




背景信息
随着非结构化数据(如图像、视频和音频)的爆炸性增长,非结构化数据分析在现实世界的丰富应用脉络中广泛存在。这些非结构化数据最终会以特征向量的形式存储在向量数据库当中。如何在庞大的数据中找到想要的数据便成为了目前研究热点。
在目前成熟的索引算法中,均利用数据划分来加快索引速率,如IVFflat,IVFPQ等。其很少有从查询角度进行优化的方法被提出。故本方案设计一种基于学习型模型的向量数据库索引算法,它是从查询驱动优化角度来提高索引速率。
技术方案
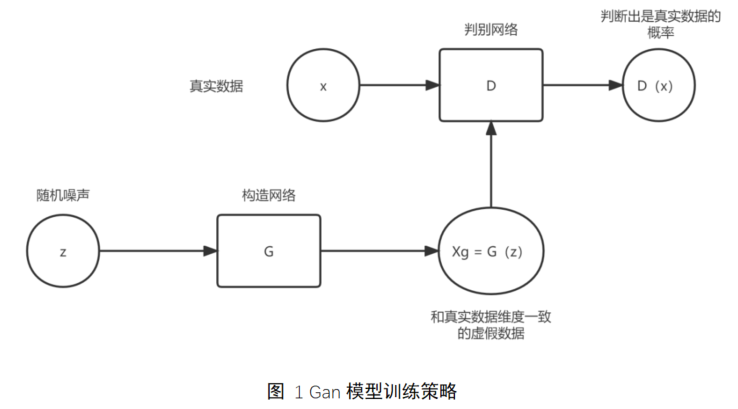
训练预测结果生成模型(Gan);
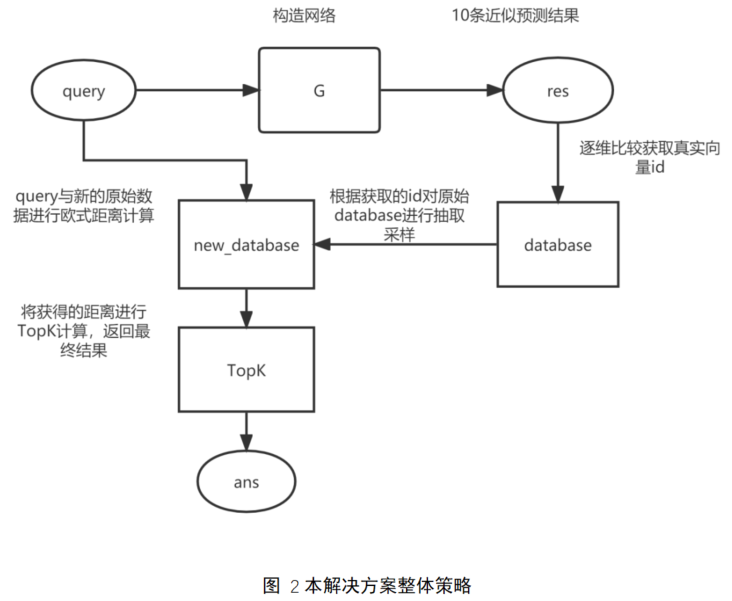
利用Gan模型生成query的10条近似结果;
将原始数据按向量维度进行排序;
根据Gan模型生成的query预测结果数据,查询其那维度排序后周围的20条数据;
我们假设数据维度为n,最终我们将得到200n条预选数据;
利用原始query与获取到的200n条预测数据进行欧式距离计算,选取最终topk结果最为输出。
最后修改时间:2024-07-25 14:42:43
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
