





点击蓝字 关注我们

互联网发展到今天,高并发并不是什么新鲜话题,数据同时被读写是业务常态,比如电商系统中的商品库存、金融行业中的用户余额等,实现这一切离不开数据库 MVCC 能力,全称 Multi-Version Concurrency Control,多版本并发控制。
本文大约7500字,需要20分钟阅读。读完将会了解数据库高并发底层原理、从根上了解不同数据库的特性。文章适合资深开发、架构师、DBA等同学阅读。

MVCC 包含两方面:
Multi-Versioning,MV:生成多版本的数据内容,使得不同请求(读写)可以获取响应版本数据。
Concurrency Control,CC:并发控制,使得并行执行的内容能保持串行化结果。

In this paper, we perform such a study for key transaction man-agement design decisions in of MVCC DBMSs: concurrency control protocol, version storage, garbage collection, and index management.For each of these topics, we describe the state-of-the-art implementations for in-memory DBMSs and discuss their trade-offs.
在这篇论文中,我们对MVCC 在数据库管理系统中中的关键事务管理设计决策进行了这样的研究:并发控制协议、版本存储、垃圾收集、索引管理。对于这些主题中的每一个,我们描述了内存DBMS的最新实现,并讨论了它们的权衡。
该论文认为 MVCC 主要实现主要基于四个关键模块,文章也用了大量笔墨详细介绍了这四块。
Concurrency Control Protocol 并发控制协议
Version storage 版本数据存储方式
Garbage Collection 垃圾清理机制
Index Management 索引管理
事务
数据库在事务开始时给事务分配一个唯一的事务ID,事务ID是一个自然增长时间戳作为标识符(TID),并发控制协议(Concurrency Control Protocol)使用TID
标记事务获取数据的不同版本。
元组
txn-id: 数据的TID,用以实现写锁。
begin-ts & end-ts:标识该元组版本的生命起止时间。
pointer:指向同一行数据相邻(新/旧)版的指针,依靠指针,版本数据可以形成一个单向链表。

图2
txn-id是否等于0,如果是的话,将
TID填到这个字段。其他事务想对该数据持有写锁,就会发现
txn-id字段不是0也不是自己
TID,就知道已有其他事务占据这个元组的写锁。写完后需要将该元组
txn-id设置为0。
begin-ts和
end-ts的时间戳代表这个元组版本的生命周期。他们的初始值会设置为0。当这个元组被删除了,
begin-ts会被设置
INF。
pointer字段是存储相邻(上一个或下一个)版本(如果有)的地址的指针。
2.2 并发控制协议
数据库都有一个并发控制协议,用于协调并发事务的执行,负责事务是否可以访问或修改特定版本的元组,以及事务是否可以提交它的改动。
MVTO
Timestamp Ordering 实现,数据的元组除了维护三个字段read-ts
、 begin-ts
、 end-ts
,还加加了 read-ts
字段,它记录的是上一个读取它的事务TID
。见图3
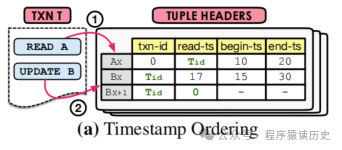
当事务T要读取到符合要求的那一条元组信息。首先事务的 TID
在对应元组中的 begin-ts
和 end-ts
之间,如图3所示,事务T要读到Ax,满足10 < Tid < 20。其次还需要确保Ax的元组写锁没被其他事务占住(即txn-id
是0或者是TID
)。因为,MVTO 不允许事务读到没有提交的元组版本。在读取A的版本数据Ax时,如果Ax的read-ts
小于TID
,则将该字段修改为TID
。否则,该版本数据被其他事务占有写锁,事务读取旧版本而不更新read-ts
字段。
在MVTO实现下,事务总是更新最新版本元组。如图二所示,如果没有事务持有BX版本的写锁,并且BX版本的Tid
大于其read-ts
字段值,则事务T创建新版本Bx+1。如果满足这些条件,数据库将创建该数据新的元组版本Bx+1,并将其txn-id
设置为TID
。当T提交时,数据库将BX+1元数据版本的begin-ts
和end-ts
字段分别设置为TID
和INF
,将BX版本的end-ts
字段设置为TID
。
MV2PL
begin-ts和
end-ts字段来决定该版本记录是否可见。是否可写,由锁来控制。元组除了维护三个字段:
read-ts begin-ts end-ts,还会加一个字段
read-cnt,它记录的是上一个读取它的事务
TID。见图4。
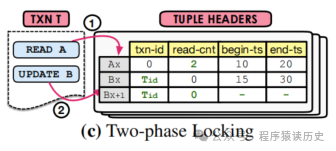
想要读元数据A,和上述协议一样要找到一个可见的版本,当找到可见版本时,将元组的read-cnt
的值增加1,当然需要在txn-id
等于0的情况下,否则该版本是被持有修改中的写操作。如图4。
同样的一个事务想要更新BX时,需要确认BX的txn-id
字段为 0 或者当前TID
,且read-cnt
字段为 0。当事务提交时,数据库会分配一个时间戳(Tcommit)来更新新版本的begin-ts
字段,并释放事务持有的所有的锁。如图4。
MVOCC
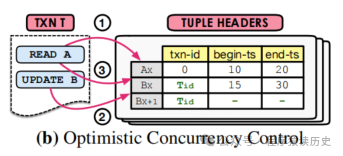
小结
read-cnt描述的是当前版本数据行的读锁个数,并不关心这些读锁是来自未来的事务还是以前的事务。因此
read-cnt可以看作一个共享锁,这是两者主要区别。
2.3 版本存储
Append-only Storage
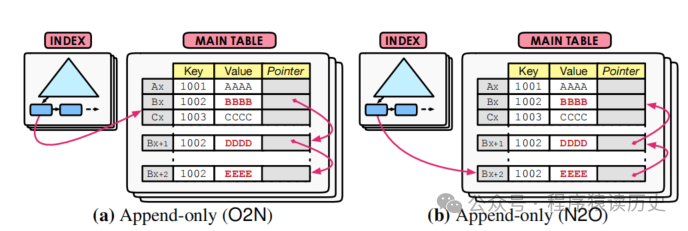
图6
Time-Travel Storage
Time-Travel表中。代表产品有 SQLServer。
当想要更新元组时,数据库先在time-travel
表中将主版本元组信息拷贝到该位置。另外,该方案也避免索引上的指针频繁更新,因为索引指向主版本,此时主版本没有变化。因此,这种方式避免维护数据库索引的负担,无论何时事务更新了元组。同时,对于获取元组的当前版本的查询效率也比较高。见图7。
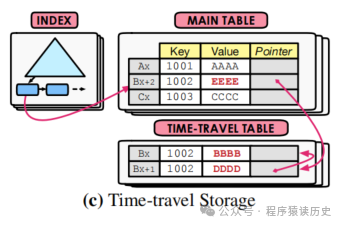
图7
Delta Storage
delta存储空间存储
delta版本,这个存储空间在MySQL 和 Oracle 称之为回滚段(
rollback segment),如 MySQL InnoDB 中的
undo log。
大部分这类数据库选择在主表中存储当前版本(也就是最新版本)。当更新一个元组时,从delta
存储空间申请一个连续空间用于创建一个新的delta
版本。该delta
版本只会记录更改的元组的原先值,而不会记录整个元组(这一点有别于 time-travle storage)。然后数据库直接更新主表上主版本的内容。见图8。

小结
Append-only存储在一些数据分析场景下更佳,因为版本数据存储在连续的空间中,当进行大范围的扫描时可以提高缓存的命中率,而且还可以配合硬件预读进行优化。但是这种方案访问元组的旧版本的查询会遭受更高的开销,因为数据库需要通过元组的链来查找正确的版本。
Append-only、Time-Travel)可以暴露物理的版本数据给索引管理系统,为索引管理提供了更多可选的方案,而Delta存储中就没有物理的版本数据行,在以上方面的对比处于劣势。
2.4 垃圾回收机制
Garbage Collection(垃圾收集,简称GC)机制。
检测过时版本在链表中将它们断开连接(移除链表元素)释放空间
检测过时版本数据有很多方法,例如检测版本行是否由异常的事务创建,或者检查版本行是否对所有活跃事务都不可见。对于后者,可以通过比较版本行的end-ts
和活跃事务的TID
来实现。
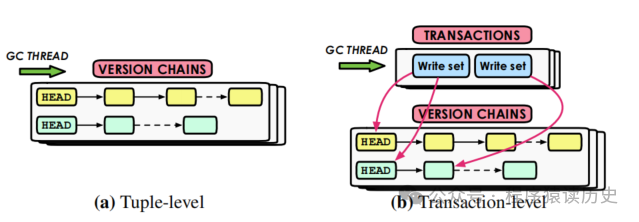
Tuple-level
Transaction-level
小结
Tuple-level的 VAC 是最常用的版本数据清理方案,通过增加GC线程的数量可以提升它的性能。但是对比
Transaction-level GC,这种方案在面对长事务/大事务的时候会对性能有较大的影响,因为长事务意味着它开始之后的所有版本数据都得不到清理,这时候版本数据链就会变得很长,直到长事务提交或者中止。
2.5 索引管理
delta模式下,指向元祖的主版本在主表上,所以索引无需更新。对于
append-only模式下,取决于版本链的顺序,例如
N2O的顺序下,当新版本元组创建时,主键的索引项的值也会更新。如果主键被更改,数据库会在索引上进行删除再添加。
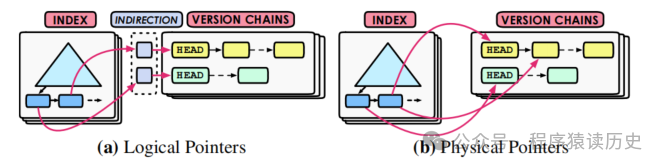
Logical Pointers
Physical Pointers
append-only,因为数据库将版本存储在同一个表中,因此所有索引都可以指向它们。当更新表中的任何元组时,数据库会将新创建的版本插入到所有二级索引中。以这种方式,数据库从二级索引中搜索元组,而无需将二级索引与所有索引版本进行比较。
小结
Logical Pointer,在写入频繁的场景下表现更好,因为辅助索引只需要在索引字段值发生改变时才会改变,在读取场景下,它还需要对不同的版本链进行对比,因为同一个逻辑值有可能对应不同的物理值;对于
Physical Pointers,频繁的更新场景会导致写入性能变差,但是在检索时就会有它的优势。
Append-only的设计,回到主表进行检索是必须的;而对于Delta存储,至少也需要在
delda空间(例如
undo log)中查找对应版本。
3.1 MySQL
undo log,
consistent read view(一致性读视图)²。它的具体流程如下:
DB_TRX_ID(最后修改该行的事务ID)、
DB_ROLL_PT(指向该行上一个版本的回滚指针)、
DB_ROW_ID(新行插入时的行ID)。数据库在每次更新一条记录时,旧值被复制到
undo log中,形成版本链。每个版本包含了创建该版本时对应的事务ID。如图11。

undo log中留下快照,用于读取旧版本信息。
3.2 Postgres
undo的概念,其文件页中以逻辑方式存放着在元组数据空间,每个元组都对应着该逻辑行数据的每一个版本,数据文件中存放着每一逻辑行的多个版本。其通过当前的事务快照和对应的元组版本号来判断该元组的有效性、可见性、可更新性。它的具体流程如下:
t_xmin(该版本的创建事务ID)和
t_xmax(删除事务ID)、
t_cid(包含cmin和cmax两个字段,标识在同一个事务中多个语句命令的序列值)等信息来唯一定义元组的版本 ,每次对元组的更改都会产生新版本的元组,版本之间会形成一条版本链,在版本链中,由旧到新。³ 如图12所示。
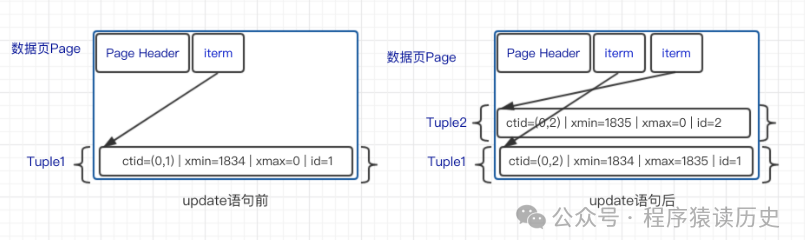
XID存储到行版本头部的
xmin中,在提交之前,该事务插入的数据对于其他事务是不可见的。对于更新和删除操作,与更新不同的是它们会将XID存储到行版本的
xmax中。事务只能读取比该事务
XID小,并且已经提交的行版本数据。
AutoVacuum自动清理辅助进程,将MVCC带来的垃圾数据定期清理。
3.3 Oracle
undo log中保存了某个数据被修改之前的前映像的数据。当我们在数据中查询之前版本的数据时,oracle首先查询的过程会在
undo中查找该数据块的前映像后,然后把前映像和当前块合并形成了一个
CR block,满足数据的一致性了。
undo使用独立的表空间来存放,不管数据被修改了多少次,不会对业务数据段产生的影响,但是
undo空间容量也是有限的,它有三种状态来管理生命周期,分别是
ACTIVE UNEXPIRED EXPIRED,活跃事务的段总是
ACTIVE状态;已完成事务的,但是在
UNDO_RETENTION周期内的是
UNEXPIRED状态;已完成事务的UNDO,但已经过了
UNDO_RETENTION保留周期的是
EXPIRED状态。
3.4 TiDB
start Timestam(StartTs),这是事务在整个生命周期内的版本基础。
Snapshot Read(快照读)原则,看到的是在事务开始时刻所有已提交事务的数据版本。读取时,会按照版本号找到最新的,但是低于当前事务时间戳的有效版本进行读取。
StartTS作为版本号。更新操作会在 MVCC 视图下创建新的版本,同时旧版本的数据得以保留。删除操作也是生成一个新的标记删除的版本,而非立即物理删除。
Time To Live策略,删除超过指定生存时间且不再被任何未提交事务引用的旧版本。对于
delete或
update后的历史版本,在没有活跃事务依赖的情况下,可以通过
compaction过程将其移除。
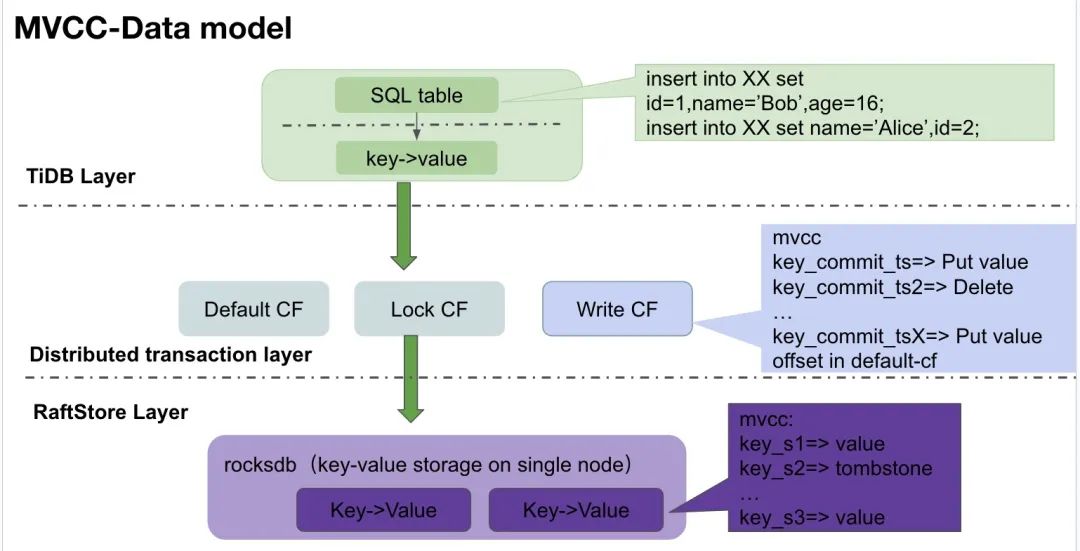
图14 来自TiDB 文章
1、https://www.vldb.org/pvldb/vol10/p781-Wu.pdf
4、https://mp.weixin.qq.com/s/ulY2vsITlAGHvypYGMzCFQ
