




1、介绍
随着大数据时代的到来,数字数据变得越来越珍贵。世界上大部分数据都存储在磁盘中。海量数据存储使磁盘的稳定性面临巨大挑战。一旦磁盘发生故障,存储在其中的数据可能会永远丢失。虽然磁盘可以冗余备份,但这会增加成本,当多个磁盘损坏时,仍会发生数据丢失。根据Backblaze 2019年的报告,磁盘的年故障率为1.25%,这使得维护变得极其困难。在一个拥有25000个磁盘的中兴数据中心,磁盘几乎每天都会发生故障。
磁盘故障通常分为不可预测故障和可预测故障。不可预测的故障通常是由意外事故引起的,本文将不作讨论。对于可预测的故障,异常的外部振动、磁盘周围的异常温度和湿度以及读写错误率的增加为磁盘故障预测提供了可能性。提前迁移数据可以大大减少损失。磁盘故障预测技术已成为学术界和工业界的热点,对提高数据中心的可靠性具有重要意义
在相关研究中,主要方法是基于磁盘状态数据建立状态分类模型,然后根据分类模型对要测试的磁盘数据进行分类。一种是正常的,另一种是接近故障的。这种方法的主要限制是适用性有限。这是因为运维人员只能知道磁盘即将发生故障,但不知道故障会持续多久,很难掌握磁盘更换的时间。过早更换磁盘会浪费大量磁盘生命周期。太晚更换磁盘很容易导致永久无法修复的数据。基于中兴通讯对高效磁盘管理的需求,我们认为提前5-7天预测磁盘故障是合理的。
本文研究了中兴通讯每天收集一次的SMART[13]数据集,试图预测磁盘是否会在5-7天内发生故障。磁盘状态在5天内分为正常或故障。之后,通过过采样和欠采样来平衡阳性和阴性样本。最后,对特征数据进行训练,得到磁盘故障预测模型。在实验阶段,本文基于中兴通讯的历史数据集,比较了不同的数据平衡方法、不同的采样日、不同的训练轮、不同的算法效果,并在数据中心进行了为期7个月的有针对性的优化,取得了良好的效果。
2、预测器的设计与实现
由于不同磁盘品牌的数据具有一些不同的属性,本文的研究对象是中兴数据中心共73942个希捷磁盘,其中包括2年内3119个故障磁盘。
A.样品标签
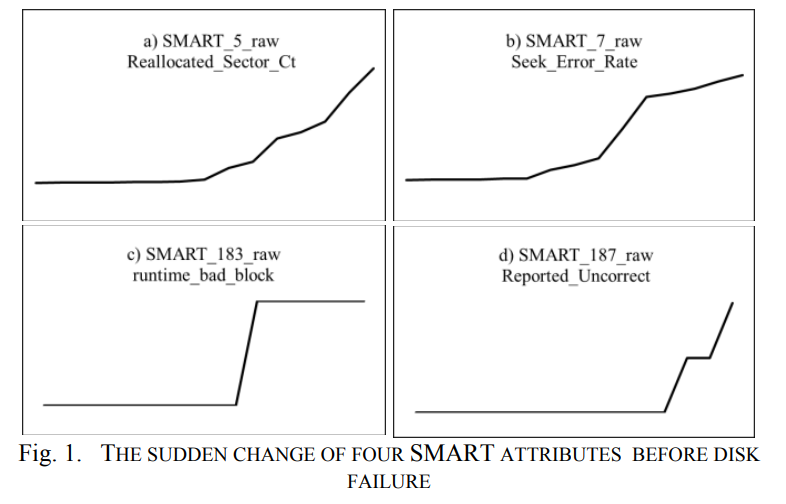
SMART数据集是一组属性,并设置阈值,超过阈值的属性在正常操作下不应通过。SMART被广泛用于磁盘故障预测。首先,观察故障前磁盘SMART属性的变化。如图1所示,失效前数据集中SMART_5_raw、SMART_7_raw、SMART_183_raw和SMART_187_raw的值发生了显著变化,这是本文预测的最重要属性。从Backblaze数据集中可以得出类似的结论。我们观察了大量磁盘的状态,并考虑了实际的应用需求,最终在故障前5天将磁盘定义为故障磁盘。
训练集的原始阳性样本是故障时间5天内所有故障磁盘的SMART属性数据,训练集的初始阴性样本是从每个健康磁盘中随机选择10次的SMART特性数据。因此,有18714个阳性样本和708230个阴性样本。
由于偶尔出现SMART采集失败或传输数据集错误,因此需要进行缺失值填充。本文采用的方法是:如果缺失值连续2个或更多,则使用磁盘上SMART项目的模式作为填充值;如果只有一个缺失值,则使用其前后值的平均值作为填充值。
数据归一化使用区间缩放方法,该方法在特征中使用Max和Min将所有值缩放到[0,1]的区间。
Sample_days和predict_failure_days是两个重要参数:
Sample_days定义为每个序列样本中LSTM网络输入数据的时间窗口大小,例如,Sample_days为5,则训练样本将包含过去5天磁盘的SMART属性信息。sample_days需要具有适当的值。如果它太小,提供给LSTM的潜在信息就会更少。如果它太大,它对应于一个很长的时间序列。距离最终故障太远的数据对最终故障趋势的预测影响很小,甚至可能产生误导。
Predict_failure_days定义为故障发生前的天数,这是一个报警边界。predict_failure_days的值也需要适当。时间间隔过长或过短都会影响磁盘故障处理的有效性。predict_failure_days的值在5-7天内是合理的。
关于特征选择,因为深度学习模型会自动学习特征,数据集的特征维度涉及45个维度,在滤除方差为0的特征后,只剩下21个维度。本文中没有进一步的特征选择,因此所选的特征包括:SMART_1_raw、SMART_4_raw、SMART_5_raw、SMART _7_raw、SMART_9_raw、SMA _12_raw、SMART_183_raw、SM _184_raw、MA _187_raw、AM _188_raw、PM _189_raw、M _190_raw、MM _192_raw、MR _193_raw、RM _194_raw、MP _197_raw、CM _198_raw、MS _199_raw、MT _240_raw、_241_raw和SMART_242_raw。
C.数据集平衡
由于其他硬盘SMART数据集也面临着同样的问题,中兴数据集中的正样本数量远少于负样本数量,这使得机器学习算法在训练模型时难以获得足够的正样本信息,因此FDR相对较低,需要平衡数据。本文尝试了四种样本平衡方法,包括ADASYN、SMOTE、ADASYN结合ENN和SMOTE结合ENN,以比较不同的预测结果。数据平衡后,阳性和阴性样本的数量均为50000。在评估部分,我们将比较数据平衡对预测效果的影响。
每个磁盘都会经历一个从健康到故障的过程,因此在固定时间段定期收集的SMART数据是时间序列。作为一种常见的算法,RNN模型的记忆通常在7个时间段内,早期输入的数据会由于梯度的消失而逐渐失效。如果仅使用SMART属性来更改7天或更短的时间窗口,则远远不能反映磁盘状态的变化。幸运的是,LSTM是RNN的改进版本,它在具有时间序列特征的问题上表现更好。它通过信息传输器存储内存,解决了梯度消失的问题,因此本文可以使用更大的时间窗口进行磁盘预测。此外,为了进行比较,本文还尝试了常见的算法,包括RNN、AdaBoost、随机森林、LOG、SVM和决策树。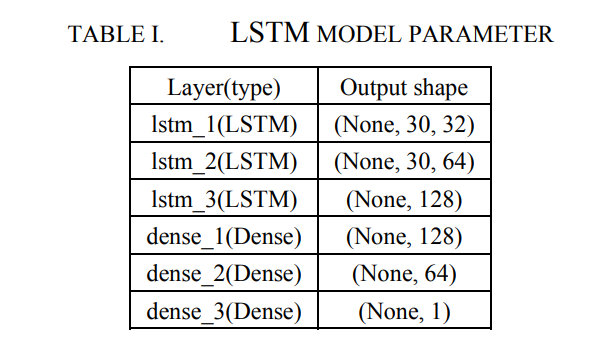
如表1所示,本文使用LSTM N to 1模型。输入是sample_days中的数据,输出是故障是否会在5天内发生。如果即将发生故障,输出为1,否则为0。考虑到磁盘故障预测规则的复杂性,本文构建了一个由3层LSTM和3层Dense组成的神经网络。前5层的输出尺寸为32、64、128、128、64,第6层的输出维度为1。
3、 评价
本章首先基于中兴通讯历史数据集进行训练和测试,并将所有样本按8:2的比例分为训练集数据和测试集。在测试过程中,分别比较了不同的数据平衡方法、不同的样本日大小、不同的训练轮和不同的算法。每个样本都按照故障或健康状况进行分类。然后,在中兴数据中心推出后的7个月内,我们根据每个磁盘预测未来5-7天是否会出现故障。本章以FDR和FAR作为评价指标。
A.对历史数据集的评价
在本章中,基于不平衡、ADASYN、SMOTE、ADASYN-结合ENN和SMOTE结合ENN,对原始数据集进行预处理以进行比较。为了提高效率,训练迭代次数限制为50轮,sample_days设置为30。实验结果如表2所示。在特征、模型和预测失败天数相同的因素下,与不平衡相比,过采样方法显著提高了FDR,过采样和欠采样方法的结合降低了FAR,进一步提高了预测效果。其中,SMOTE与ENN的结合性能最佳,FDR为89.2%,FAR为9.3%,因此该方法用于后续实验的数据平衡。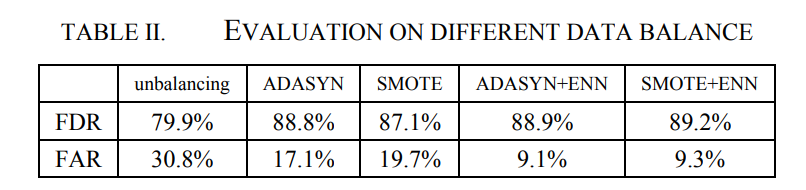
在5、10、15、20、30和40个采样日内对不同采样日大小进行评估。为了提高实验效率,训练迭代次数限制在50轮以内。如表3所示,当sample_days为30时,预测性能最佳。sample_days越长,提供的信息越多,预测就越准确。然而,距离故障时间点40天太长了,这些数据对最终故障趋势的预测几乎没有甚至产生误导性的影响。因此,后续实验sample_days被设置为30。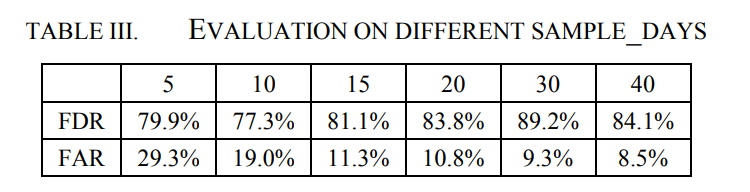
对不同训练轮的评估与50、100、200、300、400、500和1000的训练轮进行了比较。对于超过1000轮的训练,由于需要超过24小时,因此在数据中心是不可接受的。如表4所示,训练轮数达到400轮后,FDR和FAR不再变化。因此,后续训练轮数设置为400轮。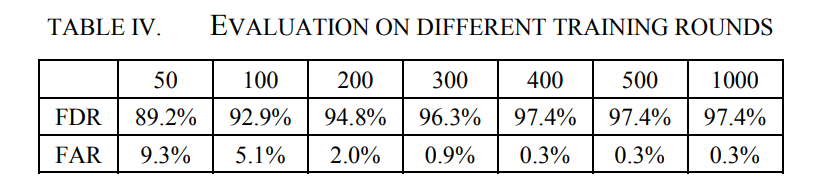
评估主要基于LSTM,并与其他算法进行比较。实验结果如表5所示,在特征、数据平衡方法和样本日大小相同的条件下,不同机器学习模型对磁盘故障预测的影响差异很大。LSTM和决策树的FDR在97%以上,而LSTM在FAR上的性能最好。综合考虑FDR和FAR,后续实验的算法为LSTM。本实验中的训练模型将在第4.2节中使用。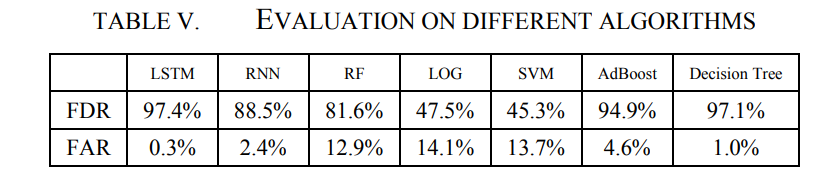
B.数据中心在线评估
为了进一步更准确地验证4.1中训练的模型的效果,本文在数据中心进行了为期7个月的验证,每月有100多个故障磁盘。这些故障盘用于测试上个月的预测结果,第7个月仅用于观察磁盘是否发生故障,而不是预测。如表6所示,所有带有故障报警的磁盘分为4种类型:5天内故障、6天或7天故障、8天以上故障和30天以上故障(健康)。数据中心每天收集一次所有磁盘的SMART,然后给出预测结果。当磁盘第一次报警时,会自动记录时间。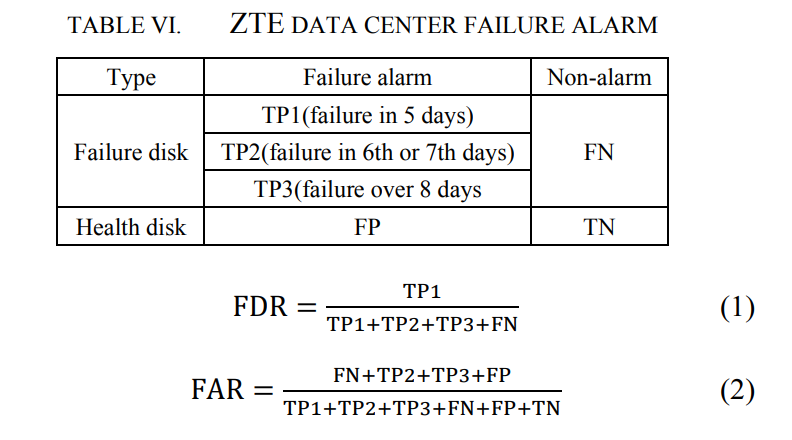
首先,我们计算了FDR和FAR,如(1)和(2)所示。也就是说,只有5天内的故障报警被视为正确的预测,模型不再更新。实验结果如表7所示。我们可以看到有两个问题:1)模型时间越长,FDR越低,FAR越高;2) FDR远低于4.1的实验结果。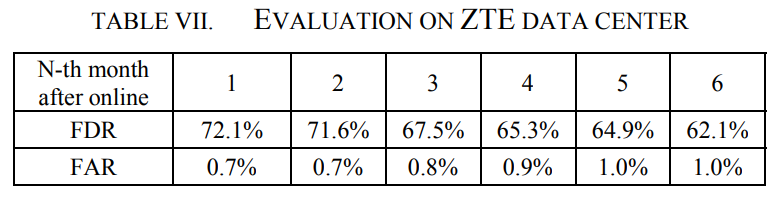
第一个问题是由模型的老化引起的,因此本文试图每月将新获得的样本放入训练集中,以便每月更新一次模型,并使用新模型预测下个月的失败。实验结果如表8所示,可以看出问题已经得到解决。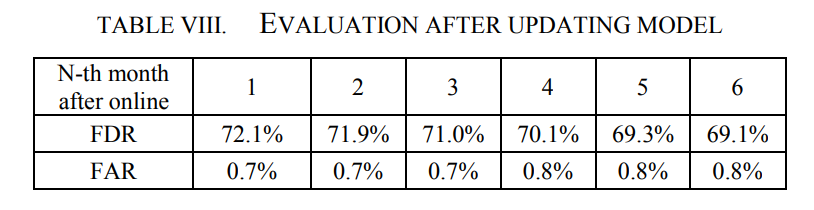
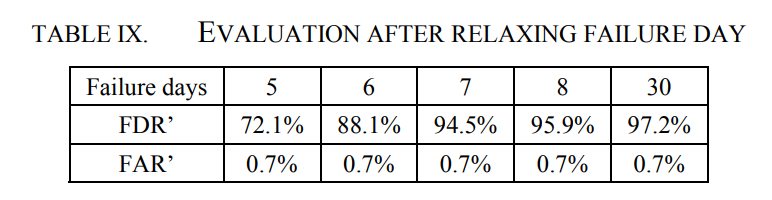
面对第二个问题,通过研究表6中的值,我们发现TP2值较大,这是FDR降低的原因。对于SMART在5天内接近磁盘故障的磁盘,其剩余寿命与现场IO有关。一旦IO减少,该磁盘将从TP1更改为TP2,这显然会导致预测不准确。因此,本文放宽了预测是否正确的判断标准。对于6或7天后出现故障的磁盘,认为判断也是正确的。因此,FDR'和FAR'的新方程如(3)和(4)所示。实验结果如表9所示。磁盘7天失效预测的FDR'和FAR'分别为94.5%和0.7%。虽然如果放宽到8天以上,FDR会更高,但它超出了数据中心的限制,因此本文不讨论。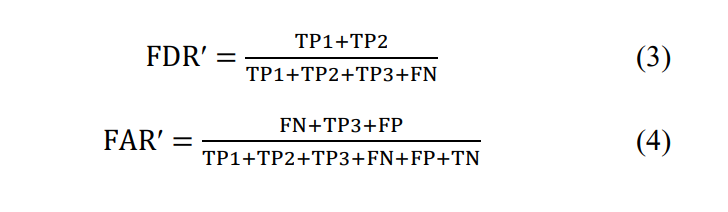
4、 相关工作
目前,大多数研究工作只关注磁盘的二元分类,无法在5-7天之前预测故障。业务数据中心的验证很少
在使用传统机器学习模型的研究中,Murray使用SVM进行磁盘预测的研究,并选择磁盘IO作为状态量化数据,其中磁盘FDR达到55%,FAR为5%。Hamerly Greg使用贝叶斯模型作为分类器,使预测达到更高的准确性,FDR提高到71%,FAR降低到1.8%。在Pitakrat的论文中,不再选择磁盘IO,而是选择SMART作为SVM模型训练的特征。FDR上升至85%,FAR下降至0.8%。在Botezatu[6]的论文中,选择了SMART数据的15个特征,并尝试使用RGF模型提前10到15天预测磁盘故障,结果FDR为98%。
在使用深度学习模型时,朱使用ANN模型以时间窗口为单位训练输入数据,并提前15天进行预测,FDR达到95%。庞和贾提出了使用BP-ANN进行训练,也取得了良好的效果。在徐的论文中,使用RNN模型以时间窗为单位训练输入数据,使FDR达到97%以上。在Ioannis的论文中,SMART的时间序列得到了有效的应用。FDR可以提前48小时达到93.91%。并比较了LSTM和RNN模型的效果,得出LSTM更好的结论。
此外,微软提出使用FastTree算法代替机器学习算法,为磁盘故障预测提供了一种新的解决方案。
