




旧闻
2024年4月,据报道,谷歌为了削减成本,将整个美国Python团队的不到10名成员全部解雇,作为将工作外包给更便宜的劳动力市场的策略的一部分。该团队负责管理谷歌的大部分Python生态系统,包括:
• 维护Python的稳定版本
• 更新数千个第三方包
• 开发类型检查器
这件事和下面我要说的事情是否有关系呢? 我也说不清楚,这个就需要各位看官自行判断了。
我一直在寻找比file
命令更好用的解决方案,今天偶然发现了一篇Google开源博客上的一篇文章Magika:AI 驱动的快速高效的文件类型识别 [1],让我有种找到了宝的感觉。
开始介绍Magika之前,让我们先介绍下file
命令。
file命令
如果你是Windows用户,这里需要科普下file
命令
file 命令是一个常见的Unix/Linux命令,用于确定文件的类型。它通过检查文件的内容而不是扩展名来判断文件的类型。
Magika
2024年2月15日,Google开源了AI 驱动的快速高效的文件类型识别 Python 库, Magika
Magika 是一种新的基于人工智能的文件类型检测器。Magika 内部使用的是一个定制的、高度优化的深度学习模型,由 Keras 设计并训练,其大小仅约为 1MB。在推理时,Magika 使用 Onnx 作为推理引擎,以确保文件在几毫秒内被识别,即使在 CPU 上也几乎与非人工智能工具一样快。
并附上了对比图
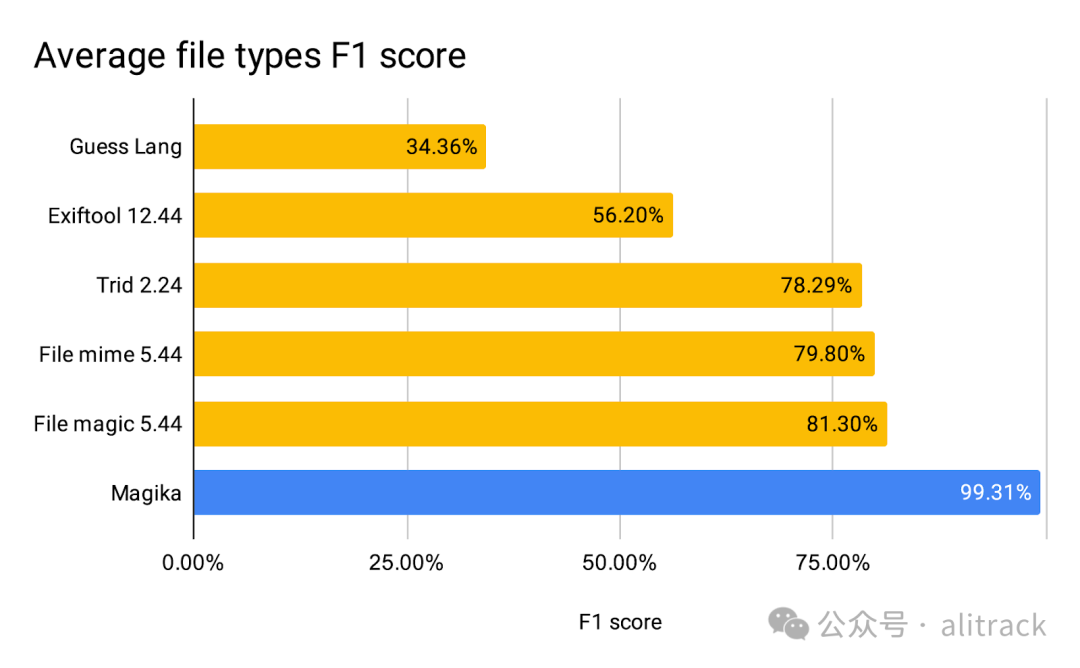
从这里看,Magika的确惊艳, 我忍不住第一时间安装测试
pip install magika
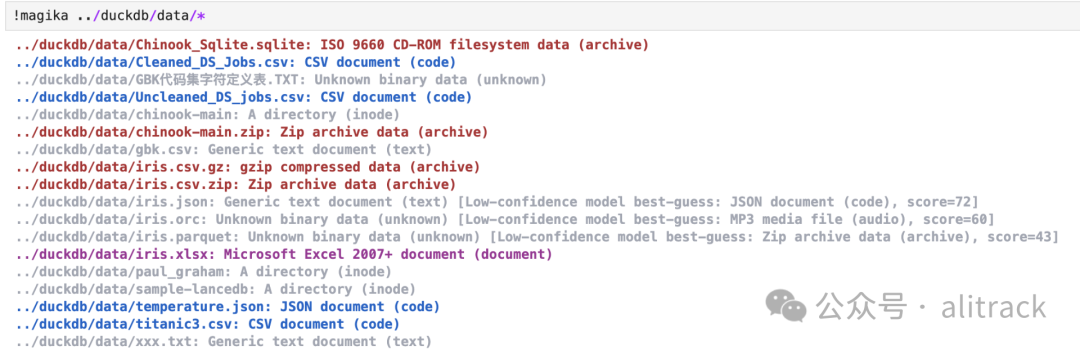
对比下file的结果
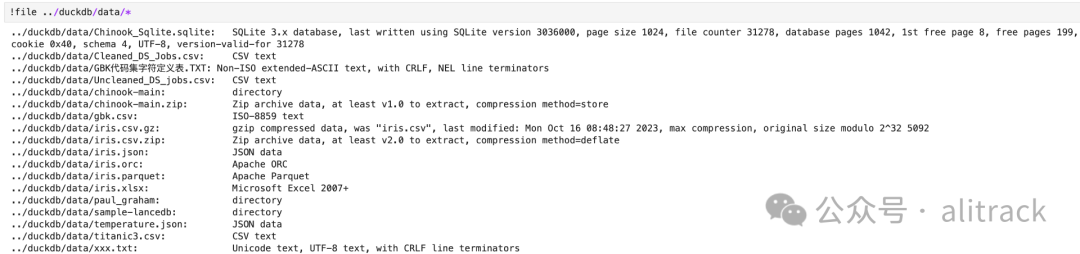
各位看官自己看吧, 我想我已经不必再多说啥了。
python-magic
file
命令 依赖libmagic
, 而libmagic
是一个用来根据文件头识别文件类型的开发库。于是就有了很多基于libmagic的封装,这里介绍一个比较热门的python-magic
python-magic
是 libmagic
文件类型识别库的 Python 接口。libmagic
通过根据预定义的文件类型列表检查文件头来识别文件类型。这个功能在 Unix 命令行中由 file
命令实现。
pip install python-magic
mac 和Windows用户还需要额外安装libmagic
使用也很简单
import magic
magic.from_file("testdata/test.pdf")
'PDF document, version 1.2'
# recommend using at least the first 2048 bytes, as less can produce incorrect identification
magic.from_buffer(open("testdata/test.pdf", "rb").read(2048))
'PDF document, version 1.2'
magic.from_file("testdata/test.pdf", mime=True)
'application/pdf'
写在最后
Windows 下的file命令
file 在Linux下和macOS下为系统自带命令,Windows下需要自行安装了,网上有不少提供编译好的版本, 我也曾经自己编译过,有兴趣的可以看看这两款软件可以解决你大部分编码的烦恼
引用链接
[1]
Magika:AI 驱动的快速高效的文件类型识别 : https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html
