




DuckDB只支持UTF8编码的CSV,对于非UTF-8编码的需要自行转换, 因此很多人对此抱有比较多,但奈何DuckDB官方并不理睬。
不过今天我想告诉大家,DuckDB也可以方便地访问非UTF-8编码的CSV了,具体方法听我慢慢道来。
这一切还得归功于 DuckDB 社区扩展仓库的shellfs 扩展[1]。
shellfs 扩展
shellfs
扩展为 DuckDB 提供了使用 Unix 管道进行输入和输出的能力。
通过在文件名后附加管道字符 |
,DuckDB 会将其视为一系列要执行的命令,并捕获输出。相反,如果你在文件名前加上 |
,DuckDB 会将其视为输出管道。
虽然提供的示例很简单,但在实际场景中,您可能会使用此功能来运行另一个生成 CSV、JSON 或其他格式的程序,以管理 DuckDB 无法直接处理的复杂性。
实现使用了 popen()
来创建进程之间的管道。
shellfs 扩展 + iconv 助力编码转换
• 先上代码,再解释
-- Install the extension.
install shellfs from community;
load shellfs;
select * from read_csv('iconv -f gbk -t utf-8 data/gbk.csv|')

• 测试数据的获得
import pandas as pd
df = pd.DataFrame({"test":['DuckDB很牛','DuckDB只支持UTF-8']})
df.to_csv('data/gbk.csv',encoding='GBK',index=False)
如果使用duckdb直接访问gbk.csv
会报错
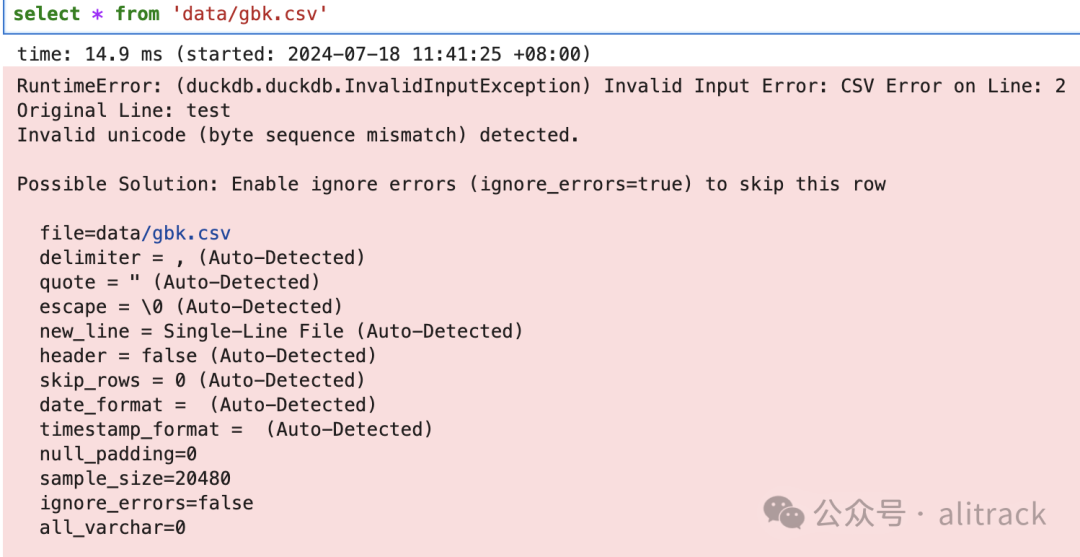
从上面的代码可以看出,需要用到iconv命令,Linux 和macOS已经内置了,如果是Windows,需要额外下载iconv应用,
Windows 下的测试

想要下载可以查看这个链接获得下载地址这两款软件可以解决你大部分编码的烦恼, 我的都是单文件,无额外依赖, 也可以网上自行搜索下载别的编译版本。
结论
如果碰到转换的过程中出现乱码,可以考虑添加额外参数-c
如果觉得这样不满意,可以自己扩展read_csv,增加编码支持。
file可以自动获取文本文件的编码,但并不是总有效,我曾经写过一个应用,结合几种技术更高效地判断编码,并转为UTF-8版本的CSV。
引用链接
[1]
shellfs 扩展: https://github.com/rustyconover/duckdb-shellfs-extension
