




从COPY导数里竟然还能挖掘出这么多一个个小问题
看腻了就来听听视频演示吧(持续更新中):
https://www.bilibili.com/video/BV1Z6vseLEux/
https://www.bilibili.com/video/BV1u1v8e7EBv/
有事先吐槽,没事再整理文章
吐下槽先 😁
不怕需求有多难,就怕提需求的人脑洞有多离谱。
真是问题处理多了,啥都见怪不怪了。
场景描述
数仓供数,业务从那边拿文本数据,类似csv和txt的文本数据再用copy导入到PostgreSQL和openGauss库里。早期数据文件几个GB采用truncate表后再全量导入,随着业务发展现在数据文件达到几十、上百GB的全量数据,前来咨询是否能做到:数仓供数那边提供增量数据文件,包含修改的数据,用 copy 导入时对已经存在的数据做update,新数据做insert。
针对业务场景这个需求也是挺正常滴 . . .
先copy导数再合并表数据
先将增量数据导入相同表结构的临时表里,然后再合并表数据。
merge into
PostgreSQL 15开始支持merge into语法:https://www.postgresql.org/docs/15/sql-merge.html
-- merge into,约束条件是关联条件on后面的数据唯一,不存重复数据,否则会报错:ERROR: unable to get a stable set of rows in the source tables
drop table IF EXISTS test1;
CREATE TABLE test1(id int,name text);
insert into test1 values(1,'PostgreSQL'),(2,'Oracle'),(3,'MySQL');
create unique index on test1(id);
drop table IF EXISTS test2;
CREATE TABLE test2(id int,name text);
insert into test2 values(5,'TiDB'),(1,'PG'),(2,'OG'),(4,'Oracle'),(6,'SQLServer');
create unique index on test1(id);
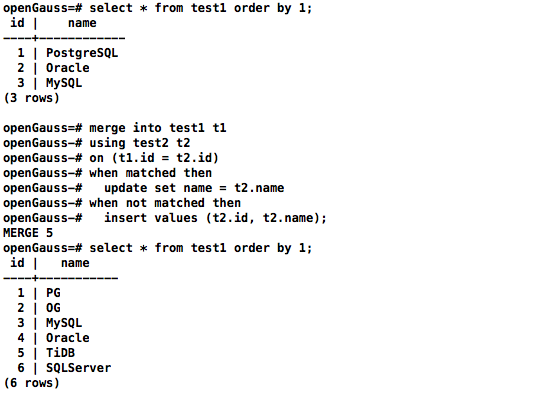
select * from test1 order by 1;
merge into test1 t1
using test2 t2
on (t1.id = t2.id)
when matched then
update set name = t2.name
when not matched then
insert values (t2.id, t2.name);
CTE
PostgreSQL 15之前的版本可用CTE写法实现merge into语法
drop table IF EXISTS test1;
CREATE TABLE test1(id int,name text);
insert into test1 values(1,'PostgreSQL'),(2,'Oracle'),(3,'MySQL');
drop table IF EXISTS test2;
CREATE TABLE test2(id int,name text);
insert into test2 values(5,'TiDB'),(1,'PG'),(2,'OG'),(4,'Oracle'),(6,'SQLServer');
-- 存在重复数据时,更新表test1已存在的数据则更新第一个数字,不存在数据则都会插入
insert into test2 values(5,'TiDB'),(1,'PG'),(2,'OG'),(2,'OG-HA'),(4,'Oracle'),(4,'Oracle-RAC'),(6,'SQLServer');
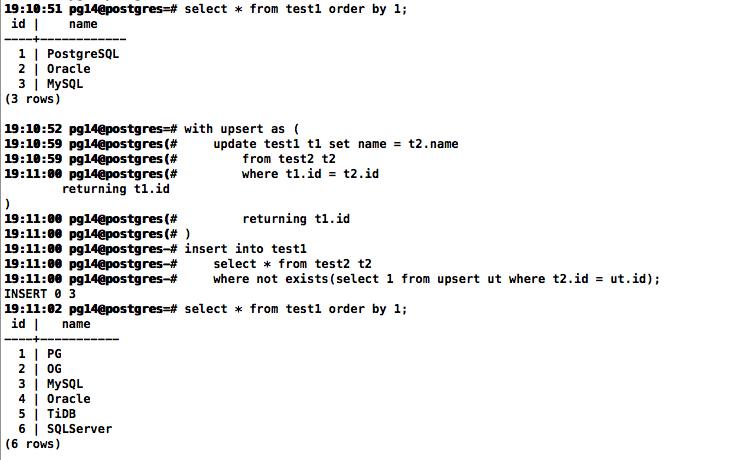
select * from test1 order by 1;
with upsert as (
update test1 t1 set name = t2.name
from test2 t2
where t1.id = t2.id
returning t1.id
)
insert into test1
select * from test2 t2
where not exists(select 1 from upsert ut where t2.id = ut.id);
UPDATE小细节
drop table IF EXISTS test1;
CREATE TABLE test1(id int,name text);
insert into test1 values(1,'PostgreSQL'),(2,'Oracle'),(3,'MySQL');
drop table IF EXISTS test2;
CREATE TABLE test2(id int,name text);
insert into test2 values(5,'TiDB'),(1,'PG'),(2,'OG'),(2,'OG-HA'),(4,'Oracle'),(4,'Oracle-RAC'),(6,'SQLServer');
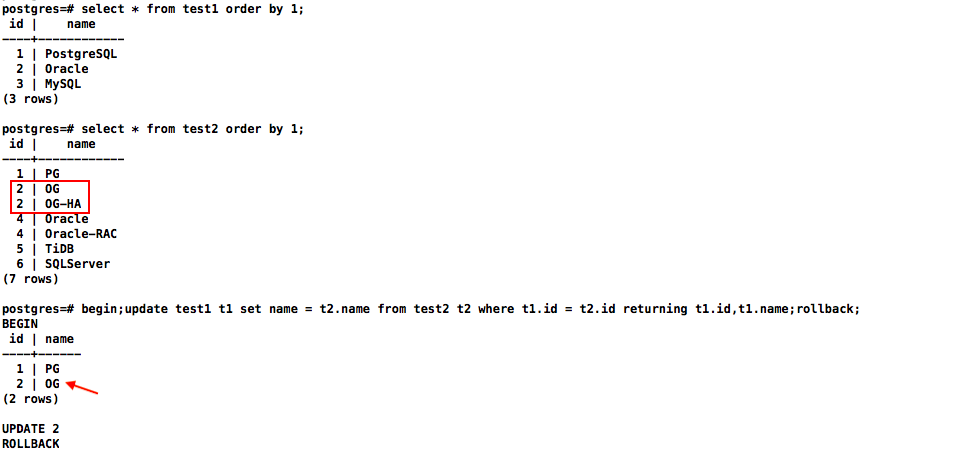
select * from test1 order by 1;
select * from test2 order by 1;
update test1 t1 set name = t2.name
from test2 t2
where t1.id = t2.id
returning t1.id,t1.name;
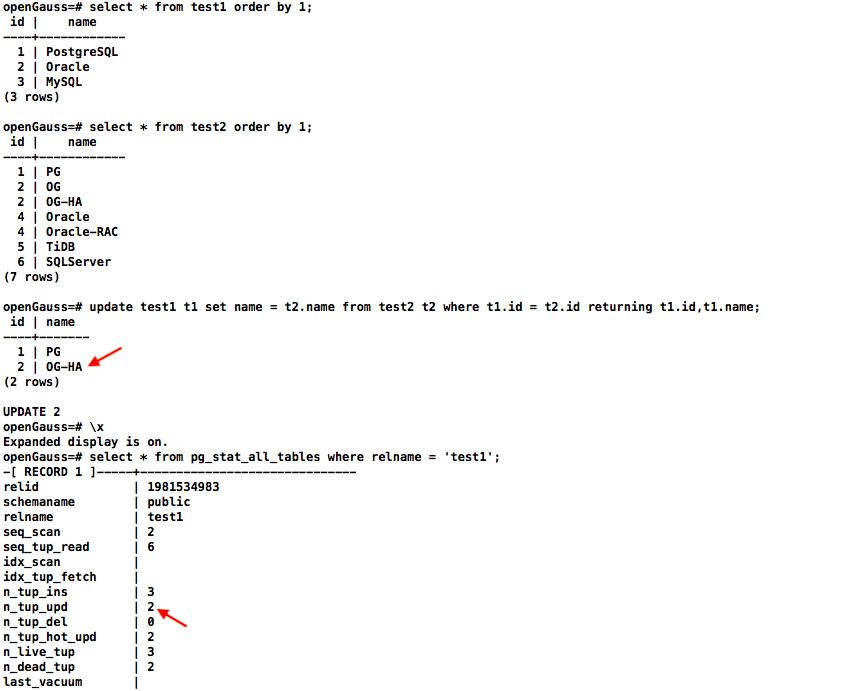
select * from pg_stat_all_tables where relname = 'test1';
PostgreSQL数据库update关联存在重复数据时只更新第一行数据:
看下PG执行计划,可以看到走merge join时是有排序的所以更新第一行数据,关闭merge join后走hash join时则更新排序后的最后一行数据:
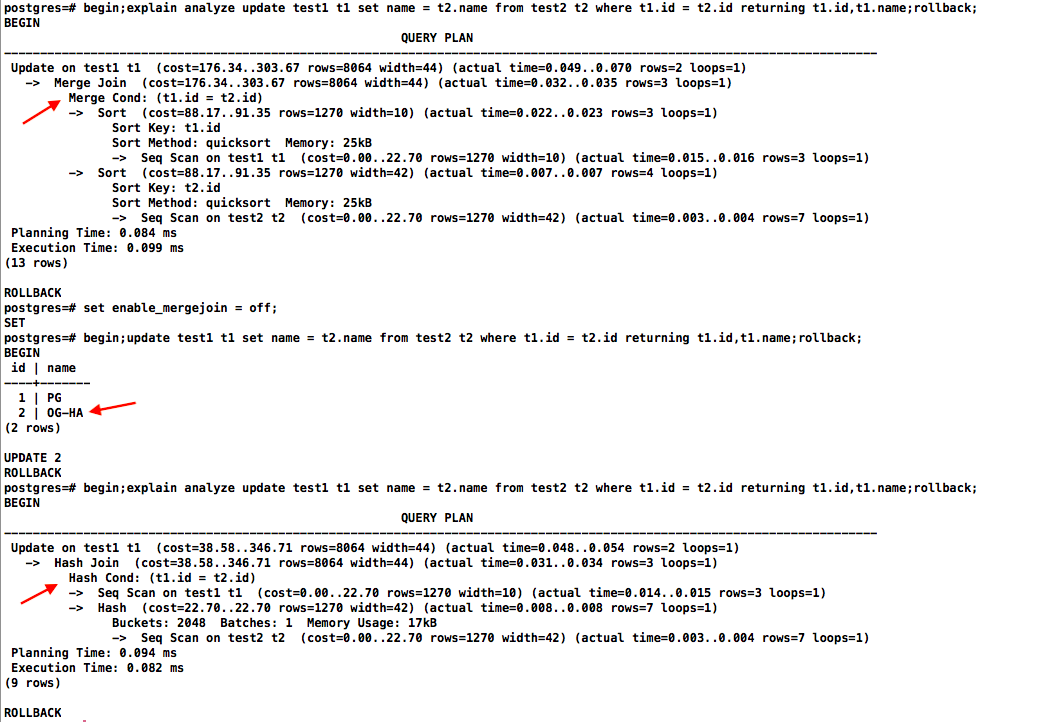
openGauss数据库update关联存在重复数据时会更新排序后的最后一行数据:
看下OG的执行计划,走的是hash join路径:
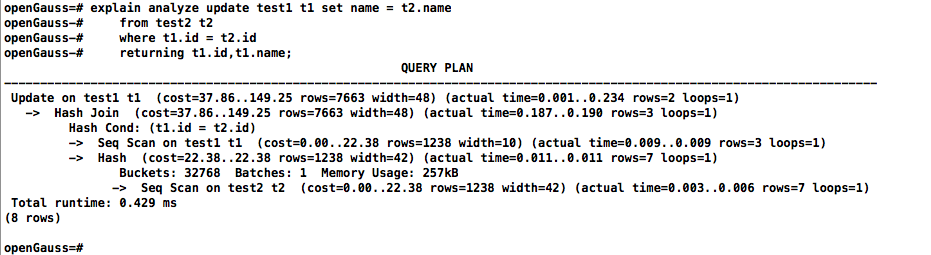
归根结底是执行计划不一致导致出现不同的执行结果。这里引伸出另外一个问题:就是同一条SQL语句不同的执行计划除了会影响执行效率,还可能影响执行结果集。
详细测试解说:https://www.modb.pro/db/1814984796269010944
这里我们把update语句换成子查询关联写法,可以看到
-- 报错:ERROR: more than one row returned by a subquery used as an expression
update test1 t1 set name = (select t2.name from test2 t2 where t1.id = t2.id ) where exists (select 1 from test2 t2 where t2.id=t1.id);
-- 增加 limit 1 仅取一行
update test1 t1 set name = (select t2.name from test2 t2 where t1.id = t2.id limit 1) where exists (select 1 from test2 t2 where t2.id=t1.id);

创建触发器copy导数一步到位
创建测试对象和数据环境:
drop table IF EXISTS test;
create table test(id int,name text);
insert into test values(1,'PostgreSQL'),(2,'openGuass'),(3,'MySQL');
-- 创建触发器,操作相同id数据时更新该name字段,update = delete + insert
create or replace function tg_gender() returns trigger as $proc$
declare
lid int;
begin
-- PG 支持,OG兼容Oracle查询返回空行会报错:ERROR: query returned no rows when process INTO
select id into lid from test where id = new.id;
-- OG 写法
-- with ft as (select id into lid from test where id = new.id)select ft.id from dual left join ft on 1=1;
if new.id = lid then
delete from test where id=new.id;
raise notice '=======: %,%', new.id,new.name;
end if;
return new;
end;
$proc$ language plpgsql;
-- 直接删除判断,极简版
create or replace function tg_gender() returns trigger as $proc$
begin
delete from test where id=new.id;
raise notice '=======: %,%', new.id,new.name;
return new;
end;
$proc$ language plpgsql;
create trigger tg_gender before insert on test for each row execute procedure tg_gender();
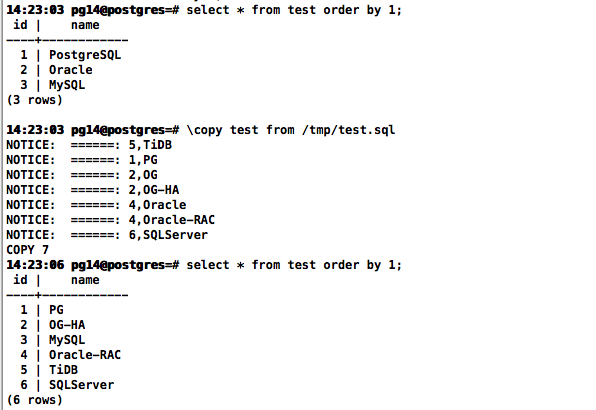
\copy test to /tmp/test.sql
vi /tmp/test.sql
5 TiDB
1 PG
2 OG
2 OG-HA
4 Oracle
4 Oracle-RAC
6 SQLServer
truncate test;
insert into test values(1,'PostgreSQL'),(2,'Oracle'),(3,'MySQL');
select * from test order by 1;
\copy test from /tmp/test.sql
PostgreSQL:
openGauss:
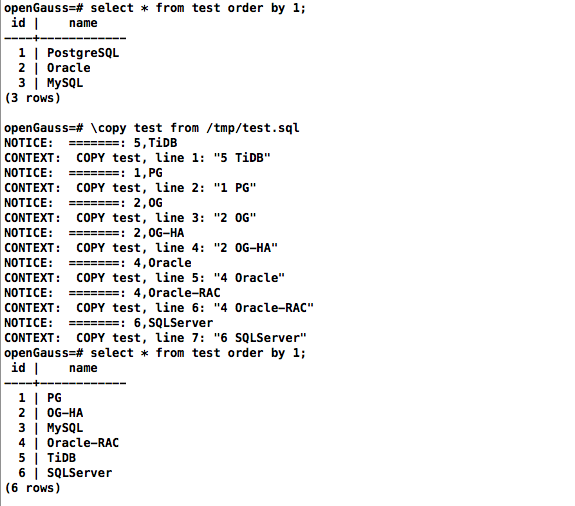
存在问题:每一行数据都要经过触发器,对性能会有较大影响
拓展
调用函数中的select into没有返回值时报错
问题描述:
openGauss数据库里 select into语句会报错:
ERROR: query returned no rows when process INTO
但在 PostgreSQL 里确是正常的,为什么呢?
问题解答:
上面查询结果为空行时,在PostgreSQL 里默认返回空,不会报错。如果加strict必须要精确返回一行,空行会报错。在openGauss数据库里, 为了兼容Oracle习惯,默认使用了strict属性,所以会报错。
测试用例:
drop table if exists test3;
create table test3(id int,info text);
CREATE OR REPLACE function public.test3()
returns varchar AS $function$
declare
v_out varchar;
begin
select info into v_out from test3 where id=10;
return v_out;
end;
$function$
LANGUAGE plpgsql;
select test3();

