




Lizard XA 分布式事务系统
分布式业务背景
PolarDB-X 作为一款企业级的分布式数据库,数据天然分片到不同的存储节点上,跨节点的修改和访问变成了常态,保障数据库的 ACID 特性,以及如何做到透明分布式也变成了一项有挑战的事情。
分布式业务挑战
- 转账模型,如何保证 ACID 特性?
如下图所示,一个经典的转账模型,在跨节点的情况下,如何保证事务的原子性,以及跨节点查询的一致性,单机的事务系统已经无法完成。
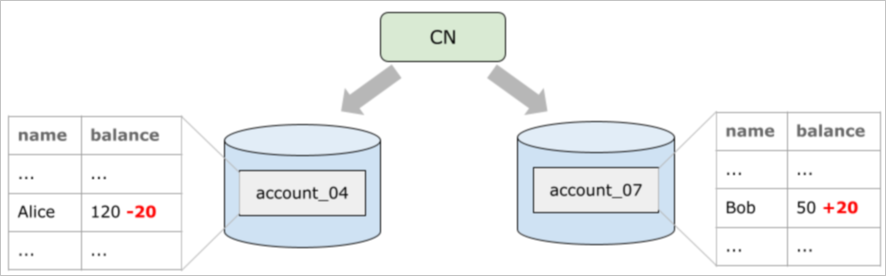
- 多维度分区键,如何做到业务透明访问?
在业务模型设计的时候,对应的业务访问,通常会涉及到多个维度,传统的本地索引无法多维度路由,这就需要引入全局二级索引来应对多维度的业务访问诉求,以便达到业务无感知,并高效的多维度路由访问方式,如何在跨节点的维护全局二级索引,同样需要分布式事务来保证。
分布式事务模型
能否完整支持事务ACID是企业级分布式数据库最核心的特性。目前,主流的分布式事务模型有:
- Percolator模型
Percolator 是 Google 在 2010 年提出的一种分布式事务处理模型,它的设计目标是在大规模分布式系统中实现高效的事务处理。Percolator 是一种乐观的事务模型,写写冲突被延迟到事务提交时才会进行检测。可见性与冲突检测依赖于事务的开始时间戳以及提交时间戳。Percolator 模型,包括后续的 Omid 模型,其特点是:实现原理容易理解且易于工程实现,作为一种高效且直接的分布式事务处理模型,被广泛应用于主流分布式数据库,其代表包括:TiDB、OceanBase 等。另外,由于其事务过程数据存放于内存中,事务大小会受到内存资源的限制。
- Calvin模型
Calvin 模型由 Brown 等人于2012年提出。它旨在提供高性能、高可用性和强一致性的分布式事务处理。Calvin 模型的核心思想是通过全局调度器,事先确定好各个调度节点的子事务执行顺序,从根源上规避掉并发事务的锁资源、缓存资源等资源的开销。为此,Calvin 模型还引入了一种称为 "transaction flow graph"(事务流图)的数据结构,用于描述事务的执行顺序和依赖关系。事务流图是一个有向无环图,其中节点表示子事务,边表示子事务之间的依赖关系。通过事务流图,Calvin 模型可以在分布式环境中实现事务的一致性和原子性。
尽管 Calvin 模型具有许多优点,但也存在一些缺点和挑战。在 Calvin 模型中,每个事务的执行都是独立的,并且在分布式环境中以并行方式执行。这种并行执行可能导致一些数据一致性问题,例如读取到过期或不一致的数据。虽然Calvin 模型提供了一些机制来解决这些问题,如版本控制和冲突检测,但仍然无法完全消除数据一致性的风险。其次,Calvin 模型需要一个全局调度器来协调和管理所有事务的执行。全局调度器需要考虑诸多因素,如事务的依赖关系、并发控制、负载均衡等,这增加了调度的复杂性。此外,全局调度器也可能成为系统的瓶颈,限制了整个系统的扩展性和可伸缩性。
- XA模型
XA 模型是一种用于管理分布式事务的标准接口规范。它定义了在分布式环境中进行事务处理所需的协议和操作。XA模型的名称来自于 X/Open 组织(现在是The Open Group),它制定了 XA 接口规范,以便不同的事务处理管理器(Transaction Manager)和资源管理器(Resource Manager)之间能够进行协作,实现数据的一致性。
在 XA 模型中,事务管理器(Transaction Manager)负责协调和管理事务的执行,而资源管理器(Resource Manager)则负责管理和操作特定的资源,XA 模型通过定义一组标准的接口和操作,使得事务管理器和资源管理器之间可以进行协作。
XA 模型的核心是两阶段提交(Two-Phase Commit,2PC)协议。在2PC协议中,事务管理器和资源管理器之间通过一系列的消息进行通信,以确保所有参与的资源管理器都在一个事务中执行相应的操作,并且最终要么全部提交,要么全部回滚。在这个过程中,事务管理器作为协调者(Coordinator),负责发起和管理2PC协议的执行。
XA模型的具体实现需要事务管理器和资源管理器都遵循 XA 接口规范。事务管理器需要实现事务的开始、提交、回滚等操作,以及协调 2PC 协议的执行。资源管理器需要实现参与 2PC 协议的相关操作,如准备(Prepare)、提交(Commit)、回滚(Rollback)等。
InnoDB XA 缺陷
弊端1:Read/Write 冲突严重
InnoDB 事务系统在内存结构中维护了全局活跃事务,包括活跃事务 (transaction) 链表,活跃视图 (read view)链表等结构,并由一把大锁保护,其简略结构如下:
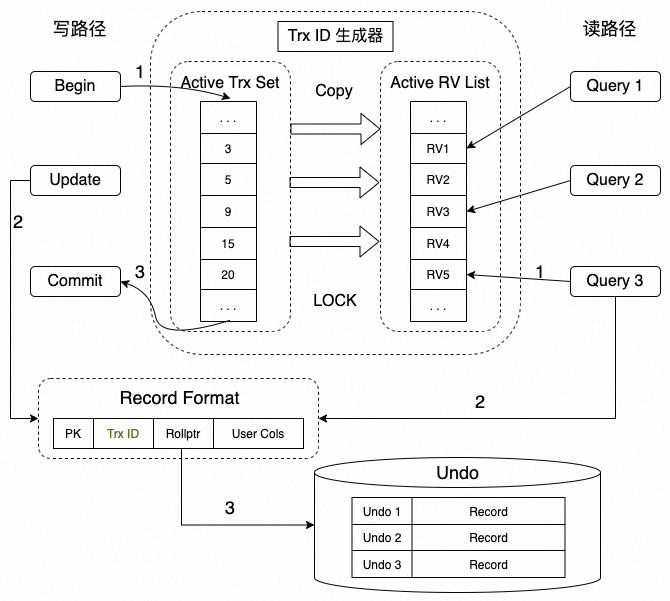
写路径上:
- 事务启动时,分配事务 ID,并插入到全局的活跃事务 ID 数组中
- 事务过程中,修改操作会将事务 ID 更新到行记录上来,表示该行记录的最新修改者
- 事务提交后,将事务 ID 从全局的活跃事务 ID 数组删除
读路径上:
- 查询启动时,启动 Read View,并将全局的活跃事务 ID 数组拷贝到 Read View 上
- 查询过程中,根据行记录上的事务 ID 号,判断是否在 Read View 上的活跃事务 ID 数组中来决定可见性
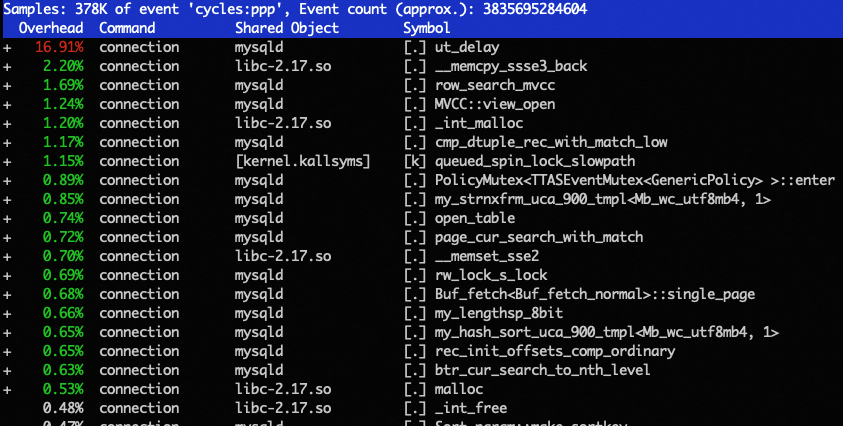
可以看到,无论是写路径还是读路径,都需要访问全局结构(全局活跃事务数组),这个过程需要在一个事务大锁的保护下完成。在过去,这样的设计是高效且可靠的。随着单机 CPU 多核能力的大幅加强,这样的设计越来越成为制约性能提升的瓶颈。以 PolarDB-X DN 节点在公有云上目前售卖的最大规格(polarx.st.12xlarge.25, 90C, 720G, 最大并发连接数2W)为例,压测 Sysbench read_write 场景,CPU 有接近 17% 的时间耗在无用的等待上:
弊端2:Commit 无法外部定序
在 InnoDB 事务系统中,其提交的真实顺序,由内部确定,其产生的提交号为 trx->no,其由内部来递增,外部既不能访问,也不能修改,当在分布式数据库集群中,使用两阶段提交协议进行提交分布式事务时,不同分片的提交号都由自己产生,各不相同,无法实现由 TSO 来统一定序的能力。
弊端3:MVCC 视图无法传播
InnoDB 事务系统的 MVCC 依赖视图 Read View,而 Read View 是由一个活跃事务 ID 数组来表达,其实现:
- 事务 ID 无法在分片之间同步和识别
- 数组大小跟当时活跃事务数量有关,无法固定大小和高效传播
这就带来了很大的限制:
- 在单机存储计算分离的模式下,无法高效使用 read view 进行存储计算下推
- 在分片集群模式下,无法得到全局一致性版本
- 在生态上下游下,无法存储 read view 版本
所以,PolarDB-X 存储引擎,自研了 Lizard XA 分布式事务系统,来替换传统的 InnoDB 单机事务系统。针对 InnoDB 事务系统的弊端,Lizard 事务系统,分别设计了 SCN 单机事务系统和 GCN 分布式事务系统来解决这些弊端,有效的支撑分布式数据库能力。
Lizard XA 架构
XA 状态流转
完全遵守 XA Spec 规范,Lizard XA 对于分布式事务定义了四种状态,依次为:
- Active 状态
- Prepare 状态
- Commit/Rollback 状态
- Forget 状态
XA 角色组件
为了实现 PolarDB-X 具有数据库的 ACID 特性和强一致性,其分布式事务模型采用了两阶段提交 (Two-Phase Commit,2PC) 协议,按照严格的 XA Spec 的定义,其中:
- Transaction Manager
CN 节点承担事务管理的职责,作为协调器 (Coordinator) , 负责分布式事务状态的持久化和分布式事务的推进流转
- Resource Manager
DN 节点承担事务参与者的职责,作为参与方 (Participants),负责接受用户数据的修改和事务状态的变化
XA 协议实现
跨节点的分布式事务,严格按照 2PC 协议的标准来实现,根据 XA Spec 定义的接口,CN 节点通过以下的语法来操作 DN 节点,
XA {START|BEGIN} xid
XA END xid
XA PREPARE xid
XA COMMIT xid [ONE PHASE] $GCN
XA ROLLBACK xid $GCN
XA RECOVER在 XA COMMIT / ROLLBACK 的时候,CN 节点从 GMS 获取一个 TSO,作为本次的外部提交号,也就是 GCN,传给所有 DN 参与方,并持久化,通过 2PC 协议, PolarDB-X 严格保证用户跨节点事务的原子性。
XA 完整性
PolarDB-X的分布式事务依赖于XA模型。然而,MySQL XA事务在多副本策略下,容易导致主备不一致。经过测试,直到 MySQL 8.0.32 版本,经过多轮完善修改后,XA 事务仍然有概率导致主备不一致。该问题的根源在于,BINLOG 日志作为 XA 事务参与方之一,由于其本身为文本追加的格式,事实上并不支持回滚能力。这个问题在 PolarDB-X 的分布式模型中会被放大,原因在于 PolarDB-X DN 节点内部依赖 X-Paxos 的多数派协议,BINLOG 日志同时作为协议的载体,需要承担更多更复杂的状态流转逻辑。
Lizard 事务系统针对 MySQL XA 事务完整性问题,提出了基于 GTID 的全量事务日志回补方案,彻底解决了 MySQL 由来已久的 XA 事务完整性问题。其核心思想是,BINLOG 日志除了承担了内部协调日志功能外,还保存了全量的事务操作日志。在故障恢复中,存储引擎会提供 GTID executed 集合,binlog 日志会根据 GTID 集合,回补在存储引擎中丢失的事务。
PolarDB-X 存储引擎,想要实现全局分布式事务的 ACID 特性,和全生态一致性,必须依赖一套分布式事务系统,而MySQL 社区版本的 InnoDB 事务系统,存在诸多的弊端。
SCN 架构
事务系统架构
关系型数据库的 MVCC 机制,依赖数据的提交版本来决定其可见性,所以,Lizard 单机事务系统,引入了 SCN (System Commit Number) 来表达事务的提交顺序,并设计了事务槽 (Transaction Slot) 来持久化事务的提交版本号即 SCN,其架构图如下:
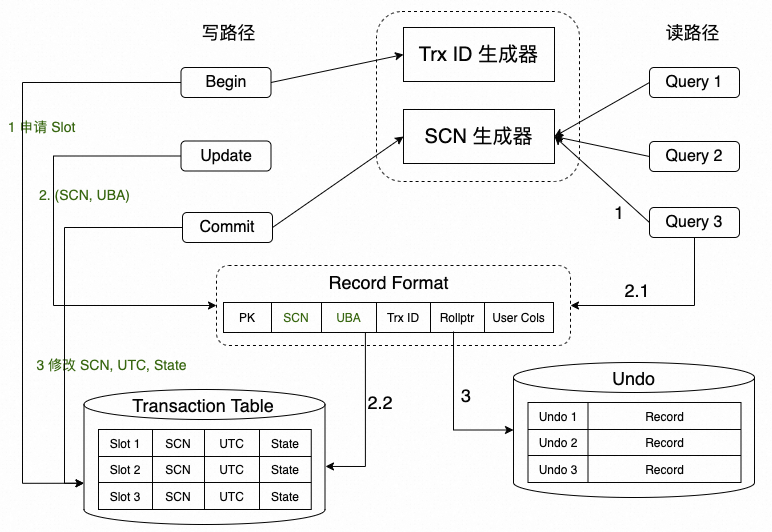
写事务:
- 事务启动时,申请事务槽 Transaction Slot,地址记为 UBA
- 事务过程中,对修改的记录填入 (SCN=NULL, UBA) 两个字段
- 事务提交时,获取提交号 SCN,并回填到事务槽上,并完结事务状态,返回客户提交完成
读事务:
- 查询启动时,启动事务视图 Vision,即从 SCN 生成器上获取当前 SCN,作为查询的 Vision
- 查询进行时,根据行记录的 UBA 地址找到对应的事务槽,获知事务的状态以及提交号
- 根据记录 SCN 和 视图 SCN 进行数字大小比较,就可以判断可见性
事务系统代价
相比于 InnoDB 事务系统,Lizard SCN 事务系统带来了巨大的优势:
- 解绑对全局结构的访问依赖,读写冲突得到大幅缓解
- 视图升级为 Vision,只有一个 SCN 数字,不再有活跃事务ID 数组,易于传播
- 支持自定义的 FlashBack 查询
但同时也引入了一些代价,因为事务提交只修改了事务槽,行记录上的 SCN 一直为 NULL 值,所以,每次的可见性比较,都需要根据 UBA 地址访问事务槽,来确定真实的提交版本号 SCN,为了减轻事务槽的多次重复访问,我们在Lizard SCN 事务系统上引入了 Cleanout,一共分为两类,Commit Cleanout 和 Delayed Cleanout。
Commit Cleanout
事务在修改过程中,收集部分记录,在事务提交后,根据提交的 SCN,回填部分收集的记录,因为需要尽量保证提交的速度不受影响,仅仅根据当前记录数和系统的负载能力,回填少量的记录,并快速的提交返回客户。
Delayed Cleanout
查询过程中,在根据 UBA 地址回查事务槽 SCN,判断其事务状态以及提交版本号之后,如果事务已经提交,就尝试帮助进行行记录的 Cleanout, 我们称之为 Delayed Cleanout,以便下次查询的时候,直接访问行记录 SCN 进行可见性判断,减轻事务槽的访问。
Transaction Slot 复用
由于事务槽不能无限扩展,为了避免空间膨胀,采用 Reusing 方案。事务槽会持续的保存到一个 free_list 链表上,在分配的时候,优先从 free list 中获取进行复用。
另外频繁地访问 free_list 链表以及从 free_list 链表上摘取,需要访问多个数据页,这带来了巨大的开销,为了避免访问多个数据页,事务槽 page 会被先放入 cache 快表中,下次获取时直接从 cache 快表上获取,这大大降低了读多个数据页带来的开销。
事务系统性能
虽然 Cleanout 带来了部分的代价,但由于分担到了查询过程中,并且没有集中的热点争抢存在,在测试结果上,相比 InnoDB 事务系统,Lizard SCN 事务系统整体的吞吐能力大幅提升。
QPS | TPS | 95% Latency (ms) | |
Lizard-8032 | 636086.81 | 31804.34 | 16.07 |
MySQL-8032 | 487578.78 | 24378.94 | 34.33 |
MySQL-8018 | 311399.84 | 15577.15 | 41.23 |
(注:以上数据测试环境为 Intel 8269CY 104C,数据量为1600万,场景为 Sysbench Read Write 512 并发)
相比于MySQL-8032,Lizard SCN 事务系统性能提升 30%,延时降低 53%。
GCN 架构
为了实现严格的 2PC 协议, PolarDB-X 存储引擎在 SCN 单机事务系统的基础上,实现了 GCN ( Global Commit Number) 分布式事务系统,其架构图如下:
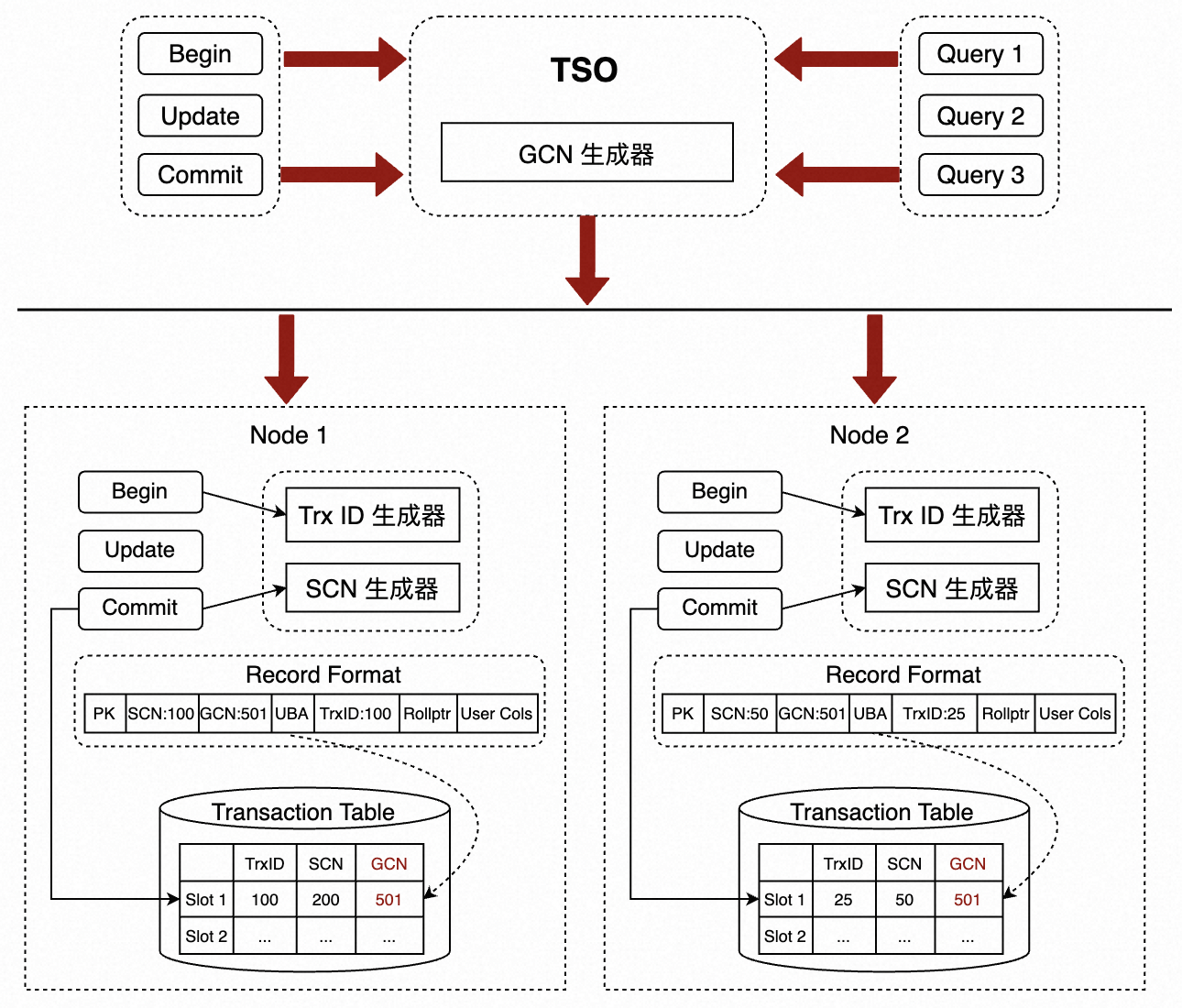
Lizard 事务系统的事务槽 (Transaction Slot) 在原有的基础上扩展了一个字段,用于保存一个 GCN,即 Global Commit Number,这个 GCN 来源于 TSO 发起号,至此,跨节点的事务将使用 GCN 来代替 SCN 为分布式事务全局定序。
读强一致性
在用户的跨节点访问中,CN 节点将获取一个 TSO 作为本次查询的 MVCC 视图,并通过 AS OF 查询下发到 DN 存储节点,其语法如下:
SELECT ... FROM tablename
AS OF GCN expr;在 GCN 事务系统中, 由于分布式事务由 GCN 定序,所以查询的可见性比较,也从单机的 SCN 比较转换成 GCN 比较,来保证全局的强一致性,由于外部定序和两阶段的提交过程, 在可见性比较的时候,对于无法决策的 Prepare 状态,PolarDB-X 采用了等待的策略,等事务状态完结,再进行 GCN 的大小比较。
