前言
5 月初,我写过一篇介绍 AI 原生应用技术栈的文章:一次性把“AI 原生应用技术栈”说明白,超过 12000+阅读,看起来大家对这块的技术非常有兴趣。
下面这个图就是当时介绍的技术栈,主要 PaaS 这块是 6 大块组成,包括大模型,Model Builder,向量数据库,Agent Builder,App Builder,Agent Store这 6 部分组成。大家可以先翻一翻前面的文章回忆一下。
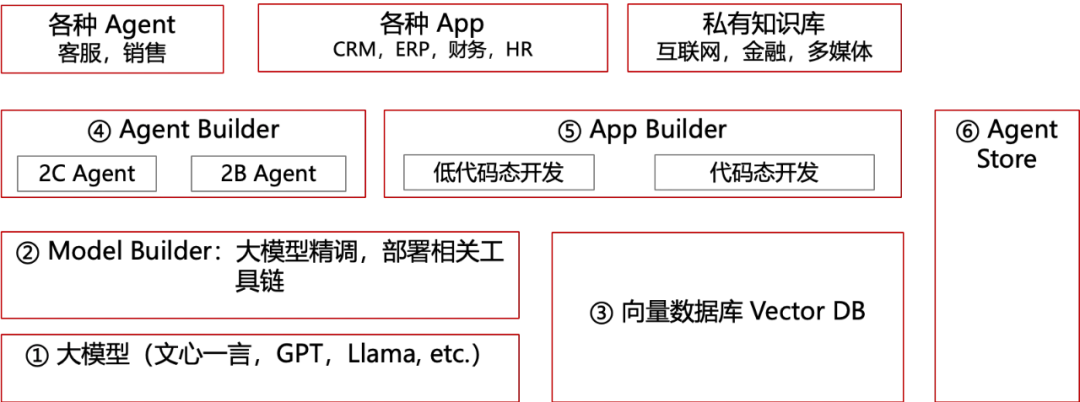
这块的技术发展还是非常快的,越来越多的新东西增加,才不到 3 个月,我就要更新这个技术栈了。
最新的技术栈
按惯例,先上最新技术栈:
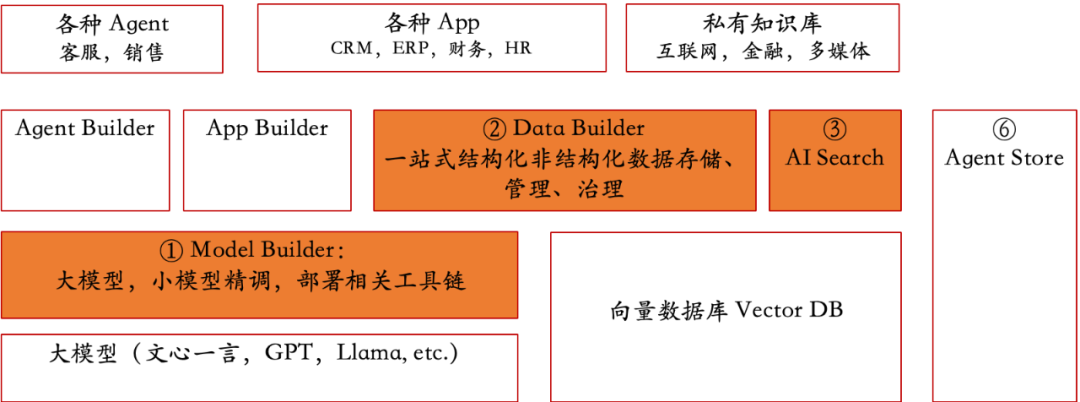
标红部分就是这次调整的点,可以看到最新的技术栈变化还是挺大的,也反映了这个领域的技术发展新趋势。接下来还是一个个介绍下主要变化的点以及背后的原因,相信对关心或者正在规划这块技术的同学有帮助。
① 首先是 Model Builder or ML platform
Model Builder 刚出来大家都会定位为围绕大模型精调,部署相关工具链。
为 AI 准备工具链并不是大模型特有,传统小模型就有相关工具链,比如阿里云的 PAI,腾讯云的 TI 平台,华为的 Model Arts,百度智能云的 BML等等。这块的工作主要是 ML Ops,提供模型开发、训练、推理端到端工具链。

随着场景的深入,大家会发现小模型,大模型有很大的结合空间:
首先客户场景上,大模型和小模型有结合的空间,比如大模型的文本能力和小模型的 OCR 识别是最常见的结合。
其次技术上会有,在数据准备,标准,评估等流程上也有一定的相似处。
所以一个融合的平台,同时服务于大模型和小模型。
② Data Builder:一站式结构化,非结构化数据存储,管理和治理平台。
随着大数据场景的深入,大家发现大模型还是有非常的多的缺陷的,包括数据不能更新,幻觉等问题。尤其是在 2B 场景里面,和企业的数据无法结合,无法产生真正的企业智能,应用于企业业务。
databricks 在这块就提出了要从通用智能走向数据智能的理念:(参考:大模型时代最懂数据的公司 databricks)
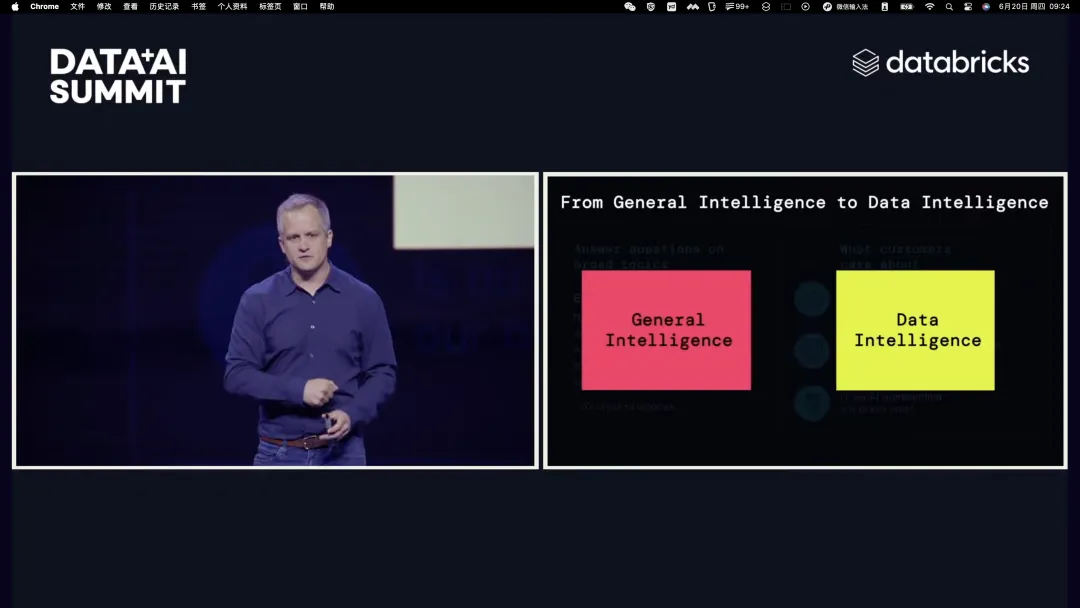
最近业界对这块也有深入的讨论,主要观点如:“数据杂乱、用户意图明确时的低命中率,以及用户意图不明确时的语义 gap,是阻碍 RAG 技术走向更多企业、让企业愿意为之付费的主要瓶颈。”
也有一些创业公司,如unstructured专门解决数据处理的问题等。
所以在大模型 AI 原生应用技术栈里面,有一个位置是留给能统一处理结构化数据,以及非结构化数据存储,管理和治理的平台。(类似①说的统一处理大模型和小模型的平台)
目前看来,Databricks 走在了前列,Databricks提得统一格式,统一元数据,开放的引擎数据湖范式是最有前途的标准架构。
③ AI Search
AI Search这个在 2C 领域有不少创业公司,随着大模型技术最先火起来的应用之一就包含plerplexity。还有很多创业公司比如ThinkAny等等。
这是 2C 领域,在传统企业搜索领域,大家也在想怎么去更智能的构建类似的技术和产品。这个就是AI Search。
微软应该是最先意识到这个领域,推出Azure AI search,这个服务也是在原来认知搜索的基础上发展而来,相当于是小模型技术演进到大模型技术。
从技术角度,这个是包含了 RAG,向量数据库,机器学习排序等等技术。下图是一个典型的 AI Search的产品逻辑图:
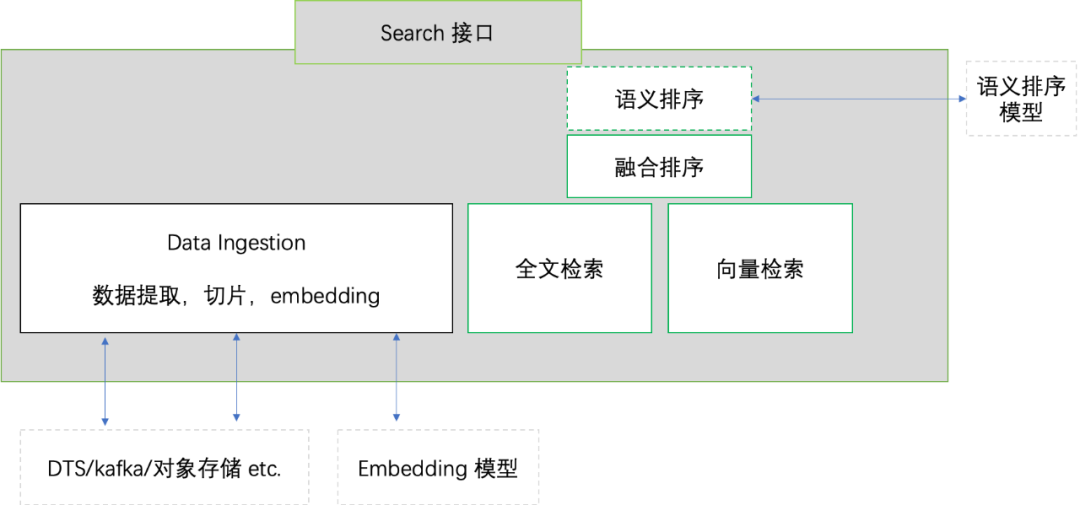
处理的数据包括结构化(如数据库),非结构化(对象存储,文件等)
提供全文索引和向量索引
结果支持融合排序和语义排序的能力。
好了,今天对 AI 原始技术栈的更新部分就简单介绍这些。
大模型如火如荼,相关技术日新月异,祝愿大家都:
Good Good Study,Day Day Up!
-----------------
欢迎加本作者微信交流,加微信请先自我介绍下!