





今天为大家分享一篇SIGMOD 2023年的向量检索论文:
High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations
论文概述
目前,深度神经网络输出的嵌入向量的维数正在快速增长。比如,在自然语言领域,SalesForce公司最近发布的SFR-Embedding-2模型的输出向量维数是4096,阿里巴巴的gte-Qwen2-7B-instruct模型则输出3584维向量。
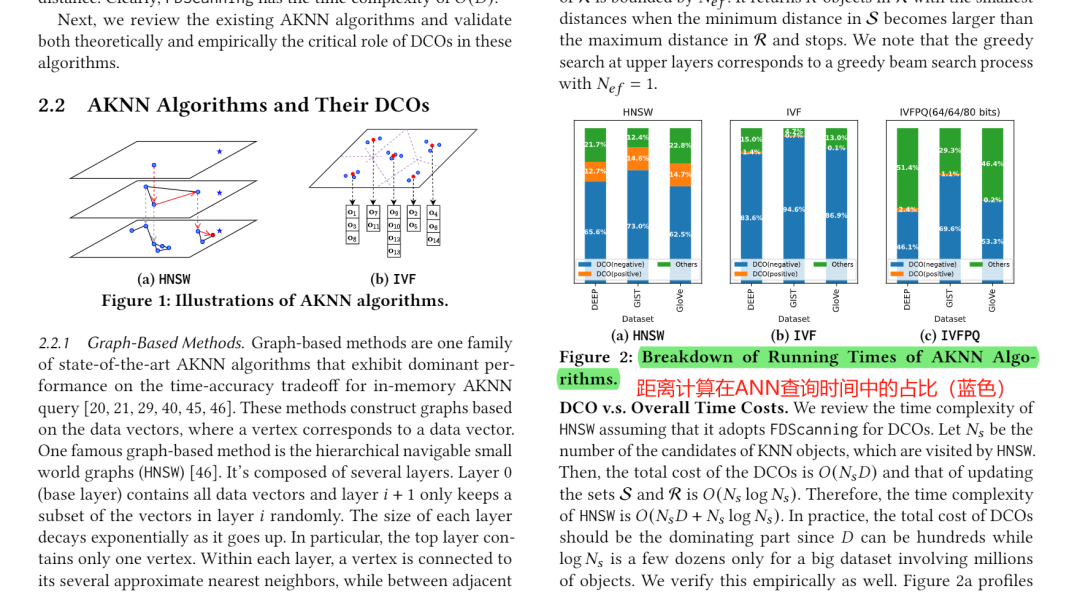
相比于低维向量,高维向量有更广泛的语义表示空间,可以提高文本表示的精确性。然而,这也给后续的向量检索带来了更大的压力。在向量相似性检索索引中,查询时间的主要瓶颈是向量间的距离计算(占总时间80%以上),而距离计算的复杂度和向量维数成正比。向量维数的提高意味着查询代价的线性增长。
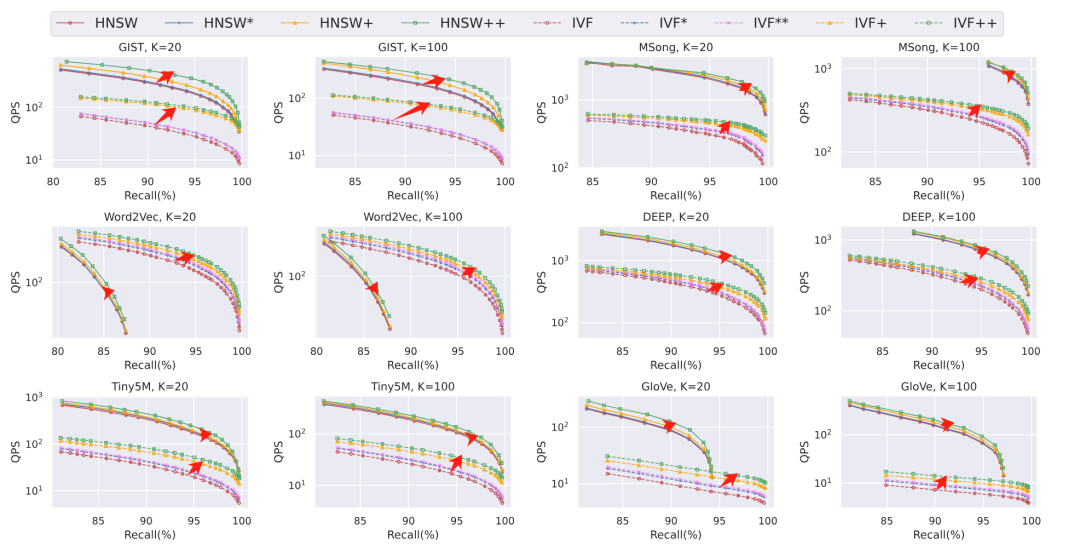
针对这个问题,本篇论文提出基于低维计算估计高维向量精确距离的算法ADSampling,降低距离计算代价;同时针对两种主流的向量索引:IVF和HNSW进行改造。结果显示,ADSampling可以减少HNSW查询中至多75%,IVF中至多89%的距离计算代价。
关键算法
基于随机映射的向量间距离估计
简而言之,随机映射方法可以在低维空间中通过简单数学变换反映高维向量间距离,且维数越接近原始向量,精度损失越小。
自适应维数选择
与ANN算法的融合
精彩段落


<<< 左右滑动见更多 >>>
总结
延伸阅读
[1] arXiv'24:多种降维方式加速向量检索的benchmark Distance Comparison Operators for Approximate Nearest Neighbor Search: Exploration and Benchmark
[2] VLDB'23:向量量化压缩提升查询吞吐量 Similarity Search in the Blink of an Eye with Compressed Indices
[3] SISAP'23:PCA降维加速图索引算法 General and Practical Tuning Method for Off-the-Shelf Graph-Based Index: SISAP Indexing Challenge Report by Team UTokyo
编者简介

复旦大学与巴黎西岱大学联合培养博士生,研究领域为高维数据(向量、序列等)管理和分析。以第一作者在SIGMOD,VLDB,VLDBJ,TKDE等数据库领域会议/期刊发表多篇论文,并担任审稿人。
关注 AI 搜索引擎,获取更多专业技术分享
