




1. AVG
语法
AVG([ DISTINCT | UNIQUE | ALL ] expr) [ OVER (analytic_clause) ]示例
创建表 test1,并插入测试数据。
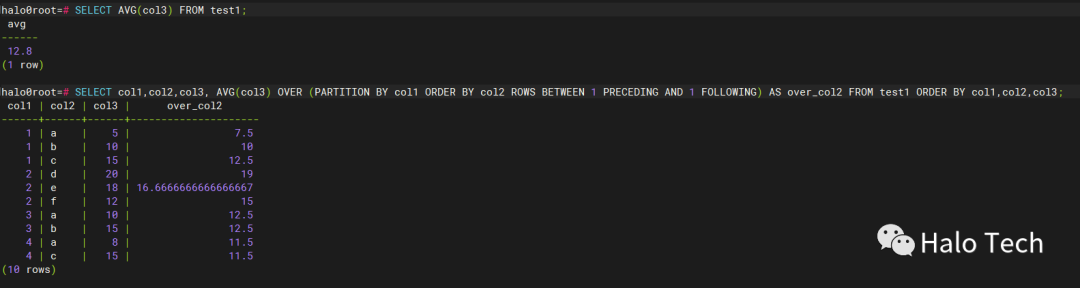
CREATE TABLE test1 (col1 INT,col2 varchar(10),col3 INT);INSERT all INTO test1 VALUES (1,'a',5)INTO test1 VALUES (1,'b',10)INTO test1 VALUES(1,'c',15)INTO test1 VALUES(2,'d',20)INTO test1 VALUES(2,'e',18)INTO test1 VALUES(2,'f',12)INTO test1 VALUES(3,'a',10)INTO test1 VALUES(3,'b',15)INTO test1 VALUES(4,'c',15)INTO test1 VALUES(4,'a',8)SELECT 1 from dual;SELECT AVG(col3) FROM test1;--以 col1 分组及列 col2 升序排序,计算列 col3 中值的之前和之后范围的平均值。SELECT col1,col2,col3, AVG(col3) OVER (PARTITION BY col1 ORDER BY col2 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS over_col2 FROM test1 ORDER BY col1,col2,col3;
2. CORR 相关系数函数
语法
CORR(expr1, expr2) [ OVER (analytic_clause) ]示例
Drop table test1;CREATE TABLE test1(col1 INT,col2 varchar(10),col3 INT,col4 INT);INSERT ALLINTO test1 VALUES (1,'A1',8,12)INTO test1 VALUES (1,'A2',10,15)INTO test1 VALUES (1,'A3',11,16)INTO test1 VALUES (2,'B1',9,14)INTO test1 VALUES (2,'B2',10,15)INTO test1 VALUES (2,'B3',8,13)INTO test1 VALUES (2,'B4',11,16)INTO test1 VALUES (3,'C1',8,18)INTO test1 VALUES (3,'C2',9,16)INTO test1 VALUES (3,'C3',10,15)INTO test1 VALUES (3,'C4',11,12)INTO test1 VALUES (3,'C5',12,10)SELECT 1 FROM DUAL;--计算列 col3 的数据与列 col4 的数据相关系数。SELECT CORR(col3,col4) FROM test1;--按列 col1 分组,计算列 col3 的数据与列 col4 的数据相关系数。SELECT col1,col3,col4,CORR(col3,col4) OVER(PARTITION BY col1) "corr" FROM test1;

3. COUNT 计数函数
语法
COUNT({ *|[DISTINCT|UNIQUE|ALL] expr })[OVER(analytic_clause)]示例
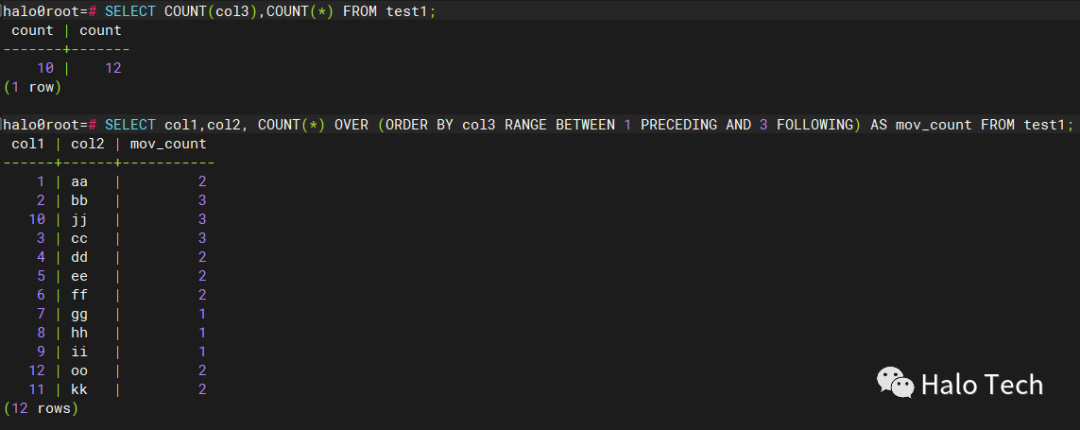
Drop table test1;CREATE TABLE test1 (col1 INT,col2 varchar(10),col3 INT);INSERT ALLINTO test1 VALUES (1,'aa',10)INTO test1 VALUES (2,'bb',12)INTO test1 VALUES (3,'cc',15)INTO test1 VALUES (4,'dd',18)INTO test1 VALUES (5,'ee',20)INTO test1 VALUES (6,'ff',23)INTO test1 VALUES (7,'gg',25)INTO test1 VALUES (8,'hh',30)INTO test1 VALUES (9,'ii',40)INTO test1 VALUES (10,'jj',15)INTO test1 VALUES (11,'kk',NULL)INTO test1 VALUES (12,'oo',NULL)SELECT * FROM dual;SELECT COUNT(col3),COUNT(*) FROM test1;--求表 中所有以 col3 中值排序并且的偏移量在 1 至 3 范围内的个数。SELECT col1,col2, COUNT(*) OVER (ORDER BY col3 RANGE BETWEEN 1 PRECEDING AND 3 FOLLOWING) AS mov_count FROM test1;
4. MAX
语法
MAX ([ DISTINCT | UNIQUE | ALL ] expr) [ OVER (analytic_clause) ]
示例
-- 创建表 employeesCREATE TABLE employees (department_id INT,manager_id INT,last_name varchar(50),hiredate varchar(50),SALARY INT);-- 插入数据INSERT INTO employees VALUES(30, 100, 'Raphaely', '2017-07-01', 1700),(30, 100, 'De Haan', '2018-05-01',11000),(40, 100, 'Errazuriz', '2017-07-21', 1400),(50, 100, 'Hartstein', '2019-10-05',14000),(50, 100, 'Raphaely', '2017-07-22', 1700),(50, 100, 'Weiss', '2019-10-05',13500),(90, 100, 'Russell', '2019-07-11', 13000),(90,100, 'Partners', '2018-12-01',14000);SELECT MAX(salary) FROM employees;--以 department_id 分组,查询 salary 列的最大值。SELECT department_id,last_name,salary, MAX(salary) OVER (PARTITION BY department_id) AS rmax_sal FROM employees;

5. MIN
语法
MIN([ DISTINCT | UNIQUE | ALL ] expr) [ OVER (analytic_clause) ]示例
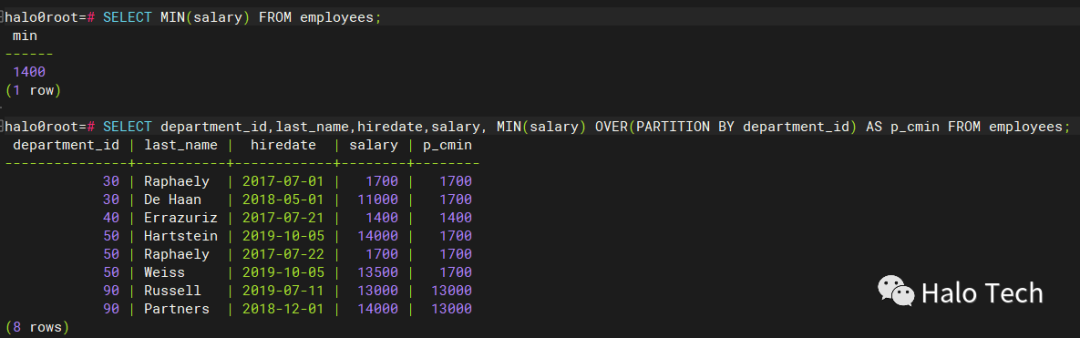
SELECT MIN(salary) FROM employees;SELECT department_id,last_name,hiredate,salary, MIN(salary) OVER(PARTITION BY department_id) AS p_cmin FROM employees;
6. RANK
语法
/*聚合语法*/RANK(expr [, expr ]...) WITHIN GROUP( ORDER BYexpr_col [ DESC | ASC ][ NULLS { FIRST | LAST } ][, expr_col [ DESC | ASC ][ NULLS { FIRST | LAST } ]]...)/*分析语法*/RANK() OVER ([ query_partition_clause ] order_by_clause)
示例
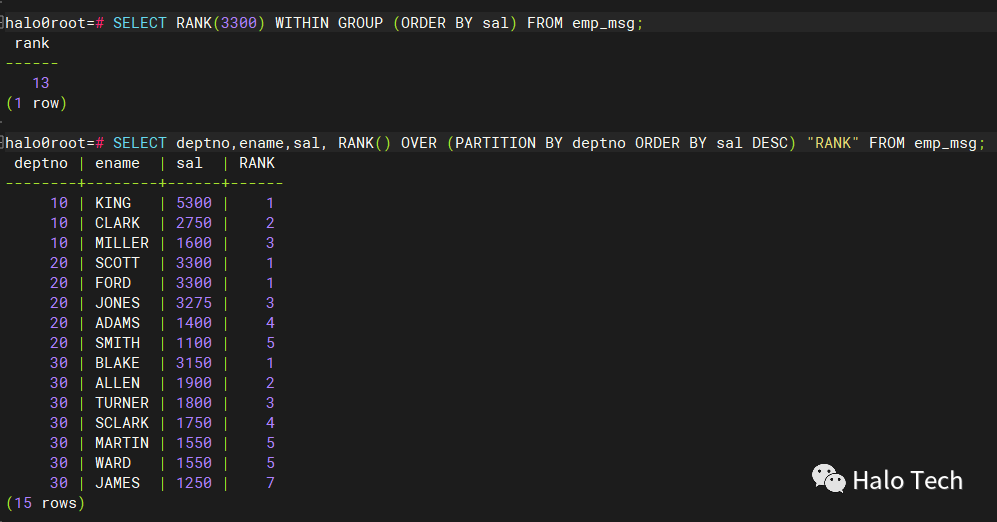
CREATE TABLE emp_msg (DEPTNO NUMBER,ENAME VARCHAR2(50),SAL NUMBER,MGR NUMBER);-- 插入数据INSERT INTO emp_msg VALUES (10, 'CLARK', 2750, 7839);INSERT INTO emp_msg VALUES (10, 'KING', 5300, NULL);INSERT INTO emp_msg VALUES (10, 'MILLER', 1600, 7782);INSERT INTO emp_msg VALUES (20, 'ADAMS', 1400, 7788);INSERT INTO emp_msg VALUES (20, 'FORD', 3300, 7566);INSERT INTO emp_msg VALUES (20, 'JONES', 3275, 7839);INSERT INTO emp_msg VALUES (20, 'SCOTT', 3300, 7566);INSERT INTO emp_msg VALUES (20, 'SMITH', 1100, 7902);INSERT INTO emp_msg VALUES (30, 'ALLEN', 1900, 7698);INSERT INTO emp_msg VALUES (30, 'BLAKE', 3150, 7839);INSERT INTO emp_msg VALUES (30, 'JAMES', 1250, 7698);INSERT INTO emp_msg VALUES (30, 'MARTIN', 1550, 7698);INSERT INTO emp_msg VALUES (30, 'TURNER', 1800, 7698);INSERT INTO emp_msg VALUES (30, 'WARD', 1550, 7698);INSERT INTO emp_msg VALUES (30, 'SCLARK', 1750, 7839);SELECT * FROM emp_msg;SELECT RANK(3300) WITHIN GROUP (ORDER BY sal) FROM emp_msg;SELECT deptno,ename,sal, RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) "RANK" FROM emp_msg;
7. DENSE_RANK
语法
/*聚合语法*/DENSE_RANK(expr [, expr ...])WITHIN GROUP ( ORDER BY expr_col [ DESC | ASC ][ NULLS { FIRST | LAST } ][,expr_col [ DESC | ASC ][ NULLS { FIRST | LAST } ]]...)/*分析语法*/DENSE_RANK( ) OVER([ query_partition_clause ] order_by_clause)
示例
SELECT DENSE_RANK(3300) WITHIN GROUP (ORDER BY sal) FROM emp_msg;SELECT deptno,ename, sal, DENSE_RANK ( ) OVER (PARTITION BY deptno ORDER BY sal DESC ) "RANK" FROM emp_msg;
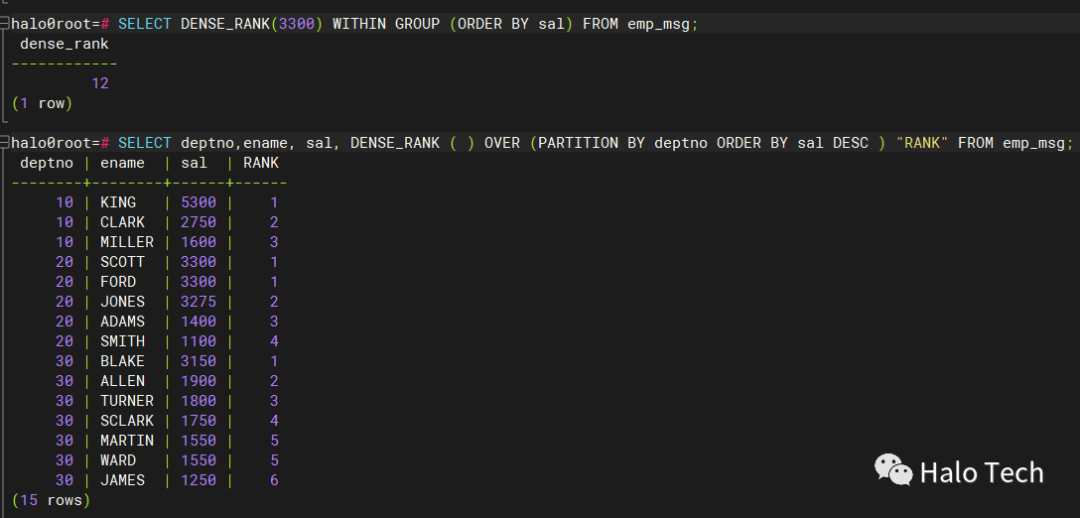
8. KEEP
语法
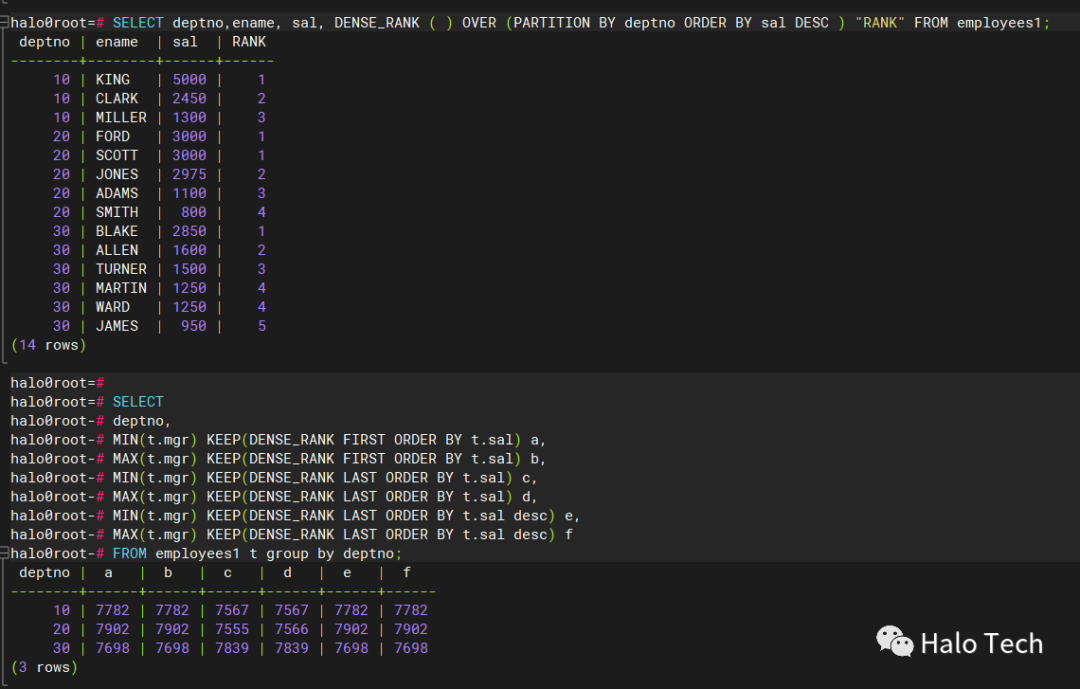
aggregate_function KEEP ( DENSE_RANK { FIRST | LAST }ORDER BY expr [ DESC | ASC ] [ NULLS { FIRST | LAST } ][, expr [ DESC | ASC ] [ NULLS { FIRST | LAST } ]]...)[ OVER ( [query_partition_clause] ) ]aggregate_function:MIN|MAX|SUM|AVG|COUNT|VARIANCE|STDDEV总结起来,`KEEP` 子句用于在聚合函数中指定保留行的条件,而 `DENSE_RANK` 是一个排序函数,用于计算结果集中每行的排名。它们是两个不同的概念和功能,但在某些情况下可以结合使用以满足特定的需求。
示例
-- supoort keep functioncreate table employees1 (empno int, ename varchar2(64), mgr int, sal int, deptno int);insert into employees1 values (7369, 'SMITH', 7902, 800, 20);insert into employees1 values (7900, 'JAMES', 7698, 950, 30);insert into employees1 values (7876, 'ADAMS', 7788, 1100, 20);insert into employees1 values (7521, 'WARD' , 7698, 1250, 30);insert into employees1 values (7654, 'MARTIN', 7698, 1250, 30);insert into employees1 values (7934, 'MILLER', 7782, 1300, 10);insert into employees1 values (7844, 'TURNER', 7698, 1500, 30);insert into employees1 values (7499, 'ALLEN', 7698, 1600, 30);insert into employees1 values (7782, 'CLARK', 7839, 2450, 10);insert into employees1 values (7698, 'BLAKE', 7839, 2850, 30);insert into employees1 values (7566, 'JONES', 7839, 2975, 20);insert into employees1 values (7788, 'SCOTT', 7566, 3000, 20);insert into employees1 values (7902, 'FORD' , 7555, 3000, 20);insert into employees1 values (7839, 'KING' , 7567, 5000, 10);SELECTdeptno,MIN(t.mgr) KEEP(DENSE_RANK FIRST ORDER BY t.sal) a,MAX(t.mgr) KEEP(DENSE_RANK FIRST ORDER BY t.sal) b,MIN(t.mgr) KEEP(DENSE_RANK LAST ORDER BY t.sal) c,MAX(t.mgr) KEEP(DENSE_RANK LAST ORDER BY t.sal) d,MIN(t.mgr) KEEP(DENSE_RANK LAST ORDER BY t.sal desc) e,MAX(t.mgr) KEEP(DENSE_RANK LAST ORDER BY t.sal desc) fFROM employees1 t group by deptno;
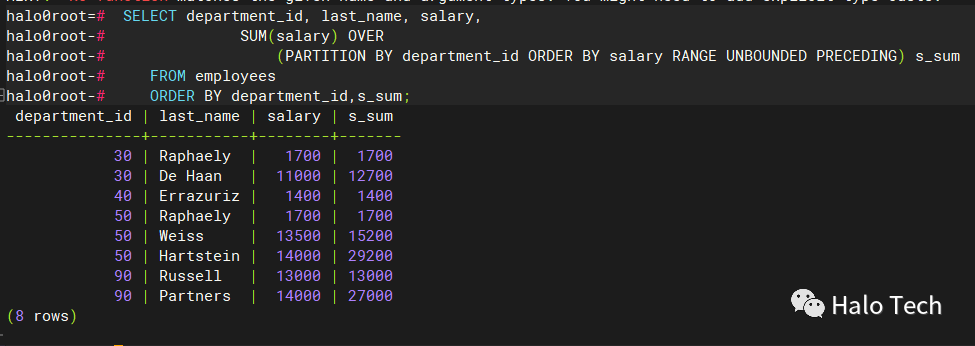
9. SUM
语法
SUM([ DISTINCT | UNQIUE | ALL ] expr) [ OVER (analytic_clause) ]
示例
SELECT department_id, last_name, salary,SUM(salary) OVER(PARTITION BY department_id ORDER BY salary RANGE UNBOUNDED PRECEDING) s_sumFROM employeesORDER BY department_id,s_sum;
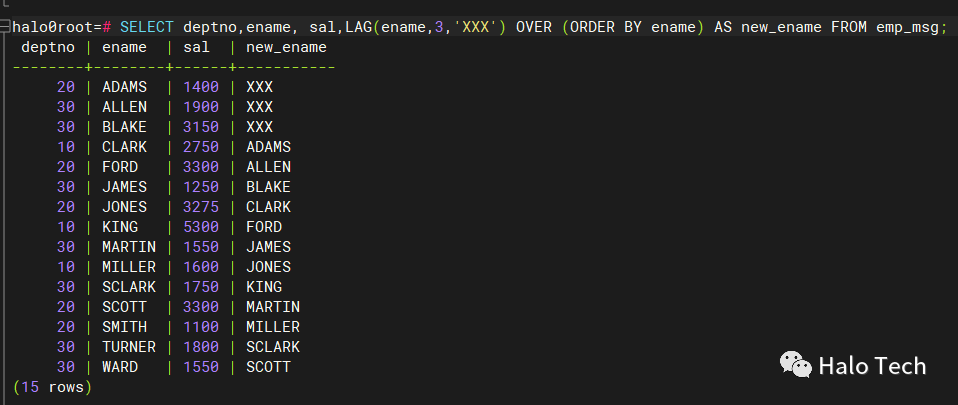
10. LAG
语法
LAG { (value_expr [,offset [,default]]) [{ RESPECT|IGNORE } NULLS ]| (value_expr [{ RESPECT|IGNORE } NULLS ] [,offset [,default] ])}OVER([query_partition_clause] order_by_clause)
示例
--emp_msg 表,将前 3 个值用 XXX 代替,从第 4 个值开始追加按 ename 字段升序排列的值SELECT department_id, last_name, salary,SUM(salary) OVER(PARTITION BY department_id ORDER BY salary RANGE UNBOUNDED PRECEDING) s_sumFROM employeesORDER BY department_id,s_sum;
11. ROLLUP
语法
SELECT ... GROUP BY ROLLUP(col_name [,col_name...])示例
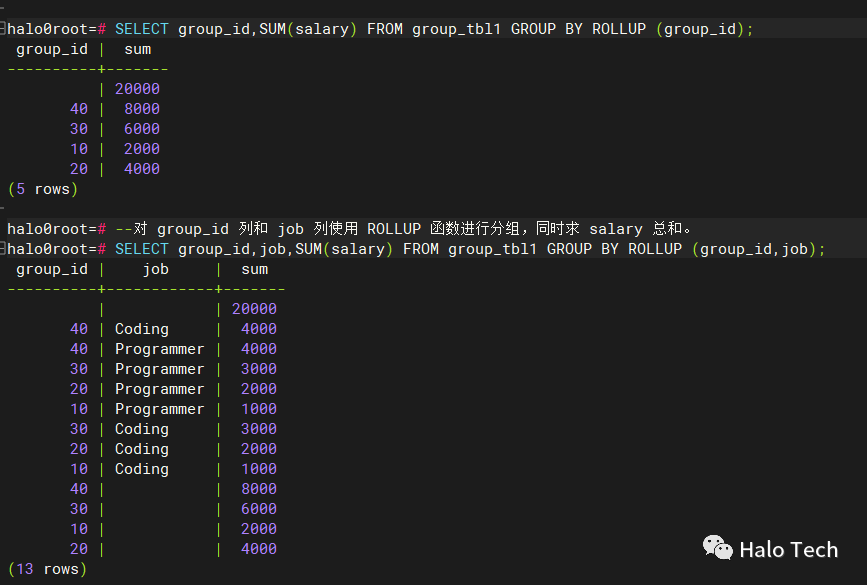
CREATE TABLE group_tbl1 (group_id INT,job VARCHAR2(10),name VARCHAR2(10),salary INT);INSERT INTO group_tbl1 VALUES (10,'Coding','Bruce',1000), (10,'Programmer','Clair',1000), (20,'Coding','Jason',2000), (20,'Programmer','Joey',2000), (30,'Coding','Rebecca',3000), (30,'Programmer','Rex',3000), (40,'Coding','Samuel',4000), (40,'Programmer','Susy',4000);SELECT * FROM group_tbl1;--对 group_id 使用 ROLLUP 函数进行分组,同时求 salary 总和。SELECT group_id,SUM(salary) FROM group_tbl1 GROUP BY ROLLUP (group_id);--对 group_id 列和 job 列使用 ROLLUP 函数进行分组,同时求 salary 总和。SELECT group_id,job,SUM(salary) FROM group_tbl1 GROUP BY ROLLUP (group_id,job);
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
