




SQL解析器
SQL解析器主要是识别用户输入的SQL语句,并将其转化为后续优化器所需要的查询树结构。对应的就是将SQL通过bison转换为RawStmt的结构,再将RawStmt转换为Query结构。代码主要在postgres/src/backend/parser这一部分,大概不到4W行代码左右。
[postgres@slpc parser]$ ls
analyze.c parse_clause.c parse_expr.c parse_partition_lt.c parse_utilcmd.c
check_keywords.pl parse_coerce.c parse_func.c parser.c README
gram.y parse_collate.c parse_node.c parse_relation.c scan.l
Makefile parse_cte.c parse_oper.c parse_target.c scansup.c
parse_agg.c parse_enr.c parse_param.c parse_type.c
[postgres@slpc parser]$ cloc .
25 text files.
24 unique files.
2 files ignored.
github.com/AlDanial/cloc v 1.70 T=0.24 s (95.4 files/s, 234155.3 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 19 3757 9706 22455
yacc 1 1295 2190 15241
lex 1 164 457 897
Perl 1 43 28 166
make 1 15 20 37
-------------------------------------------------------------------------------
SUM: 23 5274 12401 38796
-------------------------------------------------------------------------------
以SELECT语句为例,在这一阶段,会将select * from t1转化为SelectStmt,进而转为抽象语法树RawStmt,把SQL文本字符串转为数据库可以理解的数据结构。
typedef struct RawStmt
{
NodeTag type;
Node *stmt; /* raw parse tree */
int stmt_location; /* start location, or -1 if unknown */
int stmt_len; /* length in bytes; 0 means "rest of string" */
} RawStmt;
typedef struct SelectStmt
{
NodeTag type;
/*
* These fields are used only in "leaf" SelectStmts.
*/
List *distinctClause; /* NULL, list of DISTINCT ON exprs, or
* lcons(NIL,NIL) for all (SELECT DISTINCT) */
IntoClause *intoClause; /* target for SELECT INTO */
List *targetList; /* the target list (of ResTarget) */
List *fromClause; /* the FROM clause */
Node *whereClause; /* WHERE qualification */
List *groupClause; /* GROUP BY clauses */
bool groupDistinct; /* Is this GROUP BY DISTINCT? */
Node *havingClause; /* HAVING conditional-expression */
List *windowClause; /* WINDOW window_name AS (...), ... */
/*
* In a "leaf" node representing a VALUES list, the above fields are all
* null, and instead this field is set. Note that the elements of the
* sublists are just expressions, without ResTarget decoration. Also note
* that a list element can be DEFAULT (represented as a SetToDefault
* node), regardless of the context of the VALUES list. It's up to parse
* analysis to reject that where not valid.
*/
List *valuesLists; /* untransformed list of expression lists */
/*
* These fields are used in both "leaf" SelectStmts and upper-level
* SelectStmts.
*/
List *sortClause; /* sort clause (a list of SortBy's) */
Node *limitOffset; /* # of result tuples to skip */
Node *limitCount; /* # of result tuples to return */
LimitOption limitOption; /* limit type */
List *lockingClause; /* FOR UPDATE (list of LockingClause's) */
WithClause *withClause; /* WITH clause */
/*
* These fields are used only in upper-level SelectStmts.
*/
SetOperation op; /* type of set op */
bool all; /* ALL specified? */
struct SelectStmt *larg; /* left child */
struct SelectStmt *rarg; /* right child */
/* Eventually add fields for CORRESPONDING spec here */
} SelectStmt;

在阅读PG源码的过程中,每个README都是必读的,下面是对应解析器部分的README:
/*
src/backend/parser/README
Parser
======
这句话最重要,解析SQL语句转换为Query结构,给Optimizer和executor使用。
This directory does more than tokenize and parse SQL queries. It also
creates Query structures for the various complex queries that are passed
to the optimizer and then executor.
parser.c things start here
scan.l break query into tokens
scansup.c handle escapes in input strings
gram.y parse the tokens and produce a "raw" parse tree
analyze.c top level of parse analysis for optimizable queries
parse_agg.c handle aggregates, like SUM(col1), AVG(col2), ...
parse_clause.c handle clauses like WHERE, ORDER BY, GROUP BY, ...
parse_coerce.c handle coercing expressions to different data types
parse_collate.c assign collation information in completed expressions
parse_cte.c handle Common Table Expressions (WITH clauses)
parse_expr.c handle expressions like col, col + 3, x = 3 or x = 4
parse_func.c handle functions, table.column and column identifiers
parse_node.c create nodes for various structures
parse_oper.c handle operators in expressions
parse_param.c handle Params (for the cases used in the core backend)
parse_relation.c support routines for tables and column handling
parse_target.c handle the result list of the query
parse_type.c support routines for data type handling
parse_utilcmd.c parse analysis for utility commands (done at execution time)
See also src/common/keywords.c, which contains the table of standard
keywords and the keyword lookup function. We separated that out because
various frontend code wants to use it too.
*/
也就是说,解析器解决的问题就是将合法的SQL语句转换为后续优化器或者执行器用到的Query结构。一般DDL,command等语句无需优化所以无需经过优化器可直接在执行器中执行。怎么检测输入语句是否合法呢?一个是在语法定义阶段,主要是gram.y定义了语法规则,首先要符合语法规则,这个语法规则指的是符合SQL语法规则,其次是要符合语义规则,比如要查询的表必须要存在,这就要靠检查pg_class、pg_attribute等系统表中是否有相关的表信息,列信息等进行判断。
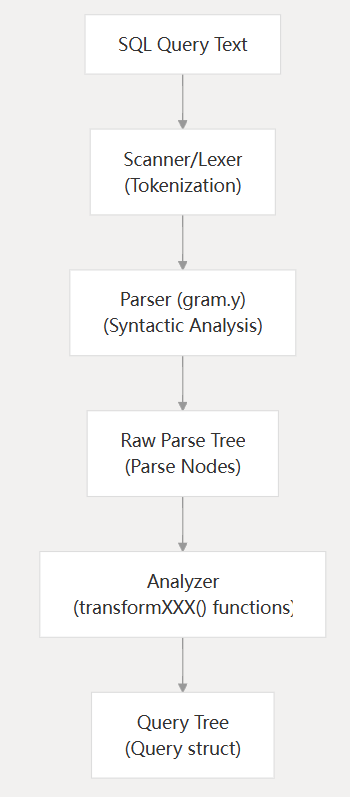
代码部分的话,将SQL转换为抽象语法树RawStmt是pg_parse_query函数,之后调用parse_analyze将RawStmt转换为查询树Query。
/* Analyze a raw parse tree and transform it to Query form.*/
Query *parse_analyze(RawStmt *parseTree, const char *sourceText,Oid *paramTypes, int numParams,QueryEnvironment *queryEnv)
{
ParseState *pstate = make_parsestate(NULL);
Query *query;
Assert(sourceText != NULL); /* required as of 8.4 */
pstate->p_sourcetext = sourceText;
if (numParams > 0)
parse_fixed_parameters(pstate, paramTypes, numParams);
pstate->p_queryEnv = queryEnv;
query = transformTopLevelStmt(pstate, parseTree);
if (post_parse_analyze_hook)
(*post_parse_analyze_hook) (pstate, query);
free_parsestate(pstate);
return query;
}

到这里一定要读一下openGauss的博文openGauss数据库源码解析系列文章——SQL引擎源码解析(一)。写的非常之好,我就不用再写了。另外非常推荐《openGauss数据库核心技术》一书,书中第7章“openGauss SQL引擎”一章值得深读。
背景知识
理解SQL解析器,就必须理解编译原理中相关的内容,这里补充一些编译原理的内容,如果对编译原理掌握较好,对SQL解析器就很容易理解了。
- 终结符: 通俗的说就是不能单独出现在推导式左边的符号,也就是说终结符不能再进行推导。
- 非终结符: 不是终结符的都是非终结符,可理解为一个可拆分元素,而终结符是不可拆 分的最小元素。
- 移进:当语法分析器读到的记号无法结束一条规则时,将该记号压入内部堆栈;
- 归约:当压入堆栈的语法符号已经可以组成规则的右部时,弹出所有右部符号,把对应的左部符号入栈;归约后会执行规则关联的代码
移进/归约冲突和操作符优先级
- 可以在语法规则外单独描述优先级,%left %right %noassoc的出现顺序决定了由低到高的优先级
- %left表示左结合、%right右结合、%noassoc表示没有结合性
- 不要滥用优先级规则,除了表达式语法或者解决if/then/else语言结构的”dangling else”冲突;尽量修正语法解决冲突
- 冲突类型有两种:移进/归约和归约/归约
- 嵌入动作:规则中间的动作,被构造一条新的规则。但有时会造成移进归约冲突
优先级和结合性声明:解决语法歧义和冲突。%prec声明规则的优先级,移进和归约冲突时,比较移进记号和归约规则的优先级,若优先级相同则检查结合性,左结合则归约,右结合则移进。典型应用:if/then/else
dangling else ambiguity
假定我们正在分析一个语言,其中有if-then和if-then-else语句,对应的规则如下:
if_stmt: IF expr THEN stmt
| IF expr THEN stmt ELSE stmt
;
这里我们假设IF,THEN和ELSE是特别的关键字终结符。
当ELSE终结符读入后作为一个预读终结符时,堆栈中的内容(假设输入是合法的)正好可以归约到第一条规则上。但是把它移进堆栈也是合理的,因为那样根据第二条规则就会导致最后的归约。
在这种情况下,移进或者归约都是合法的,称为移进-归约冲突(shift-reduce conflict)。Bison的设计是,用移进来解决冲突,除非有操作符优先级声明的指令。为了解释如此选择的理由,让我们与其它可选办法进行一个比较。
遇到shift/reduce conflict怎么办?
遇到这个,首先是定位哪里出现的冲突,可通过bison -v(生成.out日志文件) 查看(gram.y)生成的gram.out 从这里去定位问题发生在哪里,然后解决。
