




关注 GreptimeDB,了解更多技术干货👇
2024 下半年伊始,根据最新的 GreptimeDB Roadmap,今天,我们很高兴地宣布支持日志存储和查询的 GreptimeDB 全新版本正式上线!
在这个版本中,我们引入了一个专门为日志存储和查询优化的存储引擎——Log Engine,不仅提升了日志数据的分析和存储效率,还为用户提供了更强大的日志数据处理和查询能力。
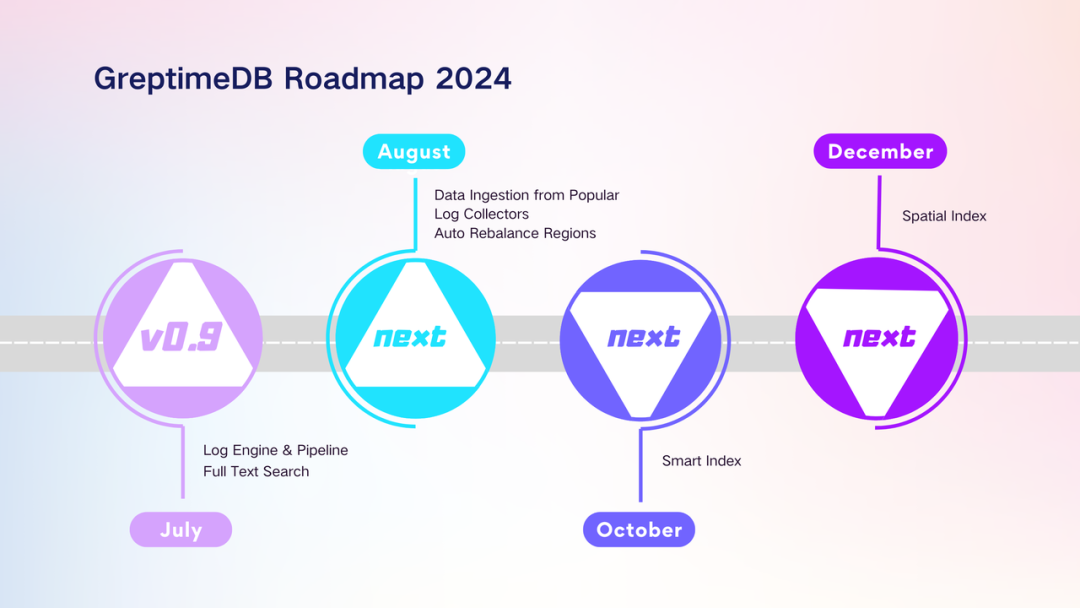
(图 1:2024 GreptimeDB Roadmap)
从 v0.8 到 v0.9,Greptime 团队取得了显著的进展:共合并了 167 次代码提交,修改了 705 个文件,其中包括 85 项功能增强, 29 项错误修复, 21 项代码重构,以及大量的测试工作。在此期间,共有 5 位来自社区的个人贡献者提交了 11 次代码贡献。
非常感谢团队和各位个人贡献者的努力,也欢迎更多对技术感兴趣的同学加入我们!
直播

Log Engine 是一个专门为日志存储和查询优化设计的存储引擎,包含全文索引。
为什么需要 Log Engine?
日志数据通常是非结构化或半结构化的数据,包括文本、时间戳、错误信息、事件描述等,更详细、更丰富,记录了系统的各类事件和操作。在此之前,GreptimeDB 主要支持基于 Metrics 进行指标数据分析。然而,在物联网、可观测等场景中,日志分析对故障诊断与排除、性能、安全监控以及用户行为等方面都有重要意义。
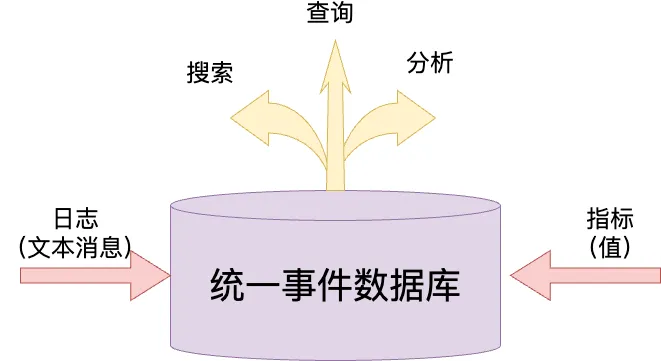
(图 2:统一的事件数据库)
关于监控系统中统一日志和指标所带来的优势可以详见《事件管理革命:监控系统中统一日志和指标》。
Pipeline 是 GreptimeDB 中对 log (由 JSON 格式构成的数据)数据进行转换的一种机制, 由一个唯一的名称和一组配置规则组成,这些规则定义了如何对日志数据进行格式化、拆分和转换。
这些配置以 YAML 格式提供,使得 Pipeline 能够在日志写入过程中,根据设定的规则对数据进行处理,并将处理后的数据存储到数据库中,便于后续的结构化查询。
Pipeline 由两部分组成:Processors 和 Transforms。一个 Pipeline 配置可以包含多个 Processor 和多个 Transform。
Processor 用于对 log 数据进行预处理,例如解析时间字段,替换字段等;
Transform 用于对 log 数据进行转换,例如将字符串类型转换为数字类型。
全文检索能力包括:
全文索引:通过建表语句或者 Pipeline 配置指定某些列使用全文索引来加速搜索操作;
全文搜索函数 MATCHES:允许用户通过多种词项表达式进行搜索,支持简单词项、否定词项、必需词项等多种搜索类型。
## pipeline.yaml 文件
processors:
- date:
field: time
formats:
- "%Y-%m-%d %H:%M:%S%.3f"
ignore_missing: true
transform:
- fields:
- id1
- id2
type: int32
- fields:
- type
- logger
type: string
index: tag
- fields:
- log
type: string
index: fulltext
- field: time
type: time
index: timestamp
2. 写入日志
curl -X "POST" "http://localhost:4000/v1/events/logs?db=public&table=logs&pipeline_name=test" \
-H 'Content-Type: application/json' \
-d $'{"time":"2024-05-25 20:16:37.217","id1":"2436","id2":"2528","type":"I","logger":"INTERACT.MANAGER","log":"this is a test log message"}
{"time":"2024-05-25 20:16:37.217","id1":"2436","id2":"2528","type":"I","logger":"INTERACT.MANAGER","log":"Started logging"}
{"time":"2024-05-25 20:16:37.217","id1":"2436","id2":"2528","type":"I","logger":"INTERACT.MANAGER","log":"Attended meeting discussion"}
{"time":"2024-05-25 20:16:37.217","id1":"2436","id2":"2528","type":"I","logger":"INTERACT.MANAGER","log":"Handled customer support requests"}'
3. Logs 表结构(包含自动 create table 的语句)
DESC TABLE logs;
Column|Type|Key|Null|Default|SemanticType
--------+---------------------+-----+------+---------+---------------
id1 |Int32|| YES || FIELD
id2 |Int32|| YES || FIELD
type |String| PRI | YES || TAG
logger |String| PRI | YES || TAG
log |String|| YES || FIELD
time|TimestampNanosecond| PRI |NO||TIMESTAMP
(6rows)
4. 使用 MATCHES 函数进行全文搜索
SELECT *FROM logs WHERE MATCHES(log,"Attended OR Handled");
+------+------+------+------------------+-----------------------------------+----------------------------+
| id1 | id2 | type | logger | log |time|
+------+------+------+------------------+-----------------------------------+----------------------------+
|2436|2528| I | INTERACT.MANAGER |Handled customer support requests |2024-05-2520:16:37.217000|
|2436|2528| I | INTERACT.MANAGER |Attended meeting discussion |2024-05-2520:16:37.217000|
+------+------+------+------------------+-----------------------------------+----------------------------+
1. Flow Engine 功能完善
Flow Engine 支持以集群方式部署;
支持 show create flow;
性能优化及 bug 修复。
2. 优化 Remote WAL,分布式 Region Failover 功能推荐默认开启
重构了 Remote WAL 写入逻辑,引入无延迟攒批;
优化了 Remote WAL 打开批量 Region 的速度;
对基于 Remote WAL 的 Region Failover 功能进行了大量的测试工作,确保该功能稳定执行和数据高可靠。
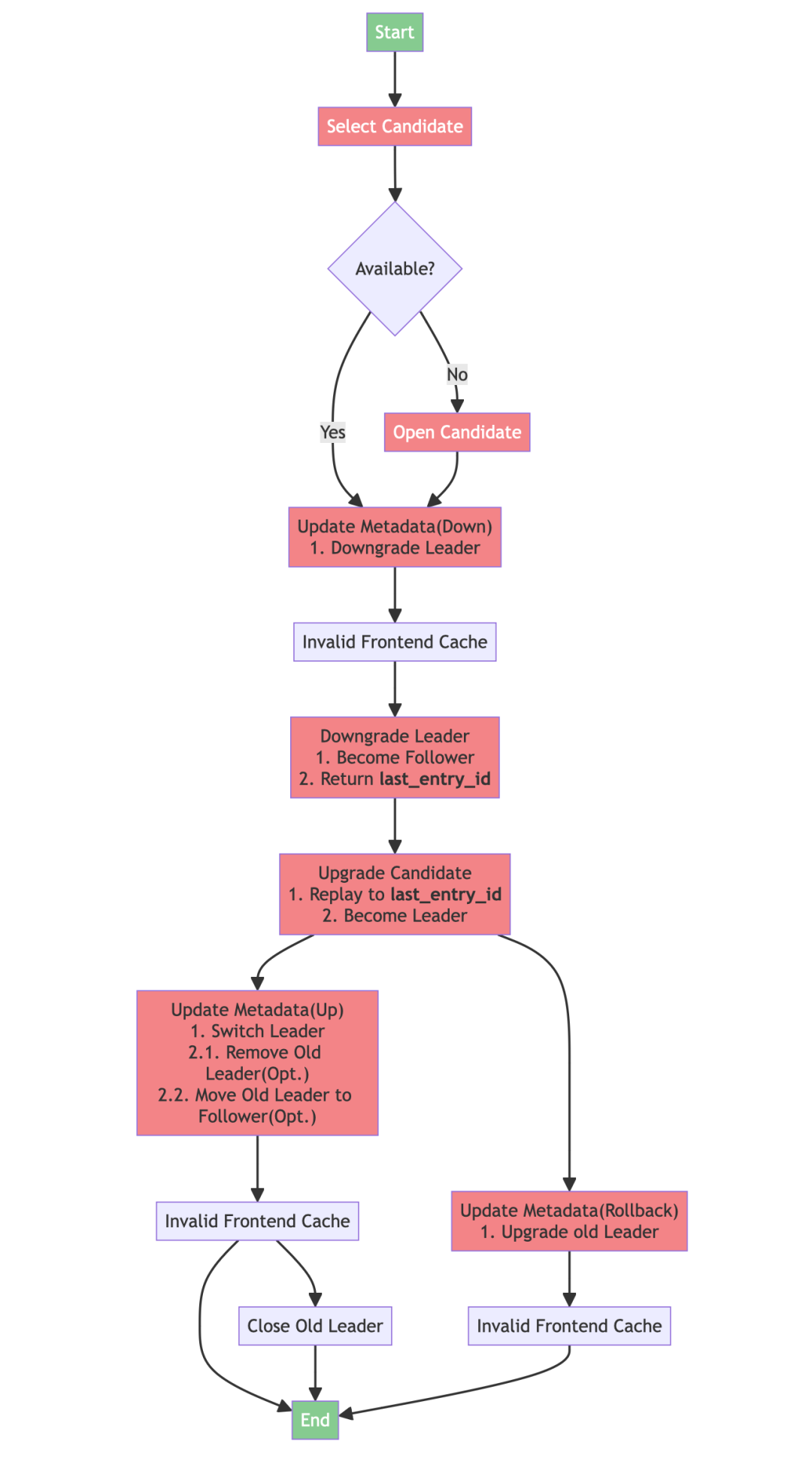
(图 3:Region Failover 流程)
3. 支持 InfluxDB merge read
新增建表参数 merge_mode 来控制 GreptimeDB 如何合并 tags 和时间戳相同的行。可选值为 last_row 和 last_non_null,默认值为 last_row。在 last_row 模式下,GreptimeDB 会选择最新的一行作为合并结果;
在 last_non_null 模式下,GreptimeDB 会选择每个 field 最新的非空值作为合并结果。该模式允许用户更新一行的部分列,使得 GreptimeDB 可以兼容 InfluxDB 的语义;
以下是一个例子
create table if not exists last_non_null_table(
host string,
ts timestamp,
cpu double,
memory double,
TIME INDEX (ts),
PRIMARY KEY(host)
)
Engine=mito
with('merge_mode'='last_non_null');
INSERTINTO last_non_null_table VALUES('host1',0,0,NULL),('host2',1,NULL,1);
INSERTINTO last_non_null_table VALUES('host1',0,NULL,10),('host2',1,11,NULL);
查询结果如下:
SELECT * from last_non_null_table ORDERBY host, ts;
+-------+-------------------------+------+--------+
| host | ts | cpu | memory |
+-------+-------------------------+------+--------+
| host1 |1970-01-01T00:00:00|0.0|10.0|
| host2 |1970-01-01T00:00:00.001|11.0|1.0|
+-------+-------------------------+------+--------+
通过 InfluxDB line protocol 协议写入数据到 GreptimeDB 并触发自动建表时,GreptimeDB 会默认将 merge_mode 设置为 last_non_null。
4. 支持视图
用户现在可以使用直观的 SQL 语法创建和查询视图。该功能将复杂的逻辑封装成可重用的虚拟表,提供了更好的数据安全性、性能优化和数据复杂性抽象;
新支持的 SQL 语法如下:
创建视图 CREATE [OR REPLACE] [IF NOT EXISTS] VIEW <view_name> AS <SELECT_statement>;查询视图
SELECT * FROM <view_name>;
5. 支持 interval 表达式的缩写
该 PR 支持缩写的 interval 表达式,比如用 y 代表年(year)。其他的缩写有:
mon 代表月(month)
w 代表星期(week)
d 代表天(day)
m 代表分钟(minute)
s 代表秒(second)
ms 或 millis 代表毫秒(millisecond)
µs 代表微秒(microsecond)
ns 代表纳秒(nanosecond)
SELECT INTERVAL '7 days' - INTERVAL '1d';
+----------------------------------------------------------------------------------------------+
|IntervalMonthDayNano("129127208515966861312")-IntervalMonthDayNano("18446744073709551616")|
+----------------------------------------------------------------------------------------------+
|0 years 0 mons 6 days 0 hours 0 mins 0.000000000 secs |
+----------------------------------------------------------------------------------------------+
SELECT '3y2mon'::INTERVAL;
+---------------------------------------------------------+
| IntervalMonthDayNano("3010670175542044828554670112768") |
+---------------------------------------------------------+
| 0 years 38 mons 0 days 0 hours 0 mins 0.000000000 secs |
+---------------------------------------------------------+
6. 并行扫描优化
引入分区并行扫描能力,部分条件下可以做到 Row Group 粒度的并行扫描,扫描速度最高提升 55%;
在扫描并发度为 4 时,部分查询的优化效果如下:
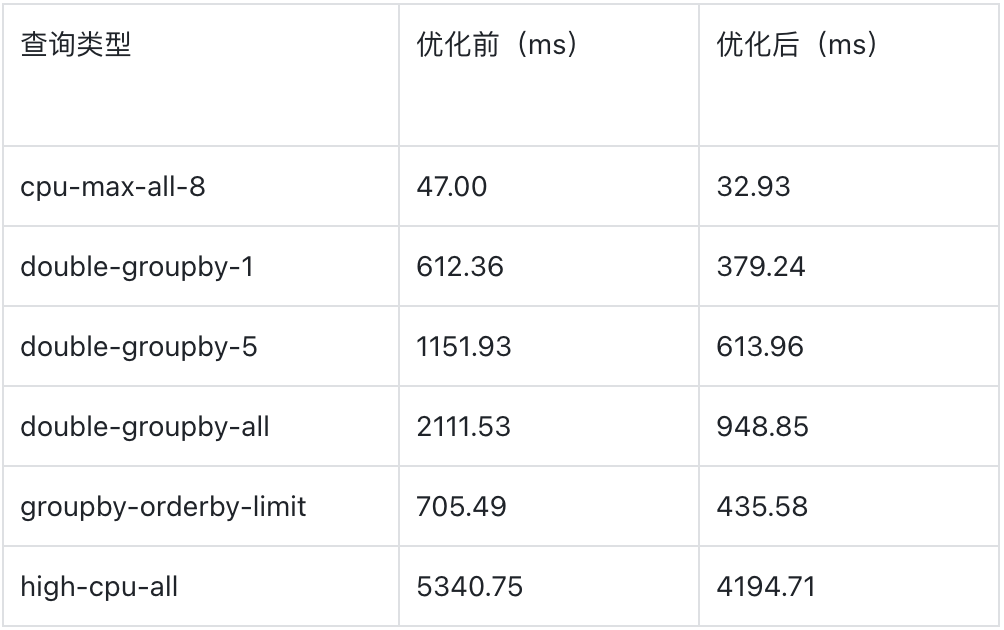
(图 4:查询优化结果)
7. gRPC 服务添加 TLS 支持
这个 PR 通过增加 TLS 支持增强了 gRPC 服务的安全性。
gRPC 服务器 TLS 配置如下:
[grpc.tls]
## TLS 模式
mode="enable"
## 证书文件路径
cert_path="/path/to/certfile"
## 私钥文件路径
key_path="/path/to/keyfile"
## 监控证书和密钥文件的变动并自动重新加载
watch= false
8. 支持不同策略的手动 Compaction
这个 PR 引入了通过 SQL 命令手动触发不同类型的 Compaction 的功能。新支持的 SQL 语法如下:
SELECT COMPACT_TABLE(<table_name>, [<compact_type>], [<options>])
目前支持的 compact_type 选项包括:
regular:触发类似于 Flush 操作的标准 Compaction。
strict_window:严格按照指定时间窗口划分 SST 文件。
<options> 参数可用于具体 Compaction 策略的配置。例如,对于 strict_window,选项指定 Compaction 窗口的秒数。
1. 创建一个全新的 v0.9 集群
2. 关闭旧集群流量入口(停写)
3. 通过 GreptimeDB CLI 升级工具导出表结构和数据
4. 通过 GreptimeDB CLI 升级工具导入数据到新集群
5. 入口流量切换至新集群
详细升级指南请参考:
中文:https://docs.greptime.cn/user-guide/upgrade
英文:https://docs.greptime.com/user-guide/upgrade
GreptimeDB 的短期目标是成为一个融合 Metrics 和 Log 的泛时序数据库。在下一个版本中,我们将继续打磨 Log Engine,降低 transform 开销,优化查询性能,并发展周边生态系统,例如实现更多 log collectors。同时,我们还可能将 Log Engine 与 Flow Engine 进行结合,例如进行日志内容的解析和抽取。
欢迎大家来到直播间了解我们的版本更新计划,也欢迎各位参与代码贡献或功能、性能的反馈和讨论,让我们携手见证 GreptimeDB 持续的成长与精进。
关于 Greptime
Greptime 格睿科技专注于为物联网(如智慧能源、智能汽车等)及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
GreptimeDB 是一款用 Rust 语言编写的开源时序数据库,具有云原生、无限水平扩展、高性能和融合分析等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。我们提供 GreptimeDB 企业版,支持更多企业特性和定制化服务,如有需要欢迎联系我们:15310923206(同微信)。
边云一体方案专为更高效地解决物联网中边缘存储和计算问题而设计,解决了物联网企业数据呈几何倍数增长后的实际业务痛点。它通过将多模式边缘数据库与云端的GreptimeDB 企业版相结合,大幅降低了流量、计算和存储成本,同时提升了数据及时性和商业洞察力。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,基于开源时序数据库 GreptimeDB 打造,能够高效支持可观测、物联网、金融等领域的应用。

Star us on GitHub Now:
https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:


👇 点击下方阅读原文,立即体验 GreptimeDB!
