




通过自适应标签对齐黑盒大语言模型的检索器
论文摘要
检索增强生成(RAG)通过整合外部数据源的信息来增强大语言模型(LLM)。这使得LLM能够适应特定领域。但现有的检索器和LLM是分开训练的,导致模型之间是不对齐的。有一些相关工作通过LLM和检索器的联合训练来解决这个问题,但从0开始训练LLM是成本极高的。而且很多模型是黑盒模型,无法获取模型参数。
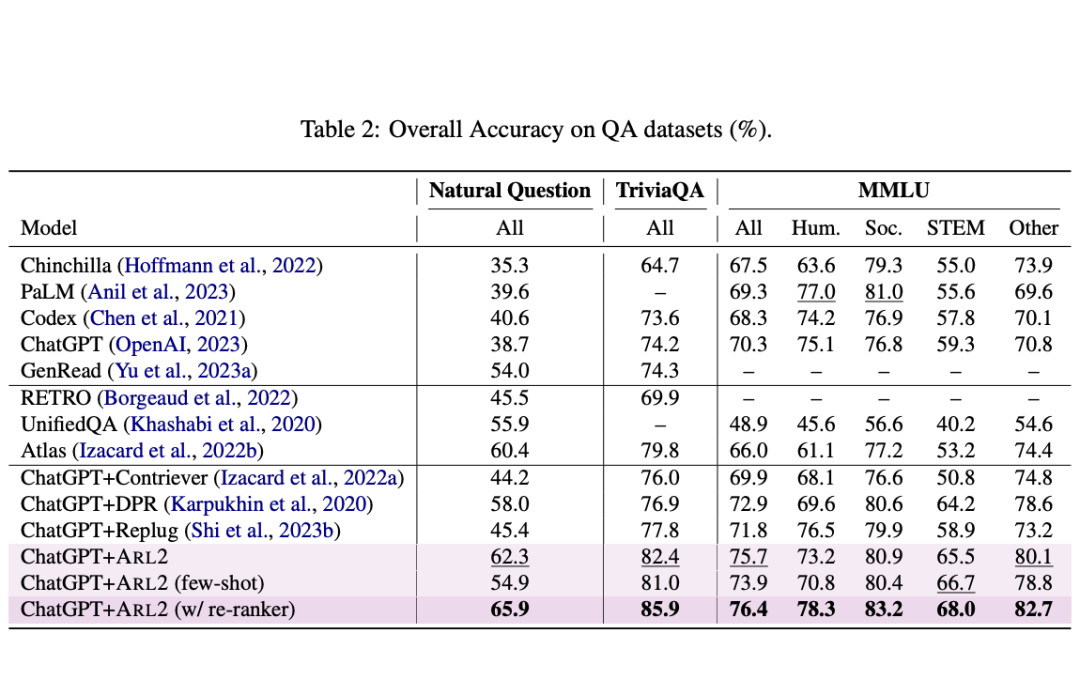
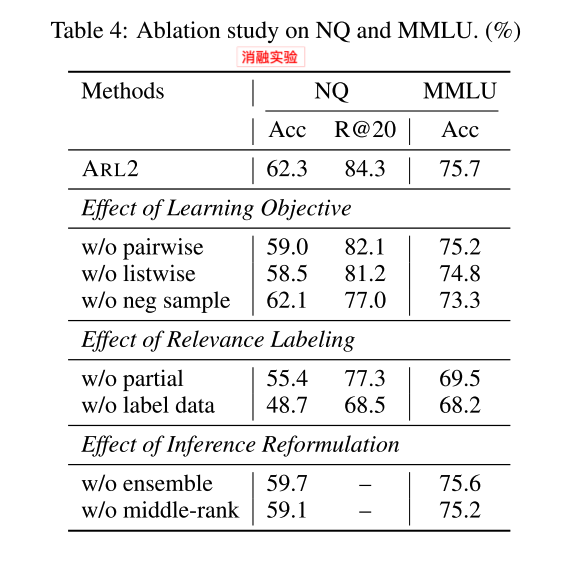
为了解决这个问题,本文提出了ARL2方法,利用LLM来注释和评分相关数据。从而来训练检索器。此外,还提出了低成本的自适应策略来生成高质量、多元化的相关数据。实验显示,与其他方法相比,在NQ和MMLU数据集准确率增长5.4%和4.6%。
主要方法
如何利用LLM来构建一个多样化和高质量的相关性标签训练数据集?
1. 数据集
与传统的query-document数据集不同的是,本文使用的数据集格式如下
2. 生成问题的多样性
3. 生成相关度评价
将问题和文档输入给ChatGPT,使用设定的提示词来生成证据和相关性分数。对于检索器来说,除了需要正负样本,还需要挑战性的负样本来增强检索能力。作者通过从相同文章或其他类似文章抽取文档段落的方式生成了挑战性负样本数据集。
如何训练检索器?
损失函数采用ranking loss,由如下两部分组成。
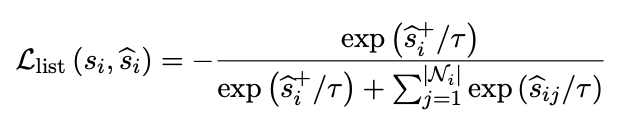
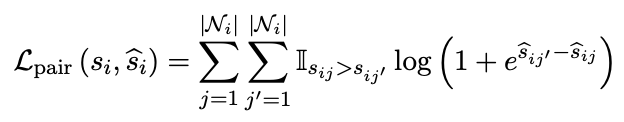
精彩段落

<<< 左右滑动见更多 >>>
总结
编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。作为核心研发工程师参与向量数据库、RAG等产品的研发。代表公司参加DTCC、WAIM等会议论坛进行主题分享。
文章转载自向量检索实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
