




引言
压缩能力测评
数据准备
我们分别准备TPCH,NGSIM, server log 和 IJCAI-15 四种数据集,创建一个新的库size_test来进行测试:
create database size_test mode='auto';
使用基准测试程序TPC-H,TPC-H是业界常用的一套Benchmark,由TPC委员会制定发布,用于评测数据库的分析型查询能力。
create database tpch partition_mode = 'auto';use tpch;CREATE TABLE `customer` (`c_custkey` int(11) NOT NULL,`c_name` varchar(25) NOT NULL,`c_address` varchar(40) NOT NULL,`c_nationkey` int(11) NOT NULL,`c_phone` varchar(15) NOT NULL,`c_acctbal` decimal(15,2) NOT NULL,`c_mktsegment` varchar(10) NOT NULL,`c_comment` varchar(117) NOT NULL,PRIMARY KEY (`c_custkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(c_custkey) PARTITIONS 4;CREATE TABLE `lineitem` (`l_orderkey` int(11) NOT NULL,`l_partkey` int(11) NOT NULL,`l_suppkey` int(11) NOT NULL,`l_linenumber` int(11) NOT NULL,`l_quantity` decimal(15,2) NOT NULL,`l_extendedprice` decimal(15,2) NOT NULL,`l_discount` decimal(15,2) NOT NULL,`l_tax` decimal(15,2) NOT NULL,`l_returnflag` varchar(1) NOT NULL,`l_linestatus` varchar(1) NOT NULL,`l_shipdate` date NOT NULL,`l_commitdate` date NOT NULL,`l_receiptdate` date NOT NULL,`l_shipinstruct` varchar(25) NOT NULL,`l_shipmode` varchar(10) NOT NULL,`l_comment` varchar(44) NOT NULL,PRIMARY KEY (`l_shipdate`,`l_orderkey`,`l_linenumber`),KEY `i_l_partkey` (`l_partkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(l_orderkey) PARTITIONS 4;CREATE TABLE `nation` (`n_nationkey` int(11) NOT NULL,`n_name` varchar(25) NOT NULL,`n_regionkey` int(11) NOT NULL,`n_comment` varchar(152) DEFAULT NULL,PRIMARY KEY (`n_nationkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 broadcast;CREATE TABLE `orders` (`o_orderkey` int(11) NOT NULL,`o_custkey` int(11) NOT NULL,`o_orderstatus` varchar(1) NOT NULL,`o_totalprice` decimal(15,2) NOT NULL,`o_orderdate` date NOT NULL,`o_orderpriority` varchar(15) NOT NULL,`o_clerk` varchar(15) NOT NULL,`o_shippriority` int(11) NOT NULL,`o_comment` varchar(79) NOT NULL,PRIMARY KEY (`o_orderdate`,`o_orderkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(O_ORDERKEY) PARTITIONS 4;CREATE TABLE `part` (`p_partkey` int(11) NOT NULL,`p_name` varchar(55) NOT NULL,`p_mfgr` varchar(25) NOT NULL,`p_brand` varchar(10) NOT NULL,`p_type` varchar(25) NOT NULL,`p_size` int(11) NOT NULL,`p_container` varchar(10) NOT NULL,`p_retailprice` decimal(15,2) NOT NULL,`p_comment` varchar(23) NOT NULL,PRIMARY KEY (`p_partkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(p_partkey) PARTITIONS 4;CREATE TABLE `partsupp` (`ps_partkey` int(11) NOT NULL,`ps_suppkey` int(11) NOT NULL,`ps_availqty` int(11) NOT NULL,`ps_supplycost` decimal(15,2) NOT NULL,`ps_comment` varchar(199) NOT NULL,PRIMARY KEY (`ps_partkey`,`ps_suppkey`),KEY `IDX_PARTSUPP_SUPPKEY` (`PS_SUPPKEY`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(ps_partkey) PARTITIONS 4;CREATE TABLE `region` (`r_regionkey` int(11) NOT NULL,`r_name` varchar(25) NOT NULL,`r_comment` varchar(152) DEFAULT NULL,PRIMARY KEY (`r_regionkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 broadcast;CREATE TABLE `supplier` (`s_suppkey` int(11) NOT NULL,`s_name` varchar(25) NOT NULL,`s_address` varchar(40) NOT NULL,`s_nationkey` int(11) NOT NULL,`s_phone` varchar(15) NOT NULL,`s_acctbal` decimal(15,2) NOT NULL,`s_comment` varchar(101) NOT NULL,PRIMARY KEY (`s_suppkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 PARTITION BY HASH(s_suppkey) PARTITIONS 4;
点击链接下载TPC-H脚本工具包,下载地址:http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/183466/cn_zh/1645604888228/tpchData%20%281%29.tar.gz?spm=a2c4g.11186623.0.0.5e672386VqadsO&file=tpchData%20%281%29.tar.gz
tar xzvf tpchData.tar.gz
cd tpchData/vim param.conf
#!/bin/bash### remote generating directoryexport remoteGenDir=./### target pathexport targetPath=../tpch/tpchRaw### cores per worker, default value is 1export coresPerWorker=`cat proc/cpuinfo| grep "processor"| wc -l`### threads per worker, default value is 1export threadsPerWorker=`cat proc/cpuinfo| grep "processor"| wc -l`#export threadsPerWorker=1export hint=""export insertMysql="mysql -h{HOST} -P{PORT} -u{USER} -p{PASSWORD} -Ac --local-infile {DB} -e"
说明: 具体填入的值包括:
{HOST}:主机名
{PORT}:端口号
{USER}:用户名
{PASSWORD}:密码
{DB}: 数据库名
如果希望更高效地生成数据,可调大脚本中threadsPerWorker的值。
执行脚本,生成1 GB的数据:
cp workloads/tpch.workload.100.lst workloads/tpch.workload.1.lstcd datagensh generateTPCH.sh 100
可以在tpch/tpchRaw/SF1/目录下查看到生成的数据
ls ../tpch/tpchRaw/SF1/customer lineitem nation orders part partsupp region supplier
导入数据到PolarDB-X实例
cd ../loadTpchsh loadTpch.sh 1
检查数据完整性
select (select count(*) from customer) as customer_cnt,(select count(*) from lineitem) as lineitem_cnt,(select count(*) from nation) as nation_cnt,(select count(*) from orders) as order_cnt,(select count(*) from part) as part_cnt,(select count(*) from partsupp) as partsupp_cnt,(select count(*) from region) as region_cnt,(select count(*) from supplier) as supplier_cnt;+--------------+--------------+------------+-----------+----------+--------------+------------+--------------+| customer_cnt | lineitem_cnt | nation_cnt | order_cnt | part_cnt | partsupp_cnt | region_cnt | supplier_cnt |+--------------+--------------+------------+-----------+----------+--------------+------------+--------------+| 150000 | 6000737 | 25 | 1500000 | 200000 | 800000 | 5 | 10000 |+--------------+--------------+------------+-----------+----------+--------------+------------+--------------+
将导入数据转换到OSS存储引擎
create database oss_tpch partition_mode = 'auto';use oss_tpch;create table customer like tpch.customer engine='oss' archive_mode='loading';create table nation like tpch.nation engine='oss' archive_mode='loading';create table region like tpch.region engine='oss' archive_mode='loading';create table partsupp like tpch.partsupp engine='oss' archive_mode='loading';create table part like tpch.part engine='oss' archive_mode='loading';create table supplier like tpch.supplier engine='oss' archive_mode='loading';create table orders like tpch.orders engine='oss' archive_mode='loading';create table lineitem like tpch.lineitem engine='oss' archive_mode='loading';
后续我们会选取其中较大的orders表作为比较对象。
NGSIM测试集
官网下载数据集:https://data.transportation.gov/Automobiles/Next-Generation-Simulation-NGSIM-Vehicle-Trajector/8ect-6jqj/about_data
得到文件并存放在dataset目录下:
./dataset/Next_Generation_Simulation__NGSIM__Vehicle_Trajectories_and_Supporting_Data.csv
创建表
CREATE TABLE `ngsim` (`ID` int(11) NOT NULL AUTO_INCREMENT,`Vehicle_ID` int(11) NOT NULL,`Frame_ID` int(11) NOT NULL,`Total_Frames` int(11) NOT NULL,`Global_Time` bigint(20) NOT NULL,`Local_X` decimal(10, 3) NOT NULL,`Local_Y` decimal(10, 3) NOT NULL,`Global_X` decimal(15, 3) NOT NULL,`Global_Y` decimal(15, 3) NOT NULL,`v_length` decimal(10, 3) NOT NULL,`v_Width` decimal(10, 3) NOT NULL,`v_Class` int(11) NOT NULL,`v_Vel` decimal(10, 3) NOT NULL,`v_Acc` decimal(10, 3) NOT NULL,`Lane_ID` int(11) NOT NULL,`O_Zone` char(10) DEFAULT NULL,`D_Zone` char(10) DEFAULT NULL,`Int_ID` char(10) DEFAULT NULL,`Section_ID` char(10) DEFAULT NULL,`Direction` char(10) DEFAULT NULL,`Movement` char(10) DEFAULT NULL,`Preceding` int(11) NOT NULL,`Following` int(11) NOT NULL,`Space_Headway` decimal(10, 3) NOT NULL,`Time_Headway` decimal(10, 3) NOT NULL,`Location` char(10) NOT NULL,PRIMARY KEY (`ID`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4PARTITION BY KEY(`ID`)PARTITIONS 4
执行Load data语句进行数据导入,将数据导入到行存表 ngsim中
/*+TDDL:load_data_auto_fill_auto_increment_column=true*/load data local infile './dataset/Next_Generation_Simulation__NGSIM__Vehicle_Trajectories_and_Supporting_Data.csv' into table ngsim FIELDS TERMINATED BY ',' IGNORE 1 LINES (Vehicle_ID,Frame_ID,Total_Frames,Global_Time,Local_X,Local_Y,Global_X,Global_Y,v_length,v_Width,v_Class,v_Vel,v_Acc,Lane_ID,O_Zone,D_Zone,Int_ID,Section_ID,Direction,Movement,Preceding,Following,Space_Headway,Time_Headway,Location)
数据导入完成后,执行下列语句,进行冷数据一键迁移归档:
create table ngsim like sizetest.ngsim engine = 'oss' archive_mode = 'loading';
执行结果如下

ACCESS_LOG测试数据集
官网下载测试集:https://www.kaggle.com/datasets/eliasdabbas/web-server-access-logs
得到文件并存放在dataset目录下:
./dataset/access.log
创建行存表ACCESS_LOG:
CREATE TABLE `ACCESS_LOG` (`ID` int(11) NOT NULL AUTO_INCREMENT,`CONTENT` varchar(10000) DEFAULT NULL,PRIMARY KEY (`ID`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4PARTITION BY KEY(`ID`)PARTITIONS 4
执行Load data语句进行数据导入,将数据导入到行存表 ACCESS_LOG中:
/*+TDDL:load_data_auto_fill_auto_increment_column=true*/load data local infile './dataset/access.log' into table ACCESS_LOG FIELDS TERMINATED BY '\n' IGNORE 1 LINES (CONTENT)
数据导入完成后,执行下列语句,进行冷数据一键迁移归档:
create table ACCESS_LOG like sizetest.ACCESS_LOG engine = 'oss' archive_mode = 'loading';
执行结果如下:

IJCAI-15测试数据集
./dataset/user_log_format1.csv
创建行存表USER_LOG
CREATE TABLE `USER_LOG` (`ID` int(11) NOT NULL AUTO_INCREMENT,`USER_ID` int(11) NOT NULL,`ITEM_ID` int(11) NOT NULL,`CAT_ID` int(11) NOT NULL,`SELLER_ID` int(11) NOT NULL,`BRAND_ID` int(11) DEFAULT NULL,`TIME_STAMP` char(4) NOT NULL,`ACTION_TYPE` char(1) NOT NULL,PRIMARY KEY (`ID`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4PARTITION BY KEY(`ID`)PARTITIONS 4
执行Load data语句进行数据导入,将数据导入到行存表 USER_LOG中:
/*+TDDL:load_data_auto_fill_auto_increment_column=true*/load data local infile './dataset/user_log_format1.csv' into table user_log FIELDS TERMINATED BY ',' IGNORE 1 LINES (user_id,item_id,cat_id,seller_id,brand_id,time_stamp,action_type)
数据导入完成后,执行下列语句,进行冷数据一键迁移归档:
create table USER_LOG like sizetest.USER_LOG engine = 'oss' archive_mode = 'loading';
数据导入完成后,执行下列语句,进行冷数据一键迁移归档:
create table USER_LOG like sizetest.USER_LOG engine = 'oss' archive_mode = 'loading';
执行结果如下:

数据校验
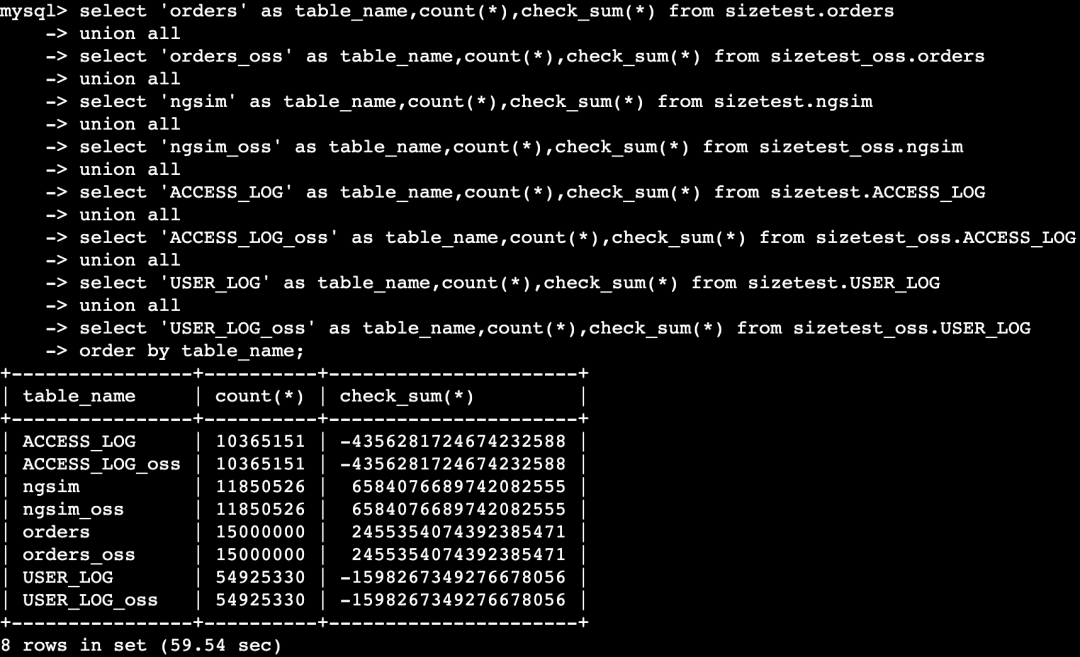
备注:请根据实际创建的冷数据table名称进行查询校验。
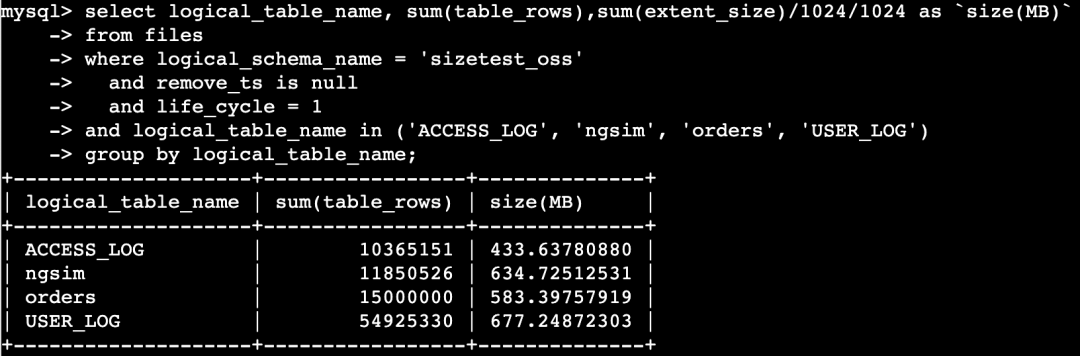
空间占用统计
select logical_table_name, sum(table_rows),sum(extent_size)/1024/1024 as `size(MB)`from information_schema.fileswhere logical_schema_name = 'sizetest_oss'and remove_ts is nulland life_cycle = 1and logical_table_name in ('ACCESS_LOG', 'ngsim', 'orders', 'USER_LOG')group by logical_table_name;
查询结果如下:
测试结果
根据以上测试,和引用文章中已有的数据库测评结果进行对比,得到以下结果。其中,PolarDB-X On OSS 获得了3个第一和1个第二(压缩效率top1已标红):
测试集 | 原始测试集大小 | PolarDB-X 热数据 on InnoDB | PolarDB-X 冷数据 on OSS | Lindorm (默认压缩) | Lindorm (开启字典压缩) | HBase | MySQL | MongoDB (默认snappy) | MongoDB (ZSTD) |
TPC-H | 1.76 GB | 2.04 GB | 583 MB | 784 MB | 639 MB | 1.23 GB | 2.10 GB | 1.63 GB | 1.32 GB |
NGSIM | 1.54 GB | 2.35 GB | 635 MB | 995 MB | 818 MB | 1.72 GB | 2.51 GB | 1.88 GB | 1.50 GB |
server log | 3.51 GB | 4.01 GB | 434 MB | 646 MB | 387 MB | 737 MB | 3.99 GB | 1.17 GB | 893 MB |
IJCAI-15 | 1.91 GB | 2.92 GB | 677 MB | 805 MB | 721 MB | 1.48 GB | 2.90 GB | 3.33 GB | 2.74 GB |
测试集 | 原始测试集大小 | PolarDB-X 热数据 on InnoDB | PolarDB-X 冷数据 on OSS | HBase | MySQL | MongoDB (默认snappy) | MongoDB (ZSTD) |
TPC-H | 1.76 GB | 2.04 GB | 583 MB | 1.23 GB | 2.10 GB | 1.63 GB | 1.32 GB |
NGSIM | 1.54 GB | 2.35 GB | 635 MB | 1.72 GB | 2.51 GB | 1.88 GB | 1.50 GB |
server log | 3.51 GB | 4.01 GB | 434 MB | 737 MB | 3.99 GB | 1.17 GB | 893 MB |
IJCAI-15 | 1.91 GB | 2.92 GB | 677 MB | 1.48 GB | 2.90 GB | 3.33 GB | 2.74 GB |
存储成本分析
存储成本 | 共享存储 | 本地SSD盘 | OSS对象存储 |
说明 | 自建数据库普遍选择ESSD PL2构建,符合性能的要求 | PolarDB-X 热数据 on InnoDB,采用物理机本地SSD盘 | PolarDB-X 冷数据 on InnoDB,采用物理机本地SSD盘 |
定价 | 定价:2 元/1 GiB/月 | 定价:0.72元/1 GiB/月 | 定价:0.12元/1 GiB/月 |
总成本 | 成本仅为共享存储的1/3 | 成本仅为共享存储的1/15 成本仅为本地SSD盘的1/6 |
说明:
基于LSM Tree的HBase,通常基于compaction做通用场景的优化,具备普适性,这也是业界NewSQL数据库基于LSM Tree做存储引擎所具备的能力,通用在3~4倍的压缩率。
PolarDB-X的热数据,默认采用MySQL InnoDB,整体的空间基本和开源MySQL对齐,PolarDB-X的冷数据,相比于PolarDB-X的热数据场景,平均有3~4倍的压缩,基本对齐LSM Tree的压缩场景,另外,面向字符和数值类型居多的场景最多有10倍的压缩效果
PolarDB-X基于存储介质的选型和优化,PolarDB-X On OSS的冷数据归档,结合高压缩率以及HDD存储成本的优势,成本仅为PolarDB-X热数据的1/20,具体计算公式 = 1 (3~4倍压缩率 * 6倍的OSS存储成本优势)
原理解读
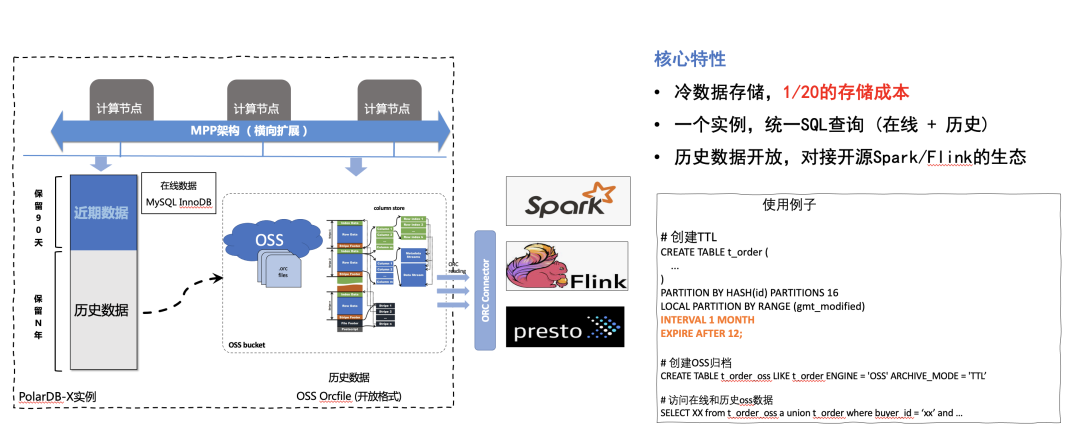
核心特性:
极低的冷数据存储成本,仅为在线热数据的1/20成本
一个数据库实例,一个SQL引擎可以同时访问热数据和冷数据,具备跨数据的join/union/subquery等。在数据库运维上,冷热数据具备一体化的备份恢复能力,支持任意时间点恢复
数据入湖,冷数据基于开源ORCFile通用格式,可以轻松对接Spark/Flink等开源生态,后续我们会开放对应Connector扩展接入大数据生态。
ORCFile
PolarDB-X 冷数据以开源格式ORC作为表文件的存储格式。ORC采用列式存储,并采取run-length encoding、dictionary encoding等算法对数值类型和字符类型进行高效编码。在此基础上,再选取LZ4压缩算法对编码后的数据进行通用压缩。
由于PolarDB-X是MySQL生态下的分布式数据库,对MySQL数据类型完全兼容,因此还需要对MySQL主要数据类型进行不同的序列化设计,来适配ORC本身的压缩能力,从而将最终的存储空间优化到极致。
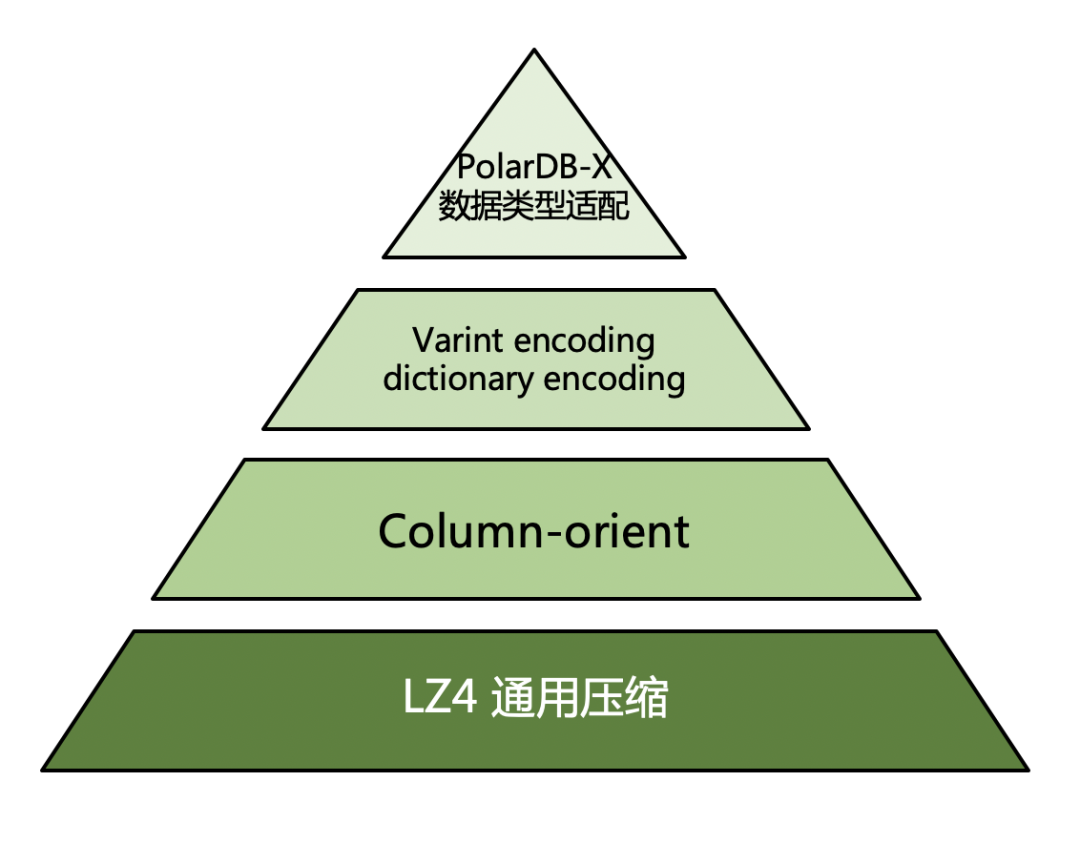
列存高效压缩
run-length encoding
run-length encoding是用于整数类型的一套编码算法,其思路来源于Protobuf 提出的varint数值压缩。主流语言都使用32bit或64bit的固定长度来存储数值,但是在实际场景中,绝大多数的数值是比较小的,有效数据只集中在低位字节。varint压缩算法将数值中每7个bit进行一次分隔,将分隔后的比特串按小端序排列;再用最高位的1bit来标识编码是否继续:比特位为为1代表编码继续,为0代表编码终止。
以Java long类型数字551为例,原始数据占据64bit,二进制串为:
00000000 00000000 00000000 00000000 00000000 00000000 00000010 00100111
varint算法先按7bit进行有效位的拆分,并以小端序排列,得到:
0100111 0000100
再补齐最高的比特位:
10100111 00000100
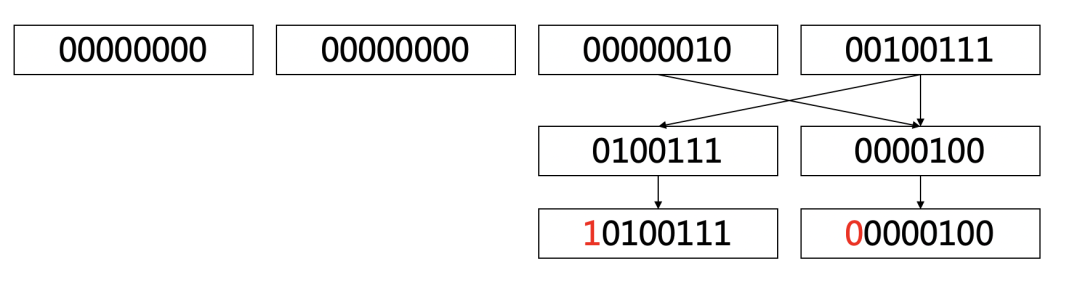
这样我们变得到了最终的压缩数据:0xA7 0x04。相比于原来8字节的固定长度,编码后的数据只占据2字节的空间。对于数值x,其压缩后的空间占用为:
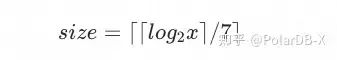
例如将上述例子中的数值551带入,可以得到空间占用为2字节。
dictionary encoding
dictionary encoding(字典编码)用于压缩字符串数据。它的基本思想是,先从一组字符串中统计出不重复的值,称为“字典”;再存储对字典值的引用。不重复值的数目在数据库领域中称为NDV,是"number of distinct value"的缩写。显然,NDV越小,则字典值越少,字典压缩的效率就越高。
例如我们要存储颜色这列字符,其字典值为“green”、“blue”、“red”,引用值分别为0、1、2,那么最终只需要存储012这三种数字即可。相比于直接存储字符串,字典压缩大大减少了存储空间的占用。
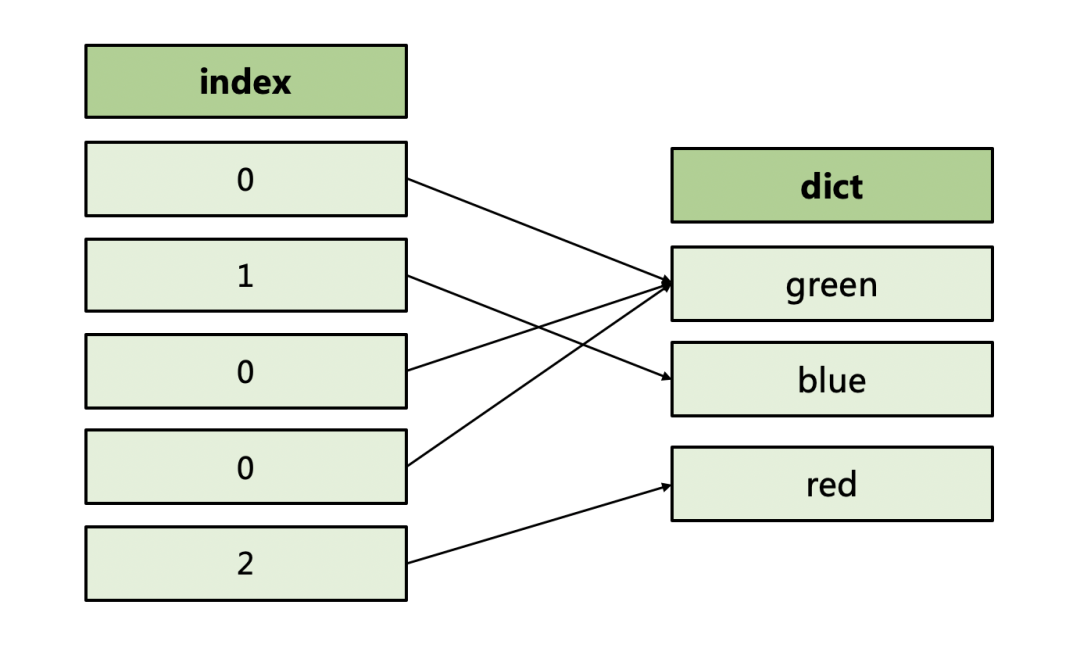
数据类型序列化
PolarDB-X为不同MySQL数据类型设计了相应的序列化方式,从而将复杂数据类型转化为数字或字节序列,用于适配ORC的字典编码和run-length编码。序列化过程要保证数据精度不会损失,并且保证序列化后的数字顺序或字节顺序能够反映不同类型下数据的真实大小关系。
数值类型
MySQL的数值类型中,bigint等整数类型可以直接应用于ORC;需要重点解决的是decimal类型的序列化设计。
PolarDB-X采取多项式的形式来表示任意精度、任意小数的decimal;每个多项式系数使用integer整型存储,系数取值范围在10的9次方以内:
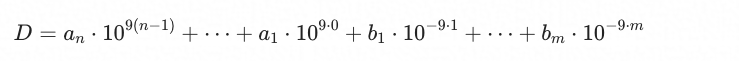
我们可以在此表示形式的基础上,将每个多项式的系数以更紧密的形式进行字节排列。例如对于数字1234567890.1234,可以拆分成多项式系数 1-234567890-123400000。将系数转化为16进制形式,再截取系数两端的0值,形成更紧密的字节排列,得到最终序列化结果0x01 0x0D 0xFB 0x38 0xD2 0x04 0xD2:
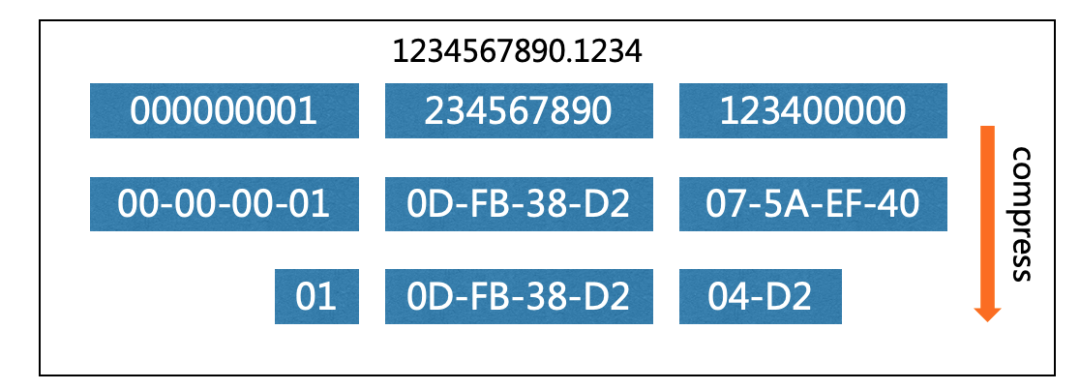
Decimal精度、小数位数与最终序列化后的大小关系如下,其中i代表整数部分长度,f代表小数部分长度:
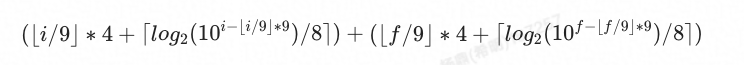
例如对于decimal(15,2),其序列化得到的字节长度为7。
时间类型
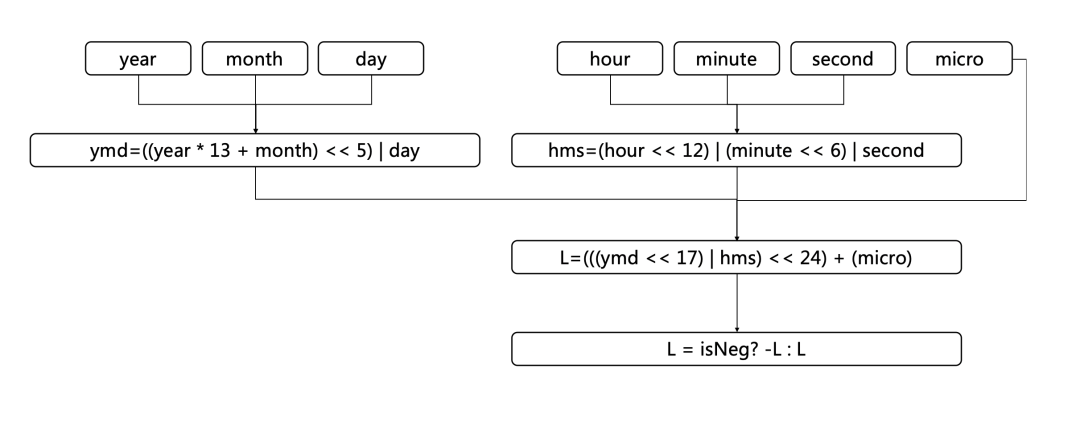
PolarDB-X 针对各个时间类型的特征进行了不同的序列化方式:针对时区无关的类型datetime、date、time,依据年月日、时分秒、微秒进行拆分;针对时区相关的类型timestamp,依据 epoch second和微秒进行拆分。
以datetime类型的时间值为例,先压缩时分秒部分得到hms值,再压缩年月日部分得到ymd值。将微秒值和以上两部分组装在一起,最后取正负号:
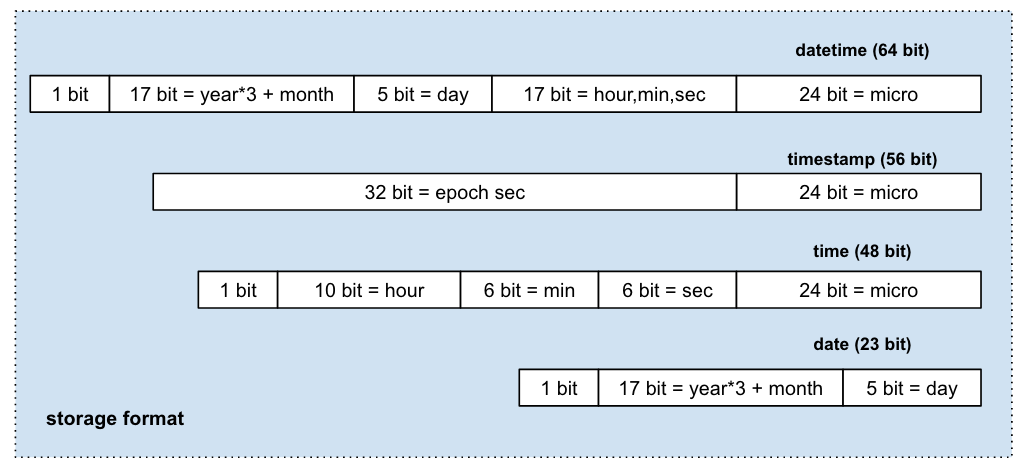
各个时间类型最终的空间占用如下图所示:
总结
参考内容
10倍压缩比?Lindorm与其他数据库实测大比拼
Apache ORC
https://orc.apache.org/specification/ORCv0/
ProtoBuf Varint
https://developers.google.com/protocol-buffers/docs/encoding
TPCH
http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/183466/cn_zh/1645604888228/tpchData%20%281%29.tar.gz
NGSIM数据集
https://data.transportation.gov/Automobiles/Next-Generation-Simulation-NGSIM-Vehicle-Trajector/8ect-6jqj
server log数据集
https://www.kaggle.com/datasets/eliasdabbas/web-server-access-logs
IJCAI-15数据集
https://tianchi.aliyun.com/dataset/dataDetail?spm=5176.12281978.0.0.1e4268d7WHdFvm&dataId=47
