




技术特点
X-Engine基于LSM-Tree架构设计,主要是为了利用其天然分层的结构,同时为了避免LSM固有的一些劣势,对整个存储架构做了根本性的调整和优化,比如 :
- 使用多事务处理队列和流水线处理技术,减少线程上下文切换代价,并计算每个阶段任务量配比,使整个流水线充分流转,极大提升事务处理性能,相对于其他类似架构的存储引擎比如RocksDB,X-Engine的事务处理性能有10倍以上提升。
- X-Engine使用的copy-on-write技术,避免原地更新数据页,从而对只读数据页面进行编码压缩,相对于传统存储引擎(比如InnoDB)数据压缩2倍以上。
- 数据复用技术减少数据合并代价,并且因为数据复用减少缓存淘汰带来的性能抖动。进一步利用FPGA硬件加速compaction过程,使得系统上限进一步提升。
- Bloom Filter 快速判定数据是否存在, Surf Filter判断范围数据是否存在, Row Cache缓存热点行,加速读取性能。
我们将X-Engine的架构和优化技术总结成论文<X-Engine: An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing>,发表在了数据库最顶尖的会议SIGMOD’19。
以下章节逐一介绍X-Engine的优化架构和实现细节。既然是基于LSM架构设计,首先简要介绍下LSM架构的一些特点。
背景知识:LSM基本逻辑
一条数据在LSM结构中的旅程,从写入WAL(Write Ahead Log)开始,然后进入MemTable,这是Ta整个生命周期的第一处落脚点。随后,flush操作将Ta刻在更稳固的介质上,compaction操作将Ta带往更深远的去处,或是在途中丢弃,取决于Ta的继任者何时到来。
LSM的本质是,所有写入操作并不做原地更新,而是以追加的方式写入内存。每次写到一定程度,即冻结为一层(Level),写入持久化存储。所有写入的行,都以主键(Key)排序好后存放,无论是在内存中,还是持久化存储中。在内存中即为一个排序的内存数据结构(Skiplist, B-Tree, etc.),在持久化存储也作为一个只读的全排序持久化存储结构。
普通的存储系统若要支持事务处理,尤其是ACI,需要加入一个时间维度,借此为每个事务构造出一个不受并发干扰的独立视域。存储引擎会对每个事务定序并赋予一个全局单调递增的事务版本号(SN),每个事务中的记录会存储这个SN以判断独立事务之间的可见性,从而实现事务的隔离机制。
如果LSM存储结构持续写入,不做其他的动作,那么最终会成为如下结构:
注意这里每一层的SN范围标识了事务写入的先后顺序,已经持久化的数据不再会被修改。每一层数据按Key排序,层与层之间的Key range会交叠。
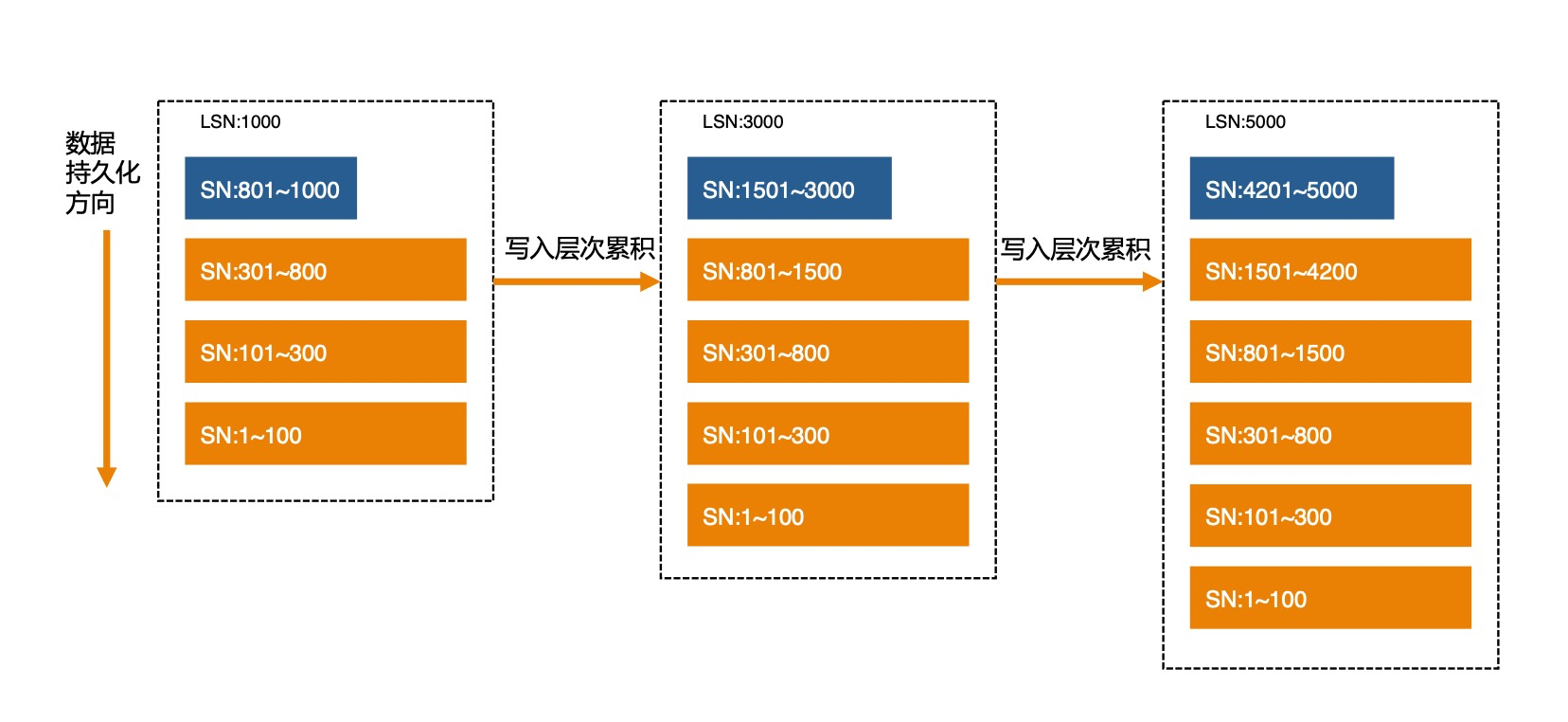
这种结构对于写入是非常友好的,只要追加到最新的内存表中即完成,为实现crash recovery,只需记录WAL(Redo Log),因为新数据不会覆盖旧版本,追加记录会形成天然的多版本结构。
可以想见,如此累积冻结的持久化层次越来越多,会对查询会产生不利的影响,对同一个key不同事务提交产生的多版本记录会散落在各个层次中,不同的key也会散落在不同层次中,读操作诸如顺序扫描便需要查找各个层并合并产生最终结果。
LSM引入了一个compaction的操作解决这个问题,这个操作不断的把相邻层次的数据合并,并写入这个更低层次。而合并的过程实际上就是把要合并的相邻两层(或是多层)数据读出来,按key排序,相同的key如果有多个版本,只保留新(比当前正在执行的活跃事务中最小版本号新)的版本,丢掉旧版本数据,然后写入新的层。可以想见这个操作非常耗费资源。
LSM compaction操作,有几种作用,一是为了丢弃不再被使用的旧版本数据,二是为了控制LSM层次形状,一般的LSM形状都是层次越低,数据量越大(倍数关系),这样放置的目的主要是为了提升读性能。
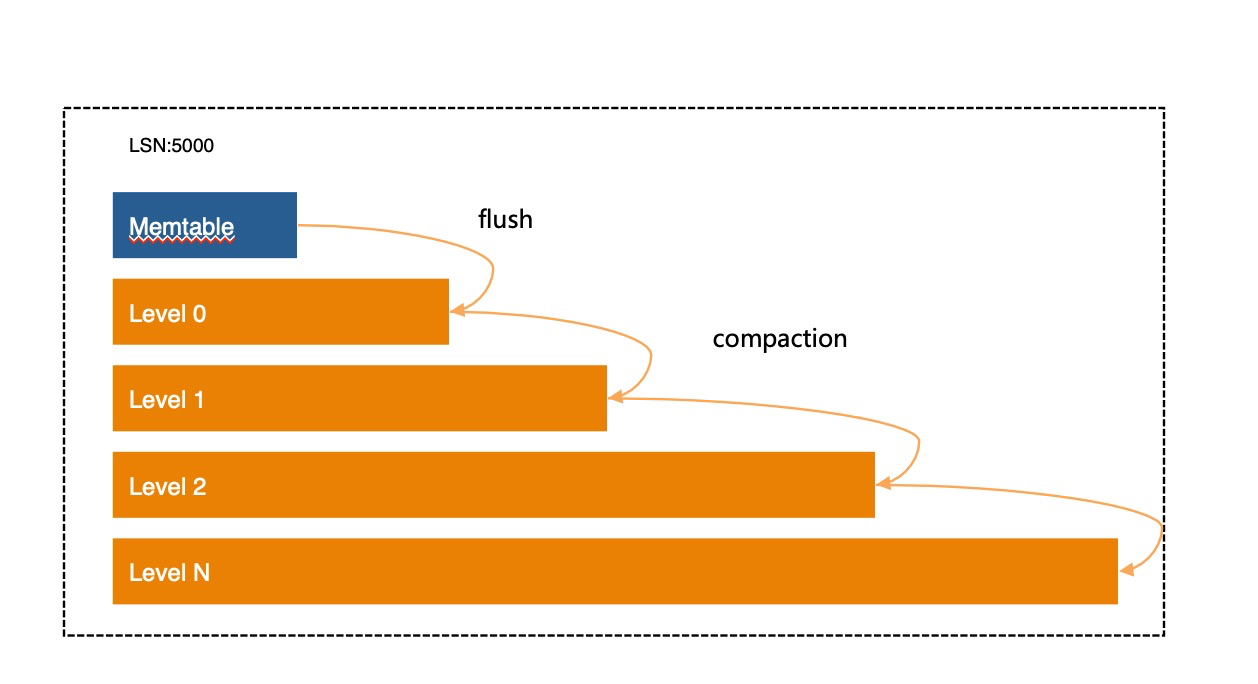
一般来讲,任何存储系统的数据访问都有局部性,大量的访问都集中在少部分数据上,这也是缓存系统能有效工作的基本前提,在LSM存储结构中,如果我们把访问频率高的数据尽可能放在较高的层次上,保持这部分数据量规模,可以存放在快速存储设备中(比如NVM,DRAM),而把访问频率低的数据放在较低层次中,使用廉价慢速存储设备存储。这就是X-Engine的根据冷热分层概念。
要达到这种效果,核心问题是如何挑选合适的数据合并到更低的层次,这是compaction调度策略首先要解决的问题,根据冷热分层的逻辑,就是优先合并冷数据(访问频率相对低)。识别冷数据有很多方法,对于不同的业务不尽然相同,对于很多流水型业务(如交易,日志系统),新近写入的数据会有更多的概率被读到,冷热按写入时间顺序即可区分,也有很多应用的访问特征跟写入的时间不一定有关系,这个就要根据实际的访问频率去识别冷数据或是热数据。
除了数据热度以外,挑选合并数据还有其他一些维度,会对读性能产生影响,比如数据的更新频率,大量的多版本数据在查询的时候会浪费更多的I/O和CPU,因此需要优先进行合并以减少记录的版本数量,X-Engine综合考虑了各种策略形成自己的compaction调度机制。
