




改善 Flow 的易用性:现在 Flow 的管理和元数据检查等操作变得更加容易;
增强数据备份功能:现在数据备份能力现在变得更加实用。
在过去的两周里,GreptimeDB 共合并了 87 个 PR,其中有 6 位独立贡献者,累计 6 个 PR 被成功合并,还有很多待合并的 PR。
@besrabasant (docs#1100)
@J0HN50N133 (db#4428)
@leaf-potato
(db#4427 db#4426 db#4412)
@realtaobo (db#4405)
db#4386 db#4416
在过去的两周里,我们专注于使 Flow 更易于使用。包括实现 SHOW FLOWS 子句:
public=> SHOW FLOWS;
Flows
----------------
filter_numbers
(1 row)
Information schema 中还有一个新的表 FLOWS 来显示 Flow 的元数据:
public=> select * from INFORMATION_SCHEMA.FLOWS;
flow_name | flow_id | catalog_name | raw_sql | comment | expire_after | source_table_ids | sink_table_name | flownode_ids | options
----------------+---------+--------------+-----------------------------------------------------------------------------------------------------------+---------+--------------+------------------+-----------------------------+--------------+---------
filter_numbers | 1024 | greptime | SELECT SUM(case WHEN `size` > 550::DOUBLE THEN 1::DOUBLE ELSE 0::DOUBLE END) as high_size_count FROM logs | | | [1024] | greptime.public.out_num_cnt | {"0":0} | {}
(1 row)
而在某些情况下我们需要手动触发更新,现在有了 flush_flow 函数可以帮助实现:
select flush_flow('test_numbers_df_func');
greptime cli export --help
Usage: greptime cli export [OPTIONS] --addr <ADDR> --output-dir <OUTPUT_DIR> --target <TARGET>
Options:
-t, --target <TARGET>
Things to export
Possible values:
- create-table: Corresponding to `SHOW CREATE TABLE`
- table-data: Corresponding to `EXPORT TABLE`
- database-data: Corresponding to `EXPORT DATABASE
同时,它也替代了旧的 table-data 目标选项。
copy table x from datasource with (start_time='2022-06-15 07:02:37', end_time='2022-06-15 07:02:38')
关键词:Cloud,Object Store
难度:中等
过多的小请求可能会导致昂贵的账单;我们可以对像 s3 这样的对象存储进行优化来减少不必要的开销。如果范围几乎是连续的,我们可以将这些范围合并成一个大块,并同时按首选大小获取这个大块。
点击下方链接🔗关注 GreptimeDB,了解更多技术干货👇
关于 Greptime
Greptime 格睿科技专注于为物联网、车联网及可观测等领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。
GreptimeDB 是一款用 Rust 语言编写的云原生开源时序数据库,支持指标,日志和事件等数据的联合分析,从边缘到云端,实时获取数据洞察。咨询 GreptimeDB 企业版请联系下方小助手微信。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,国内已在阿里云市场上线 边云一体解决方案 是一款深入物联网边缘端实际业务场景的协同数据解决方案,多模态边缘端数据库结合云端。
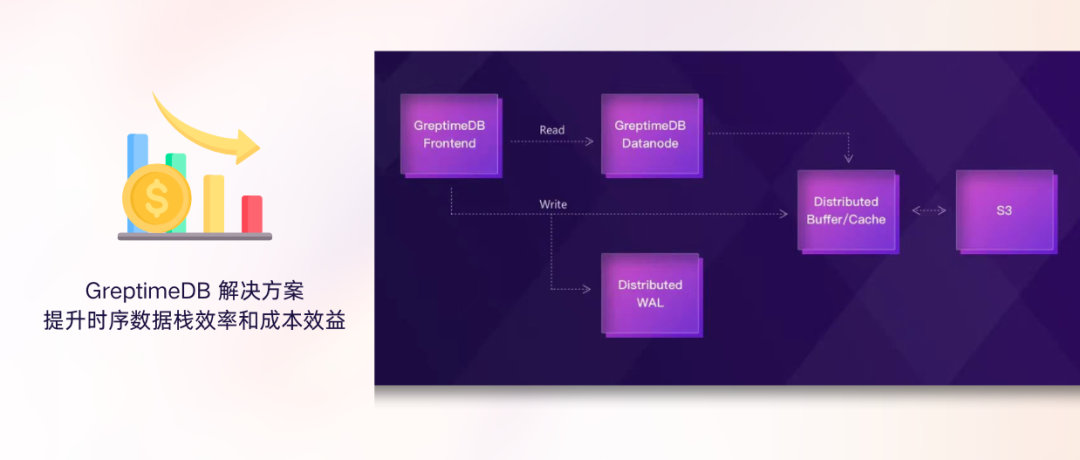
GreptimeDB 企业版 可极大降低流量、计算和存储成本,并提升数据实时性和业务洞察能力。
GreptimeCloud 是一款全托管的云上数据库即服务(DBaaS)解决方案,基于开源时序数据库 GreptimeDB 打造,能够高效支持可观测、物联网、金融等领域的应用。

Star us on GitHub Now:
https://github.com/GreptimeTeam/greptimedb
官网:https://greptime.cn/
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
往期精彩文章:


👇 点击下方阅读原文,立即体验 GreptimeDB!
