




导读



优化查询:重写查询逻辑,减少不必要的联接和数据扫描。 索引优化:为常用于联接和查询的字段创建索引,提高查询效率。 分区表:根据业务逻辑对表进行分区,以提高查询和维护的性能。 读写分离:通过读写分离来减轻主数据库的压力,提高查询响应速度。 分布式数据库:考虑使用分布式数据库解决方案,以支持水平扩展和负载均衡。 异步处理:对于不需要即时返回结果的查询,采用异步处理方式。

SQL 解析与优化:TiDB Server 负责接收客户端的 SQL 请求,进行语法解析和逻辑优化,生成执行计划。这一步骤是查询优化的关键,TiDB Server 会利用其优化器来决定最有效的查询执行路径。 分布式协调器 PD(Placement Driver):PD 是 TiDB 的元数据管理组件,负责存储集群的元信息,包括数据分布和节点状态。它与 TiDB Server 交互,协调数据的分布和负载均衡。 分布式存储 TiKV:TiKV 是一个分布式的键值存储系统,负责存储实际的数据。TiDB Server 通过 PD 与 TiKV 进行交互,获取或写入数据。 执行器:在获取到数据后,TiDB Server 的执行器负责进行数据的进一步处理,包括合并、排序、分页和聚合等操作。
水平扩展:TiDB Server 可以轻松地通过增加节点来扩展系统的处理能力。 高可用性:TiDB Server 设计为无状态,可以快速故障转移,保证服务的连续性。 强一致性:通过分布式事务和 MVCC 机制,TiDB 保证了事务的 ACID 属性。
集中式处理:MySQL 的所有数据库操作,包括 SQL 解析、查询优化、数据存储和检索,都在同一服务器上完成。 单一数据存储:数据存储在本地磁盘或连接的存储系统中,没有分布式存储的概念。 垂直扩展依赖:由于是单体架构,MySQL 通常通过增加单个服务器的硬件能力(如 CPU、内存、存储)来提升性能,这称为垂直扩展。
简化管理:由于所有组件都在一个服务器上,管理和维护相对简单。 扩展性限制:垂直扩展有其物理限制,当达到硬件极限时,性能提升会遇到瓶颈。 事务和并发处理:MySQL 通过行锁和表锁等机制来处理并发和事务,但在高并发场景下可能会遇到性能瓶颈。
扩展性:TiDB 的分布式架构允许其水平扩展,而 MySQL 主要依赖垂直扩展。 容错能力:TiDB 通过多节点和副本机制提供高可用性,MySQL 则依赖于主从复制和故障转移机制。 性能:TiDB 通过分布式计算和存储优化了大规模数据集的性能,MySQL 在大规模数据集下可能会遇到性能瓶颈。 复杂性与灵活性:TiDB 的架构较为复杂,但提供了更高的灵活性和扩展性;MySQL 架构简单,但在处理大规模和高并发场景时可能需要额外的优化措施。
 MySQL 架构图
MySQL 架构图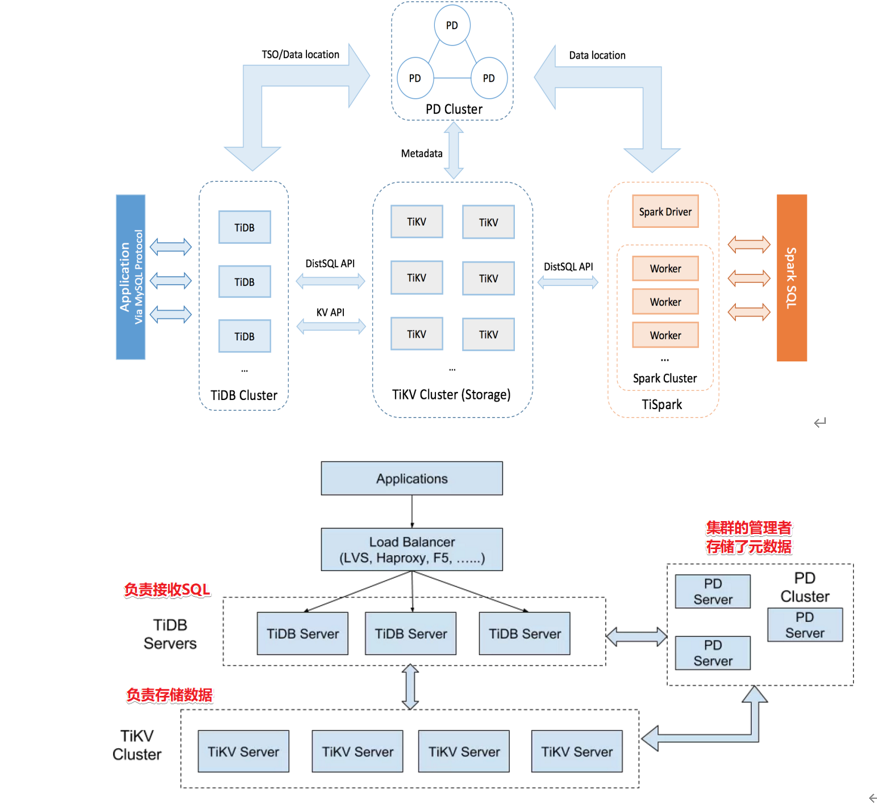
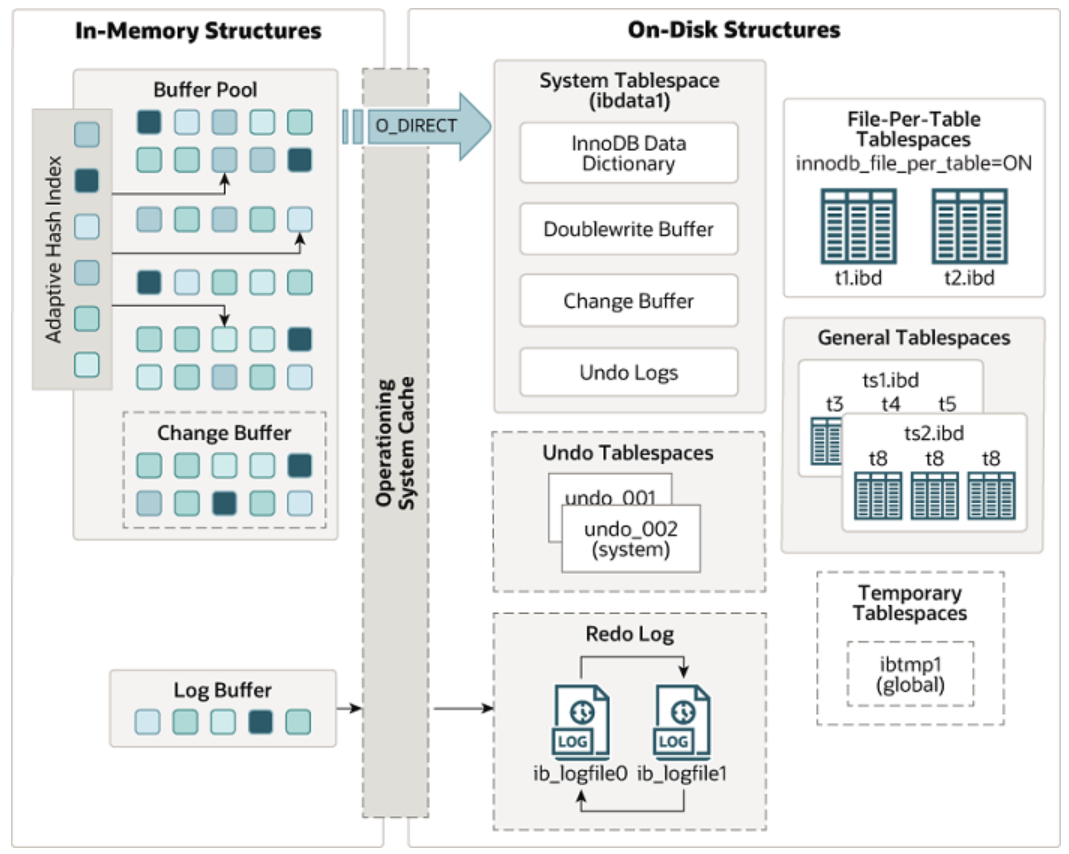
MySQL 的默认存储引擎是 InnoDB,它是一个健壮的事务型存储引擎,支持 ACID 事务。 所有数据都存储在表空间中,表空间可以包含多个数据文件和日志文件。 表数据以 B+树的索引结构存储,这为快速的数据访问提供了基础。
主键索引和非主键索引都是 B+树结构,其中非主键索引的叶子节点存储主键值,用于快速定位到具体的数据行。 B+树的每个节点可以存储更多的键值,这意味着相比 B 树,B+树的高度更低,查询效率更高。
InnoDB 通过行级锁定和 MVCC 机制来支持高并发的读写操作。 通过 Undo 日志来实现 MVCC,允许在不锁定资源的情况下读取历史数据版本。
TiKV 是 TiDB 的分布式存储层,它使用 RocksDB 作为其本地存储引擎,优化了写入性能和磁盘空间使用。 TiKV 将数据分散存储在多个节点上,通过 Raft 协议保证数据的强一致性和高可用性。
MVCC 版本控制:
TiKV 使用 MVCC 机制来处理并发控制和历史数据版本,每个事务都会获取一个全局唯一的时间戳(TS)作为版本号。 通过这种方式,TiKV 可以支持同一时间点的多个事务读取到一致的数据快照。
主键数据存储格式为tablePrefix{tableID}_recordPrefixSep{Col1},其中Value包含了行数据的所有列值。 唯一索引的存储格式为tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue,Value为对应的行 ID。 非唯一索引的存储格式与唯一索引类似,但每个索引值后附加行 ID,Value可能为null。
TiKV 的存储层设计为易于扩展,可以水平扩展以适应不断增长的数据量。 通过 Raft 协议,TiKV 能够在多个副本之间同步数据,提高了数据的可用性和容错能力。
3.2.3 存储层对比总结
扩展性:TiDB 的 TiKV 存储层设计为分布式,易于水平扩展,而 MySQL 的 InnoDB 存储引擎通常需要垂直扩展。 并发控制:TiDB 使用 MVCC 和 TSO(Timestamp Ordering)来实现并发控制,而 MySQL 使用行级锁定和 MVCC。 数据一致性:TiKV 通过 Raft 协议保证跨多个节点的数据一致性,InnoDB 则依赖于单个服务器的事务日志和恢复机制。 存储效率:TiKV 的 RocksDB 存储引擎优化了写入性能和压缩,而 InnoDB 的 B+树结构优化了读取性能。
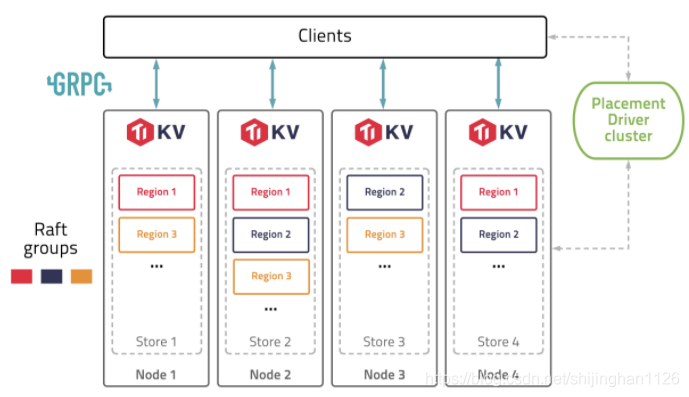
3.3.1 MySQL 索引实现
MySQL 的索引基于 B+树结构,这是一种自平衡树,优化了读写性能和空间使用。 B+树的所有数据都存储在叶子节点,内部节点仅存储键值和指向子节点的指针,这减少了查找过程中的磁盘 I/O 操作。
主键索引是聚簇索引,非主键索引是二级索引。聚簇索引的叶子节点直接包含行数据,而非主键索引的叶子节点包含主键值,用于快速跳转到聚簇索引。
非主键索引的叶子节点不直接存储行数据,而是存储对应的主键值。查询时,需要通过主键值回表查询,访问聚簇索引以获取完整的行数据。
B+树结构减少了查询过程中的 I/O 操作次数,提高了数据访问速度。 聚簇索引和非聚簇索引的设计,优化了数据的物理存储,减少了冗余和空间使用。
TiDB 的索引基于键值(Key-Value)存储模型实现。这种模型非常适合分布式环境,因为它允许数据的水平分割和分布式存储。
主键索引使用行的主键值作为键,行数据的序列化形式作为值。例如,如果Col1是主键,则键可能表示为tablePrefix{tableID}_recordPrefixSep{Col1}。 这种映射允许 TiDB 通过主键值直接访问对应的行数据,提供了高效的数据检索。
唯一索引使用索引列的值作为键,行的主键值作为值。例如,键可能表示为tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue,值是对应的RowID。 这种设计确保了索引的唯一性,并且可以通过索引值快速定位到具体的数据行。
非唯一索引与唯一索引类似,但允许同一个键对应多个值。在这种情况下,键仍然是索引列的值,但值是包含RowID的列表。 这允许 TiDB 处理具有相同索引值的多行数据。
TiDB 的索引实现简化了分布式环境下的数据访问,通过键值对直接映射,提高了查询效率。 由于 TiDB 的存储层 TiKV 使用 RocksDB,索引数据也被优化存储,以减少磁盘空间的使用。
数据访问方式:TiDB 通过键值对直接映射数据,而 MySQL 通过 B+树结构进行索引。 分布式适应性:TiDB 的索引实现更适合分布式环境,易于水平扩展。MySQL 的 B+树索引则优化了单个服务器上的数据访问。 查询效率:TiDB 的索引实现允许快速的数据检索,特别是在分布式查询中。MySQL 的 B+树索引通过减少 I/O 操作提高了查询效率。 存储优化:TiDB 的 RocksDB 存储引擎优化了索引数据的存储,而 MySQL 的 B+树结构减少了索引的存储空间需求。
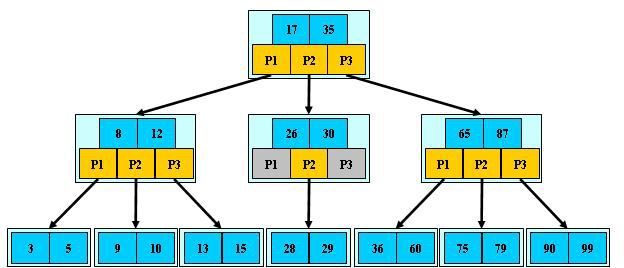
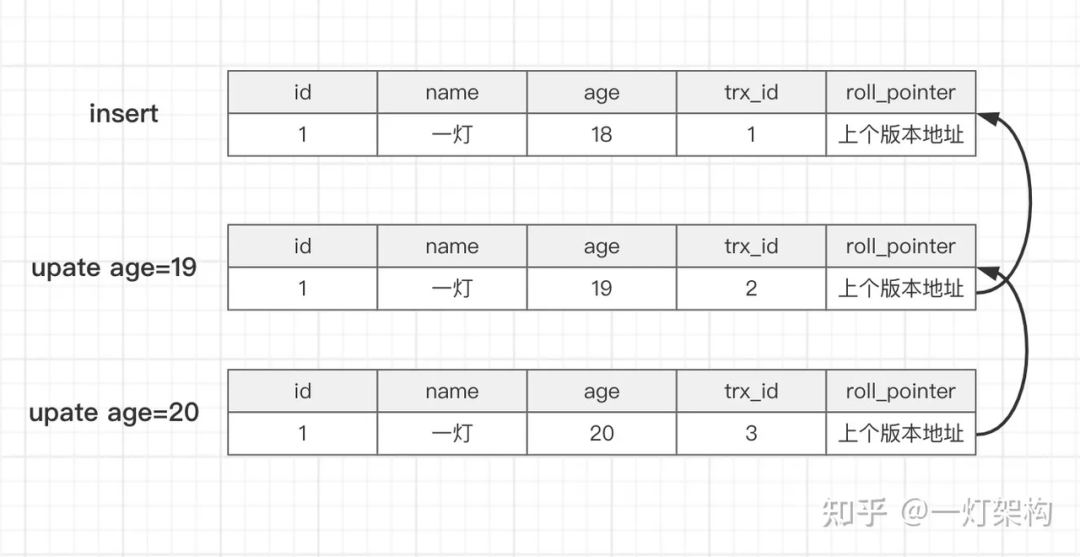
3.4.1 MySQL 事务处理和 MVCC
MySQL 的 InnoDB 存储引擎支持 ACID(原子性、一致性、隔离性、持久性)事务。 InnoDB 使用行级锁定机制来处理并发写入,确保事务的隔离性。
InnoDB 通过 Undo Log 来实现 MVCC,允许在不锁定资源的情况下读取历史数据版本。 Undo Log 记录了数据在事务开始前的状态,这样即使在其他事务修改了数据之后,当前事务仍然可以读取到事务开始前的数据状态。 InnoDB 的 MVCC 主要通过 Read View 来实现,Read View 是一个快照,包含了在事务开始时所有已提交的数据的可见性信息。
InnoDB 主要使用悲观锁,通过行锁和表锁来处理数据的并发访问,防止数据的不一致性。 行锁在 SELECT ... FOR UPDATE 或 INSERT/UPDATE/DELETE 操作时自动加锁,以保证事务的原子性和隔离性。 表锁在某些特定的操作,如全表扫描或某些类型的索引操作中使用。
3.4.2 TiDB 事务处理和 MVCC
TiDB 支持两种类型的锁:乐观锁和悲观锁,以适应不同的业务场景。 乐观锁:适用于写冲突较少的环境,通过检测在事务开始后数据是否被其他事务修改来避免锁的争用。如果检测到冲突,事务会进行重试。 悲观锁:适用于高冲突环境,通过在事务开始时就锁定涉及的数据行,防止其他事务修改这些数据。
TiDB 采用 MVCC 机制来提供在不锁定资源的情况下读取历史数据版本的能力,从而提高并发性能。 MVCC 通过为每个事务分配一个全局唯一的时间戳(TS),并使用这个时间戳来确定数据的可见性。 在 TiDB 中,每个数据行都保存了多个版本,每个版本都有一个开始和结束的时间戳。查询操作会根据当前事务的时间戳来确定应该读取哪个版本的数据。
锁机制:TiDB 支持乐观锁和悲观锁,提供了更灵活的锁策略,而 MySQL 主要使用悲观锁。 MVCC 实现:TiDB 使用时间戳和版本控制来实现 MVCC,而 InnoDB 使用 Undo Log 和 Read View。 并发性能:TiDB 的 MVCC 机制通过减少锁的争用来提高并发性能,特别是在高并发读写的场景下。InnoDB 的 MVCC 通过 Undo Log 减少锁的使用,但在高冲突环境下可能仍然会遇到锁争用。 历史数据访问:TiDB 和 InnoDB 都允许在不锁定资源的情况下访问历史数据版本,提高了系统的并发读取能力。
通过这种详细的事务和 MVCC 机制对比,我们可以更深入地理解 TiDB 和 MySQL 在事务处理和并发控制方面的差异,以及它们如何适应不同的业务场景和性能需求。
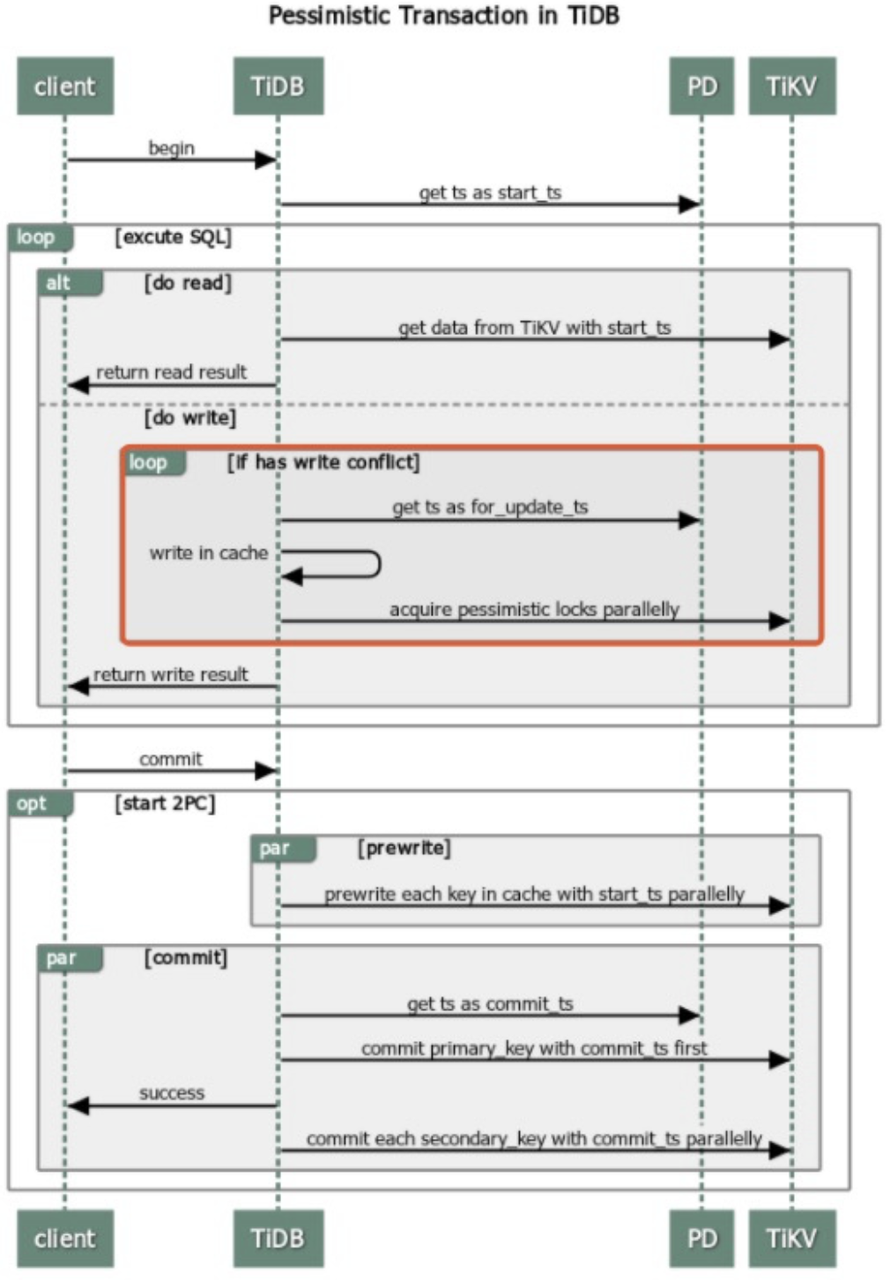

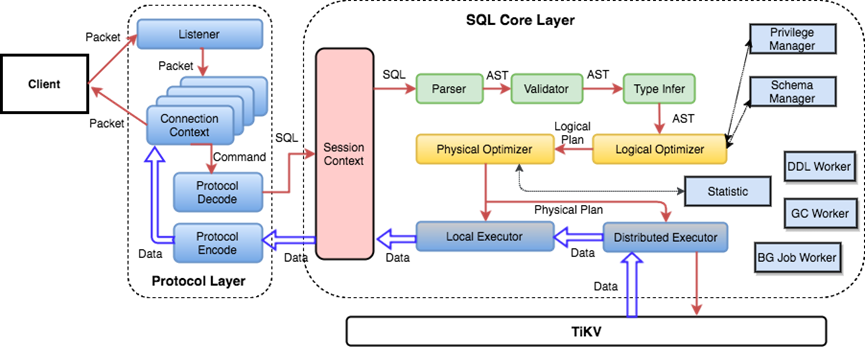
TiDB SQL 执行:分布式环境中,SQL 执行涉及多个组件和步骤,包括索引使用、存储引擎选择等。 性能分析工具:使用EXPLAIN和EXPLAIN ANALYZE分析 SQL 执行计划和实际执行情况。
explain yoursql;
explain analyze yoursql; //真实执行
TiDB 分区:支持多种分区类型,如 Range、List 和 Hash 分区,简化数据管理并提高查询效率。 分区表分析:自动分析分区数据分布,优化查询计划。
/*查看分区的数据分布*/
SHOW STATS_META where table_name = "table_demo";
/*从分区直接查询数据*/
CREATE TABLE table_demo (
`id` bigint(20) primary key auto_random,
start_time timestamp(3)
) PARTITION BY RANGE (FLOOR(UNIX_TIMESTAMP(`start_time`)))
SELECT * FROM table_demo PARTITION (p1) where xxx;
/* 新增分区 */
ALTER TABLE table_demo ADD PARTITION(PATITION p2 VALUES LESS THAN ( FLOOR(UNIX_TIMESTAMP(`start_time`))
/* 删除分区 */
ALTER TABLE table_demo drop partition p1
- 分区表的说明:
show variables like '%tidb_auto_analyze_end_time%';set global tidb_auto_analyze_end_time = "06:00 +0000";
analysis table table_name; //分析表,有利于执行计划
3.5.3 列式存储 TiFlash
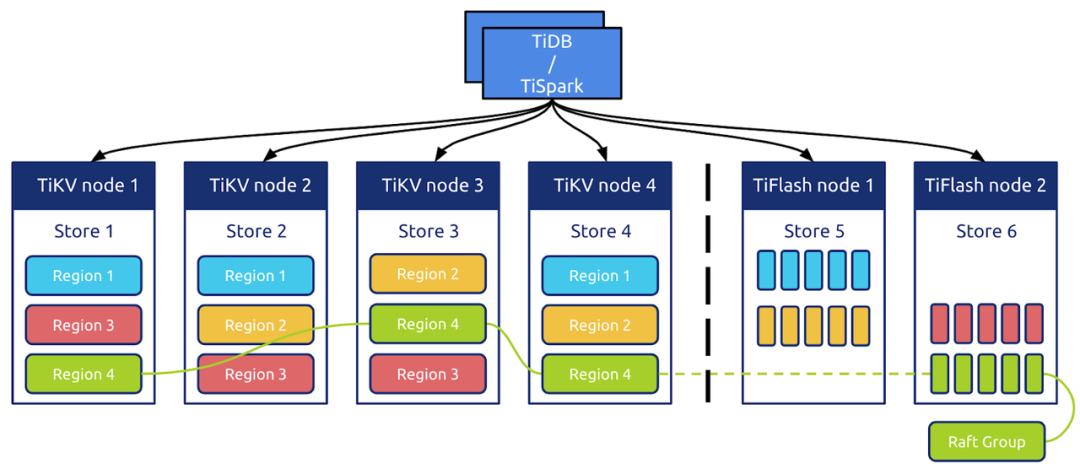
只需在 TiDB 做出一些设置,数据就可以从 TiKV->TiFlash 同步过去。
//增加 tiflash 副本
ALTER TABLE table_name SET TIFLASH REPLICA count;
//查看数据同步进度
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = '<db_name>' and TABLE_NAME = '<table_name>';
TiDB 可以根据表分析的情况综合索引信息和数据量,自动选择使用 TiFlash 或者 TiKV,也可以在 SQL 内指定使用的存储引擎,且支持多表。
select /*+ read_from_storage(tiflash[table_name]) */ ... from table_name;














文章转载自PingCAP,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
