




半结构化数据是一种灵活多变的数据形式,不受固定结构限制,无需事先定义固定的表结构,为数据存储和分析提供了强大的灵活性及便捷性。常见的半结构化数据包括 XML、JSON、日志文件等。半结构化数据被广泛应用于以下场景:
电商平台可以利用半结构化数据来存储用户对产品的评价,这些评价包括文字、图片甚至视频。这种数据结构有助于进行复杂的情感分析和用户行为模式挖掘。
移动应用利用半结构化数据记录用户行为数据,随着新功能的引入,用户行为的属性可能会发生改变。半结构化数据能够灵活适应这些变化,无需频繁修改数据库结构。
车联网、物联网等场景可使用半结构化数据存储车辆传感器的实时信息,如速度、位置和油耗,提供高度灵活性以适应技术更新。这使得平台能够提供实时监控、故障预警和智能路线规划等服务,提升驾驶体验和车辆性能。
为应对半结构化数据的处理,Apache Doris 2.1 之前的版本提供了两种解决方案:预定义表结构和直接将数据存储为 JSON 。虽然早期方案各有优势,但在解析性能、数据读取效率以及运维研发成本方面仍面临巨大的挑战。例如:将数据直接存储为 JSON 后,在查询时需要实时解析 JSON 数据 ,这将导致较高的 CPU/IO 消耗和查询延迟,尤其是在处理大量或复杂半结构化数据时,性能瓶颈尤为突出。此外,也由于缺乏预定义结构,查询优化将变得更加复杂,从而影响数据处理分析的效率。
全新 Variant 数据类型
在最新发布的 Apache Doris 2.1 新版本中,我们引入了全新的数据类型 Variant,对半结构化数据分析能力进行了全面增强。
功能及使用介绍
建表:建表语法关键字 variant
-- 无索引
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
table_properties;
-- 在v列创建索引,可选指定分词方式,默认不分词
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT,
INDEX idx_var(v) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
)
table_properties;
-- 在v列创建bloom filter
CREATE TABLE IF NOT EXISTS ${table_name} (
k BIGINT,
v VARIANT
)
...
properties("replication_num" = "1", "bloom_filter_columns" = "v");
查询:通过 [] 访问子列,子列的类型同样为 Variant 类型
SELECT v["properties"]["title"] from ${table_name}
接下来,我们使用 Github Events 数据展示 Variant 的建表、导入、查询。下面是其中一条格式化后的数据。
{
"id": "14186154924",
"type": "PushEvent",
"actor": {
"id": 282080,
"login": "brianchandotcom",
"display_login": "brianchandotcom",
"gravatar_id": "",
"url": "https://api.github.com/users/brianchandotcom",
"avatar_url": "https://avatars.githubusercontent.com/u/282080?"
},
"repo": {
"id": 1920851,
"name": "brianchandotcom/liferay-portal",
"url": "https://api.github.com/repos/brianchandotcom/liferay-portal"
},
"payload": {
"push_id": 6027092734,
"size": 4,
"distinct_size": 4,
"ref": "refs/heads/master",
"head": "91edd3c8c98c214155191feb852831ec535580ba",
"before": "abb58cc0db673a0bd5190000d2ff9c53bb51d04d",
"commits": [""]
},
"public": true,
"created_at": "2020-11-13T18:00:00Z"
}
创建 3 个 Variant 类型的列, actor,repo 和 payload 创建表的同时创建 payload 列的倒排索引 idx_payload USING INVERTED 指定索引类型是倒排索引,用于加速子列的条件过滤 PROPERTIES("parser" = "english") 指定采用english 分词
CREATE DATABASE test_variant;
USE test_variant;
CREATE TABLE IF NOT EXISTS github_events (
id BIGINT NOT NULL,
type VARCHAR(30) NULL,
actor VARIANT NULL,
repo VARIANT NULL,
payload VARIANT NULL,
public BOOLEAN NULL,
created_at DATETIME NULL,
INDEX idx_payload (`payload`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for payload'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(id) BUCKETS 10
properties("replication_num" = "1");
需要注意的是:在 Variant 列上创建索引,如果 Payload 的子列较多时,可能会造成索引列过多,影响写入性能。如果全部是等值查询,可以在 Variant 上构建布隆过滤器来加速等值过滤,与倒排索引相比,布隆过滤器的索引写入性能会有明显提升。同一个 Variant 列的分词属性是相同的,如果有不同的分词需求,那么可以创建多个 Variant 分别指定索引属性。
02 使用 Stream Load 导入
导入 gh_2022-11-07-3.json,该数据是 Github Events 一个小时的数据,格式化后的一行数据为:
wget http://doris-build-hk-1308700295.cos.ap-hongkong.myqcloud.com/regression/variant/gh_2022-11-07-3.json
curl --location-trusted -u root: -T gh_2022-11-07-3.json -H "read_json_by_line:true" -H "format:json" http://127.0.0.1:18148/api/test_variant/github_events/_strea
m_load
{
"TxnId": 2,
"Label": "086fd46a-20e6-4487-becc-9b6ca80281bf",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 139325,
"NumberLoadedRows": 139325,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 633782875,
"LoadTimeMs": 7870,
"BeginTxnTimeMs": 19,
"StreamLoadPutTimeMs": 162,
"ReadDataTimeMs": 2416,
"WriteDataTimeMs": 7634,
"CommitAndPublishTimeMs": 55
}
-- 查看行数
mysql> select count() from github_events;
+----------+
| count(*) |
+----------+
| 139325 |
+----------+
1 row in set (0.25 sec)
-- 随机看一条数据
mysql> select * from github_events limit 1;
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| id | type | actor | repo | payload | public | created_at |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
| 25061821748 | PushEvent | {"gravatar_id":"","display_login":"jfrog-pipelie-intg","url":"https://api.github.com/users/jfrog-pipelie-intg","id":98024358,"login":"jfrog-pipelie-intg","avatar_url":"https://avatars.githubusercontent.com/u/98024358?"} | {"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16","id":562683829,"name":"jfrog-pipelie-intg/jfinte2e_1667789956723_16"} | {"commits":[{"sha":"334433de436baa198024ef9f55f0647721bcd750","author":{"email":"98024358+jfrog-pipelie-intg@users.noreply.github.com","name":"jfrog-pipelie-intg"},"message":"commit message 10238493157623136117","distinct":true,"url":"https://api.github.com/repos/jfrog-pipelie-intg/jfinte2e_1667789956723_16/commits/334433de436baa198024ef9f55f0647721bcd750"}],"before":"f84a26792f44d54305ddd41b7e3a79d25b1a9568","head":"334433de436baa198024ef9f55f0647721bcd750","size":1,"push_id":11572649828,"ref":"refs/heads/test-notification-sent-branch-10238493157623136113","distinct_size":1} | 1 | 2022-11-07 11:00:00 |
+-------------+-----------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------+---------------------+
1 row in set (0.23 sec)
-- 未开启扩展列展示
mysql> desc github_events;
+------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(30) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| repo | VARIANT | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| public | BOOLEAN | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
+------------+-------------+------+-------+---------+-------+
7 rows in set (0.01 sec)
-- 开启Variant扩展列展示
mysql> set describe_extend_variant_column = true;
Query OK, 0 rows affected (0.01 sec)
mysql> desc github_events;
+------------------------------------------------------------+------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------------------------------------------+------------+------+-------+---------+-------+
| id | BIGINT | No | true | NULL | |
| type | VARCHAR(*) | Yes | false | NULL | NONE |
| actor | VARIANT | Yes | false | NULL | NONE |
| actor.avatar_url | TEXT | Yes | false | NULL | NONE |
| actor.display_login | TEXT | Yes | false | NULL | NONE |
| actor.id | INT | Yes | false | NULL | NONE |
| actor.login | TEXT | Yes | false | NULL | NONE |
| actor.url | TEXT | Yes | false | NULL | NONE |
| created_at | DATETIME | Yes | false | NULL | NONE |
| payload | VARIANT | Yes | false | NULL | NONE |
| payload.action | TEXT | Yes | false | NULL | NONE |
| payload.before | TEXT | Yes | false | NULL | NONE |
| payload.comment.author_association | TEXT | Yes | false | NULL | NONE |
| payload.comment.body | TEXT | Yes | false | NULL | NONE |
....
+------------------------------------------------------------+------------+------+-------+---------+-------+
406 rows in set (0.07 sec)
DESCRIBE ${table_name} PARTITION ($partition_name);
03 查询
需要注意的是:在使用过滤和聚合等功能查询子列时,需对子列执行额外的 CAST 操作,以确保数据类型一致性。这是因为存储类型可能不固定,需要通过 SQL 的 CAST 表达式来统一数据类型。例如,可以使用 SELECT * FROM tbl WHERE CAST(var['title'] AS TEXT) MATCH 'hello world' 来进行查询。
以下简化的示例说明如何使用 Variant 进行查询,下面是典型的三个查询场景:
1. 从 github_events 表中获取 Top5 Star 数的代码库
mysql> SELECT
-> cast(repo["name"] as text) as repo_name, count() AS stars
-> FROM github_events
-> WHERE type = 'WatchEvent'
-> GROUP BY repo_name
-> ORDER BY stars DESC LIMIT 5;
+--------------------------+-------+
| repo_name | stars |
+--------------------------+-------+
| aplus-framework/app | 78 |
| lensterxyz/lenster | 77 |
| aplus-framework/database | 46 |
| stashapp/stash | 42 |
| aplus-framework/image | 34 |
+--------------------------+-------+
5 rows in set (0.03 sec)
mysql> SELECT
-> count() FROM github_events
-> WHERE cast(payload['comment']['body'] as text) MATCH 'doris';
+---------+
| count() |
+---------+
| 3 |
+---------+
1 row in set (0.04 sec)
3. 查询 Comments 最多的 Issue 号以及对应的库
mysql> SELECT
-> cast(repo["name"] as string) as repo_name,
-> cast(payload["issue"]["number"] as int) as issue_number,
-> count() AS comments,
-> count(
-> distinct cast(actor["login"] as string)
-> ) AS authors
-> FROM github_events
-> WHERE type = 'IssueCommentEvent' AND (cast(payload["action"] as string) = 'created') AND (cast(payload["issue"]["number"] as int) > 10)
-> GROUP BY repo_name, issue_number
-> HAVING authors >= 4
-> ORDER BY comments DESC, repo_name
-> LIMIT 50;
+--------------------------------------+--------------+----------+---------+
| repo_name | issue_number | comments | authors |
+--------------------------------------+--------------+----------+---------+
| facebook/react-native | 35228 | 5 | 4 |
| swsnu/swppfall2022-team4 | 27 | 5 | 4 |
| belgattitude/nextjs-monorepo-example | 2865 | 4 | 4 |
+--------------------------------------+--------------+----------+---------+
3 rows in set (0.03 sec)
04 注意事项
Variant 性能对比
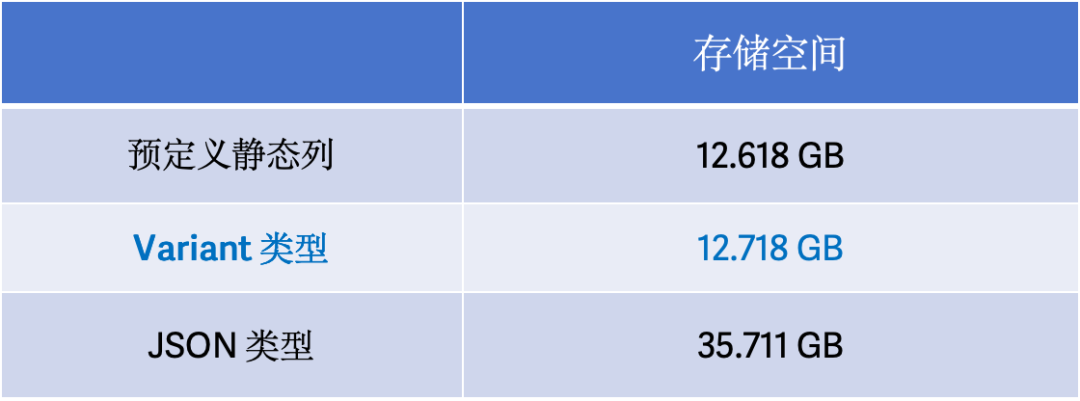
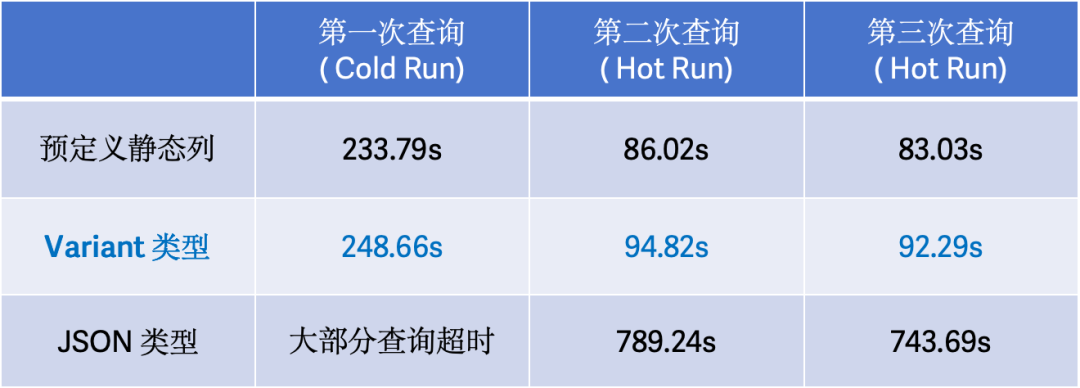
为了验证引入 Variant 数据类型后,在存储以及查询上所带来的优势,我们基于 Clickbench 数据对预定义静态列、Variant 数据类型、JSON 数据类型进行了测试,测试环境为一台配置为 16 核 64GB 内存的阿里云 ECS 实例,配备了 1TB ESSD 云盘,测试结果如下:
01 存储空间
02 查询性能
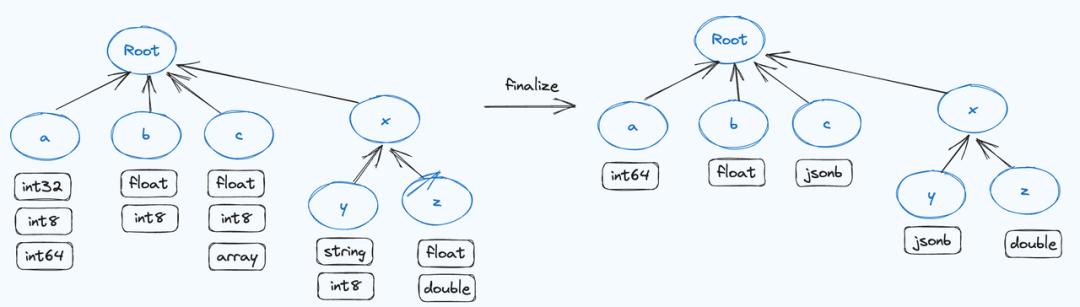
Variant 的设计实现
01 写入与类型推断
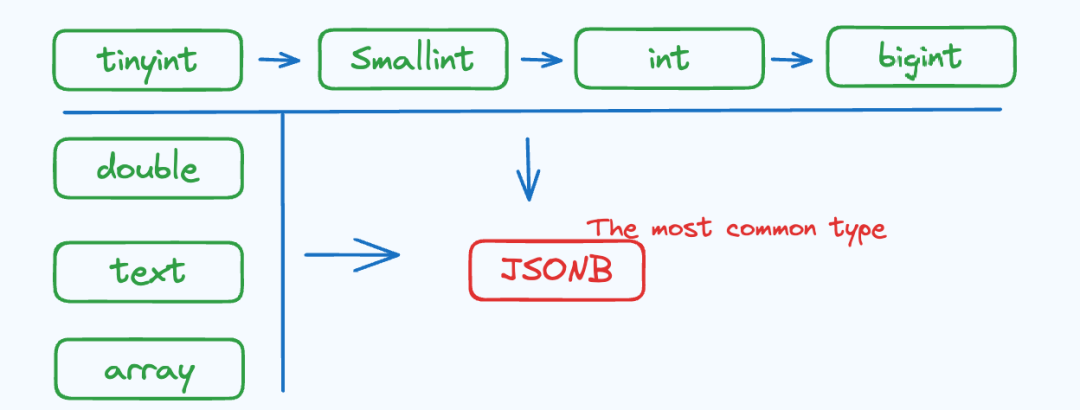
02 列变更(加列、列类型变更)

最终 ,Rowset 将使用最小公共列模式(Least Common Column Schema,即子列最多、子列类型是所有 Segment 最小公共类型的 Schema )作为合并后的元数据,从而实现列动态扩展、类型变更。因此,对于 Variant 来说,其存储的 Schema 可以认为由数据驱动产生,与 Doris 中传统的 Schema Change 流程不同,具备更大的灵活性。下图展示了类型变更的方向(只支持按箭头所指方向进行变更,JSONB 类型是所有类型的公共类型):
03 索引以及查询加速
Variant 中的叶子节点是以列存的方式存储在 Segment 文件中,与静态预定义的列存储格式完全相同。因此,可以直接利用预定义列的优化技术,例如字典编码、向量化和索引(ZoneMap、倒排、BloomFiter 等)进行查询加速。由于相同的列在不同文件中可能具有不同的类型,因此在查询时需要用户指定一个类型作为 hint,例如下面的查询示例:
-- var['title']是访问var这个variant字段下的title子列, 如果var上有倒排索引, 则利用倒排加速过滤
SELECT * FROM tbl where CAST(var['titile'] as text) MATCH "hello world"
-- 如果var上有BloomFilter, 则利用BloomFilter加速等值过滤
SELECT * FROM tbl where CAST(var['id'] as bigint) = 1010101
04 稀疏列存储优化
针对 JSON 列特别稀疏的场景, 例如以下数据:
{"a":[1], "b":2, "c":3, "x_1" : 1,"x_2": "3"}
{"a":1, "b":2, "c":3, "x_1" : 1,"x_2": "3"}
{"a":4, "b":5, "c":6, "x_3" : 1,"x_4": "3"}
{"a":7, "b":8, "c":9, "x_5" : 1,"x_6": "3"}
...
在该场景中,将数据导入到 Doris 时,系统会根据 Column 中 Null 值的占比,来判断列的稠密和稀疏程度。对于较为稀疏的列(Null 占比高),存储层将其打包成 JSONB 编码,并存储在单独列中。列存结构如下所示:
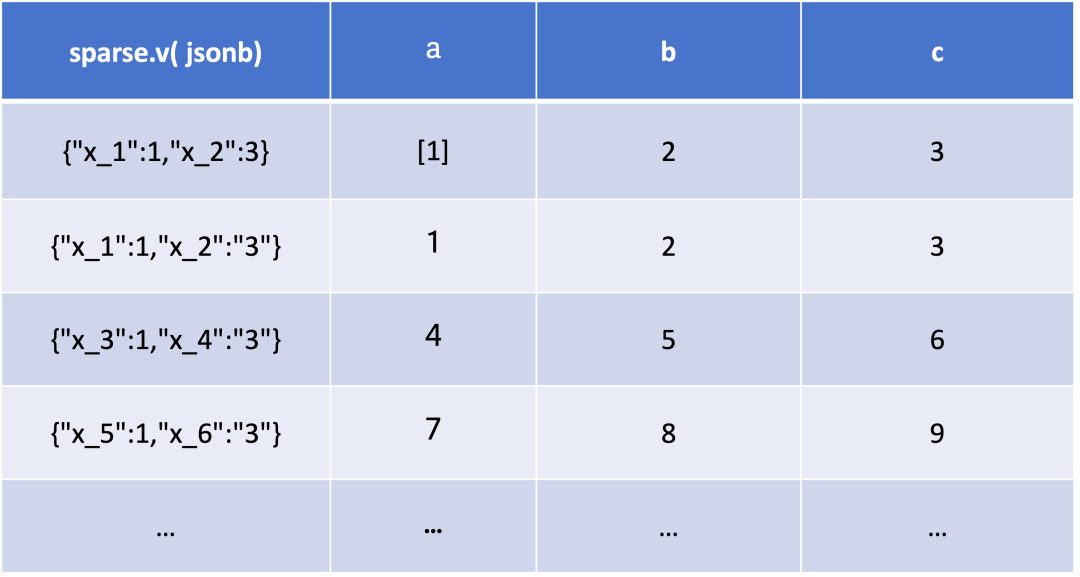
当启用稀疏列存储优化后,可降低存储 Meta 以及 Compaction 的压力,并提高了 Variant 的灵活性。稀疏列的查询方式与其他列完全一致,用户不必关心实现。
用户案例
观测云是国内领先的可观测性平台,在过去使用 Elasticsearch 来存储采集到的日志数据和用户行为数据。在面对大量的用户自定义字段时,Elasticsearch 对于 Schemaless 支持有限、原有的 Dynamic Mapping 会频繁造成字段类型冲突导致数据丢失,严重依赖人工介入进行手动处理。同时 Elasticsearch 的写入占用过多资源、面对海量数据时的低聚合性能表现,这些不足严重限制了自身业务的发展。
彻底解决了 Elasticsearch 中动态映射的问题。相比于 Elasticsearch 的动态 Schema 和类型固定的限制,Doris 使用 Variant 实现了 Partition 区级别的 Schema 变更,使得类型处理更加高效和灵活。此外,Doris 没有列数上限的限制,从而更好地满足了 Schemafree 的需求。 大幅降低写入操作的资源消耗,显著降低了写入时的 CPU 占用。 在处理海量数据的聚合查询时,借助倒排索引和查询优化技术,Doris 能够更快速地进行复杂的聚合查询,提供更高效的数据分析能力;
结束语

