X-Engine是什么
X-Engine是阿里自研的数据库存储引擎,可以作为MySQL的存储引擎使用,兼容MySQL的功能,目前已经广泛应用在阿里集团内部诸多业务系统中。只需要在配置中将默认存储引擎设置为X-Engine,在后续过程中所有创建的表就可以使用了,当然也可以在创建表时指定存储引擎,这样只有指定的表才会使用X-Engine.
那么问题来了,为什么要使用X-Engine?
作为存储引擎的特点
X-Engine是阿里内部生长出来的,一开始,也是为应对阿里内部业务带来的挑战,早在2010年,阿里内部就大规模部署了MySQL数据库,但是业务量的逐年爆炸式增长,对数据库提出了严苛的要求,一是极高的并发事务处理能力,尤其是双十一的流量突发式暴增;二是数据规模超大,需要占用大量存储资源。这两个问题当然都可以扩展数据库节点的分布式方案解决,不过堆机器不是一个高效的手段,我们更想用技术的手段来将单机的数据库性价比提升到极致,达到以少量资源换取性能大幅上升的目的。
传统数据库架构下的性能已经被仔细的研究过,数据库领域的泰斗,图灵奖得主Michael Stonebreaker就此写过一篇论文<OLTP Through the Looking Glass, and What We Found There>,分析指出传统关系通用型数据库,仅仅有不到百分之十左右的时间是在做真正有效的处理数据工作。剩下百分之九十多的时间都浪费在其它工作上,比如一些加锁等待,缓冲管理,日志同步等。
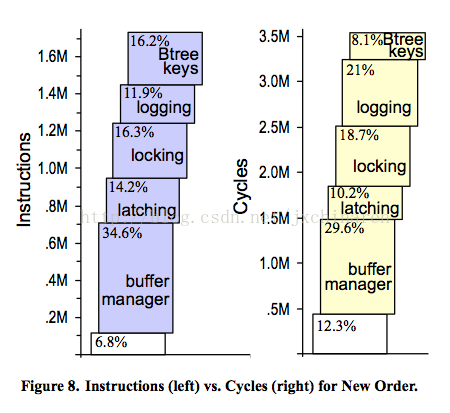
造成这种现象的原因是近些年来,我们所依赖的硬件体系发生了巨大的变化:多核(众核)CPU,新的处理器架构(Cache/NUMA),各种异构计算设备(GPU/FPGA),越来越大,越来越便宜的内存,越来越快的存储设备(SSD/3D-XPoint/NVRAM)… 而架构在这之上的数据库软件栈却没有太大xxxx的改变,一切都是为了慢速磁盘而设计,使用B-Tree索引的固定大小的数据页(Page),使用ARIES算法的事务处理与数据恢复机制,基于独立锁管理器的并发控制… 这一切在现有的体系架构上,很难发挥出硬件应有的性能,大量的cpu cycles被浪费在等锁等无效操作上了,这些问题在小规模体量的数据上还不太明显,一旦吞吐和数据量上来,就成为瓶颈了。
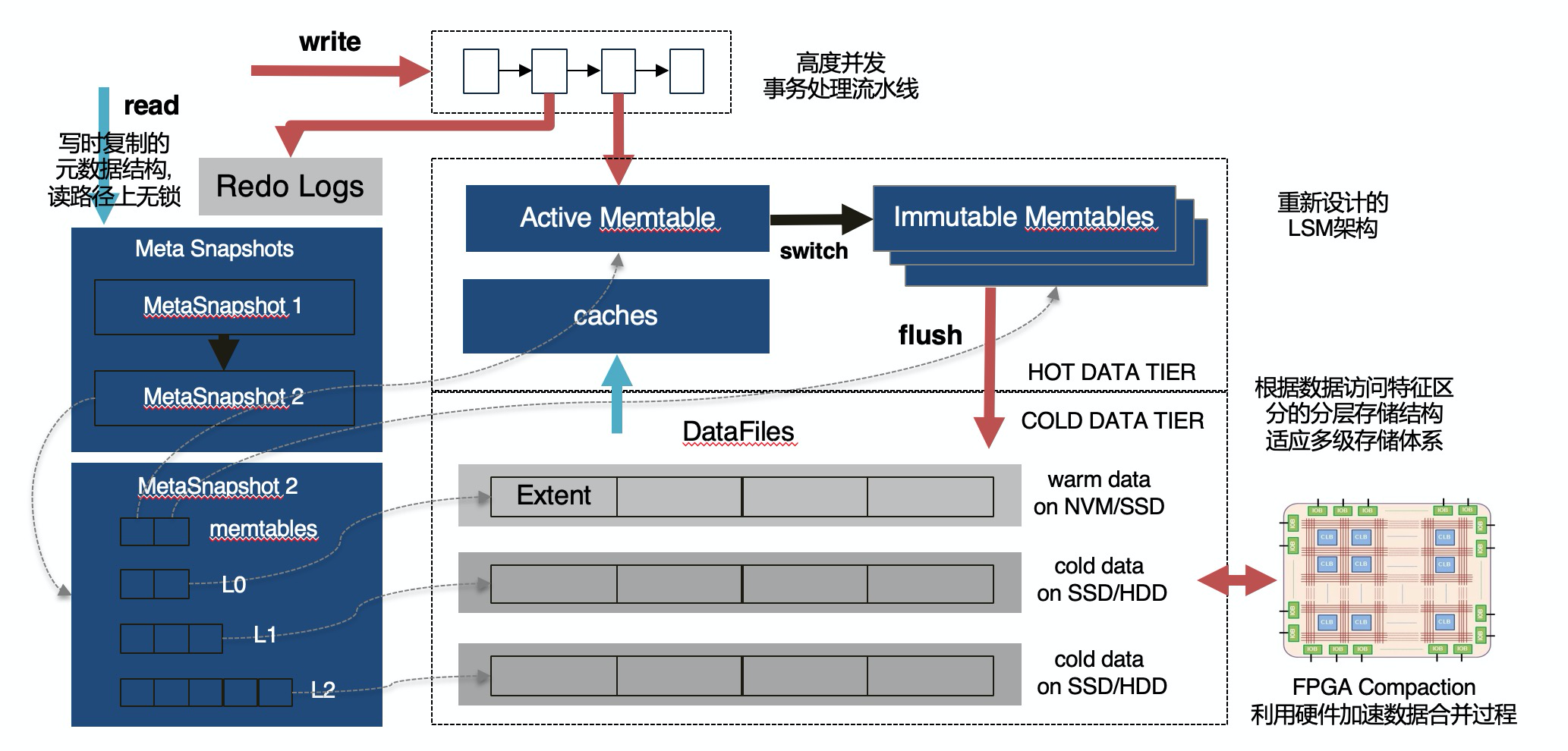
架构设计
为此我们设计了全新架构的存储引擎X-Engine,得益于MySQL Pluginable Storage Engine的特性,X-Engine可以无缝对接兼容MySQL特性,我们只需要专注优化存储结构就好。X-Engine使用了一种对数据进行分层的存储架构,(如下图) 因为目标是面向大规模的海量数据存储,提供高并发事务处理能力和尽可能降低成本,我们观察到,大部分大数据量场景下,数据被访问的机会是不均等的,访问频繁的热数据实际上占比很少,X-Engine根据数据访问频度(冷热)的不同将数据划分为多个层次,针对每个层次数据的访问特点,设计对应的存储结构,写入合适的存储设备。X-Engine使用了LSM-Tree作为分层存储的架构基础,并在这之上进行了重新设计。简单来讲,热数据层和数据更新使用内存存储,利用了大量内存数据库的技术(Lock-Free index structure/append only)提高事务处理的性能,我们设计了一套事务处理流水线处理机制,把事务处理的几个阶段并行起来,极大提升了吞吐。而访问频度低的冷(温)数据逐渐淘汰或是合并到持久化的存储层次中,结合当前丰富的存储设备层次体系(NVM/SSD/HDD)进行存储。我们对性能影响比较大的compaction过程做了大量优化,主要是拆分数据存储粒度,利用数据更新热点较为集中的特征,尽可能的在合并过程中复用数据,精细化控制LSM的形状,减少I/O和计算代价,并同时极大的减少了合并过程中的空间放大。同时使用更细粒度的访问控制和缓存机制,优化读的性能。