




点击上方蓝字关注我们,获取最新技术资讯
内容概述
高效稳定
经济
协同分析
深度融合
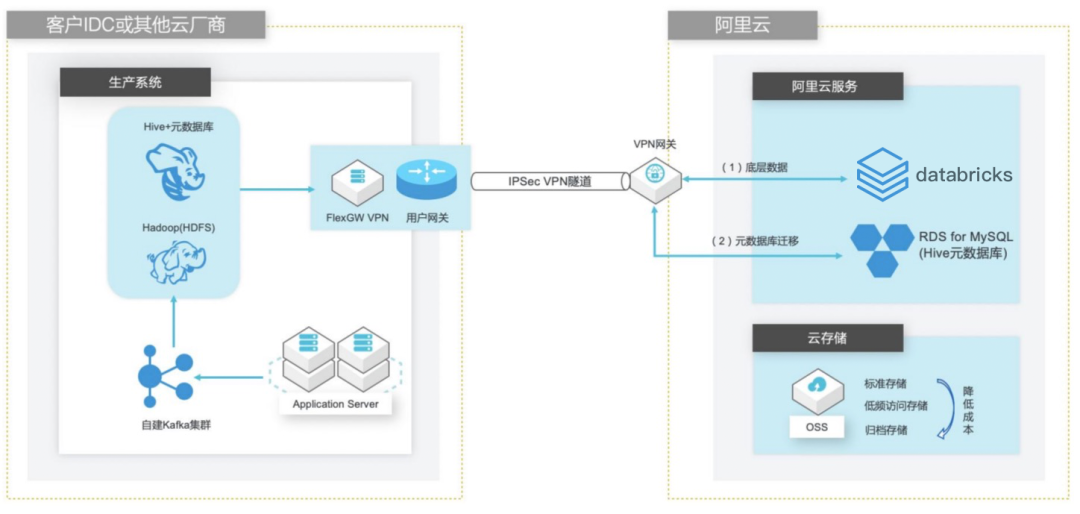
Hive 数仓数据迁移 OSS 方案。
Hive 元数据库迁移阿里云 RDS 方案。
Hive 跨版本迁移到 Databricks 数据洞察使用 Delta 表查询以提高查询效率。
内容节选

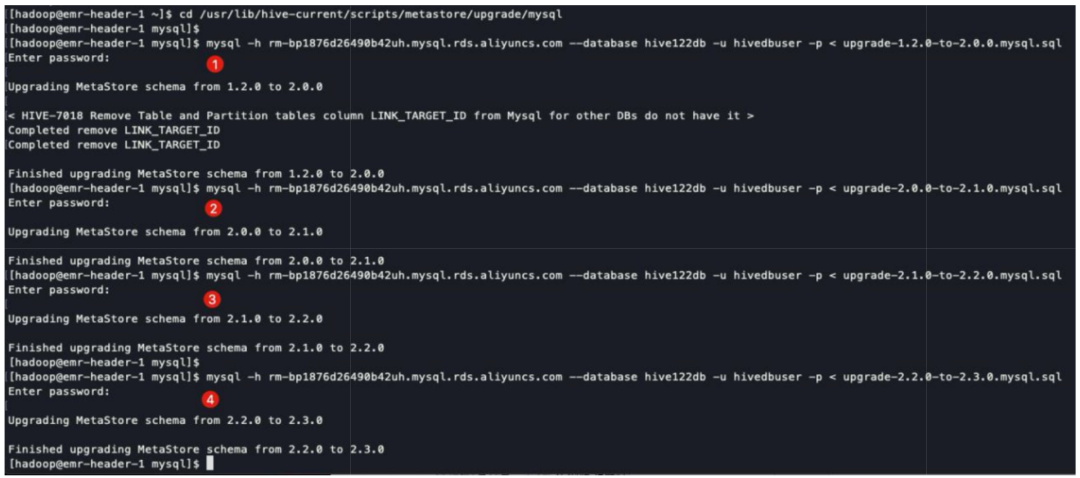
su - hadoopcd $HIVE_HOME/scripts/metastore/upgrade/mysqlls -l upgrade*.sql
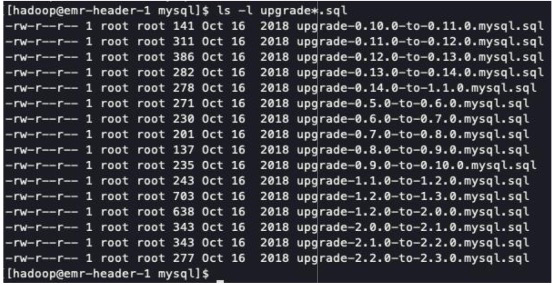
upgrade-1.2.0-to-2.0.0.mysql.sqlupgrade-2.0.0-to-2.1.0.mysql.sqlupgrade-2.1.0-to-2.2.0.mysql.sqlupgrade-2.2.0-to-2.3.0.mysql.sql

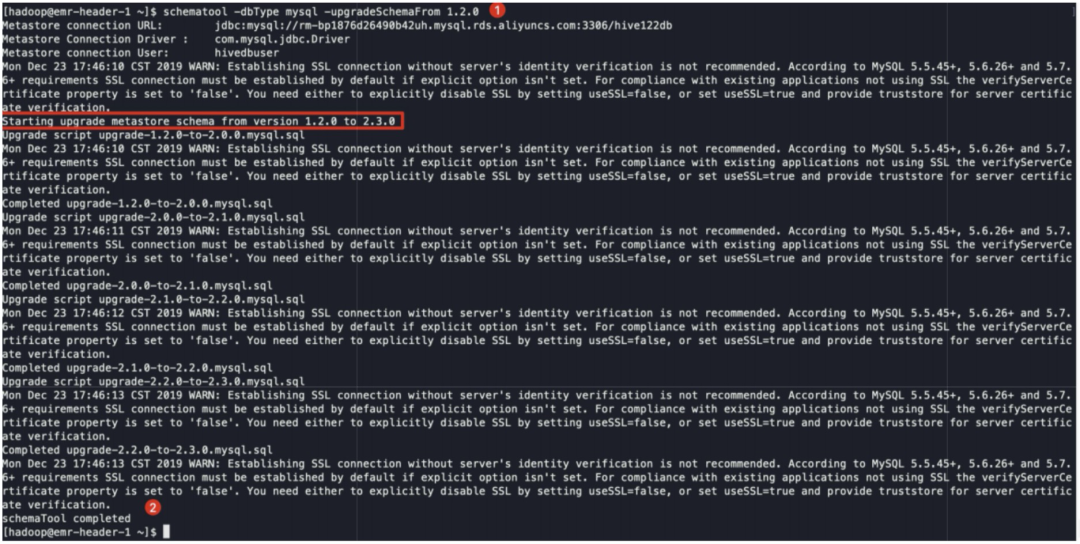
su - hadoopschematool -dbType mysql -upgradeSchemaFrom 1.2.0
su - hadoopvim $HIVE_CONF_DIR/hive-env.sh
总结
Databricks 数据洞察产品内核使用 Databricks 商业版的 Runtime 和 DeltaLake 较之前使用开源 Spark 做数据分析在性能上有3-5倍的提升,机器资源相比自建多了3倍。
全托管的 Spark 集群免去运维人力成本,免去性能调优(运维1人+大数据1人)。
使用 oss 对象存储方案,计算存储分离节省客户存储成本,并为以后数据湖和多计算框架做铺垫。
推荐客户将数据格式存储为 Parquet ,性能会有非常大优化。
Databricks 数据洞察与阿里云其它产品( Kafka 、Redis 、MongoDB 、Elasticseach 、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为 Spark 计算引擎的输入源或者输出目的地。
END

文章转载自Apache Spark技术交流社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
