




一:TiDB介绍
一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容(数据副本通过 Multi-Raft 协议同步事务日志)、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
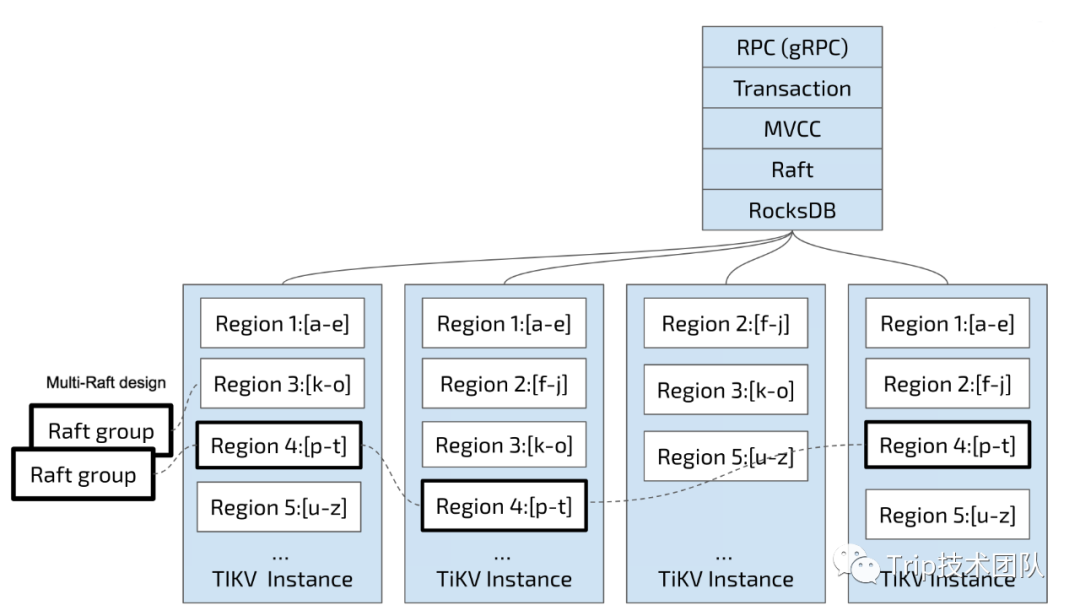
1:整体架构如下:

2:TiKV
一个可持久化的Map,负责存储数据,从外部看TiKV是一个分布式的提供事务的Key-Value存储引擎,单机的本地存储是依赖的RocksDB,也就是说具体的数据落地是由RocksDB来完成的。存储数据的基本单位是Region,每个Region负责存储一个Key Range(从StartKey 到EndKey 的左闭右开区间)的数据,每个 TiKV节点会负责多个Region。
TiKV和RocksDB的关系

Region
数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面(暂不考虑多副本)。TiDB 系统会有一个组件(PD,PD还负责授时单时间源单点授时)来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的 Region 调度过来),另一方面也实现了负载均衡。
单个Region,有多个副本Replica,通过Raft保持一致,它们会在不同的节点上,构成一个Raft Group。
有了MVCC后Region中的,Region的Key-Value是这样的:
Key1_Version3 -> ValueKey1_Version2 -> ValueKey1_Version1 -> Value……Key2_Version4 -> ValueKey2_Version3 -> ValueKey2_Version2 -> ValueKey2_Version1 -> Value……KeyN_Version2 -> ValueKeyN_Version1 -> Value……
二:RocksDB简介
RocksDB由Facebook基于LevelDB开发的存储引擎,由C++开发的,但是提供了RocksDBJava供Java系统调用。它在KV存储引擎中有着举足轻重的地位,上述TiKV是直接使用其作为存储引擎,美图、携程基于它开发了KVRocks以及TRocks,试图在绝大多数场景中替代Redis以节省内存和获得持久化的功能。这里对它做简单介绍。
1:它的ReadMe
RocksDB是由Fackbook数据库团队开发和维护的,用于Flash和Ram的一种KV存储引擎,它基于早期的LevelDB。LevelDB是由 Sanjay Ghemawat (sanjay@google.com)和Jeff Dean (jeff@google.com)二位贡献的。RocksDB性能高,并且针对Flash进行了优化。RocksDB采用了LSM结构,在写放大(WAF)、读放大(RAF)和空间放大(SAF)上做了灵活的权衡。RocksDB采用了多线程合并,使得它能够在单实例下处理上TB的数据。
2:相比于LevelDB的一些改进
Multithread compaction
Multithread memtable inserts
Reduced DB mutex holding
Optimized level-based compaction style and universal compaction style
Prefix bloom filter
Single bloom filter covering the whole SST (Sorted String Table) file
Write lock optimization
Improved Iter::Prev() performance
Fewer comparator calls during SkipList searches
Allocate memtable memory using huge page.
总的来看,改进主要是三个方面:
多线程、并发优化
SST结构优化
算法优化(主要是跳表算法)
三:LevelDB结构、读写流程梳理
1:LevelDB介绍和一些学习感受
LevelDB是谷歌开发的一个高性能的KV存储库,特性如下:
Keys和Values都是任意的字节数组
数据是Key有序的
可以由使用者自定义比较器,用于排序
支持批量写入的原子操作
支持快照读
支持前后双向遍历数据
支持数据压缩 LevelDB支持的特性都是比较朴素,基础的,事实上它的代码量也仅仅只有万行,但是并不意味它粗糙,低性能。它的LSM设计对大批量写入非常友好;跳表实现、Bloom过滤器实现、以及灵活精巧的LRU缓存设计使得它也有不凡的读性能;数字的变长码存储、对有序Key的差分增量编码、以及Snappy压缩,使得它对磁盘空间有着极致的利用率。总而言之,LevelDB小巧精致使用,便于阅读学习,同时它又是RocksDB、HBase、MyRocks、TiDB的基石。
2:LevelDB的主要结构

LevelDB没有提供网络通信的组件,需要自己实现。
内存中:
Memtable
内存表,主要数据结构是跳表,源码中有完整实现。Memtable是可读可写的,表中存放了有序的KeyValue对。默认设置大小4MB。
Imutable
不可变表,结构和Memtable一样,但是只可读不可写。Memtable表超过4MB、并且后台没有合并操作、L0文件数小于L0文件最大数时会将当前Memtable指向Imutable,并且构造新的Memtable、更新新的Log文件,尝试触发Compact。
TableCache和BlockCache
LevelDB中缓存由两个维度一个是SSTable的元信息,比如文件号、访问文件的API、文件中最大最小key、BloomFilter、Block所以等;另一个是SSTable中的DataBlock,即具体存放数据的Block。这样两个维度的缓存,可以高效利用内存空间,为什么这样说?TableCache只缓存SSTable的元数据,占用空间少,但是可以缓存更多的文件进来,这些缓存的元数据可以高效判断所查询的Key在不在当前文件中;BlockCache缓存具体的数据,DataBlock是LevelDB存储数据最小的单元,它的空间占用也很少,这样避免了将整个SSTable都缓存进来,也就是说降低了热点的粒度,不会将热点附近的Key(在同一个SSTable中),但是又不热点的数据缓存进来。
磁盘中:
SSTable(Sorted String Table)
最早是谷歌BigTable中提出来的,是一种比较高效的有序键值对磁盘存储方式。其特点是:存储键值对、数据长度随机,键值可以重复,无需对齐,随机读取比较高效;其缺点是:不可变,不适合随机读写。LevelDB完整实现了SSTable、可以完整的了解其文件结构、编码方式等技术细节。
Log
LevelDB实现了WAL,在写入时,首先顺序写入Log到磁盘中,然后才会写Memtable表。
Manifest
Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息。
Current
LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名。
3. LevelDB读写流程梳理
LevelDB支持并发写入,快照读,对于二次开发很方便实现事务隔离和MVCC。
写流程
LevelDB提供了如下三个接口写DB,其中put和delete都会被包装成write进行批量写入
// Implementations of the DB interfaceStatus Put(const WriteOptions&, const Slice& key, const Slice& value) override;Status Delete(const WriteOptions&, const Slice& key) override;Status Write(const WriteOptions& options, WriteBatch* updates) override;Status Get(const ReadOptions& options, const Slice& key, std::string*value) override;
关于删除 LevelDB实现删除的方式是,追加一条删除的记录,并不会立刻删除,而是在MajorCompact中删除。LevelDB中的Key被定义成InternalKey是如下形式:

所以通过InternalKey可以得到三个信息:UserKey,版本号,操作类型。
WriteBatch机制 LevelDB将单个操作包装成批量操作,并将操作合并进行批量写,以此提升写入性能。WriteBatch的数据结构如下:
| 8Byte | 4Byte | 1Byte | Var | Var | Var | Var |
|---|---|---|---|---|---|---|
| 批次中第一条数据的序列号 | 批次中的数量 | Value类型 | Key长度 | Key | Value长度 | Value |
这Key Value的长度都是变长码,以此节省内存空间。
Writer机制 LevelDB支持并发写入,采用的模型类似生产消费的模型,即多个写入线程生产数据,往一个队列里写入,选择队列头部的线程做操作合并和写入,其它线程挂起等待。

写入流程
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {Writer w(&mutex_);w.batch = updates;w.sync = options.sync;w.done = false;MutexLock l(&mutex_);writers_.push_back(&w);while (!w.done && &w != writers_.front()) {w.cv.Wait();}if (w.done) {return w.status;}// May temporarily unlock and wait.Status status = MakeRoomForWrite(updates == nullptr);uint64_t last_sequence = versions_->LastSequence();Writer* last_writer = &w;if (status.ok() && updates != nullptr) { // nullptr batch is for compactionsWriteBatch* write_batch = BuildBatchGroup(&last_writer);WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);last_sequence += WriteBatchInternal::Count(write_batch);// Add to log and apply to memtable. We can release the lock// during this phase since &w is currently responsible for logging// and protects against concurrent loggers and concurrent writes// into mem_.{mutex_.Unlock();status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));bool sync_error = false;if (status.ok() && options.sync) {status = logfile_->Sync();if (!status.ok()) {sync_error = true;}}if (status.ok()) {status = WriteBatchInternal::InsertInto(write_batch, mem_);}mutex_.Lock();if (sync_error) {// The state of the log file is indeterminate: the log record we// just added may or may not show up when the DB is re-opened.// So we force the DB into a mode where all future writes fail.RecordBackgroundError(status);}}if (write_batch == tmp_batch_) tmp_batch_->Clear();versions_->SetLastSequence(last_sequence);}while (true) {Writer* ready = writers_.front();writers_.pop_front();if (ready != &w) {ready->status = status;ready->done = true;ready->cv.Signal();}if (ready == last_writer) break;}// Notify new head of write queueif (!writers_.empty()) {writers_.front()->cv.Signal();}return status;}
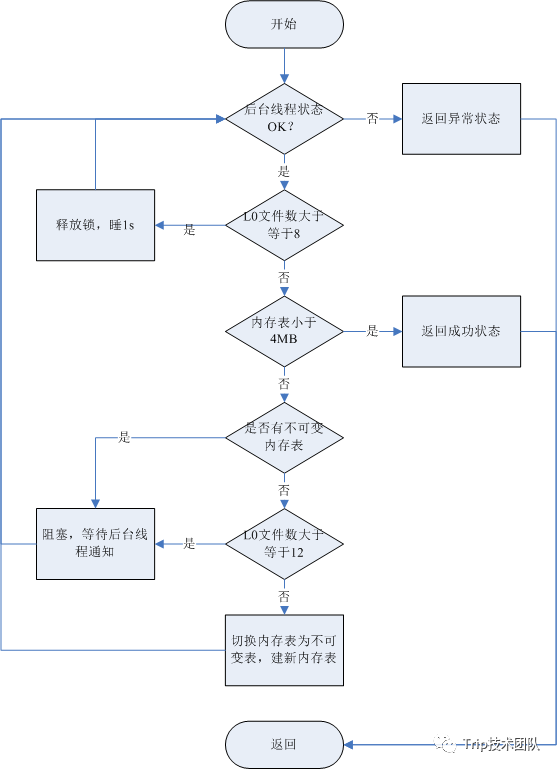
写入控制 LevelDB写入时,需要根据内部状态判断是否需要阻塞,并且触发后台Companion,这里给出makeRoomForWrite流程图:
读流程
LevelDB读时,读取流程为:Memtable、ImuTable、Cache、SSTable,SSTable会从第1层开始,一直查询到最后一层。
读取流程
Status DBImpl::Get(const ReadOptions& options, const Slice& key,std::string* value) {Status s;MutexLock l(&mutex_);SequenceNumber snapshot;if (options.snapshot != nullptr) {snapshot =static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number();} else {snapshot = versions_->LastSequence();}MemTable* mem = mem_;MemTable* imm = imm_;Version* current = versions_->current();mem->Ref();if (imm != nullptr) imm->Ref();current->Ref();bool have_stat_update = false;Version::GetStats stats;// Unlock while reading from files and memtables{mutex_.Unlock();// First look in the memtable, then in the immutable memtable (if any).LookupKey lkey(key, snapshot);if (mem->Get(lkey, value, &s)) {// Done} else if (imm != nullptr && imm->Get(lkey, value, &s)) {// Done} else {s = current->Get(options, lkey, value, &stats);have_stat_update = true;}mutex_.Lock();}if (have_stat_update && current->UpdateStats(stats)) {MaybeScheduleCompaction();}mem->Unref();if (imm != nullptr) imm->Unref();current->Unref();return s;}
总结
本文简单介绍了TiDB、TiKV、RocksDB等比较常用的数据库、KV存储引擎,相对比较详细的介绍了LevelDB框架结构,主要读写流程。虽然LevelDB是比较早期的半成品,但是它小巧精炼,性能不凡,诸如:对Key值的增量差分编码、变长码、灵活的二级缓存、BloomFilter的实现、Snappy压缩算法的使用等技术,奠定了后续RocksDB、HBase、TiKV的发展和应用,对它的深入学习,有助于对现代KV存储系统乃至分布式数据库的深入理解。
参考文档
https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
https://github.com/google/leveldb/blob/master/README.md
https://github.com/ralgond/jleveldb
https://zhuanlan.zhihu.com/p/80684560
作者介绍
Daniel ,携程资深后端开发工程师,关注Golang、Rust等新兴语言、KV存储引擎、无锁数据结构等领域。
团队招聘信息
我们是Trip.com国际事业部研发团队,主要负责集团国际化业务在全球的云原生化开发和部署,直面业界最前沿的技术挑战,致力于引领集团技术创新,赋能国际业务增长,带来更极致的用户体验。
团队怀有前瞻的技术视野,积极拥抱开源建设,紧跟业界技术趋势,在这里有浓厚的技术氛围,你可以和团队成员一同参与开源建设,深入探索和交流技术原理,也有技术实施的广阔场景。
我们长期招聘有志于技术成长、对技术怀有热忱的同学,如果你热爱技术,无惧技术挑战,渴望更大的技术进步,Trip.com国际事业部期待与您的相遇。
目前我们后端/前端/测试开发/安卓,岗位都在火热招聘。简历投递邮箱:tech@trip.com,邮件标题:【姓名】-【携程国际业务研发部】- 【投递职位】
