





点击蓝字,关注我们

导读:检索增强生成(RAG)模型通过集成外部数据检索来提高生成式语言模型生成结果的准确性和相关性。然而,传统RAG模型在处理复杂的图结构数据时忽视了文本之间的联系和数据库的拓扑信息,从而导致了性能瓶颈。为了解决这一问题,本文提出了图检索增强生成(GRAG)模型,通过强调子图结构的重要性,显著提升了检索和生成过程的性能并降低幻觉。本文详细介绍了GRAG模型的动机、模型结构以及实验结果。
动机
在许多应用场景中,如科学文献网络、推荐系统和知识图谱,文档之间存在复杂的关联,这些关联在传统的RAG模型中常常被忽略。例如,在处理科学文献时,RAG仅基于文本相似性的检索方法无法充分利用文献之间的引用关系和主题结构。这种忽视导致了生成质量的瓶颈。因此,本文提出GRAG模型,通过考虑文献之间的引用网络和主题分布将拓扑信息在检索阶段和生成阶段利用起来,提高生成式语言模型的生成质量和图场景下的上下文一致性。本文旨在解决GRAG的以下挑战:
1. 高效检索相关子图:在大规模文本图中检索相关的子图是一个NP-hard问题,检索模型需要在效率和准确性之间找到平衡。
2. 联合文本和拓扑信息:在生成过程中,需要同时利用文本和图的拓扑信息,让大语言模型理解拓扑信息是提高生成质量的关键。
模型
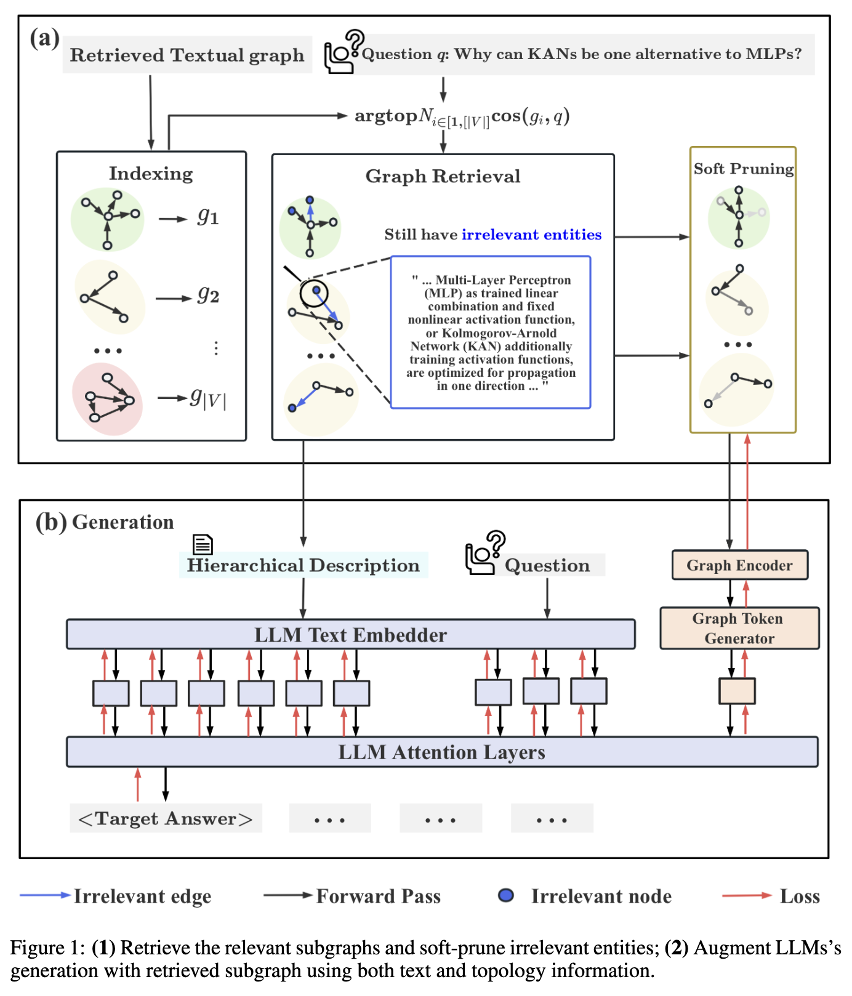
GRAG模型由四个主要阶段组成,即k阶子图索引、图检索、软剪枝和生成:
1) k阶子图索引:对图中的每个节点及其周围的k阶邻居进行编码,并存储其图嵌入。
2) 图检索:使用预训练语言模型(PLM)将查询转换为向量,并检索与查询最相关的前N个子图。
3) 软剪枝:在检索到的子图结构,对与查询不相关的节点和边进行软剪枝,以减少其对最终生成的影响。
4) 生成:整合剪枝后的文本子图和原始查询,通过GNN聚合子图内的信息。最后,利用文本信息(text tokens)和子图信息(graph token)控制生成。
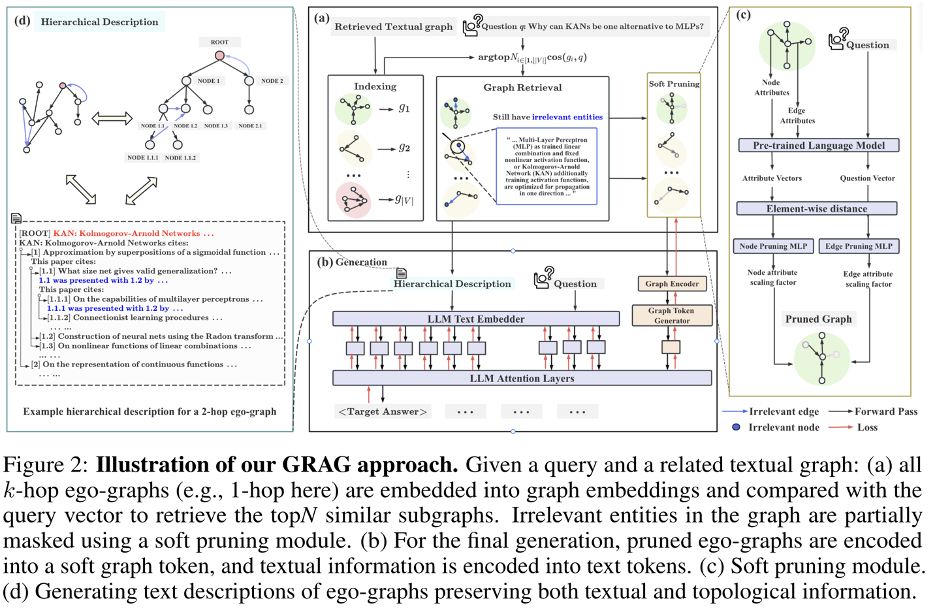
具体来说,GRAG模型采用了一种双重提示策略,即硬提示和软提示。如图2(d)所示,硬提示将检索到的子图转换为层次化的文本描述,保留拓扑信息和语义细节。如图2(c)所示,检索到的子图在剪枝过后通过GNN聚合文本和拓扑信息生成图token,随后用于引导大语言模型的生成过程。
实验
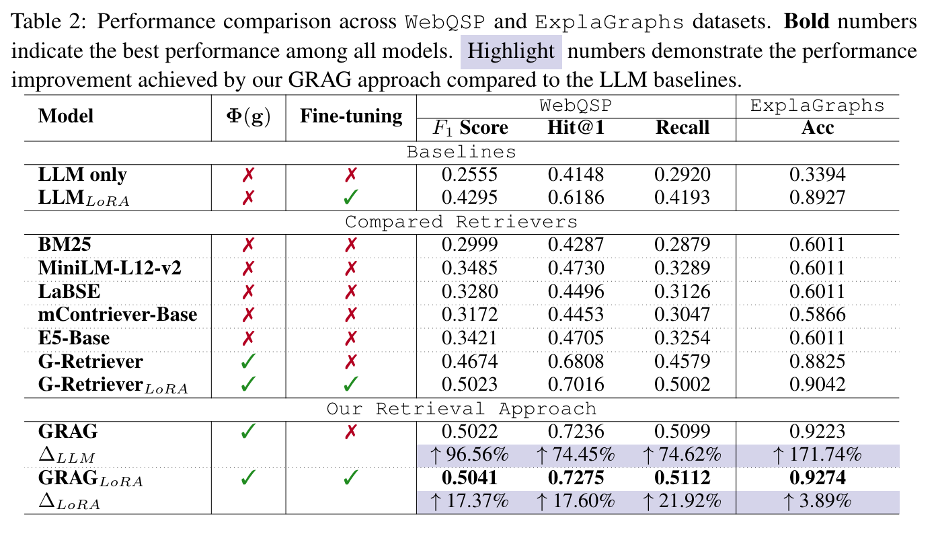
如表2所示,GRAG方法在WebQSP和ExplaGraphs数据集上的各项指标上均取得了最佳性能。在WebQSP数据集上,GRAG方法的Hit@1指标显著高于其他方法,在ExplaGraphs数据集上的准确率也同样表现出色。
特别地,本文讨论了应用GRAG时检索效率和模型性能之间的权衡。尽管我们通过编码子图的方式控制检索空间为 |V|(节点数量)个子图,检索更多的子图可以提供更全面的上下文信息以提升生成质量,但这同时也会增加计算开销和处理时间。为了平衡效率和性能,需要合理选择检索的子图数量。
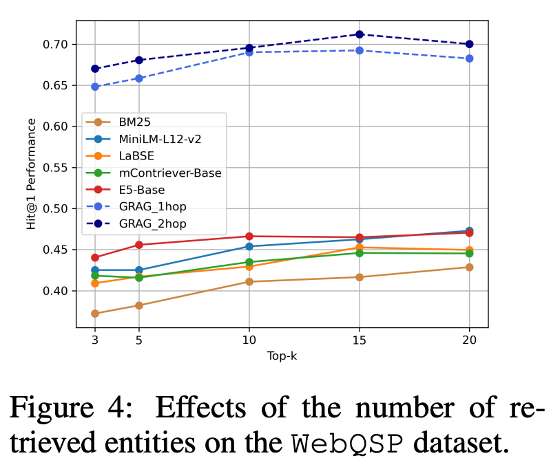
如文中图四所示,随着检索子图数量的增加,生成效果在一定范围内不断提升。例如,在WebQSP数据集上,从3个子图增加到15个子图,生成的Hit@1得分明显提高。然而,进一步增加子图数量到20个后,性能提升变得不明显,甚至出现轻微下降。这表明,过多的检索结果可能引入冗余信息,反而对生成结果产生负面影响。
总结
GRAG模型通过联合文本和图的拓扑信息,有效解决了传统RAG模型在处理图数据时的不足。实验结果证明,GRAG方法在图上的多跳推理任务上显著优于当前最先进的RAG方法和LLM基线,特别是在需要复杂推理和图上下文一致性的场景中。未来的研究可以进一步探索GRAG在更多复杂图形数据场景中的应用潜力。
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
