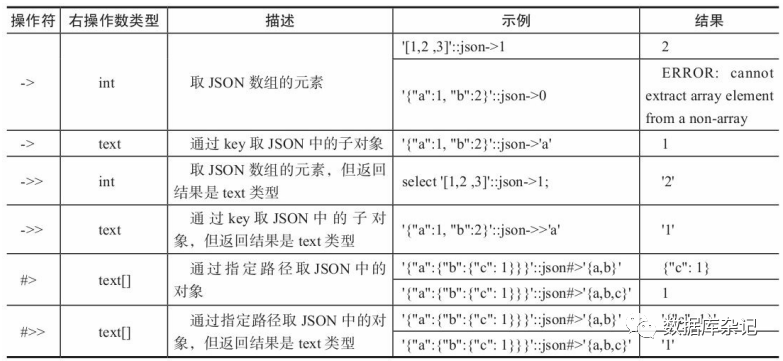
1)、JSON类型及JSONB类型支持的操作符
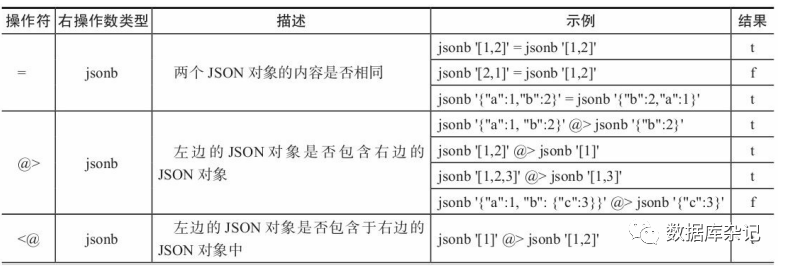
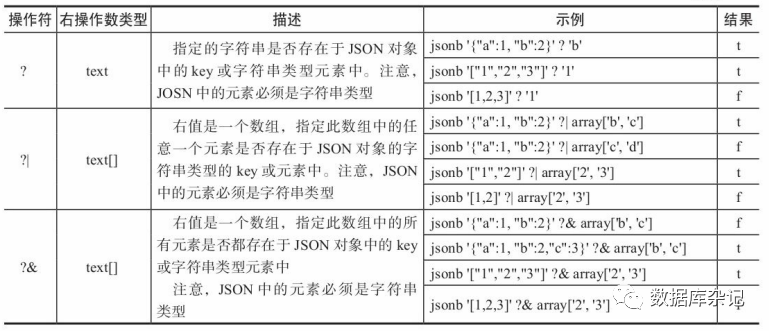
2)、还有一些操作符仅可用于JSONB类型,这部分操作符见表
PostgreSQL中提供了很多用于创建、操作JSON类型数据的函数。
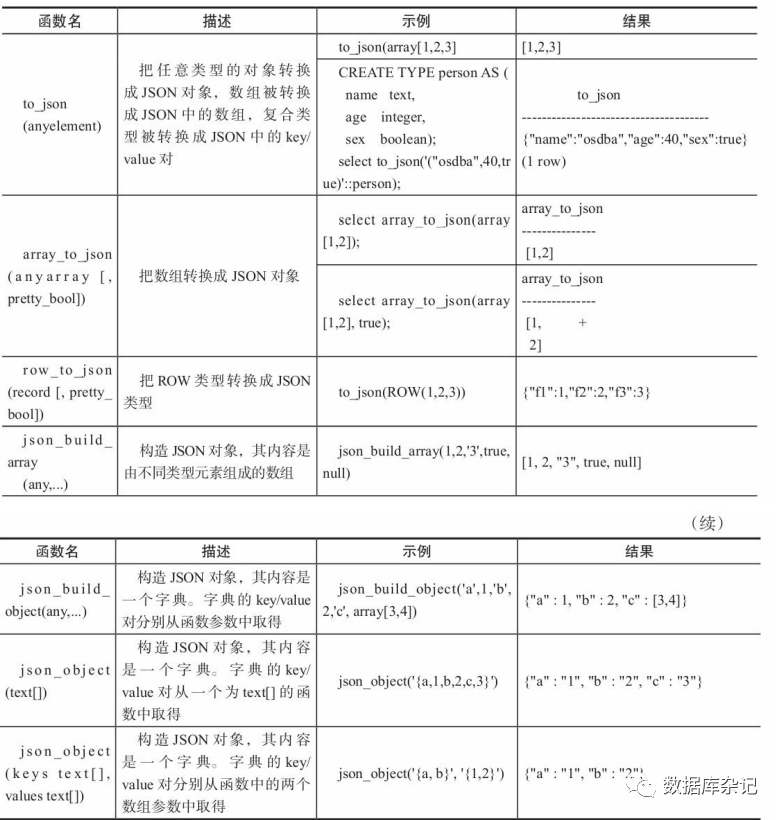
array_to_json和row_to_json除了可以指定一个pretty_bool的参数用其美化 JSON的格式之外,其功能与to_json函数完全一样。上述创建JSON的函数只能创建出JSON类型的JSON对象,而不能创建出JSONB类型 的JSON对象,但实际上可以用类型转换把JSON类型的对象转换成JSONB类型。
操作JSON类型和JSONB类型数据的函数, 如下表:





中以“jsonb_path”开头的几个函数是PostgreSQL 12版本中开始加入的,同时增 加了数据类型jsonpath,jsonpath是一个功能非常强大的表达式,称为“SQL/JSON Path Language”,具体的使用方法请参见PostgreSQL官方文档:SQL/JSON Path Language
5.7.5、JSON类型的索引
因为JSON类型没有提供相关的比较函数,所以无法在JSON类型的列上直接建索引, 但可以在JSON类型的列上建函数索引。
JSONB类型的列上可以直接建索引。除了可以建BTree索引以外,JSONB还支持建GIN索引。GIN索引可以高效地从JSONB内部的key/value对中搜索数据。
通常情况下,在JSONB类型上都会考虑建GIN索引,而不是BTree索引,因为该索引 的效率可能不高,原因是BTree索引不关心JSONB内部的数据结构,只是简单地按照比较 整个JSONB大小的方式进行索引,其比较原则如下:
Object>Array>Boolean>Number>String>Null。
n个key/value对的Object>n-1个key/value对的Object。
n个元素的Array>n-1个元素的Array。
Object内部的多个比较顺序如下:key-1,value-1,key-2,value-2,… 键值之间的比较是按存储顺序进行的,
示例如下:{"aa":1,"a1":1}>{"b":1,"b1":1} 同样,数组是按元素的顺序进行比较的:element-1,element-2,element-3,… 在JSONB上创建GIN索引有以下两种方式:
使用默认的jsonb_ops操作符创建。
使用jsonb_path_ops操作符创建。
使用默认的操作符创建GIN索引的语法如下:
CREATE INDEX idx_name ON table_name USING gin (index_col);
使用jsonb_path_ops操作符建GIN索引的语法如下:
CREATE INDEX idx_name ON table_name USING gin (index_col jsonb_path_ops);
关于GIN索引,jsonb_ops的GIN索引与jsonb_path_ops的GIN索引区别在于,jsonb_ops 的GIN索引中JSONB数据中的每个key和value都是作为一个单独的索引项,而jsonb_path_o ps则只为每个value创建一个索引项。例如:有一个项“{"foo":{"bar":"baz"}}”,对于jsonb_ path_ops来说,是把“foo”“bar”和“baz”组合成一个Hash值作为索引项,而jsonb_ops则会分 别为“foo”“bar”“baz”创建3个索引项。因为少了很多索引项,所以通常jsonb_path_ops的索 引要比jsonb_ops的小很多,这样当然也就会带来性能的提升。
下面举例说明如何使用索引,先来看JSON类型上建函数索引的例子。
首先,创建测试表,并插放一些初始化的数据:
CREATE TABLE jtest01 (id int,jdoc json);CREATE OR REPLACE FUNCTION random_string(INTEGER)RETURNS TEXT AS$BODY$SELECT array_to_string(ARRAY (SELECT substring('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'FROM (ceil(random()*62))::int FOR 1)FROM generate_series(1, $1)),'')$BODY$LANGUAGE sql VOLATILE;insert into jtest01 select t.seq, ('{"a":{"a1":"a1a1", "a2":"a2a2"}, "name":"'||random_string(10)||'","b":"bbbbb"}')::json from generate_series(1,100000) as t(seq);
然后使用函数json_extract_path_text建一个函数索引:
CREATE INDEX ON jtest01 USING btree (json_extract_path_text(jdoc,'name'));-- 分析该表:ANALYZE jtest01;
接下来看看查询没有走索引的执行计划:
osdba=# EXPLAIN ANALYZE VERBOSE SELECT * FROM jtest01 WHERE jdoc->>'name'='lnBtcJLR85';QUERY PLAN--------------------------------------------------------------------------------Seq Scan on public.jtest01 (cost=0.00..2735.00 rows=500 width=36) (actual tim..e=17.764..154.870 rows=1 loops=1)Output: id, jdocFilter: ((jtest01.jdoc ->> 'name'::text) = 'lnBtcJLR85'::text)Rows Removed by Filter: 99999Planning time: 0.141 msExecution time: 154.911 ms(6 rows)Time: 155.583 ms
然后再看走了此函数索引的执行计划:
osdba=# EXPLAIN ANALYZE VERBOSE SELECT * FROM jtest01 WHERE json_extract_path_text(jdoc, 'name') = 'lnBtcJLR85';QUERY PLAN--------------------------------------------------------------------------------Index Scan using jtest01_json_extract_path_text_idx on public.jtest01 (cost=0...42..8.44 rows=1 width=36) (actual time=0.044..0.046 rows=1 loops=1)Output: id, jdocIndex Cond: (json_extract_path_text(jtest01.jdoc, VARIADIC '{name}'::text[]).. = 'lnBtcJLR85'::text)Planning time: 0.237 msExecution time: 0.085 ms(5 rows)Time: 1.153 ms
从上面的对比可以看出,走了索引花费的时间为1.153ms,而没有走索引花费的时间 为155.583ms,可见走索引快了150倍左右。下面再来看一个JSONB类型上建GIN索引的例子。创建测试表如下:
CREATE TABLE jtest02 (id int,jdoc jsonb);CREATE TABLE jtest03 (id int,jdoc jsonb);
把前面建好的测试表“jtest01”中的数据导入表“jtest02”和“jtest03”中:
insert into jtest02 select id, jdoc::jsonb from jtest01;insert into jtest03 select * from jtest02;
下面创建GIN索引:
CREATE INDEX idx_jtest02_jdoc ON jtest02 USING gin (jdoc);CREATE INDEX idx_jtest03_jdoc ON jtest03 USING gin (jdoc jsonb_path_ops);
然后对表进行分析:
ANALYZE jtest02;ANALYZE jtest03;
SELECT * FROM jtest02 WHERE jdoc @> '{"name":"lnBtcJLR85"}'SELECT * FROM jtest03 WHERE jdoc @> '{"name":"lnBtcJLR85"}'
现在来看一下这两个SQL语句的执行计划:
osdba=# EXPLAIN ANALYZE VERBOSE SELECT * FROM jtest02 WHERE jdoc @> '{"name":"lnBtcJLR85"}';QUERY PLAN--------------------------------------------------------------------------------Bitmap Heap Scan on public.jtest02 (cost=1108.78..1424.97 rows=100 width=89) ..(actual time=7.108..7.109 rows=1 loops=1)Output: id, jdocRecheck Cond: (jtest02.jdoc @> '{"name": "lnBtcJLR85"}'::jsonb)Heap Blocks: exact=1-> Bitmap Index Scan on idx_jtest02_jdoc (cost=0.00..1108.75 rows=100 widt..h=0) (actual time=7.092..7.092 rows=1 loops=1)Index Cond: (jtest02.jdoc @> '{"name": "lnBtcJLR85"}'::jsonb)Planning time: 0.141 msExecution time: 7.162 ms(8 rows)Time: 7.883 msosdba=# EXPLAIN ANALYZE VERBOSE SELECT * FROM jtest03 WHERE jdoc @> '{"name":"lnBtcJLR85"}';QUERY PLAN--------------------------------------------------------------------------------Bitmap Heap Scan on public.jtest03 (cost=1884.78..2200.97 rows=100 width=89) ..(actual time=12.297..12.298 rows=1 loops=1)Output: id, jdocRecheck Cond: (jtest03.jdoc @> '{"name": "lnBtcJLR85"}'::jsonb)Heap Blocks: exact=1-> Bitmap Index Scan on idx_jtest03_jdoc (cost=0.00..1884.75 rows=100 widt..h=0) (actual time=12.280..12.280 rows=1 loops=1)Index Cond: (jtest03.jdoc @> '{"name": "lnBtcJLR85"}'::jsonb)Planning time: 0.140 msExecution time: 12.352 ms(8 rows)
从上面的运行结果中可以看到,这两个SQL都走到了索引上。接下来看看这两个索引的大小:
osdba=# select pg_indexes_size('jtest02');pg_indexes_size-----------------24731648(1 row)Time: 0.503 msosdba=# select pg_indexes_size('jtest03');pg_indexes_size-----------------11173888(1 row)Time: 0.458 ms
从上面的运行结果中可以看出,jsonb_path_ops类型的索引要比jsonb_ops的小。
5.8、Range(范围类型)
Range类型,此类型可以进行范 围快速搜索,因此在一些场景中非常有用。
Range类型是从PostgreSQL 9.2版本开始提供的一种特有的类型,用于表示范围,如一 个整数的范围、一个时间的范围,而范围底下的基本类型(如整数、时间)被称为Range 类型的subtype。
假设我们有以下需求,某个IP地址库中记录了每个地区的IP地址范围,现在需要查询 客户的IP地址属于哪个地区。该IP地址库的定义如下:
CREATE TABLE ipdb1(ip_begin inet,ip_end inet,area text,sp text);
如果我们要查询的是IP地址“115.195.180.105”属于哪个地区,则查询的SQL语句如下 :
select * from ipdb1 where ip_begin <= '115.195.180.105'::inet and ip_end >= '115.195.180.105'::inet;
因为表上没有索引,所以会进行全表扫描,执行速度会很慢。此时可以在ip_begin和i p_end上建索引,代码如下:
create index idx_ipdb_ip_start on ipdb1(ip_begin);create index idx_ipdb_ip_end on ipdb1(ip_end);
在PostgreSQL中,上面的SQL查询可以使用到这两个索引,但都是分别扫描两个索引 建位图,然后通过位图进行AND操作,执行计划如下:
explain analyze verbose select * from ipdb1 where ip_begin <= '115.195.180.105'::inet and ip_end >= '115.195.180.105'::inet;QUERY PLAN----------------------------------------------------------------------------------------------------------Seq Scan on public.ipdb1 (cost=0.00..17.80 rows=58 width=128) (actual time=0.004..0.004 rows=0 loops=1)Output: ip_begin, ip_end, area, spFilter: ((ipdb1.ip_begin <= '115.195.180.105'::inet) AND (ipdb1.ip_end >= '115.195.180.105'::inet))Planning Time: 0.430 msExecution Time: 0.022 ms(5 rows)
从上面的执行计划来看,对索引进行范围扫描效率仍不太高,那么有没有更高效的查 询方法呢?答案是肯定的,这就是使用Range类型,通过创建空间索引的方式来执行,下 面来看如何使用Range类型及空间索引。
首先,创建类似的IP地址库表:
CREATE TYPE inetrange AS RANGE (subtype = inet);CREATE TABLE ipdb2(ip_range inetrange,area text,sp text);insert into ipdb2 select ('[' || ip_begin || ',' || ip_end || ']') ::inetrange, area, sp from ipdb1;
然后创建GiST索引:
CREATE INDEX idx_ipdb2_ip_range ON ipdb2 USING gist (ip_range);
接下来就可以使用包含运算符“@>”来查找相应的数据了:
select * from ipdb2 where ip_range @> '115.195.180.105'::inet;
explain analyze verbose select * from ipdb2 where ip_range @> '115.195.180.105'::inet;QUERY PLAN---------------------------------------------------------------------------------------------------------------------------Bitmap Heap Scan on public.ipdb2 (cost=4.17..11.27 rows=3 width=96) (actual time=0.006..0.007 rows=0 loops=1)Output: ip_range, area, spRecheck Cond: (ipdb2.ip_range @> '115.195.180.105'::inet)-> Bitmap Index Scan on idx_ipdb2_ip_range (cost=0.00..4.17 rows=3 width=0) (actual time=0.005..0.005 rows=0 loops=1)Index Cond: (ipdb2.ip_range @> '115.195.180.105'::inet)Planning Time: 0.058 msExecution Time: 0.044 ms(7 rows)
从 中可以看到查询性能得到了很大的提高。
5.8.1、创建Range类型
PostgreSQL中内置了一些常用的Range类型,这些类型不需要创建就可以直接使用, 具体如下。
int4range:4字节整数的范围类型。 int8range:8字节大整数的范围类型。 numrange:numeric的范围类型。 tsrange:无时区的时间戳的范围类型。 tstzrange:带时区的时间戳的范围类型。 daterange:日期的范围类型。还可以使用CREATE TYPE函数创建Range类型,创建Range类型的语法如下:
CREATE TYPE name AS RANGE (SUBTYPE = subtype[ , SUBTYPE_OPCLASS = subtype_operator_class ][ , COLLATION = collation ][ , CANONICAL = canonical_function ][ , SUBTYPE_DIFF = subtype_diff_function ])
语法中的子项的说明如下。
SUBTYPE=subtype:指定子类型。 SUBTYPE_OPCLASS=subtype_operator_class:指定子类型的操作符。 COLLATION=collation:指定排序规则。 CANONICAL=canonical_function:如果要创建一个稀疏的Range类型而不是一个连续 的Range类型,那么就需要定义此函数。 SUBTYPE_DIFF=subtype_diff_function:定义子类型的差别函数。创建Range类型的示例如下:
CREATE TYPE floatrange AS RANGE (subtype = float8,subtype_diff = float8mi);
5.8.2、Range类型的输入与输出
Range类型的输入格式如下:
'[value1,value2]'。 '[value1,value2)'。 '(value1,value2]'。 '(value1,value2)'。 'empty'。其中“(”“)”表示范围内不包括此元素,而“[”“]”表示范围内包括此元素。如果是稀疏类 型的Range,其内部存储的格式为“'[value1,value2)'”。“'empty'”表示空,即范围内不包括任 何内容。下面通过一些示例来看Range类型的输出和输入。int4range类型的示例如下:
osdba=# select '(0,6)'::int4range;int4range-----------[1,6)(1 row)osdba=# select '[0,6)'::int4range;int4range-----------[0,6)(1 row)osdba=# select '[0,6]'::int4range;int4range-----------[0,7)(1 row)osdba=# select 'empty'::int4range;int4range-----------empty(1 row)
从上面的示例中可以看出,int4range总是把输入的格式转换成“'[value1,value2)'”格式 。稀疏类型的Range必须定义CANONICAL函数,以便用来将其转换成“'[value1,value2)'”格 式来存储。对于连续类型的Range,内部存储则是精确存储的,如numrange类型:
osdba=# select '[0,6]'::numrange;numrange----------[0,6](1 row)osdba=# select '[0,6)'::numrange;numrange----------[0,6)(1 row)osdba=# select '(0,6]'::numrange;numrange----------(0,6](1 row)osdba=# select '(0,6)'::numrange;numrange----------(0,6)(1 row)
Range类型还可以表示极值的区间,示例如下:
select '[1,)'::int4range;int4range-----------[1,)(1 row)select '[,1)'::int4range;int4range-----------(,1)(1 row)
上面的“[,1]”指的是从int4类型可以表示的最小值到1的范围。
还可以使用Range类型的构造函数输入Range类型的值,Range类型的构造函数名称与 类型名称相同,示例如下:
select int4range(1,10,'[)');int4range-----------[1,10)(1 row)osdba=# select int4range(1,10,'()');int4range-----------[2,10)(1 row)osdba=# select int4range(1,10);int4range-----------[1,10)(1 row)
5.8.3、Range类型的操作符
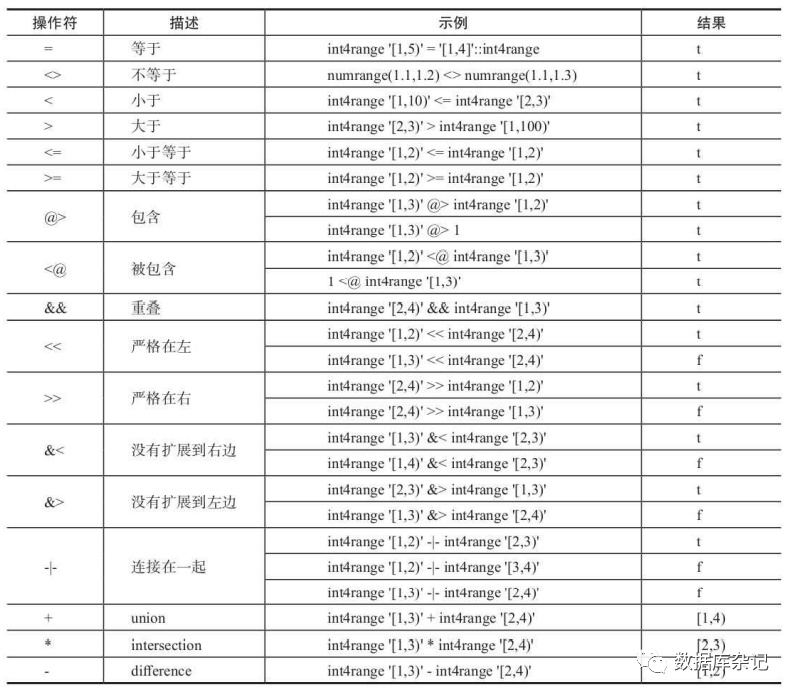
5.8.4、Range类型的函数
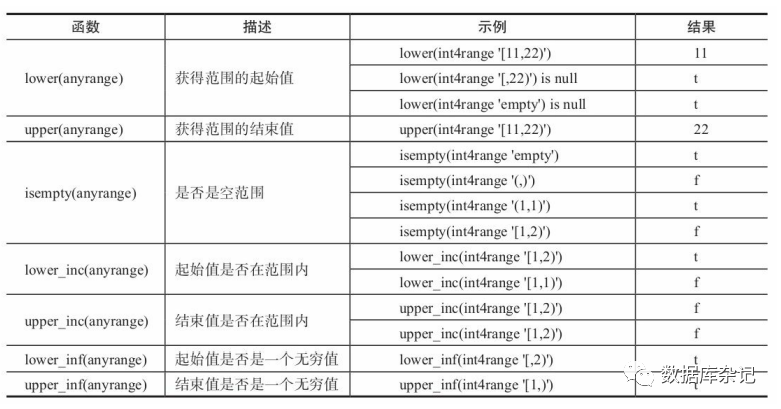
5.8.5、Range类型的索引和约束
在Range类型的列上可以创建GiST和SP-GiST索引,创建语法如下:
CREATE INDEX index_name ON table_name USING gist (range_column);
在SQL查询语句中,可以使用运算符“=”“&&”“<@”“@>”“<<”“>>”“-|-”“&<”“&>”来执 行索引。当然,在Range类型上也可以建BTree索引,但BTree索引是使用比较运算符的,通常 只在对Range的值进行排序时使用。在Range的列上也可以建立约束,使其范围永不重叠,示例如下:
CREATE TABLE rtest01 (idrange int4range,EXCLUDE USING gist (idrange WITH &&));
接下来插入数据:
osdba=# insert into rtest01 values(int4range '[1,5)');INSERT 0 1(1 row)osdba=# insert into rtest01 values(int4range '[4,5)');ERROR: conflicting key value violates exclusion constraint "rtest01_idrange_excl"DETAIL: Key (idrange)=([4,5)) conflicts with existing key (idrange)=([1,5)).
从上面的示例中可以看出,当插入的数据与原数据的范围出现重叠时就会报错。上面的约束条件只能限制在一个Range列上,如果是一个有两列的表,第一列是一个 普通类型的列,第二列是Range类型,我们需要让第一列的值相等的行的第二列值也不重 叠,这时就需要用另一个扩展模块btree_gist来实现此约束功能。
要使用此功能,需要先安装btree_gist模块,安装命令如下:
cd <postgres source code path/contrib/btree_gistmakemake install
CREATE EXTENSION btree_gist;CREATE TABLE rtest02(id int,idrange int4range,EXCLUDE USING gist (id WITH =, idrange WITH &&))--插入些数据INSERT INTO rtest02 values(1, int4range '[1,5)');INSERT INTO rtest02 values(2, int4range '[2,5)');
此时,我们发现只要第一列id的值不相同,即使第二列idrange的范围重叠,系统也不 会报错,但如果插入一个行,其id值与原有行相同,且idrange列的值也与此行idrange的范 围重叠:
INSERT INTO rtest02 values(1, int4range '[2,5)');ERROR: conflicting key value violates exclusion constraint "rtest02_id_idrange_excl"DETAIL: Key (id, idrange)=(1, [2,5)) conflicts with existing key (id, idrange)=(1, [1,5)).
那么系统就会报约束错误。
5.9、复合类型
5.9.1、简单示例
CREATE TYPE complex AS (r double precision,i double precision);CREATE TYPE person AS (name text,age integer,sex boolean);
创建复合类型的语法类似于CREATE TABLE,只是 这里只能声明字段名字和类型,目前不能声明约束(比如NOT NULL)。请注意,AS关 键字很重要,没有它,系统会认为这是另一种完全不同的CREATE TYPE命令,因此你会 看到奇怪的语法错误。定义了复合类型后,就可以用此类型创建表。
CREATE TABLE capacitance_test_data(test_time timestamp,voltage complex,current complex);
当然也可以使用此类型作为函数的参数,下面的示例中定义了前面创建的复数的乘法 函数:
CREATE FUNCTION complex_multi(complex, complex ) RETURNS complexAS $$ SELECT ROW($1.r*$2.r - $1.i*$2.i, $1.r*$2.i - $1.i*$2.r)::complex $$LANGUAGE SQL;
5.9.2、复合类型的输入
复合类型常量的一般格式如下: '( val1 , val2 , ... )'
从以上格式可以看出,其使用的是单引号加圆括号的一种格式。在此格式中,可以在 任何字段值周围加上双引号,如果值本身包含逗号或者圆括弧,则必须用双引号括起来。
CREATE TABLE author(id int,person_info person,book text);insert into author values( 1, '("张三",29,TRUE)', '张三的自传');
要让一个字段值是“NULL”,那么在列表里它的位置上就不要写任何字符。比如,以 下常量在第三个字段声明了一个“NULL”:
insert into author values( 2, '("张三",,TRUE)', '张三的自传');INSERT 0 1
如果想要一个空字符串,而不是“NULL”,则需要写一对双引号:
insert into author values(3,'("",,TRUE)', 'x的自传');
也可以用ROW表达式语法来构造复合类型值。在大多数场合下,这种方法比用字符 串文本的语法更简单,因为不用操心多重引号转义导致的问题。示例如下:
insert into author values( 4, ROW('张三', 29, TRUE), '自传');
只要表达式里有一个以上的字段,那么关键字ROW实际上也就是可选的,上面的语 句可以简化为如下SQL语句:
insert into author values(5, ('张三', 29, TRUE), '自传');
5.9.3、访问复合类型
访问复合类型字段的一个域就如C语言中访问结构体中的一个成员一样,即写出一个 点以及域的名字就可以了。这也非常像从一个表名字里选出一个字段。实际上,因为这实 在太像从表名字中选取字段了,所以我们经常需要用圆括弧来避免SQL解析器的混淆。
db1=# select person_info.name from author;ERROR: missing FROM-clause entry for table "person_info"LINE 1: select person_info.name from author;^正确的是:db1=# select (person_info).name from author;name------张三张三张三张三(5 rows)
也可以加上表名,具体如下:
db1=# select (author.person_info).name from author limit 2;name------张三张三(2 rows)
类似的语法问题适用于任何需要从一个复合类型值中查询一个域的情形。比如,要从 一个返回复合类型值的函数中选取一个字段,SQL语句如下:
SELECT (my_func(...)).field FROM ...
如果没有额外的圆括弧,就会产生语法错误。
5.9.4、修改复合类型
我们先来看插入或者更新整个字段的示例:
insert into author values(2, ('张三', 29, TRUE), '自传');UPDATE author SET person_info = ROW('李四', 39, TRUE) WHERE id =1;UPDATE author SET person_info = ('王二', 49, TRUE) WHERE id =2;
也可以只更新一个复合字段的某个子域:
UPDATE author SET person_info.name ='王二二' WHERE id =2;UPDATE author SET person_info.age = (person_info).age + 1 WHERE id =2;
需要注意的是,不能在“SET”后的字段名周围加圆括弧,但是需要在等号右边的表达 式里引用同一个字段的时候加上圆括弧,否则系统会报错:
UPDATE author SET (person_info).name ='王二二' WHERE id =2;ERROR: syntax error at or near "."LINE 1: UPDATE author SET (person_info).name ='王二二' WHERE id =2;^UPDATE author SET person_info.age = person_info.age + 1 WHERE id =2;ERROR: missing FROM-clause entry for table "person_info"LINE 1: UPDATE author SET person_info.age = person_info.age + 1 WHER...^
INSERT也可以指定复合字段的子域,示例如下
INSERT INTO author (id, person_info.name, person_info.age) VALUES(10, '张三',29);INSERT 0 1
在上面的例子中,因子域未为复合字段提供数值,故将用“NULL”填充。
5.9.5、复合类型的输入输出
在PostgreSQL中,每个基本类型都有相应的I/O转换解析规则,而在解析复合类型的 文本格式时,会先解析由复合结构定义的圆括号和相邻域之间的逗号等包含的部分,其子 域会用各自子域的I/O转换解析规则进行分析。示例如下:
'( 42)'
如果子域类型是整数,那么“42”前的空格将被忽略,但是如果是文本,那么该空格就不会被忽略。
在给一个复合类型写数值的时候,可以将独立的子域数值用双引号括起来,就像前面 的示例一样,特别是当子域数值会导致复合数值分析器产生歧义时,就必须加双引号,比 如,子域包含圆括弧、逗号、双引号、反斜杠的情形。要想在双引号括起来的子域数值里 面放双引号,那么就需要在它前面放一个反斜杠。同样,在双引号括起来的子域数值里面 的一对双引号表示一个双引号字符,类似于SQL字符串文本的单引号规则。另外,也可以 用反斜杠进行转义,而不必用引号。
需要注意的是,写的任何SQL命令都会先被当作字符串文本来解析,然后才是复合类 型。这样一来,所需要的反斜杠数目就加倍了。比如,要插入一个包含双引号和一个反斜 杠的text子域到一个复合类型的数值里,SQL语句如下:
INSERT ... VALUES (E'("\\"\\\\")');
在上面的例子中,字符串文本处理器先吃掉一层反斜杠,使复合类型分析器中的内容 变成“(“\”\”)”。接着,将该字符串传递给text数据类型的输入过程,再吃掉一层反斜杠后 内容变成我们需要的““\”。如果所使用的数据类型对反斜杠也有特殊意义,比如bytea类型 ,那么可能需要在命令里放多达8个的反斜杠,这样在存储的复合类型子域中才能有一个 反斜杠。所以在SQL命令里写复合类型值的时候,ROW构造器通常比复合文本语法更易 于使用。
如果子域数值是空字符串,或者包含圆括弧、逗号、双引号、反斜杠、空白,那么复 合类型的输出程序会在子域数值周围加上双引号。
5.10、伪类型
伪类型(Pseudo-Types)是PostgreSQL中不能作为字段的一种数据类型,但是它可以 用于声明函数的参数或者结果类型,所包含的类型有以下几种。
any:用于指示函数的输入参数可以是任意数据类型。 anyelement:表示一个函数接受任何数据类型。 anyarray:表示一个函数接受任何数组类型。 anynonarray:表示一个函数接受任何非数组类型。 anyenum:表示一个函数接受任何枚举类型。 anyrange:表示一个函数接受任何范围类型。 cstring:表示一个函数接受或返回一个以空字符(\0)结尾的C语言字符串。 internal:表示一个函数接受或者返回一种服务器内部的数据类型。 language_handler:声明一个函数的返回值类型是PL语言的handler函数。 fdw_handler:声明一个函数的返回值类型是FOREIGN-DATA WRAPPER的handler函 数。 record:标识一个函数返回一个未详细定义各列的row类型。 trigger:一个触发器函数要声明为返回trigger类型。 void:表示一个函数没有返回值。 opaque:已经过时的类型,早期的PostgreSQL版本中用于上面这些用途。
用C语言编写的函数(不管是内置的还是动态装载的)都可以声明为接受或返回上面 任意一种伪数据类型。在把伪类型用作函数参数类型时,PostgreSQL数据库本身对类型的 检查就少了很多,保证类型正确的任务就交给了写函数的开发人员。
用过程语言编写的函数不一定都能使用上面列出的全部伪类型,具体能使用哪些伪类 型需要查看相关的过程语言文档,或者查看过程语言的实现。通常情况下,过程语言不支 持使用any类型,但基本都能支持使用void和record作为结果类型,能支持多态函数的过程 语言还支持使用anyarray、anyelement、anyenum和anynonarray类型。
伪类型internal用于声明只能在数据库系统内部调用的函数,不能直接在SQL查询中调 用它们。如果函数至少有一个internal类型的参数,那么就不能从SQL中调用它。为了保留 这个限制的类型安全,我们一定要遵循以下编码规则:对于没有任何internal参数的函数 ,不要把返回类型创建为internal类型。
6、使用视图
优化器把视图当作子查询来处理
PG中视图默认是不可以更新的, 除非创建了规则(这是以前)。实际上在新版本中一些简单的视图是可以更新的。
e.g.(略)
7、建立数据库用户
数据库用户和操作系统用户是不同的
create user (sql), createuser(cmd)都可以创建用户。
mydb=> create user scott with encrypted password 'tiger';ERROR: permission denied to create rolemydb=> \c postgres postgres用户 postgres 的口令:您现在已经连接到数据库 "postgres",用户 "postgres".postgres=# create user scott with encrypted password 'tiger';CREATE ROLE
postgres=# create user scott_dba createdb createrole valid until '2022-03-09';CREATE ROLEpostgres=# alter user scott_dba with encrypted password 'tiger';ALTER ROLE
drop user scott cascade; 此处cascade似乎不可用。不支持。
8、用户授权及角色管理
对表的访问权限通过 GRANT 和 REVOKE SQL 命令赋予和回收。例如:
GRANT UPDATE DELETE ON emp TO scott_temp;GRANT UPDATE chgdesc ON jobhist TO scott;GRANT ALL ON dept TO GROUP scott_lnxdb;REVOKE UPDATE DELETE ON emp FROM scott_lnxdb;GRANT USAGE ON SCHEMA postgres TO scott;
7.1、 普通授权
grant all privileges on database zdb to zdb;grant all privileges on database zdb to foo;将zdb所有访问权限赋给用户zdb 和 foo
7.2、引入schema
http://blog.itpub.net/30126024/viewspace-2661690/ (参考)
默认每个数据库下边都有public这个schema. 每个数据库都可以有多个schema.
create schema zdb;create table zdb.t123(id int primary key);select * from t123; -- 这个默认搜索的是 public这个schema下边的表select * from zdb.t123;
postgres=# create user u1 with password 'mydb';CREATE ROLEpostgres=# create schema [u1] authorization u1;CREATE SCHEMApostgres=# grant all privileges on database mydb to u1;GRANTpostgres=# show search_path;search_path-----------------"$user", public(1 row)mydb=> \c mydb u1You are now connected to database "mydb" as user "u1".mydb=> create table t(id int);CREATE TABLEmydb=> \dList of relationsSchema | Name | Type | Owner--------+------+-------+-------public | t | table | u1(1 row)// 发现owner是u1
7.2.1 搜索schema路径 如何确定:
show search_path;`zdb=# show search_path;search_path"$user", public`
意为先搜索自己同名的schema下的对象,然后是public.
7.2.2 设置自己的search_path
zdb=# select * from t123;ERROR: relation "t123" does not existLINE 1: select * from t123;^zdb=# set search_path="$user", public, zdb;
7.2.3 基于schema授权
grant usage on schema zdb to zdb;
select * from t123 // (zdb用户来访问)
CREATE USER mydb with encrypted password 'mydb';CREATE USER zdb with encrypted password 'zdb';GRANT ALL PRIVILEGES ON DATABASE mydb to mydb;GRANT ALL PRIVILEGES ON DATABASE mydb to zdb;grant select,update,insert,delete on all tables in schema public to mydb,zdb;alter default privileges in schema public grant select,update,insert,delete on tables to zdb,mydb;
对于已有的表,虽然是同一个schema, 默认情况下也是相互隔离的,必须进行统一授权,才能让它们都能访问对方创建的表或其它资源。
grant all privileges on schema public to zdb; 注意区别, 这个依然没有用grant all privileges on all tables in schema public to PUBLIC;GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO PUBLIC|my_users;
使用示例 :
mydb=> grant all privileges on all tables in schema public to scott;mydb=> create schema mydb;CREATE SCHEMAmydb=> grant usage on schema mydb to scott;GRANTmydb=> grant all on schema mydb to scott;GRANTmydb=> \c mydb scott用户 scott 的口令:您现在已经连接到数据库 "mydb",用户 "scott".mydb=> \dpublic | department_id_seq | 序列数 | mydbpublic | dept | 数据表 | mydbpublic | weather | 数据表 | postgresmydb=> create table mydb.t(id int);CREATE TABLEmydb=> \dpublic | department_id_seq | 序列数 | mydbpublic | dept | 数据表 | mydbpublic | weather | 数据表 | postgresmydb=> insert into t values(1);ERROR: relation "t" does not exist第1行insert into t values(1);^mydb=> insert into mydb.t values(1);INSERT 0 1mydb=> select * from mydb.t;1
7.3、表和列权限解读
pg_class.relacl的解读
check document: PostgreSQL: Documentation: 14: GRANT
and PostgreSQL: Documentation: 14: 5.7. Privileges
Table 5.1. ACL Privilege Abbreviations
| Privilege | Abbreviation | Applicable Object Types |
|---|---|---|
SELECT | r(“read”) | LARGE OBJECT, SEQUENCE, TABLE(and table-like objects), table column |
INSERT | a(“append”) | TABLE, table column |
UPDATE | w(“write”) | LARGE OBJECT, SEQUENCE, TABLE, table column |
DELETE | d | TABLE |
TRUNCATE | D | TABLE |
REFERENCES | x | TABLE, table column |
TRIGGER | t | TABLE |
CREATE | C | DATABASE, SCHEMA, TABLESPACE |
CONNECT | c | DATABASE |
TEMPORARY | T | DATABASE |
EXECUTE | X | FUNCTION, PROCEDURE |
USAGE | U | DOMAIN, FOREIGN DATA WRAPPER, FOREIGN SERVER, LANGUAGE, SCHEMA, SEQUENCE, TYPE |
Table 5.2. Summary of Access Privileges
| Object Type | All Privileges | Default PUBLICPrivileges | psql Command |
|---|---|---|---|
DATABASE | CTc | Tc | \l |
DOMAIN | U | U | \dD+ |
FUNCTIONor PROCEDURE | X | X | \df+ |
FOREIGN DATA WRAPPER | U | none | \dew+ |
FOREIGN SERVER | U | none | \des+ |
LANGUAGE | U | U | \dL+ |
LARGE OBJECT | rw | none | |
SCHEMA | UC | none | \dn+ |
SEQUENCE | rwU | none | \dp |
TABLE(and table-like objects) | arwdDxt | none | \dp |
| Table column | arwx | none | \dp |
TABLESPACE | C | none | \db+ |
TYPE | U | U | \dT+ |
postgres=# select * from pg_default_acl;oid | defaclrole | defaclnamespace | defaclobjtype | defaclacl-------+------------+-----------------+---------------+----------------------------16415 | 16410 | 0 | r | {a=arwdDxt/a,b=r/a,c=rw/a}(1 row){a=arwdDxt/a,b=r/a,c=rw/a}代表默认的权限如下:a角色-表的所有权限(arwdDxt代表表的所有权限,可以参考官网文档)b角色-表的select权限(继承于a角色)c角色-表的select,update权限(继承于a角色)
postgres=# create table mytable(id int, col1 varchar(32));CREATE TABLEpostgres=# create role admin;CREATE ROLEpostgres=# create role miriam_rw;CREATE ROLEpostgres=# GRANT SELECT ON mytable TO PUBLIC;GRANTpostgres=# GRANT SELECT, UPDATE, INSERT ON mytable TO admin;GRANTpostgres=# GRANT SELECT (col1), UPDATE (col1) ON mytable TO miriam_rw;GRANTpostgres=# \dp mytableAccess privilegesSchema | Name | Type | Access privileges | Column privileges | Policies--------+---------+-------+---------------------------+-------------------------+----------public | mytable | table | postgres=arwdDxt/postgres+| col1: +|| | | =r/postgres +| miriam_rw=rw/postgres || | | admin=arw/postgres | |(1 row)The entries shown by \dp are interpreted thus:rolename=xxxx -- privileges granted to a role=xxxx -- privileges granted to PUBLICr -- SELECT ("read")w -- UPDATE ("write")a -- INSERT ("append")d -- DELETED -- TRUNCATEx -- REFERENCESt -- TRIGGERX -- EXECUTEU -- USAGEC -- CREATEc -- CONNECTT -- TEMPORARYarwdDxt -- ALL PRIVILEGES (for tables, varies for other objects)* -- grant option for preceding privilegeyyyy -- role that granted this privilege
role/user的删除方法
mydb=# drop role u1;ERROR: role "u1" cannot be dropped because some objects depend on itDETAIL: privileges for database mydb1 object in database postgres
Before dropping the role, you must drop all the objects it owns (or reassign their ownership) and revoke any privileges the role has been granted on other objects. The REASSIGN OWNED and DROP OWNED commands can be useful for this purpose;
mydb=# \duList of rolesRole name | Attributes | Member of-----------+------------------------------------------------------------+-----------mydb | | {}postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}u1 |#通过reassign owner来间接删除mydb=# reassign owned by u1 to mydb;REASSIGN OWNEDmydb=# reassign owned by u1 to mydb;REASSIGN OWNEDmydb=# drop owned by u1;DROP OWNEDmydb=# drop user u1;ERROR: role "u1" cannot be dropped because some objects depend on itDETAIL: 1 object in database postgres-- 紧接着看下边:postgres=# \duList of rolesRole name | Attributes | Member of-----------+------------------------------------------------------------+-----------mydb | | {}postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}u1 | | {}postgres=# reassign owned by u1 to mydb;REASSIGN OWNEDpostgres=# drop owned by u1;DROP OWNEDpostgres=# drop user u1;DROP ROLE
9、索引
常见索引类型:
B-Tree (默认) Hash 只有当 WHERE 语句包含一个简单的等号(”=”)时使用 (缺点: 需要 创建的时间长, 不如B-tree好) Index on Expressions – 当某个表达式(expression)经常被使用以提高查询 速度的时候使用。插入和更新操作会变慢。 Partial Index – 只对满足WHERE条件的行进行索引 (WHERE语句不能包含 索引列)。查询也必须使用partial index 使用的那个WHERE 语句。
CREATE INDEX <name> on <table> (<column>);CREATE INDEX <name> ON <table> USING HASH (<column>);CREATE INDEX <name> on <table>(expression(<column(s)>));CREATE INDEX <name> ON <table> (<column>) WHERE <where clause>;
