为了解决这个问题,本文设计了一个特定于RAG的多级动态缓存管理系统RAGCache。本文发现了两个系统优化的机会。首先,相同文档在多个请求中重复出现,使得此类文档的LLM推理中间状态 (Key Value tensors) 可以共享。其次,一小部分文档占了大多数检索请求。因此,缓存这些频繁访问的文档的中间状态,可以减轻计算负担。基于这个观察,RAG设计了一个知识树,它将检索到的文档的中间状态 (Key Value tensors) 适配到GPU和主机内存中。访问频率较高的文档缓存在快速的GPU内存中,访问频率较低的文档缓存在较慢的主机内存中。实验结果表明,与集成了Faiss的vLLM相比,RAGCache将TTFT时间降低了4倍,吞吐量提高了2.1倍。
2.核心方法
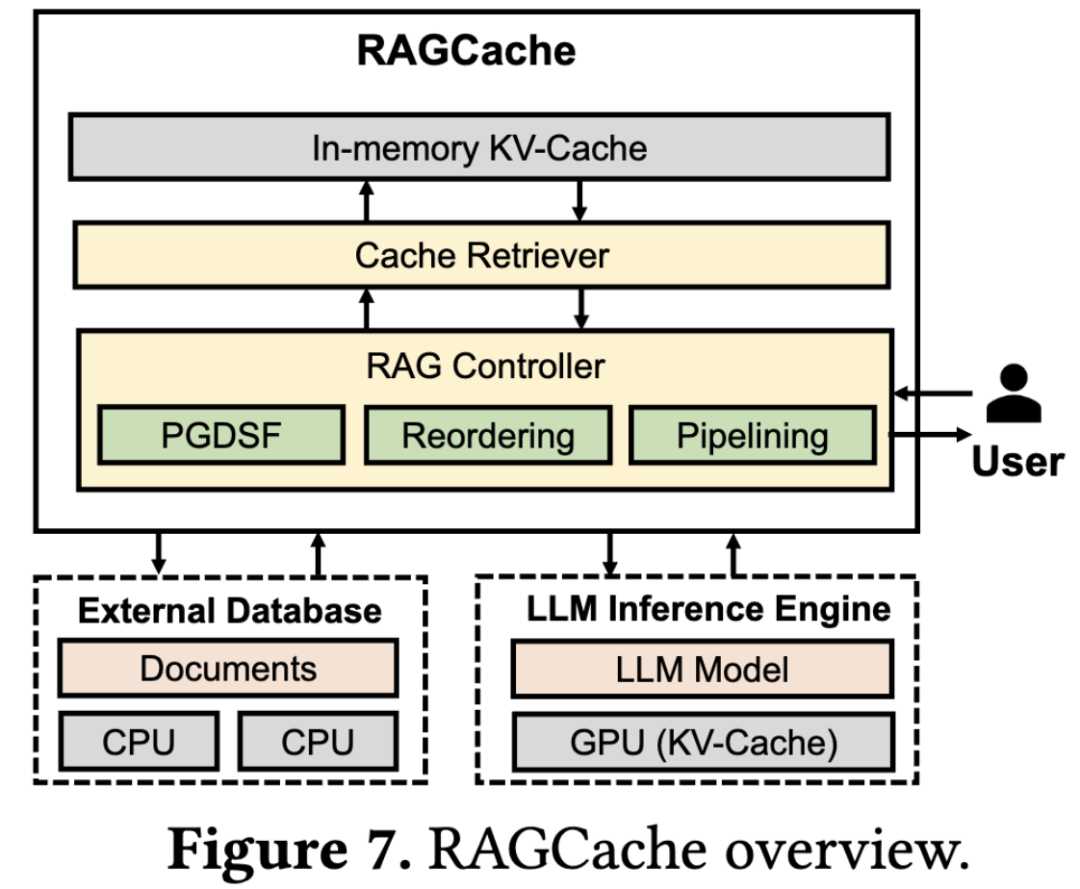
2.1 系统架构图
RAGCache架构如上图所示。当接收到一个用户请求时,RAG Controller首先从外部数据库 (External Database) 检索相关的文档。然后,这些文档被转发到Cache Retriever 以查找匹配的Key Value tensors。如果缓存中没有Key Value tensors,RAGCache会指示LLM推理引擎 (LLM Inference Engine) 生成新的tokens。相反,如果Key Value tensors可用,则带有Key Value tensors的请求将转发到LLM推理引擎,然后该引擎使用前缀缓存内核来生成标记。生成第一个标记后,Key Value tensors被转发回RAG Controller,该控制器Key Value tensors并刷新缓存的状态。最后,生成的答案作为响应传递给用户。
2.2 缓存结构和替换策略
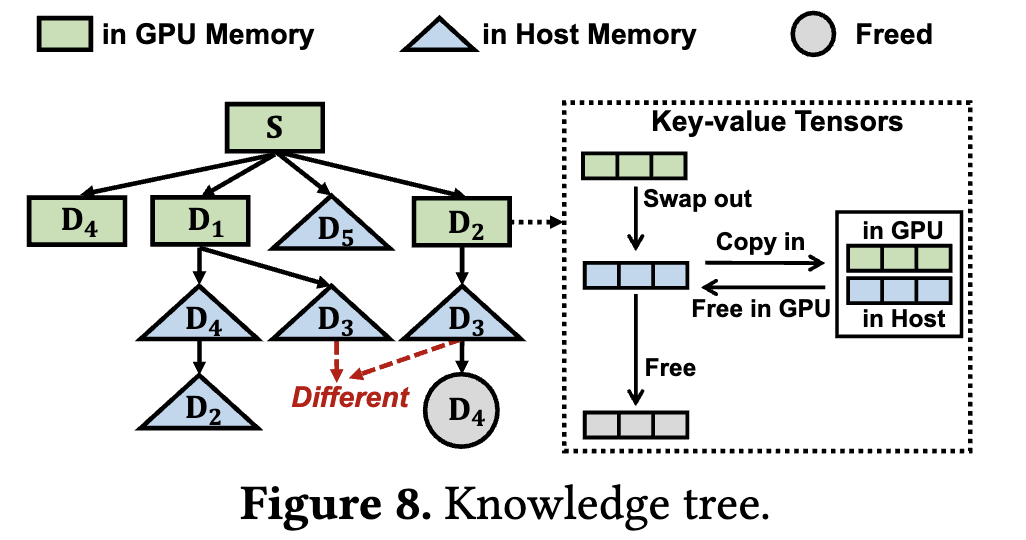
多个请求能够共享Key Value tensors的部分要求前缀相同,即必须保持相同的顺序。因此,为了在保持文档顺序的同时实现快速检索,RAGCache使用知识树来构建文档的键值张量,如下图所示。