




前言
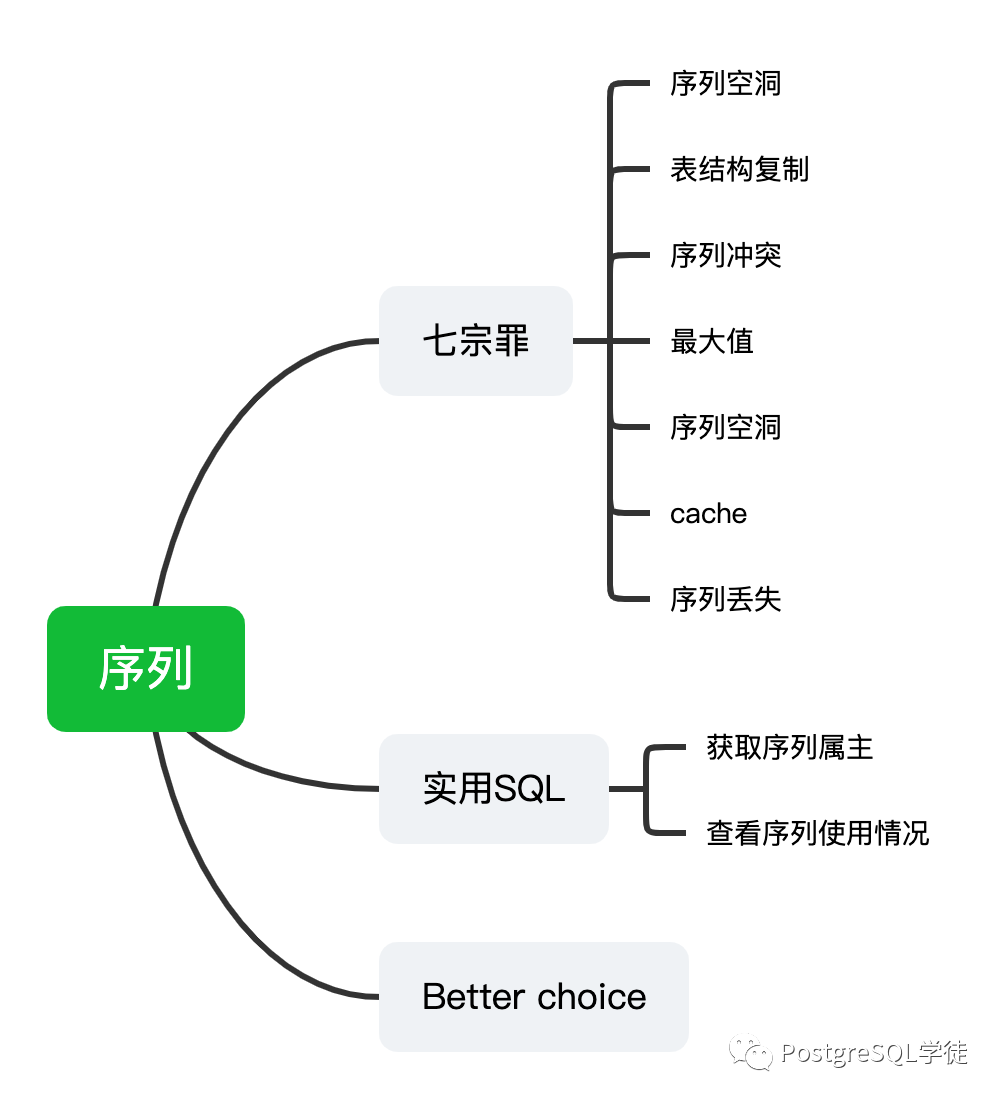
七宗罪
孤儿序列
postgres=# create table t1(id serial);
CREATE TABLE
postgres=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+--------------------------------+---------+-------------+--------------+-------------
id | integer | | not null | nextval('t1_id_seq'::regclass) | plain | | |
Access method: heap
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# create table t2(id int default nextval('myseq')); ---建表时指定nextval
CREATE TABLE
postgres=# \d+ t2
Table "public.t2"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+----------------------------+---------+-------------+--------------+-------------
id | integer | | | nextval('myseq'::regclass) | plain | | |
Access method: heap
postgres=# drop table t1;
DROP TABLE
postgres=# drop table t2;
DROP TABLE
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------+----------+----------
public | myseq | sequence | postgres
(1 row)
postgres=# SELECT ns.nspname AS schema_name, seq.relname AS seq_name
FROM pg_class AS seq
JOIN pg_namespace ns ON (seq.relnamespace=ns.oid)
WHERE seq.relkind = 'S'
AND NOT EXISTS (SELECT * FROM pg_depend WHERE objid=seq.oid AND deptype='a')
ORDER BY seq.relname;
schema_name | seq_name
-------------+----------
public | myseq
(1 row)
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# create table t2(id int default nextval('myseq'));
CREATE TABLE
postgres=# alter sequence myseq owned by t2.id;
ALTER SEQUENCE
postgres=# drop table t2;
DROP TABLE
postgres=# \d myseq ---序列已经一起删除
Did not find any relation named "myseq".
postgres=# select 'ALTER SEQUENCE '|| quote_ident(min(schema_name)) ||'.'|| quote_ident(min(seq_name))
||' OWNED BY '|| quote_ident(min(table_name)) ||'.'|| quote_ident(min(column_name)) ||';'
from (
select
n.nspname as schema_name,
c.relname as table_name,
a.attname as column_name,
substring(d.adsrc from E'^nextval\\(''([^'']*)''(?:::text|::regclass)?\\)') as seq_name
from pg_class c
join pg_attribute a on (c.oid=a.attrelid)
join pg_attrdef d on (a.attrelid=d.adrelid and a.attnum=d.adnum)
join pg_namespace n on (c.relnamespace=n.oid)
where has_schema_privilege(n.oid,'USAGE')
and n.nspname not like 'pg!_%' escape '!'
and has_table_privilege(c.oid,'SELECT')
and (not a.attisdropped)
and d.adsrc ~ '^nextval'
) seq
group by seq_name having count(*)=1;
ERROR: column d.adsrc does not exist
LINE 8: substring(d.adsrc from E'^nextval\\(''([^'']*)''(?::... ---会报错
^
postgres=# select 'ALTER SEQUENCE '|| quote_ident(min(schema_name)) ||'.'|| quote_ident(min(seq_name))
||' OWNED BY '|| quote_ident(min(table_name)) ||'.'|| quote_ident(min(column_name)) ||';'
from (
select
n.nspname as schema_name,
c.relname as table_name,
a.attname as column_name,
substring(pg_get_expr(d.adbin, d.adrelid) from E'^nextval\\(''([^'']*)''(?:::text|::regclass)?\\)') as seq_name
from pg_class c
join pg_attribute a on (c.oid=a.attrelid)
join pg_attrdef d on (a.attrelid=d.adrelid and a.attnum=d.adnum)
join pg_namespace n on (c.relnamespace=n.oid)
where has_schema_privilege(n.oid,'USAGE')
and n.nspname not like 'pg!_%' escape '!'
and has_table_privilege(c.oid,'SELECT')
and (not a.attisdropped)
and pg_get_expr(d.adbin, d.adrelid) ~ '^nextval'
) seq
group by seq_name having count(*)=1;
?column?
-------------------------------------------------
ALTER SEQUENCE public.t1_id_seq OWNED BY t1.id;
(1 row)
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# create table t2(id int default nextval('myseq'));
CREATE TABLE
postgres=# alter sequence myseq owned by t2.id;
ALTER SEQUENCE
postgres=# alter table t2 drop column id;
ALTER TABLE
postgres=# \d myseq
Did not find any relation named "myseq".
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# create table t2(id int default nextval('myseq'));
CREATE TABLE
postgres=# alter sequence myseq owned by t2.id; ---即使指定了owned by
ALTER SEQUENCE
postgres=# alter table t2 alter column id drop default ;
ALTER TABLE
postgres=# \d myseq
Sequence "public.myseq"
Type | Start | Minimum | Maximum | Increment | Cycles? | Cache
--------+-------+---------+---------------------+-----------+---------+-------
bigint | 1 | 1 | 9223372036854775807 | 1 | no | 1
Owned by: public.t2.id
复制表结构
postgres=# create table t1(id serial,info text);
CREATE TABLE
postgres=# create table t2 (like t1 including all);
CREATE TABLE
postgres=# \d t2
Table "public.t2"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+--------------------------------
id | integer | | not null | nextval('t1_id_seq'::regclass)
info | text | | |
postgres=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+--------------------------------
id | integer | | not null | nextval('t1_id_seq'::regclass)
info | text | | |
postgres=# drop table t1; ---t2表还依赖序列
ERROR: cannot drop table t1 because other objects depend on it
DETAIL: default value for column id of table t2 depends on sequence t1_id_seq ---报错提示很明显
HINT: Use DROP ... CASCADE to drop the dependent objects too.
序列冲突
postgres=# create table t3(id serial primary key,info text);
CREATE TABLE
postgres=# insert into t3 values(1,'hello') returning *;
id | info
----+-------
1 | hello
(1 row)
INSERT 0 1
postgres=# insert into t3 values(2,'world') returning *;
id | info
----+-------
2 | world
(1 row)
INSERT 0 1
postgres=# insert into t3(info) values('postgres') returning *;
ERROR: duplicate key value violates unique constraint "t3_pkey"
DETAIL: Key (id)=(1) already exists.
Other databases, such as Informix, explicitly prohibit it. However, in PostgreSQL an autoincrement value is really just a sequence which adds a default value.
pg_sequence_fixer will loop over all sequences created by serials and make sure that they are set to a value that is in sync with the data. We set a value high enough to avoid trouble. Two modes are available: With table and without table locking. Not going for table locking risks changes while your sequences are fixed. Turning locking on can lead to troubles due to (potentially) long periods of table locking.
CREATE FUNCTION pg_sequence_fixer (IN v_margin int, IN v_lock_mode boolean DEFAULT FALSE)
RETURNS void
AS $$
DECLARE
v_rec RECORD;
v_sql text;
v_max int8;
BEGIN
IF v_margin IS NULL THEN
RAISE NOTICE 'the safety margin will be set to 1';
v_margin := 1;
END IF;
IF v_margin < 1 THEN
RAISE WARNING 'a negative safety margin is used';
END IF;
FOR v_rec IN
SELECT
d.objid::regclass,
d.refobjid::regclass,
a.attname
FROM
pg_depend AS d
JOIN pg_class AS t ON d.objid = t.oid
JOIN pg_attribute AS a ON d.refobjid = a.attrelid
AND d.refobjsubid = a.attnum
WHERE
d.classid = 'pg_class'::regclass
AND d.refclassid = 'pg_class'::regclass
AND t.oid >= 16384
AND t.relkind = 'S'
AND d.deptype IN ('a', 'i')
LOOP
IF v_lock_mode = TRUE THEN
v_sql := 'LOCK TABLE ' || v_rec.refobjid::regclass || ' IN EXCLUSIVE MODE';
RAISE NOTICE 'locking: %', v_rec.refobjid::regclass;
EXECUTE v_sql;
END IF;
v_sql := 'SELECT setval(' || quote_literal(v_rec.objid::regclass) || '::text, max(' || quote_ident(v_rec.attname::text) || ') + ' || v_margin || ') FROM ' || v_rec.refobjid::regclass;
EXECUTE v_sql INTO v_max;
RAISE NOTICE 'setting sequence for % to %', v_rec.refobjid::text, v_max;
END LOOP;
RETURN;
END;
$$
LANGUAGE 'plpgsql';
postgres=# select pg_sequence_fixer('100','t');
NOTICE: locking: t1
NOTICE: setting sequence for t1 to <NULL>
NOTICE: locking: t3
NOTICE: setting sequence for t3 to 102
pg_sequence_fixer
-------------------
(1 row)
postgres=# SELECT 'SELECT SETVAL(' ||
quote_literal(quote_ident(PGT.schemaname) || '.' || quote_ident(S.relname)) ||
', COALESCE(MAX(' ||quote_ident(C.attname)|| '), 1) ) FROM ' ||
quote_ident(PGT.schemaname)|| '.'||quote_ident(T.relname)|| ';'
FROM pg_class AS S,
pg_depend AS D,
pg_class AS T,
pg_attribute AS C,
pg_tables AS PGT
WHERE S.relkind = 'S'
AND S.oid = D.objid
AND D.refobjid = T.oid
AND D.refobjid = C.attrelid
AND D.refobjsubid = C.attnum
AND T.relname = PGT.tablename
ORDER BY S.relname;
?column?
--------------------------------------------------------------------------
SELECT SETVAL('public.t1_id_seq', COALESCE(MAX(id), 1) ) FROM public.t1;
(1 row)
postgres=# create table t1(id serial primary key,info text);
CREATE TABLE
postgres=# insert into t1 values(1,'hello');
INSERT 0 1
postgres=# insert into t1 values(2,'world');
INSERT 0 1
postgres=# insert into t1(info) values('postgres');
ERROR: duplicate key value violates unique constraint "t1_pkey"
DETAIL: Key (id)=(1) already exists.
postgres=# SELECT SETVAL('public.t1_id_seq', COALESCE(MAX(id), 1) ) FROM public.t1; ---修复一下
setval
--------
2
(1 row)
postgres=# insert into t1(info) values('postgres');
INSERT 0 1
postgres=# select * from t1;
id | info
----+----------
1 | hello
2 | world
3 | postgres
(3 rows)
最大值
create sequence tbl_tbl_id_seq;
alter table tbl alter column tbl_id set default nextval('tbl_tbl_id_seq');
alter sequence tbl_tbl_id_seq owned by tbl.tbl_id;
select setval('tbl_tbl_id_seq', coalesce(max(tbl_id), 0)) from tbl;
postgres=# create table t1(id serial);
CREATE TABLE
postgres=# alter table t1 alter COLUMN id type bigserial;
ERROR: type "bigserial" does not exist
postgres=# alter table t1 alter COLUMN id type bigint;
ALTER TABLE
postgres=# select pg_relation_filepath('t1');
pg_relation_filepath
----------------------
base/13892/32796
(1 row)
postgres=# alter table t1 alter COLUMN id type bigint;
ALTER TABLE
postgres=# select pg_relation_filepath('t1');
pg_relation_filepath
----------------------
base/13892/32801
(1 row)
序列空洞
postgres=# create table t(id serial,info text);
CREATE TABLE
postgres=# insert into t(info) values('hello');
INSERT 0 1
postgres=# begin;
BEGIN
postgres=*# insert into t(info) values('hello');
INSERT 0 1
postgres=*# rollback ;
ROLLBACK
postgres=# insert into t(info) values('hello');
INSERT 0 1
postgres=# select * from t;
id | info
----+-------
1 | hello
3 | hello
(2 rows)
To avoid blocking concurrent transactions that obtain numbers from the same sequence, the value obtained by nextval
is not reclaimed for re-use if the calling transaction later aborts. This means that transaction aborts or database crashes can result in gaps in the sequence of assigned values. That can happen without a transaction abort, too. For example anINSERT
with anON CONFLICT
clause will compute the to-be-inserted tuple, including doing any requirednextval
calls, before detecting any conflict that would cause it to follow theON CONFLICT
rule instead. Thus, PostgreSQL sequence objects cannot be used to obtain “gapless” sequences.Likewise, sequence state changes made by setval
are immediately visible to other transactions, and are not undone if the calling transaction rolls back.If the database cluster crashes before committing a transaction containing a nextval
orsetval
call, the sequence state change might not have made its way to persistent storage, so that it is uncertain whether the sequence will have its original or updated state after the cluster restarts. This is harmless for usage of the sequence within the database, since other effects of uncommitted transactions will not be visible either. However, if you wish to use a sequence value for persistent outside-the-database purposes, make sure that thenextval
call has been committed before doing so.
cache的影响
The optional clause CACHE *
cache*
specifies how many sequence numbers are to be preallocated and stored in memory for faster access. The minimum value is 1 (only one value can be generated at a time, i.e., no cache), and this is also the default.
postgres=# create sequence myseq start with 100 increment by 1 cache 20;
CREATE SEQUENCE
postgres=# select nextval('myseq');
nextval
---------
100
(1 row)
postgres=# select nextval('myseq');
nextval
---------
120
(1 row)
postgres=# select nextval('myseq');
nextval
---------
101
(1 row)
序列丢失
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# select * from myseq ;
last_value | log_cnt | is_called
------------+---------+-----------
1 | 0 | f
(1 row)
typedef struct FormData_pg_sequence_data
{
int64 last_value;
int64 log_cnt;
bool is_called;
} FormData_pg_sequence_data;
typedef FormData_pg_sequence_data *Form_pg_sequence_data;
postgres=# select nextval('myseq');
nextval
---------
1
(1 row)
postgres=# select * from myseq ;
last_value | log_cnt | is_called
------------+---------+-----------
1 | 32 | t
(1 row)
postgres=# select nextval('myseq');
nextval
---------
2
(1 row)
postgres=# select * from myseq ;
last_value | log_cnt | is_called
------------+---------+-----------
2 | 32 | t
(1 row)
postgres=# select nextval('myseq');
nextval
---------
3
(1 row)
postgres=# select * from myseq ;
last_value | log_cnt | is_called
------------+---------+-----------
3 | 31 | t
(1 row)
• SELECT setval('myseq', 42); ,下一个值就是43
• SELECT setval('myseq', 42, true); 和上一个一样
• SELECT setval('myseq', 42, false); 下一个值是42
/*
* We don't want to log each fetching of a value from a sequence,
* so we pre-log a few fetches in advance. In the event of
* crash we can lose (skip over) as many values as we pre-logged.
*/
#define SEQ_LOG_VALS 32
/*
* We don't log the current state of the tuple, but rather the state
* as it would appear after "log" more fetches. This lets us skip
* that many future WAL records, at the cost that we lose those
* sequence values if we crash.
*/
XLogBeginInsert();
XLogRegisterBuffer(0, buf, REGBUF_WILL_INIT);
/* set values that will be saved in xlog */
seq->last_value = next;
seq->is_called = true;
seq->log_cnt = 0;
postgres=# create sequence myseq;
CREATE SEQUENCE
postgres=# select nextval('myseq');
nextval
---------
1
(1 row)
postgres=# select nextval('myseq');
nextval
---------
2
(1 row)
postgres=# select * from myseq;
last_value | log_cnt | is_called
------------+---------+-----------
2 | 31 | t
(1 row)
postgres=# \q
[postgres@xiongcc ~]$ pg_ctl -D pgdata/ restart -mi
waiting for server to shut down.... done
server stopped
waiting for server to start....2022-06-12 11:39:55.796 CST [19148] LOG: redirecting log output to logging collector process
2022-06-12 11:39:55.796 CST [19148] HINT: Future log output will appear in directory "log".
done
server started
[postgres@xiongcc ~]$ psql
psql (14.2)
Type "help" for help.
postgres=# select nextval('myseq');
nextval
---------
34
(1 row)
postgres=# select * from myseq;
last_value | log_cnt | is_called
------------+---------+-----------
36 | 30 | t
(1 row)
postgres=# checkpoint ;
CHECKPOINT
postgres=# select * from myseq;
last_value | log_cnt | is_called
------------+---------+-----------
36 | 30 | t
(1 row)
postgres=# select nextval('myseq');
nextval
---------
37
(1 row)
postgres=# select * from myseq; ---重置为32
last_value | log_cnt | is_called
------------+---------+-----------
37 | 32 | t
(1 row)
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/0400B040, prev 0/0400B008, desc: CHECKPOINT_ONLINE redo 0/400B008; tli 1; prev tli 1; fpw true; xid 0:852; oid 32768; multi 1; offset 0; oldest xid 726 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 852; online ---手动做的checkpoint
rmgr: Sequence len (rec/tot): 99/ 99, tx: 852, lsn: 0/0400B0B8, prev 0/0400B040, desc: LOG rel 1663/13892/24576, blkref #0: rel 1663/13892/24576 blk 0 ---记录了wal
实用SQL
获取序列属主
postgres=# SELECT seqclass.relname AS sequence_name,
seqclass.relfilenode AS sequenceref,
dep.refobjid AS depobjref,
depclass.relname AS table_name
FROM pg_class AS seqclass
JOIN pg_sequence AS seq
ON ( seq.seqrelid = seqclass.relfilenode )
JOIN pg_depend AS dep
ON ( seq.seqrelid = dep.objid )
JOIN pg_class AS depclass
ON ( dep.refobjid = depclass.relfilenode );
sequence_name | sequenceref | depobjref | table_name
---------------+-------------+-----------+------------
t1_id_seq | 32811 | 32812 | t1
(1 row)
postgres=# SELECT seqclass.relname AS sequence_name,
depclass.relname AS table_name,
attrib.attname as column_name
FROM pg_class AS seqclass
JOIN pg_depend AS dep
ON ( seqclass.relfilenode = dep.objid )
JOIN pg_class AS depclass
ON ( dep.refobjid = depclass.relfilenode )
JOIN pg_attribute AS attrib
ON ( attrib.attnum = dep.refobjsubid
AND attrib.attrelid = dep.refobjid )
WHERE seqclass.relkind = 'S';
sequence_name | table_name | column_name
---------------+------------+-------------
t1_id_seq | t1 | id
(1 row)
postgres=# SELECT seqclass.relname AS sequence_name,
seqclass.relfilenode AS sequenceref,
dep.refobjid AS depobjref,
depclass.relname AS tabl_ename,
attrib.attname AS column_name
FROM pg_class AS seqclass
JOIN pg_sequence AS seq
ON ( seq.seqrelid = seqclass.relfilenode )
JOIN pg_depend AS dep
ON ( seq.seqrelid = dep.objid )
JOIN pg_class AS depclass
ON ( dep.refobjid = depclass.relfilenode )
JOIN pg_attribute AS attrib
ON ( attrib.attnum = dep.refobjsubid
AND attrib.attrelid = dep.refobjid );
sequence_name | sequenceref | depobjref | tabl_ename | column_name
---------------+-------------+-----------+------------+-------------
t1_id_seq | 32811 | 32812 | t1 | id
(1 row)
获取序列使用情况
CREATE OR REPLACE FUNCTION seq_check ()
RETURNS TABLE (
seq_name text,
current_value bigint,
lim bigint,
remaining bigint
)
AS $CODE$
DECLARE
query text;
schemaz name;
seqz name;
seqid oid;
BEGIN
FOR schemaz,
seqz,
seqid IN
SELECT
n.nspname,
c.relname,
c.oid
FROM
pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE
c.relkind = 'S' --sequence
LOOP
RAISE DEBUG 'Inspecting %.%', schemaz, seqz;
query := format('SELECT ''%s.%s'', last_value, s.seqmax AS lim, (s.seqmax - last_value) / s.seqincrement AS remaining FROM %I.%I, pg_sequence s WHERE s.seqrelid = %s', quote_ident(schemaz), quote_ident(seqz), schemaz, seqz, seqid);
RAISE DEBUG 'Query [%]', query;
RETURN QUERY EXECUTE query;
END LOOP;
END $CODE$ LANGUAGE plpgsql STRICT;
postgres=# select * from seq_check();
seq_name | current_value | lim | remaining
-----------------------------------+---------------+------------+------------
public.t_norm_pk_seq | 1000000 | 2147483647 | 2146483647
public.deps_saved_ddl_deps_id_seq | 8 | 2147483647 | 2147483639
(2 rows)
Better choice
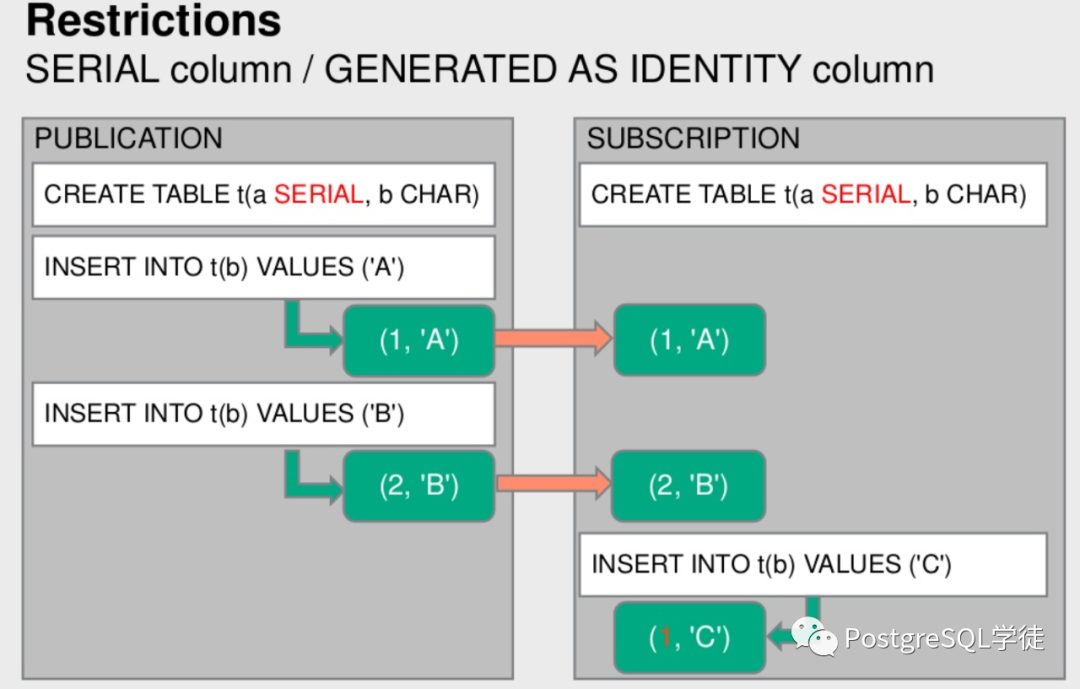
Identity columns This is the SQL standard-conforming variant of PostgreSQL's serial columns. It fixes a few usability issues that serial columns have:
• CREATE TABLE LIKE copies default but refers to same sequence
复制表结构但序列依旧指向同一个
• cannot add/drop serialness with ALTER TABLE
不能使用alter table语法增加serial类型
• dropping default does not drop sequence
删除default列并不会删除序列
• need to grant separate privileges to sequence
序列需要单独授权
• other slight weirdnesses because serial is some kind of special macro
postgres=# \d test_new
Table "public.test_new"
Column | Type | Collation | Nullable | Default
---------+---------+-----------+----------+----------------------------------
id | integer | | not null | generated by default as identity
payload | text | | |
Indexes:
"test_new_pkey" PRIMARY KEY, btree (id)
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------------+----------+----------
public | t1 | table | postgres
public | t1_id_seq | sequence | postgres
public | test_new | table | postgres
public | test_new_id_seq | sequence | postgres
(4 rows)
postgres=# CREATE table test_new_2 (
postgres(# id int generated always AS IDENTITY primary key,
postgres(# payload text
postgres(# );
CREATE TABLE
postgres=# insert into test_new_2 (payload) values ('a'), ('b'), ('c') returning *;
id | payload
----+---------
1 | a
2 | b
3 | c
(3 rows)
INSERT 0 3
postgres=# update test_new_2 set id = 4 where id = 3 returning *;
ERROR: column "id" can only be updated to DEFAULT
DETAIL: Column "id" is an identity column defined as GENERATED ALWAYS.
postgres=# insert into test_new_2 (id,payload) values(4,'d') returning *;
ERROR: cannot insert a non-DEFAULT value into column "id"
DETAIL: Column "id" is an identity column defined as GENERATED ALWAYS.
HINT: Use OVERRIDING SYSTEM VALUE to override.
postgres=# insert into test_new_2 (id,payload) OVERRIDING SYSTEM VALUE values(4,'d') returning *;
id | payload
----+---------
4 | d
(1 row)
INSERT 0 1
CREATE TABLE uses_identity (
id bigint GENERATED ALWAYS AS IDENTITY
PRIMARY KEY,
...
);
CREATE TABLE uses_identity (
id bigint GENERATED ALWAYS AS IDENTITY
(MINVALUE 0 START WITH 0 CACHE 20)
PRIMARY KEY,
...
);
• PostgreSQL10:Identity Columns 特性介绍
• postgresql-10-identity-columns
• waiting-for-postgresql-10-identity-columns
小结
1. 大型系统中,可能会存在很多孤儿序列,没有在用
2. 序列不是事务安全的,会浪费很多序列,导致空洞
3. 不能通过alter table添加或者删除serial类型,需要分两步
4. 序列还需要额外维护权限
5. 复制表结构,但是序列使用的是同一个
6. 删除default序列还会留存
bigserial是专有的 PostgreSQL 语法,这使代码更具可移植性。并且如果使用
GENERATED ALWAYS AS IDENTITY,如果尝试通过显式插入数字来覆盖生成的值,则会收到错误。这避免了手动输入的值会与稍后生成的值冲突的问题。
参考



文章转载自Bytebase,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
