




本文将从“空间”这一维度,聊一聊PolarDB-X在跨空间部署能力上的不断发展和延伸,以及在不同空间范围下的高可用和容灾能力,并着重介绍一下最新的产品能力——GDN(Global Database Network)。
常见的高可用/容灾架构
目前数据库业界常见的高可用/容灾架构主要有:
单机房
单机房内,进行异步复制或基于Paxos/Raft的强同步复制,可应对单数据副本故障或机架级别的故障容灾。同城多机房
一般为单地域3机房,一个机房一份数据副本,跨机房进行异步复制或基于Paxos/Raft进行强同步复制,可满足机房级别的故障容灾,但无法满足多地域多活的诉求。两地三中心
基于Paxos/Raft的「双地域」复制架构,分为主地域和异地灾备地域,流量主要在主地域,异地主要承担灾备容灾,异地机房日常不提供多活服务。两地三中心架构下,主地域有两个机房,每个机房有两个副本,灾备地域只有一个副本,多数派强同步在主地域即可完成,相比基于Paxos/Raft的同城多机房架构,性能持平且具备了异地容灾能力,当主地域出现不可用时,可以切换到灾备地域,但无法保障RPO=0。三地五中心
基于Paxos/Raft的「多地域」复制的架构,可以跨越3个地域,地域A两个机房,地域B两个机房,地域C一个机房,每个机房对应一个数据副本,同时可以指定A或B地域为主地域。三地五中心架构下,多数派强同步需要跨地域,对性能会带来较大影响,好处是任何一个地域发生灾难都不影响系统的可用性,且可以保证RPO=0。Global Database
构建全球多活的架构,写操作发生在中心,各自地域提供就近读的能力,可以支持一主多从、多主多从等部署形态。该架构最大的特点是轻便、灵活,可以根据需要创建单活、双活、多活等容灾形态,一般为异步复制,PolarDB-X的GDN便是此架构,后文会有详述。Geo-Partitioning
基于地域属性的partition分区架构,提供按用户地域属性的就近读写能力,该方案是一个需要在数据内核层面支持「地域空间」属性的方案,在创建库、表时可以指定地域相关的维度信息,如指定某张表需要覆盖的region以及primary region,甚至可以为同一张表下不同的分区指定不同的primary region。相比前面几种主要通过调整数据库实例的部署形态来实现容灾的架构,该架构可以控制的更加精细,一套数据库实例可以同时实现单AZ、多AZ、多Region的容灾需求,并且可以控制到分区级别,但需要业务适配的成本较高,且跨地域时必须是强同步对性能不友好。
下面通过一个表格对如上所列的容灾架构进行一下总结和对比:
容灾架构 | 容灾范围 | 最少机房要求 | 数据复制 | 优缺点 |
单机房 | 机架/单个副本故障 | 1机房 | 异步 | 异步复制,性能好,但RPO>0 |
同步 | 同步复制,性能稍有损耗,但RPO=0(少数派故障时) | |||
同城多机房 | 单机房级别 | 2机房 | 异步 | 异步复制,性能好,但RPO>0 |
3机房 | 同步 | 比较通用,业务平均RT增加1ms左右 | ||
两地三中心 | 机房、地域 | 3机房 + 2地域 | 同步 | 比较通用,业务平均RT增加1ms左右 |
三地五中心 | 机房、地域 | 5机房 + 3地域 | 同步 | 机房建设成本比较高,业务平均RT会增加5~10ms左右(具体取决于地域之间的物理距离) |
Geo-Partitioning | 机房、地域 | 3机房 + 3地域 | 同步 | 业务有适配成本(表分区增加地域属性),业务平均RT增加5~10ms左右(具体取决于地域之间的物理距离) |
Global Database | 机房、地域 | 2机房 + 2地域 | 异步 | 比较通用,业务就近读+ 远程转发写,适合异地读多写少的容灾场景 |
PolarDB-X的容灾能力
单机房(Paxos 3副本),能够应对少数派1个节点的故障
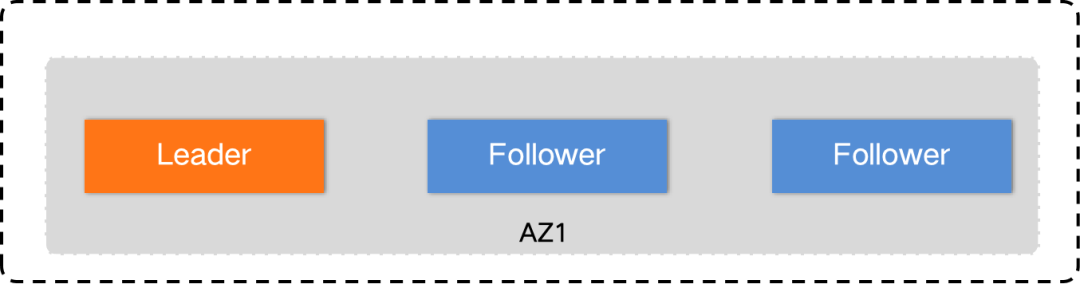
同城3机房(Paxos 3副本),能够应对单机房故障
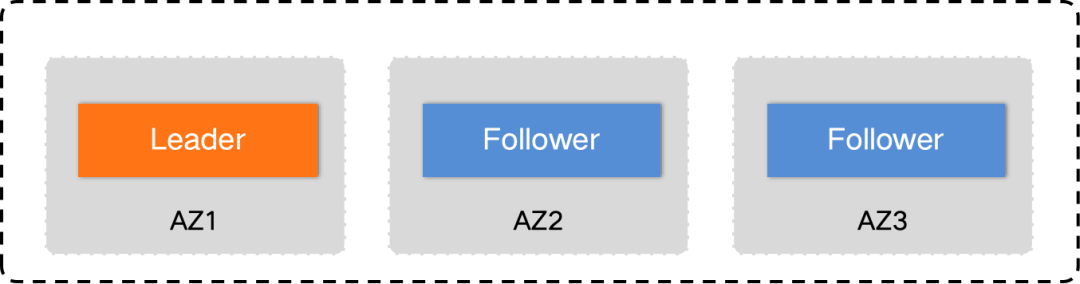
两地三中心(Paxos 5副本),能够应对地域级的故障
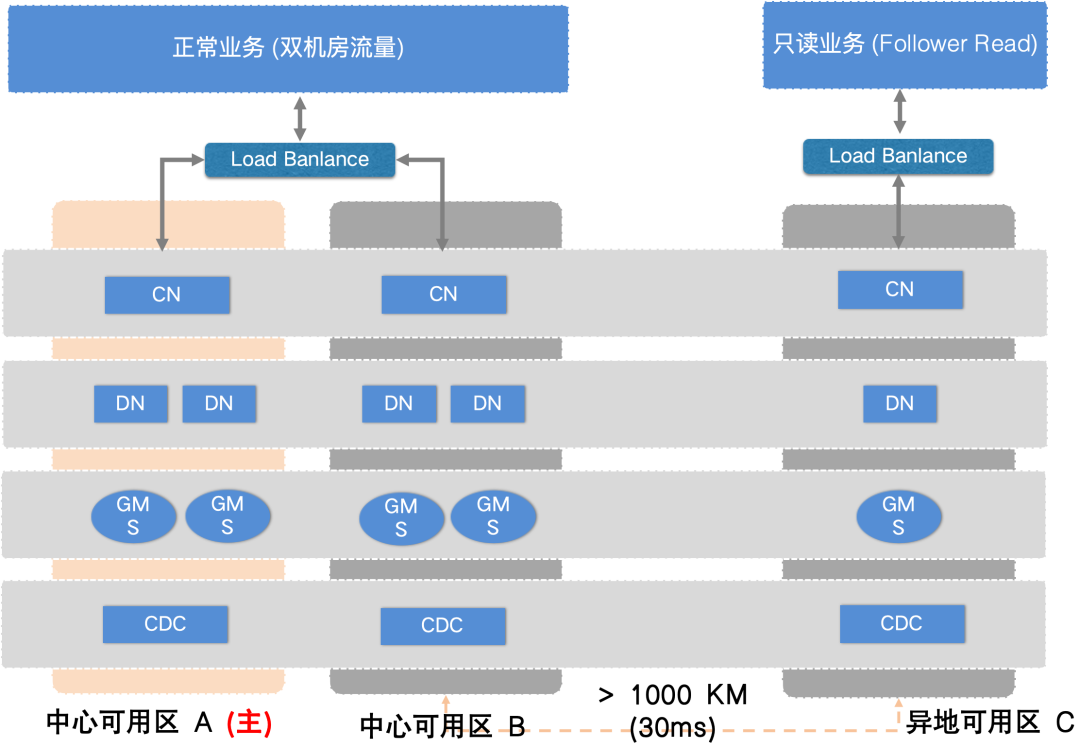
GDN多活(主从异步复制),能够应对地域级故障,并提供就近读的能力
PolarDB-X的空间哲学
空间换时间
最典型的案例——数据库索引,通过增加索引空间的占用,实现查询时间的降低。在PolarDB-X中有多种类型的索引:分区级别的Local Index,表级别的GSI(Global Secondary Index),以及面向分析查询场景的列存索引CCI (Columnar Clustered Index)。参见[附1]、[附2]、[附3]空间换隔离
最典型的案例——读写分离,通过数据同步增加冗余数据,实现读写操作的隔离。PolarDB-X原生支持读写分离架构,可以为主实例添加一个或多个只读实例,将写流量发往主实例,将需要的读流量发往只读实例,降低主实例压力的同时也保证了读操作的响应速度。参见[附4]空间换降本
成本数据。还可正常访问数据。最典型的案例——冷热数据分离,通过将冷数据的存储空间形态进行转换,实现存储成本的降低。PolarDB-X原生支持冷数据归档能力,将在线表中的冷数据归档到低成本的存储介质中(如OSS),并进行格式转换和压缩处理,大幅降低成本的同时且不影响对冷数据的实时读取。参见[附5]、[附6]、[附7]空间换安全
最典型的案例——备份和加密,通过保留全量和增量备份数据可以实现快速数据恢复,通过数据加密可以提供更好的安全保障(加密带来数据存储空间的上升)。PolarDB-X支持多个维度的备份恢复能力,基于PITR的整实例一致性备份和恢复、基于binlog的SQL闪回、基于undo log的闪回查询、基于列存的快照查询和恢复等;支持TDE数据加密和全密态安全保证。参见[附8]、[附9]、[附10]空间换ONLINE
最典型的案例——ONLINE DDL,通过开辟临时空间并结合一系列算法,实现DDL的无锁变更,让业务永远在线。基于论文《Online, Asynchronous Schema Change in F1》的思想,PolarDB-X结合分布式事务能力,通过数据拷贝、数据回填、元数据平滑切换等措施,支持各种类型的Online DDL变更,尤其值得一提的是OMC(Online Modify Column)能力,相比原生MySQL具备更加强大的Online能力。参见[附11]、[附12]空间换可用性
最典型的案例——数据副本,通过数据复制技术冗余多个数据副本,并基于一致性共识协议实现多副本的数据一致,实现RPO=0的高可用能力。PolarDB-X的DN节点基于自研的X-Paxos协议实现了可保证数据强一致的高可用能力,且可保证RTO<20s,满足金融级数据一致性要求。参见[附13]、[附14]、[附15]
PolarDB-X GDN详解
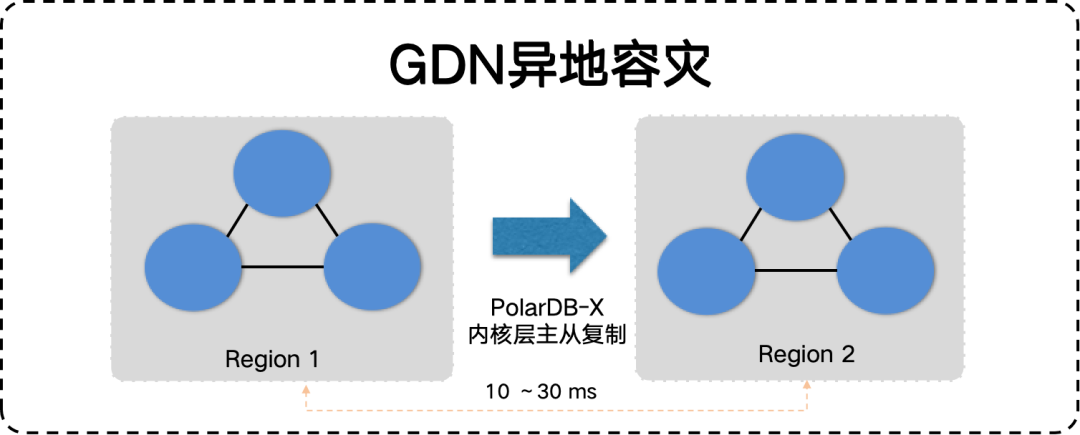
GDN是什么
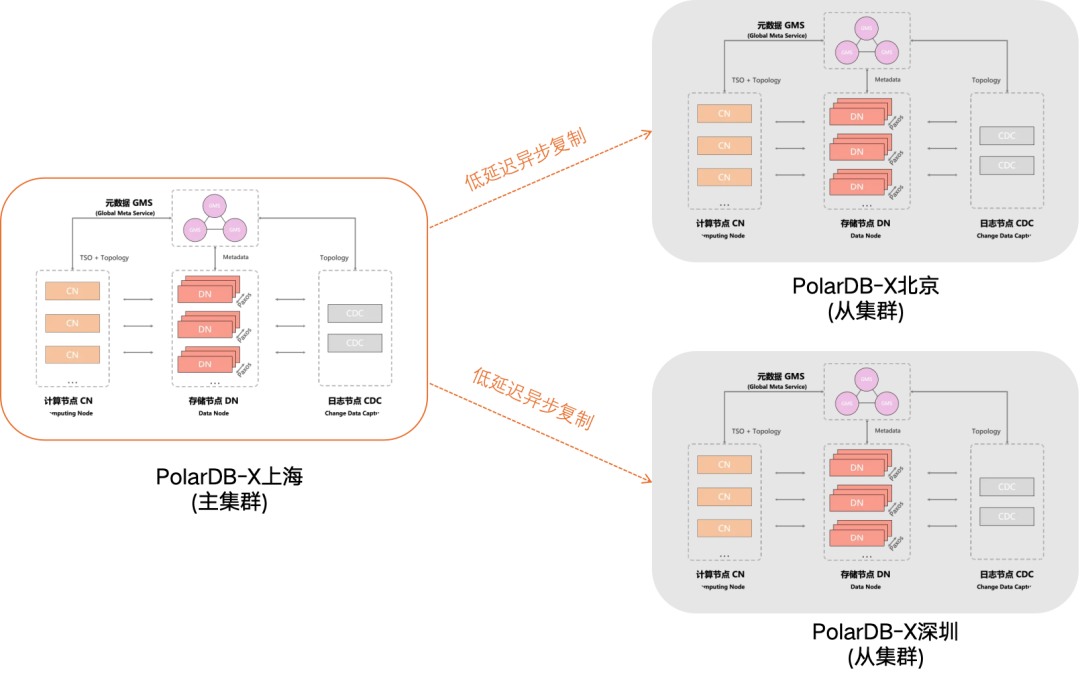
借助GDN,可以实现两大核心目标:
异地多活
如果业务部署在多个地域,传统网络下,数据库在主地域,其它地域的应用需要跨地域访问主地域的数据库,网络延迟会导致数据访问性能低下,带来不良的用户体验。通过GDN的跨地域低延迟同步、跨地域读写分离、本地就近读取等特性,可以确保各地域的应用访问数据库时的延迟控制在秒级。异地容灾
不论业务部署在一个或多个地域,都能通过GDN实现异地容灾。当主集群出现地域级别的故障时,您只需要手动将您的业务切换到从集群,主从实例切换可以在120秒内完成。
主从模式只是GDN的基础形态,此形态下应用侧进行很少量的改造便可以接入GDN。GDN的更高阶形态是「双主模式」,甚至是「多主模式」,当应用需要构建「多地域 + 多活 +多写」容灾架构时,常见方案为,首先会在业务侧进行单元化改造,其次在数据库侧构建双向同步链路、配置同步防回环策略、配置当数据出现写入冲突时的处理策略等等,在GDN高阶形态下,并结合PolarDB-X的分区能力,会让多活多写容灾变得更加简单。举例来说:
PolarDB-X提供了丰富的分区类型:Key分区、List分区、Range分区,还支持各种分区类型相组合的二级分区能力,除此之外,甚至还支持用户提交自定义的udf作为分区函数。那么,让单元化的路由规则和PolarDB-X分区表的分区规则进行关联,会让多写架构变得更加简单、灵活和安全。我们可以在每个地域(单元)将和本地域(单元)对齐的分区设置为可读可写,将未对齐的分区设置为只读(禁写),流量切换会变的更加灵活,可以做到以单元为粒度的整体切换,也可以做到只切换部分分区到另外的单元。此外,由于在数据库侧加入了分区禁写,即使应用侧出现了路由错误,PolarDB-X作为最后一道闸门会拒绝不合法的写入操作,规避写冲突。如上所述,在传统的基于「非分布式数据库 + 非分区表」的场景下,都是难以做到的,当然,基于PolarDB-X也完全可以实现传统的数据双写架构,二者并不矛盾。关于多活多写的更多资料,可参见[附17]
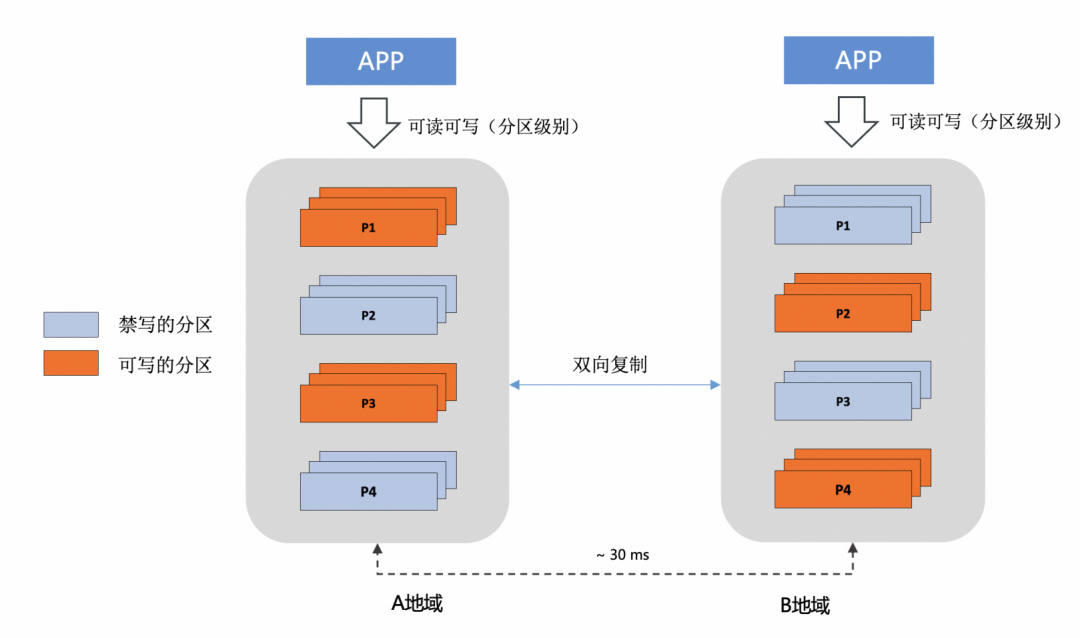
在多活多写架构下,不同region之间需要配置双向复制链路,双向复制链路最大的挑战是防止“复制回环”,PolarDB-X内置了一套基于server_id的轻量级防回环能力,简单易用,后文会有详述。
GDN的技术架构
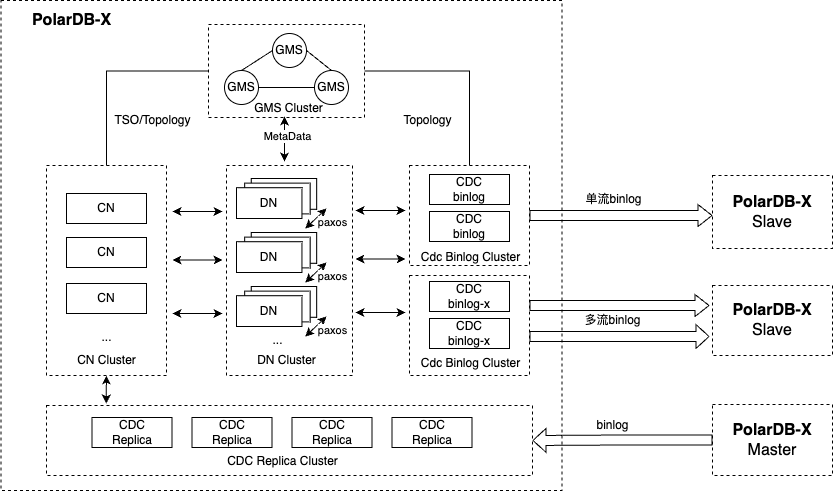
说明:
CDC binlog支持两种服务形态,单流binlog和多流binlog,且可同时存在,具体可参见官网:日志服务。
在GDN场景下,可根据实际情况选择单流或多流复制,当单流复制链路触达性能瓶颈时,可考虑使用多流复制模式,具体的瓶颈点因场景而异。
关于Replica主从复制的详细介绍可参见官网: 使用PolarDB-X作为PolarDB-X的Slave 、Replication语句。
GDN的核心能力
多样化DML复制
复制策略 | 性能表现 | 事务一致性 | 说明 |
TRANSACTION | 一般 | 强 |
|
SERIAL | 一般 | 弱 |
|
SPLIT | 较好 | 弱 |
|
MERGE | 好 | 弱 |
|
一体化DDL复制
高度的兼容性
相比于使用外挂同步工具实现PolarDB-X之间数据复制的方案,一体化的原生复制,无任何SQL兼容问题,不用担心跨产品、跨版本的兼容问题,数据复制的正确性和稳定性更有保障。除此之外,原生内核级复制更方便识别SQL语义和透传附加信息,做针对性的处理和优化,如:识别出分区变更类型的DDL及时调整DML SQL的where条件,识别出Locality类型的DDL将SQL中的DN信息剔除或替换为从实例中相对应的DN id,识别出列存类型的DDL做针对性的SQL改写等。可异步执行的DDL
比较耗时的DDL,会长时间阻塞数据复制链路并引发较高的数据延迟,这是数据复制领域的一个常见问题,而在分布式数据库场景下,对超大规模的数据表执行DDL,耗时可能会更久,引发的阻塞和延迟问题会更加严重。有很多类型的DDL在一般情况下其实是完全可以异步执行的,比如analyze table、alter table add index、alter table change partition definition等操作,PolarDB-X可以在内核层面实现自闭环且高效的异步DDL处理(beta功能),甚至可以在主从集群之间实现可联动的两阶段DDL处理,让大部分类型的DDL复制实现“零阻塞”(WIP)。一致性的DDL复制
当基于多流binlog构建GDN数据复制链路时,对于DDL复制需要考虑不同复制链路之间的协调一致,每条复制链路在收到某条DDL SQL后必须等待其它复制链路,只有当所有链路都收到该DDL SQL之后,才可以将DDL操作复制给从集群,否则将导致DML流量和Schema之间的不一致,引发异常或数据错误。GDN提供了Distributed DDL Replication Engine,通过高效的多路协调算法,实现分布式场景下一致性DDL复制。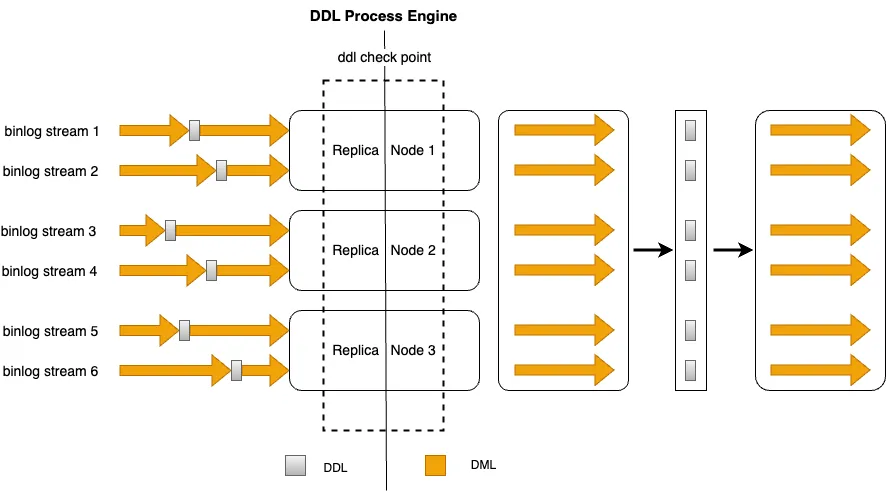
轻量级双向复制
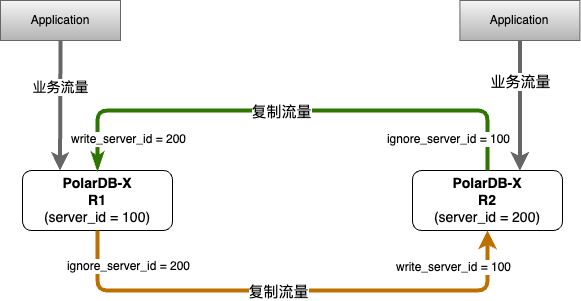
其优势可以体现在两个方面:
高性能
直接基于binlog event header中的server_id进行流量过滤的方式,相比外挂同步工具一般通过引入事务表进行流量过滤的方案更加轻量,无额外的性能损耗且扩展性更好(事务表对用户的数据库具有侵入性,且需要在同步每个事务时向事务表进行dml操作,存在写放大的情况)简单易用
在两个PolarDB-X实例上分别执行两条change master语句,即可快速构建具备回环流量过滤能力的双向复制架构。语法:CHANGE MASTER TO option [, option] ... [ channel_option ]option: {IGNORE_SERVER_IDS = (server_id_list)}示例:R1: CHANGE MASTER ... , IGNORE_SERVER_IDS = (100) , ...R2: CHANGE MASTER ... , IGNORE_SERVER_IDS = (200) , ...
完备的冲突检测
在数据复制链路中,尤其是在传统的多活多写架构下(即单元化规则和表分区规则未关联对齐的架构),如前文所述,有可能出现因bug或者某些意外情况导致的写冲突(即双边对相同主键或唯一键的数据进行了变更),此时需要一种冲突检测机制来规避可能的风险,PolarDB-X的数据复制内置了冲突检测机制,支持检测如下的冲突类型:
INSERT导致的唯一性冲突
同步INSERT语句时违背了唯一性约束,例如双向同步的两个PolarDB-X同时或者在极为接近的时间INSERT某个主键值相同的记录,那么同步到对端时,会因为已经存在相同主键值的记录,导致Insert同步失败。
UPDATE更新的记录不完全匹配
UPDATE要更新的记录在同步目标实例中不存在时,PolarDB-X支持自动转化为INSERT(默认不开启),此时可能会出现唯一键的唯一性冲突。
UPDATE要更新的记录出现主键或唯一键冲突。
DELETE对应的记录不存在
DELETE要删除的记录在同步的目标实例中不存在。出现这种冲突时,不论配置何种冲突修复策略,都会自动忽略DELETE操作。
针对数据冲突,PolarDB-X提供了配置参数来控制出现冲突时的修复策略,在创建或者后期维护复制链路时,都可以通过change master命令调整冲突修复策略。
CHANGE MASTER TO option [, option] ... [ channel_option ]option: {CONFLICT_STRATEGY = {OVERWRITE|INTERRUPT|IGNORE}}
OVERWRITE:表示对于冲突数据会采取Replace Into写入,进行覆盖,此为默认的处理策略。
INTERRUPT:表示中断复制链路。
IGNORE:表示忽略冲突。
需要说明的是:冲突修复是一种Best Effort的机制,在多活多写架构下,由于数据同步两端的系统时间可能存在差异、同步存在延时等多种因素,很难保证冲突检测机制能够完全防止数据的冲突。因此,重点还是需要在业务层面进行相应的改造,保证同一个主键、业务主键或唯一键的记录只在双向同步的某个PolarDB-X进行更新。采用单元化规则和表分区规则关联对齐的方案,靠数据库内核进行分区禁写,则是规避数据冲突的最简单有效的方案,而原生的GDN能力让这些变得更加简单。
快照级数据对账
GDN提供了原生的数据对账能力,内置的数据校验能力具备如下优势:
支持多种校验模式
直接校验:基于主从实例的最新数据进行校验,该校验方式在增量变更很频繁的情况下,会出现误差,需要多轮复核或配合人工校验进行处理。
快照校验:PolarDB-X支持基于TSO的快照查询,全局binlog支持保证线性一致的Sync Point,GDN基于这两个基础能力,可构建保证主从集群之间数据一致的tso-mapping并基于此tso进行快照查询并实现数据校验,该校验方式基于一致性快照进行校验,无误差,具备更好的易用性。
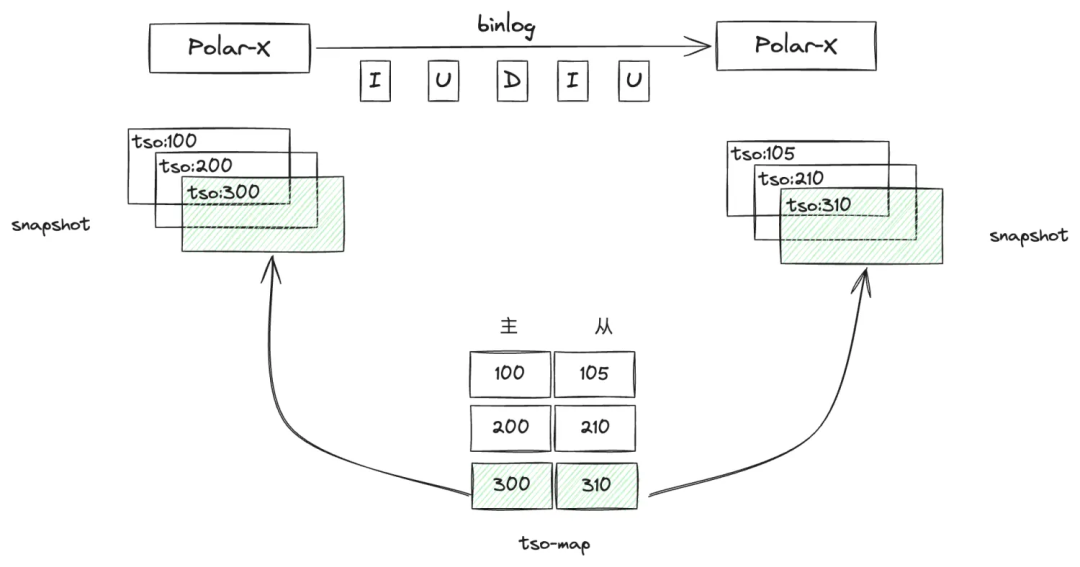
资源占用低、校验速度快。
GDN的数据校验采用checksum校验和逐条数据明细对比相结合的方式,首先通过采样算法对数据进行区间划分,优先对比每个区间数据的checksum,当checksum不一致时再转换为逐条数据明细校验,相比传统的直接one by one的逐条数据明细对比校验,此方式可以有10倍的性能提升且对资源的占用更低。
具体使用方法可参看官网文档:https://help.aliyun.com/zh/polardb/polardb-for-xscale/gdn-online-data-verification
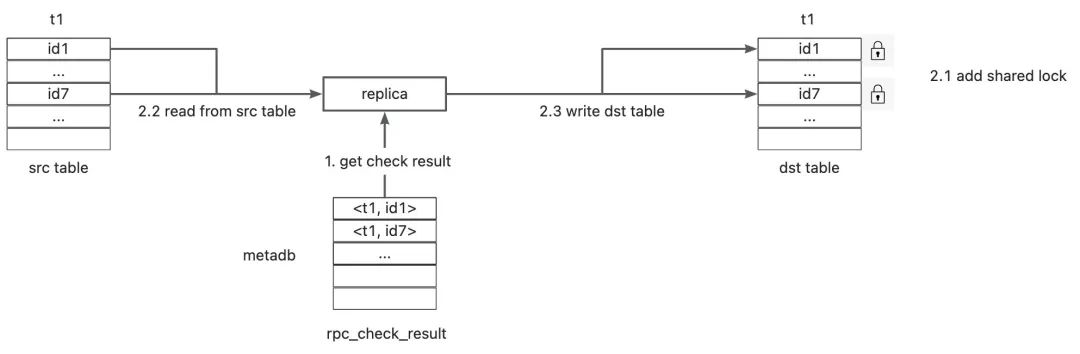
轻松的数据订正
对于后者,如果容灾切换时,采取的是应急强制切换的方案,可能会出现主实例的部分binlog还未在从实例完成复制的情况,即切换完成后新的主实例会丢失部分数据。如果原主实例最终无法恢复,相应的最终会丢失这一部分数据,但很可能在灾难恢复后,原主实例也完成了恢复,此时则有机会将丢失的binlog数据补偿给新的主实例。
如何补偿?一条一条去甄别,然后手动去操作吗?当然可以!当然也可以不用这么麻烦!PolarDB-X提供了全镜像匹配能力,可以让数据补偿变得更轻松一些,对切换前的原有复制链路开启全镜像匹配,然后消费剩余的binlog数据进行自动补偿:
对于binlog中的Insert event
回放给新主实例的时候,采取insert ignore的策略对于binlog中的delete event
回放给主实例的时候,where条件中要拼接所有column的值,如果不匹配则自动跳过对于binlog中的update event
回放给主实例的时候,where条件中要拼接所有column的值,如果不匹配则自动跳过
当然,这个方法并不是万能的,如果某条数据的某些列的值存在「改回去又改回来」的情况,则可能导致补偿后的数据不符合预期,但这种情况属于少数场景,在大部分场景下靠全镜像匹配能力可以做到自动补偿。另外,GDN的后续版本正在规划更高级的自动补偿能力,在全镜像匹配功能的基础之上,结合新主实例的binlog,来精确判断某条数据在容灾切换后是否在新主实例上发生过变更,以此来精确判断待补偿数据和目标数据之间是否存在“双写冲突”。
通过一条sql即可开启或关闭全镜像匹配功能:
CHANGE MASTER TO option [, option] ... [ channel_option ]option: {COMPARE_ALL = {true|false}}
快捷的容灾切换
常规切换(RPO=0)
计划内切换用于集群内所有实例及实例间数据复制制链路运行正常。执行计划内切换时,将导致集群中所有实例禁写,禁写时间取决于数据复制延迟的消除时间。计划内切换不会导致数据丢失。强制切换(RPO>=0)
当主实例发生短时间内无法恢复的不可用故障时,出于业务连续性优先原则,可考虑进行应急强制切换。执行应急切换时,所选从实例将立即被提升为集群主实例,该从实例从先前主实例复制组未提交的事务会丢失,数据丢失量取决于数据复制的延迟规模。
PolarDB-X也提供了便捷的原子API,在基于PolarDB-X自建GDN的场景,可以组合调用这些原子API构建自己的切换任务流。
# 对polardbx整实例进行禁写/开写alter instance set read_only = {true|false}# show full master status 可以查看主实例binlog最新的tsomysql> show full master status ;+---------------+-----------+--------------------------------------------------------+-------------+-----------+-----------+-------------+-------------+-------------+--------------+------------+---------+| FILE | POSITION | LASTTSO | DELAYTIMEMS | AVGREVEPS | AVGREVBPS | AVGWRITEEPS | AVGWRITEBPS | AVGWRITETPS | AVGUPLOADBPS | AVGDUMPBPS | EXTINFO |+---------------+-----------+--------------------------------------------------------+-------------+-----------+-----------+-------------+-------------+-------------+--------------+------------+---------+| binlog.006026 | 221137311 | 721745002099847993617485152365471498250000000000000000 | 211 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |+---------------+-----------+--------------------------------------------------------+-------------+-----------+-----------+-------------+-------------+-------------+--------------+------------+---------+# show slave status 可以查看从实例消费到的最新的tsomysql> show slave status \G;*************************** 1. row ***************************...,...Exec_Master_Log_Tso: 721745002099847993617485152365471498250000000000000000...,...
优秀的性能表现
测试环境:
polardbx实例配置(独享型)
CN:16core 128G * 4
DN: 16core 128G * 4 (版本 5.7)
CDC:32core 64G * 2
多流数量:6
测试数据:
测试场景 | 测试指标 | 单流RPS | 多流RPS | 延迟 |
Sysbench_oltp_write_only
| TPS: 3w/s QPS: 12w/s | 4w/s | 12w/s | 多流:< 2s |
Tpcc交易压测
| tpmC: 30w | 10w/s | 20w/s | 多流:< 2s |
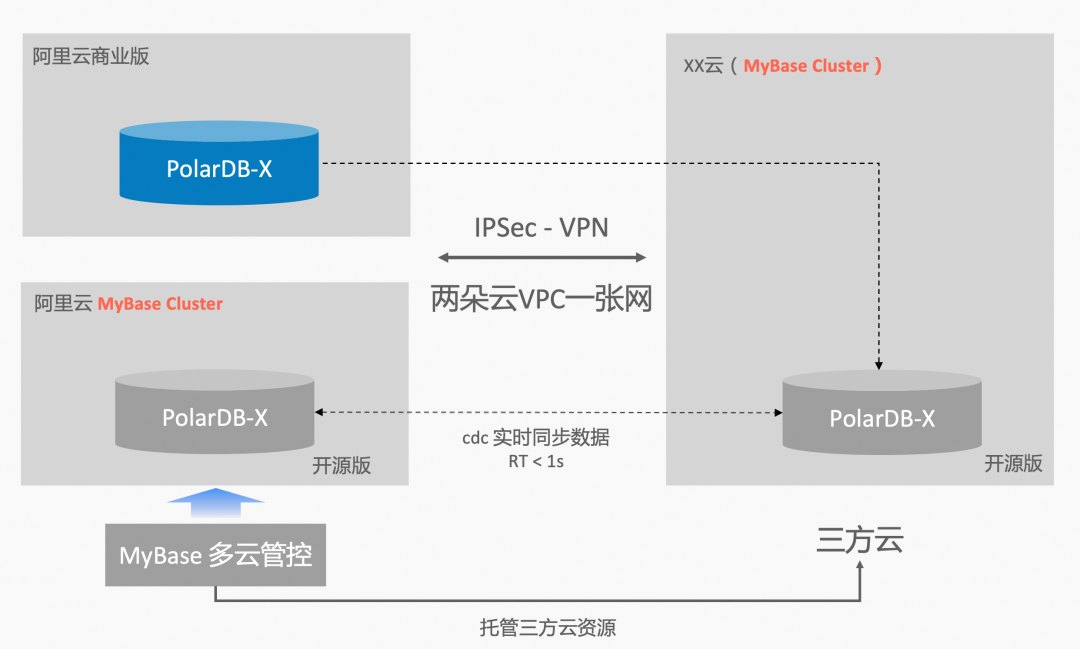
PolarDB-X GDN未来之跨云部署
附录
[附1] PolarDB-X 全局二级索引
[附3] PolarDB-X列存查询引擎
[附4] 谈谈PolarDB-X在读写分离场景的实践
https://zhuanlan.zhihu.com/p/579026526
[附5] 存储成本最高降至原来的5%,PolarDB分布式冷数据归档的业务实践
https://zhuanlan.zhihu.com/p/666737723
[附6] 实践教程之使用PolarDB-X进行冷热数据归档
https://zhuanlan.zhihu.com/p/666737723
[附7] 1/20的成本!PolarDB-X 冷热分离存储评测
https://zhuanlan.zhihu.com/p/560662058
[附9] PolarDB-X 是如何拯救误删数据的你(二):备份恢复
https://zhuanlan.zhihu.com/p/429977533
[附10] PolarDB-X 企业级特性之 TDE
https://zhuanlan.zhihu.com/p/454351658
[附11] PolarDB-X Online Schema Change
https://zhuanlan.zhihu.com/p/341685541
[附12] PolarDB-X:让“Online DDL”更Online
https://zhuanlan.zhihu.com/p/347885003
[附14] PolarDB-X 存储引擎核心技术 | Paxos多副本
https://zhuanlan.zhihu.com/p/655731358
[附15] PolarDB-X 存储架构之“基于Paxos的最佳生产实践”
https://zhuanlan.zhihu.com/p/315596644
[附17] 真·异地多活架构怎么实现?使用PolarDB-X!
https://zhuanlan.zhihu.com/p/364240552
