




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
背景介绍
1.1 国标GB18030
GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。 GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。 GB18030-2022则主要增加了CJK统一汉字扩充C、D、E、F区的汉字。
GB18030-2022《信息技术 汉字编码字符集》在2005版基础上再增加了一万多个汉字,使得汉字总数达到87887个,全面覆盖了《通用规范汉字表》中的汉字。收录的少数民族文字包括:
藏文 滇东北苗文 彝文 傈僳文 朝鲜文 西双版纳新傣文 西双版纳老傣文 维吾尔文
哈萨克文 柯尔克孜文 蒙古文 德宏傣文等
1.2 政策说明
1.3 Unicode编码与CJK对应说明
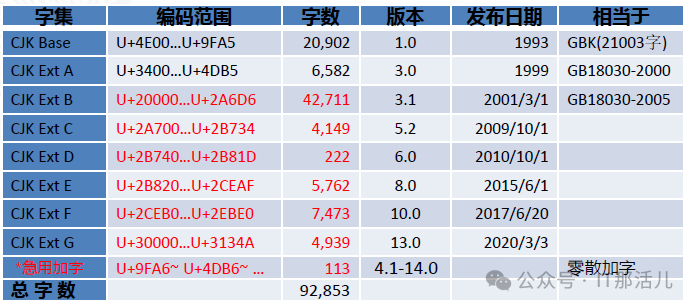
随着国际编码unicode的不断扩展,支持的汉字数量也在不断增加,上图中是unicode版本与GBK的对应关系,当前的unicode11.0相当于涵盖GB18030-2022中的八万多个字,后面我们进行逐个测试。
Oracle数据库支持说明
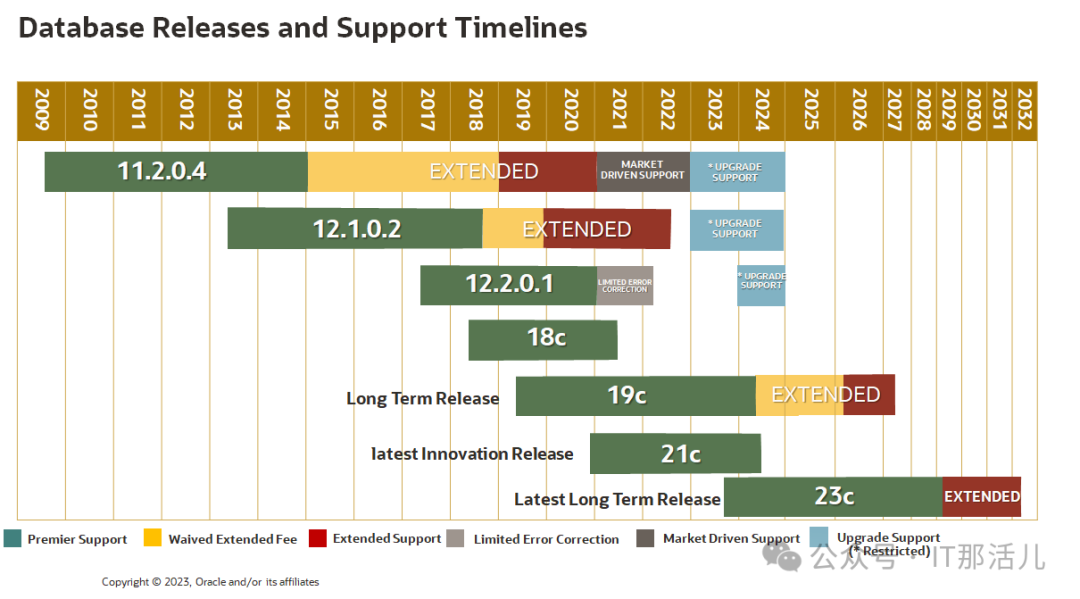
从ORACLE版本的支持矩阵来看,建议使用19C的长支撑版本,也是当前安装部署的建议版本。
测试环境说明
CentOS Linux release 7.4.1708 (Core) CentOS Linux release 7.3.1611 (Core) |
3.1 源数据库(AL32UTF8)
3.1.1 版本及补丁信息
oracle@host_1476:[/oracle/ogg21] opatch lsinv|grep "Patch description"
Patch description: "CN NEED SUPPORT GB18030-2022 IN 19C"
Patch description: "MERGE ON DATABASE RU 19.20.0.0.0 OF 35525143 35784008"
Patch description: "MERGE ON DATABASE RU 19.20.0.0.0 OF 35585502 35754528"
Patch description: "MERGE ON DATABASE RU 19.20.0.0.0 OF 35617844 35623675"
Patch description: "THOUSANDS OF NEW OLINT WARNINGS INTRODUCED BY TRANSACTION SKSAMUDR_BUG-35360571"
Patch description: "Fix for bug 35635081"
Patch description: "Fix for bug 35598911"
Patch description: "TRACKING BUG FOR SQLCL CHANGES IN SQLDEVELOPER 21.4.10"
Patch description: "EXACS - ACFS CORRUPTION ISSUE"
Patch description: "DOMAIN NAME IS MISSING FOR SERVICE POST GI PATCH TO 19.18"
Patch description: "MERGE FAILS WITH ORA-00600 [13013] IN 19.17 EVEN WITH FIX 34884598"
Patch description: "STABLE E3POD ORA-600 [KRCCSIO_1] CTWR CRASH"
Patch description: "DATABASE TERMINATED WITH ORA-600 [KCBB_PREPARE_4], [3], [], [] ON UNIQUE INDEX ON A PARTITIONED TABLE"
Patch description: "Database Release Update : 19.20.0.0.230718 (35320081)"
Patch description: "OCW RELEASE UPDATE 19.3.0.0.0 (29585399)"
$opatch lspatches |grep 34994751
34994751;CN NEED SUPPORT GB18030-2022 IN 19C
3.1.2 数据库字符集
PARAMETER VALUE
------------------------------ ------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_CHARACTERSET AL32UTF8
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
3.2 目标数据库(ZHS16GBK)
3.2.1 版本及补丁信息
--------------------------------------------------------------------------------
Installed Top-level Products (1):
Oracle Database 11g 11.2.0.4.0
There are 1 products installed in this Oracle Home.
There are no Interim patches installed in this Oracle Home.
--------------------------------------------------------------------------------
3.2.2 数据库字符集
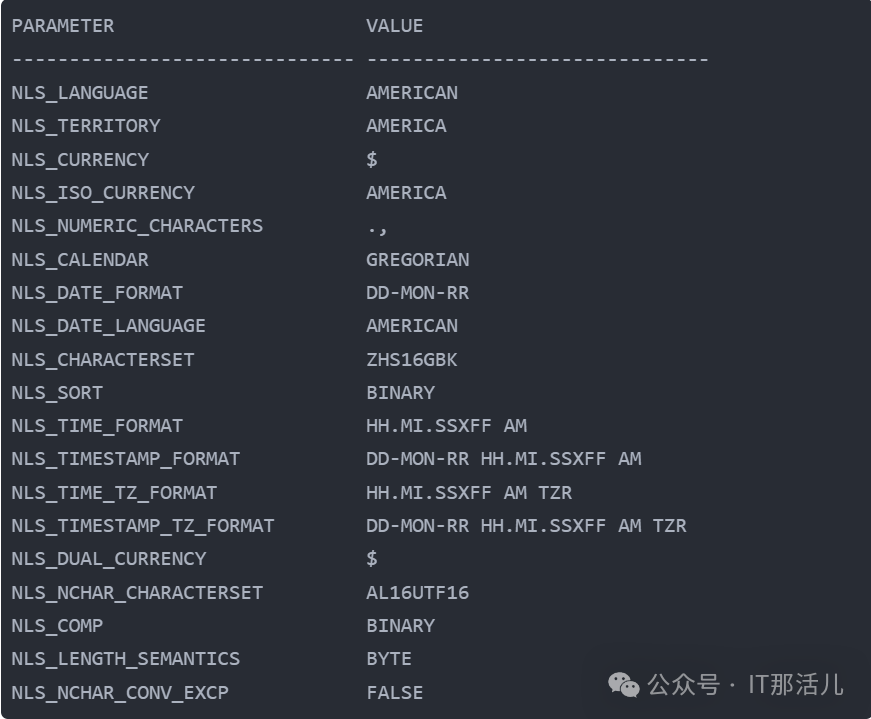
数据库字符集ZHS16GBK ,国家字符集AL16UTF16,官方介绍ZHS16GBK即GBK,支持2万多汉字。
汉字兼容测试
本次测试主要是测试三个方面:
一是GBK集汉字同步测试,数据在GBK编码范围内(0x8140-0xFEFE),数据从AL32UTF8到ZHS16GBK的同步情况; 二是扩展集汉字同步测试,从CJK扩A-G中汉字的同步测试; 三是GBK集和扩展集的混合的同步测试;
CREATE TABLE TEST.HANZI
( ID NUMBER PRIMARY KEY ,
VCOL VARCHAR2(10),
NCOL VARCHAR2(10)
)
TABLESPACE TESTTBS ;
CREATE TABLE TEST.HANZI
( ID NUMBER PRIMARY KEY ,
VCOL VARCHAR2(10),
NCOL NVARCHAR2(10)
)
TABLESPACE TESTTBS ;
EXTRACT e1
SETENV (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
SETENV (ORACLE_HOME = "/oracle/app/oracle/product/19.0.0/dbhome_1")
SETENV (ORACLE_SID = "dbname")
DISCARDFILE ./dirrpt/e1.dsc, APPEND, MEGABYTES 1024
EXTTRAIL ./dirdat/e1
GETTRUNCATES
NOCOMPRESSDELETES FETCHMISSINGCOLUMNS
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
USERID gguser@11.11.11.11:1521/dbname, PASSWORD Dbname
TABLE TEST.HANZI;
EXTRACT p1
PASSTHRU
RMTHOST 11.11.11.12, MGRPORT 7809, compress
RMTTRAIL ./dirdat/r1
TABLE test.HANZI;
REPLICAT r1
SETENV (NLS_LANG="AMERICAN_AMERICA.AL32UTF8")
SETENV (ORACLE_HOME = "/ora/oracle/product/11.2.0/db_1")
SETENV (ORACLE_SID = "dbname")
USERID gguser@11.11.11.12:1521/dbname,PASSWORD Dbname
discardfile ./dirrpt/r1.dsc,purge
ASSUMETARGETDEFS
--SOURCECHARSET PASSTHRU
MAP test.hanzi, TARGET test.hanzi;
4.1 GBK集汉字测试
源端(客户端设置UTF8字符集):
SQL> insert into test.hanzi values(1,'中国人','中国人');
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT * FROM test.hanzi;
ID VCOL NCOL
---------- ---------- ----------
1 中国人 中国人
目标端(客户端设置GB18030字符集):
SQL> SELECT * FROM test.hanzi;
ID VCOL NCOL
---------- ---------- --------------------
1 中国人 中国人
源端:
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
1
Typ=1 Len=9 CharacterSet=AL32UTF8: e4,b8,ad,e5,9b,bd,e4,ba,ba
Typ=1 Len=9 CharacterSet=AL32UTF8: e4,b8,ad,e5,9b,bd,e4,ba,ba
目标端:
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
1
Typ=1 Len=6 CharacterSet=ZHS16GBK: d6,d0,b9,fa,c8,cb
Typ=1 Len=6 CharacterSet=AL16UTF16: 4e,2d,56,fd,4e,ba
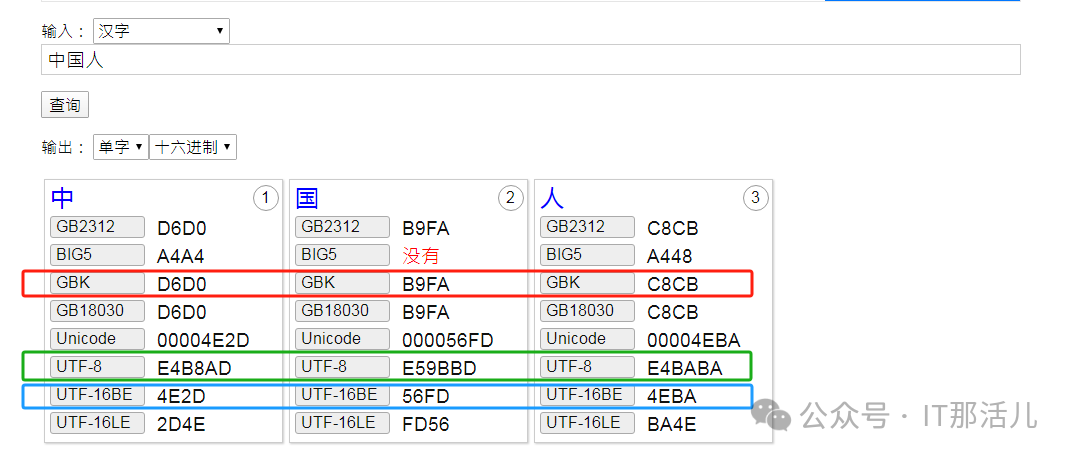
ZHS16GBK: d6,d0,b9,fa,c8,cb 与 GBK D6D0 B9FA C8CB 相同。 AL32UTF8: e4,b8,ad,e5,9b,bd,e4,ba,ba 与UTF-8 E4B8AD E59BBD E4BABA相同。 AL16UTF16: 4e,2d,56,fd,4e,ba 与UTF-16BE 4E2D 56FD 4EBA 相同。
4.2 扩展集汉字测试

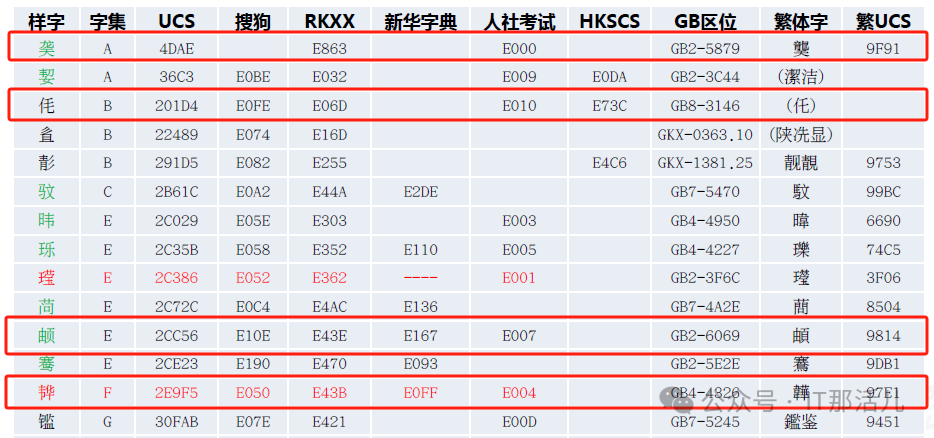
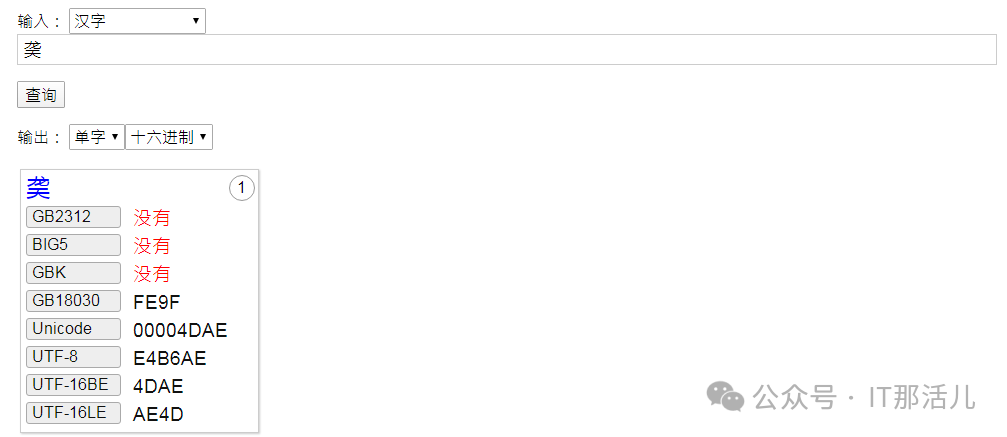
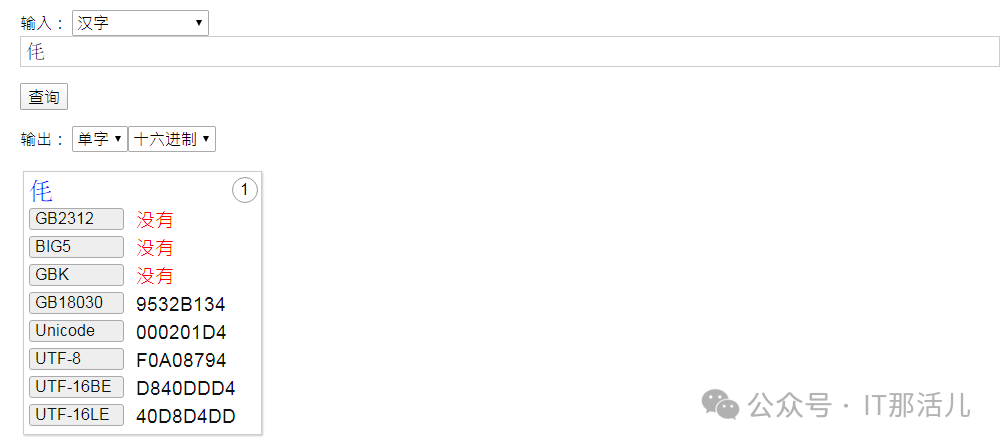
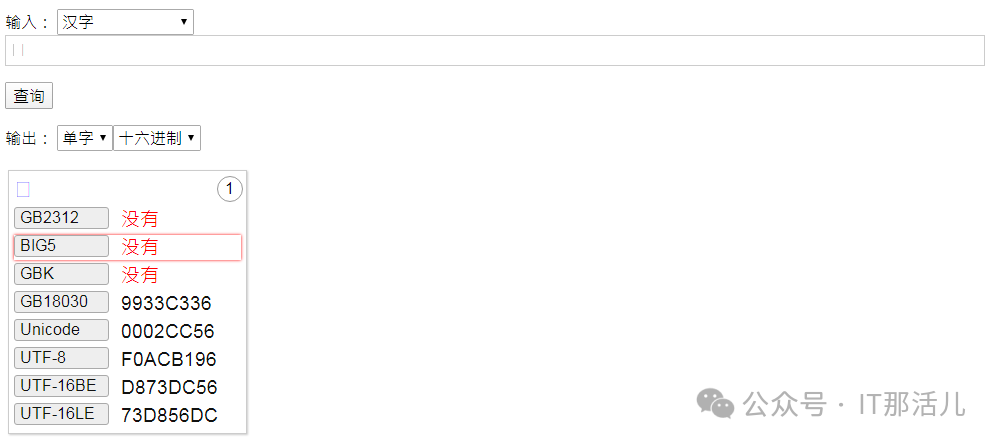

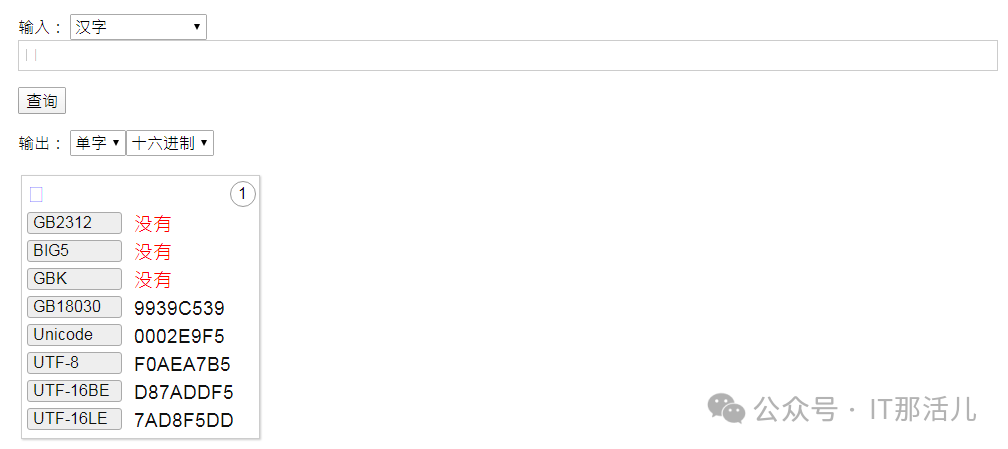
4.2.1 测试varchar2类型
源端:
SQL> insert into test.hanzi values (2,utl_raw.cast_to_varchar2('E4B6AE'),'v2') ;
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT * FROM test.hanzi;
ID VCOL NCOL
---------- ---------- ----------
1 中国人 中国人
2 䶮 v2
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=2;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
2
Typ=1 Len=3 CharacterSet=AL32UTF8: e4,b6,ae
Typ=1 Len=2 CharacterSet=AL32UTF8: 76,32
2023-11-13 11:25:17 ERROR OGG-03533 Conversion from character set UTF-8 of source column VCOL to character set zhs16gbk of target column VCOL failed b
ecause the source column contains a character 'e4 b6 ae' at offset 0 that is not available in the target character set.
2023-11-13 11:27:38 ERROR OGG-02552 The SOURCECHARSET PASSTHRU parameter does not support CHAR/VARCHAR/CLOB to/from NCHAR/NVARCHAR/NCLOB mappings.
SQL> SELECT * FROM test.hanzi;
SP2-0784: Invalid or incomplete character beginning 0xAE returned
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
2
Typ=1 Len=3 CharacterSet=ZHS16GBK: e4,b6,ae
Typ=1 Len=2 CharacterSet=ZHS16GBK: 76,32
4.2.2 测试nvarchar2类型
2023-11-13 14:45:44 ERROR OGG-02552 The SOURCECHARSET PASSTHRU parameter does not support CHAR/VARCHAR/CLOB to/from NCHAR/NVARCHAR/NCLOB mappings.
源端
SQL> insert into test.hanzi values (12,'nv2','中国人') ;
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT * FROM test.hanzi WHERE id=12;
ID VCOL NCOL
---------- ---------- ----------
12 nv2 中国人
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=12;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
12
Typ=1 Len=3 CharacterSet=AL32UTF8: 6e,76,32
Typ=1 Len=9 CharacterSet=AL32UTF8: e4,b8,ad,e5,9b,bd,e4,ba,ba
目标端
SQL> SELECT * FROM test.hanzi WHERE id=12;
ID VCOL NCOL
---------- ---------- --------------------
12 nv2 中国人
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=12;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
12
Typ=1 Len=3 CharacterSet=ZHS16GBK: 6e,76,32
Typ=1 Len=6 CharacterSet=AL16UTF16: 4e,2d,56,fd,4e,ba
源端的AL32UTF8: e4,b8,ad,e5,9b,bd,e4,ba,ba 对应GBK编码; 目标端的AL16UTF16: 4e,2d,56,fd,4e,ba对应UTF-16BE编码,说明可以正常进行编码转换。
源端
SQL> SELECT * FROM test.hanzi WHERE id=13;
ID VCOL NCOL
---------- ---------- ----------
13 nv2 䶮中
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=13;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
13
Typ=1 Len=3 CharacterSet=AL32UTF8: 6e,76,32
Typ=1 Len=6 CharacterSet=AL32UTF8: e4,b6,ae,e4,b8,ad
目标端
[oracle@sjtdb ~]$ export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
SQL> SQL> SELECT * FROM test.hanzi WHERE id=13;
ID VCOL
---------- ------------------------------
NCOL
----------------------------------------
13 nv2
䶮中
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=13;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
13
Typ=1 Len=3 CharacterSet=ZHS16GBK: 6e,76,32
Typ=1 Len=4 CharacterSet=AL16UTF16: 4d,ae,4e,2d
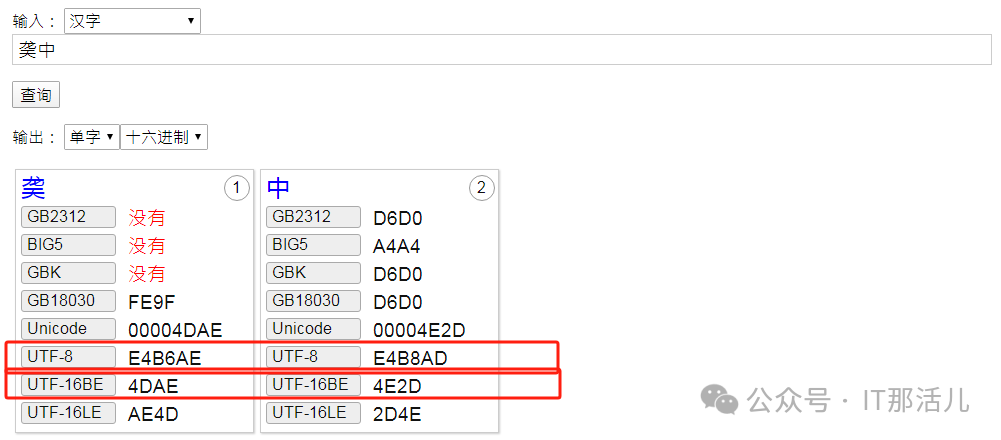
4.3 混合GBK集和扩展集测试
源端:
SQL> insert into test.hanzi values (3,'䶮中','v2') ;
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT * FROM test.hanzi WHERE id=3;
ID VCOL NCOL
---------- ---------- ----------
3 䶮中 v2
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=3;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
3
Typ=1 Len=6 CharacterSet=AL32UTF8: e4,b6,ae,e4,b8,ad
Typ=1 Len=2 CharacterSet=AL32UTF8: 76,32
SQL> insert into test.hanzi values (4,utl_raw.cast_to_varchar2('E4B6AE')||'人','v2') ;
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT * FROM test.hanzi WHERE id=4;
ID VCOL NCOL
---------- ---------- ----------
4 䶮人 v2
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=4;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
4
Typ=1 Len=6 CharacterSet=AL32UTF8: e4,b6,ae,e4,ba,ba
Typ=1 Len=2 CharacterSet=AL32UTF8: 76,32
查询目标端的表:
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi ;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
2
Typ=1 Len=3 CharacterSet=ZHS16GBK: e4,b6,ae
Typ=1 Len=2 CharacterSet=ZHS16GBK: 76,32
3
Typ=1 Len=6 CharacterSet=ZHS16GBK: e4,b6,ae,e4,b8,ad
Typ=1 Len=2 CharacterSet=ZHS16GBK: 76,32
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
4
Typ=1 Len=6 CharacterSet=ZHS16GBK: e4,b6,ae,e4,ba,ba
Typ=1 Len=2 CharacterSet=ZHS16GBK: 76,32
SQL> SELECT * FROM test.hanzi WHERE id=4;
ID VCOL NCOL
---------- ---------- ----------
4 䶮人 v2
SQL> SELECT * FROM test.hanzi WHERE id=3;
ID VCOL NCOL
---------- ---------- ----------
3 䶮中 v2
SQL> SELECT * FROM test.hanzi WHERE id=2;
SP2-0784: Invalid or incomplete character beginning 0xAE returned
SQL> SELECT * FROM test.hanzi WHERE id=2;
SP2-0784: Invalid or incomplete character beginning 0xAE returned
SQL> SELECT * FROM test.hanzi WHERE id=3;
ID VCOL NCOL
---------- ---------- ----------
3 涠腑 v2
SQL> SELECT * FROM test.hanzi WHERE id=4;
ID VCOL NCOL
---------- ---------- ----------
4 涠汉 v2
4.4 扩展F集汉字测试
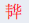 ,因为本地计算机不支持扩F字,导致出现□。
,因为本地计算机不支持扩F字,导致出现□。
SQL> insert into test.hanzi values (16,'kE',utl_raw.cast_to_varchar2('F0AEA7B5')||'中') ;
1 row created.
SQL> SELECT * FROM test.hanzi WHERE id=16;
ID VCOL NCOL
---------- ---------- ----------
14 kE 𮧵中
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=14;
ID
----------
COL1
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
16
Typ=1 Len=2 CharacterSet=AL32UTF8: 6b,45
Typ=1 Len=7 CharacterSet=AL32UTF8: f0,ae,a7,b5,e4,b8,ad
SQL> SELECT * FROM test.hanzi WHERE id=16;
ID VCOL
---------- ------------------------------
NCOL
----------------------------------------
16 kE
𮧵中
SQL> select id,dump(vcol,1016) col1,dump(ncol,1016) col2 from test.hanzi WHERE id=16;
ID
----------
COL1
--------------------------------------------------------------------------------
COL2
--------------------------------------------------------------------------------
16
Typ=1 Len=2 CharacterSet=ZHS16GBK: 6b,45
Typ=1 Len=6 CharacterSet=AL16UTF16: d8,7a,dd,f5,4e,2d
附 录:
1)AL32UTF8是不是ZHS16GBK的超集
2)AL32UTF8和AL16UTF16是不是具备相同UNICODE范围
3)使用N-types(AL16UTF16)的优劣势
n-types优势,总结就是汉字占比高会节省空间 a) one possible (but rather theoretical) advantage is storage (disk space) for NCHAR/NVARCHAR2. b) other possible advantage is extending the limits of CHAR semantics. n-types劣势 * You might have some problems with older clients if using AL16UTF16 see point 6) b) in this note * Be sure that you use (AL32)UTF8 as NLS_CHARACTERSET , otherwise you will run into point 13 of this note. * Do not expect a higher *performance* by using NCHAR, NVARCHAR2 and NCLOB instead of CHAR, VARCHAR2 and CLOB with an AL32UTF8 NLS_CHARACTERSET , it might be a little bit faster on some systems, but that has more to do with I/O then with the database kernel and the difference will not be noticable in the overall picture. * Forms 6i/9i does not support NCHAR NVARCHAR2. This is documented in the 6i Forms online help. * If you use N-types, DO use the (N'...') syntax when coding it so that Literals are denoted as being in the national character set by prepending letter 'N'. 劣势,总结是:1.老的客户端不识别,2.性能有影响,3.插入数据需要’ N’形式,对查询没有影响,4.不允许跟zhs16gbk的varchar在一起,会导致客户端字符集无法正确解析汉字。
本文作者:孙其成(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
