今天为大家分享一篇VLDB 2023年的向量检索论文:
Similarity search in the blink of an eye with compressed indices
基于压缩索引的快速相似性搜索,作者来自英特尔实验室
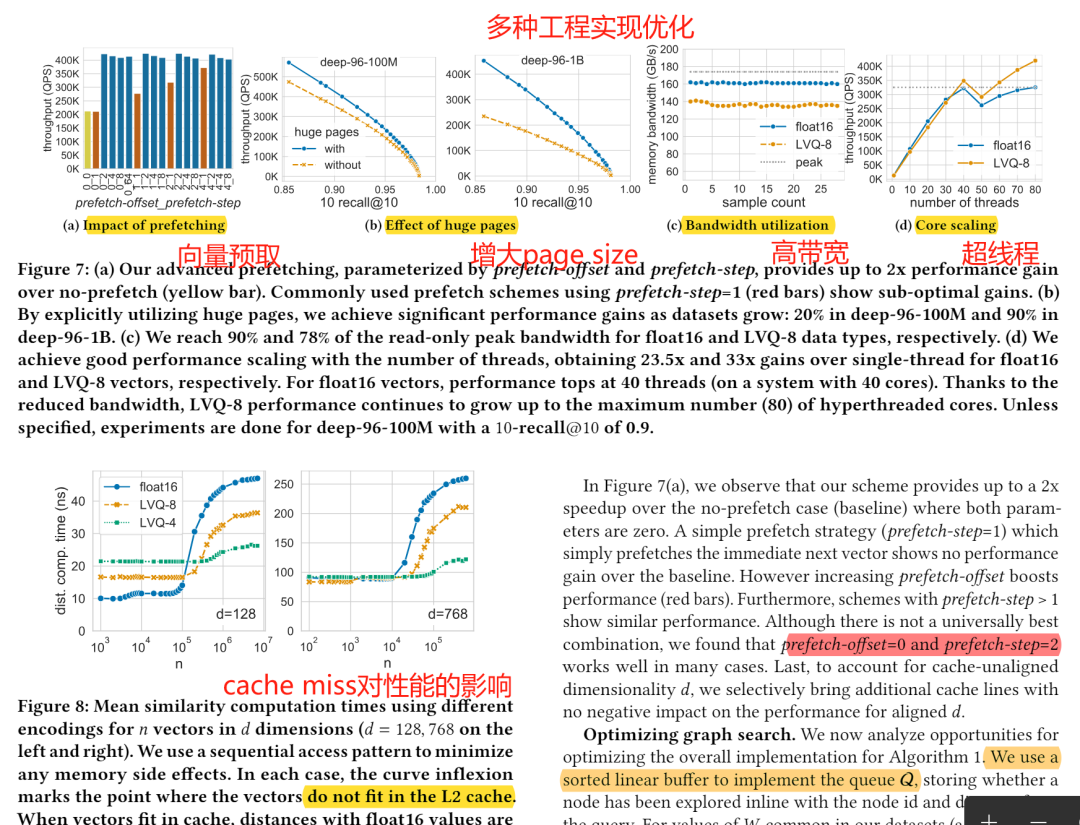
论文概述 随着近年来向量索引性能的深度优化,单机索引可以支持的向量规模和吞吐量(QPS)逐渐攀升。在对索引性能的分析中,本文研究者发现,内存访问的延迟和内存带宽的限制,已经逐渐超越计算的代价,成为目前基于近邻图的索引算法的主要瓶颈。
在本栏目的上一期【随机映射降维加速 ANN 距离计算|向量检索论文分享】 ,我们介绍了通过向量降维来进行距离估算的方式,来降低ANN算法的计算代价。而本期论文的算法LVQ,通过对向量数据的有损编码压缩,降低了向量索引的存储代价(即内存开销);同时通过提高cache命中率和减少访存需求,保证整体查询性能降低微乎其微。
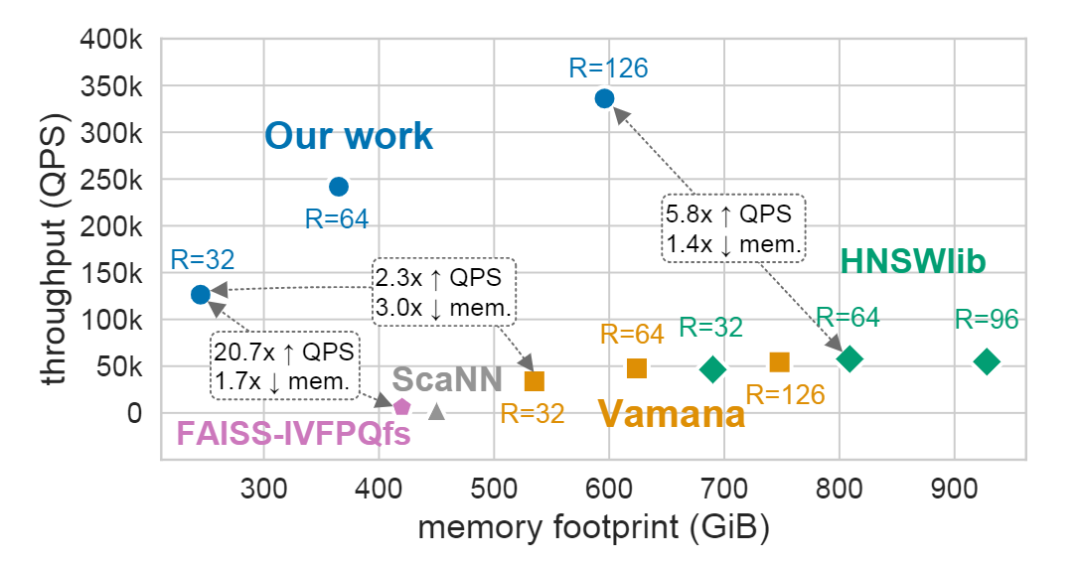
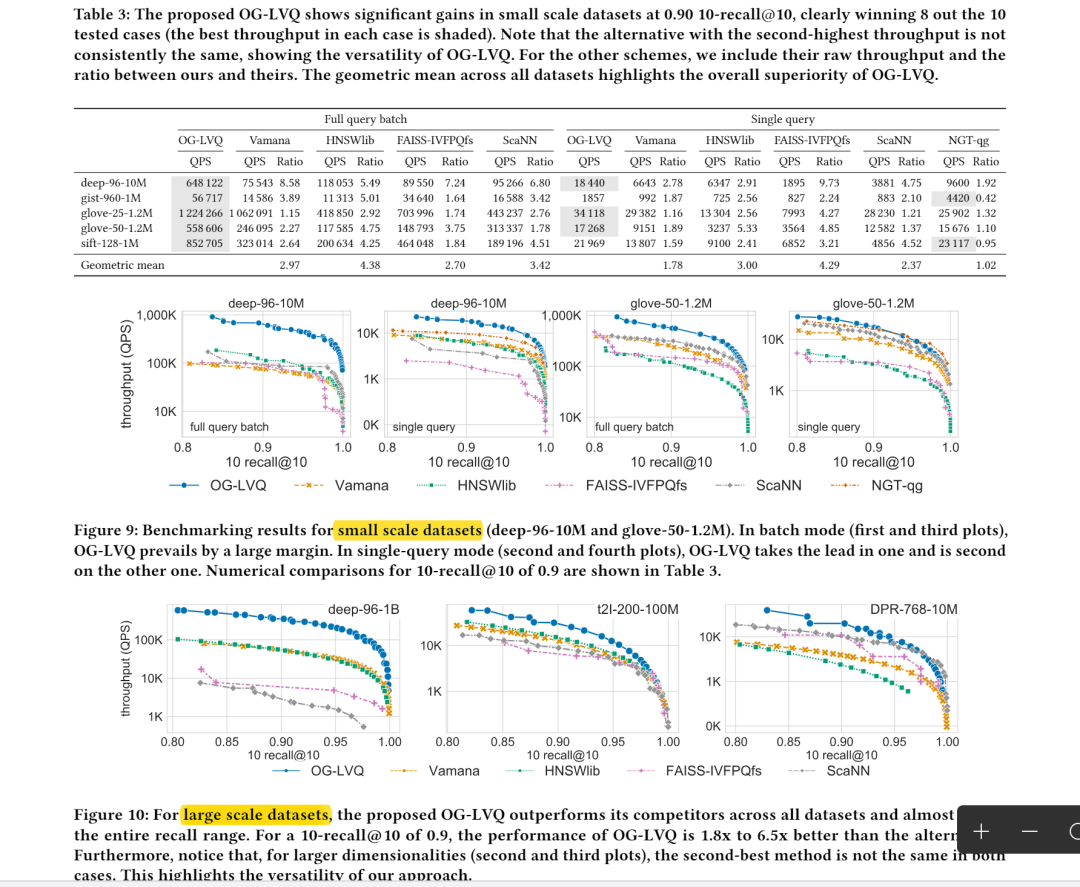
论文结果显示,8-bit量化下的LVQ,相比于HNSW,可以获得3-5倍的吞吐量提升。 论文地址: https://arxiv.org/pdf/2304.04759
代码地址: https://github.com/intel/ScalableVectorSearch
关键算法 逐向量浮点数压缩算法
向量的组成单位:浮点数float,一般是由32个bit进行表示的,即IEEE754标准。对浮点数进行压缩,已经有多种成型的办法了。比如,在神经网络的量化中,就可以将模型的权重和偏差量化成int4, int8, float16等多种格式满足存储需求。其基本原理是根据范围(比如网络的某一层)中浮点数的值域,成比例地映射到更小的值域中,比如int8即为(-127,127)。在本文中,这种方式称为全局量化。 然而,这种方式由于整体值域范围大、数据值分布不均等问题,对于比特的利用率并不高。因此,本文提出局部敏感量化LVQ(Locally-Adaptive Quantization)算法,提高bit利用率,降低量化损失。 LVQ对每个向量单独量化,即首先将每个向量减去数据集的均值向量,然后计算每个向量中各维度的最大最小值,用以确定量化后的值域。再按照分配的bit数,均匀分割值域范围。因此LVQ量化后,每个向量占用的内存是每个浮点数的量化码+上下值域,通常使用16bit的浮点数来表示。
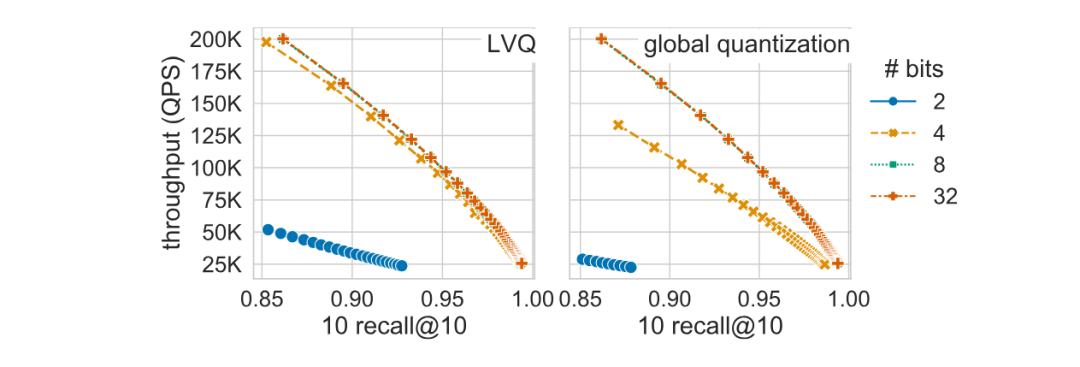
类似于乘积量化算法,LVQ也设计了针对残存值的量化编码。即针对每一个向量中浮点数的量化损失,再次进行量化。那么此时的值域即为分割范围的一半,那么也就不需要额外存储值域范围。 在论文中,作者通过理论推导与实验证明:LVQ可以在压缩向量后,直接基于量化码用于索引构建和查询。 从下图(左)可以看到,在8bit量化中,查询性能几乎无损失;而在4bit量化中,性能损失也较小。
精彩段落 <<< 左右滑动见更多 >>>
总结 本文设计了一个简洁有效的标量量化算法LVQ,通过对cache、内存带宽的充分利用,大幅降低了图索引的内存开销,并尽可能降低了对查询性能的影响。从研究角度看,LVQ算法简单,但针对索引构建和查询的各个步骤,通过理论分析和实验充分证明了微小的精度损失,论述严谨。从应用价值看,LVQ在分布式、云服务等场景中可以大幅节省成本,是实用性较强的算法。
延伸阅读 [1] TPAMI'10:乘积量化 Product Quantization for Nearest Neighbor Search
(https://www.researchgate.net/profile/Herve-Jegou/publication/47815472_Product_Quantization_for_Nearest_Neighbor_Search/links/00b4953c9a4b399203000000/Product-Quantization-for-Nearest-Neighbor-Search.pdf) [2] arXiv'23:神经网络量化 A Survey of Quantization Methods for Efficient Neural Network Inference
(https://arxiv.org/pdf/2103.13630) 编者简介 复旦大学与巴黎西岱大学联合培养博士生,研究领域为高维数据(向量、序列等)管理和分析。以第一作者在SIGMOD,VLDB,VLDBJ,TKDE等数据库领域会议/期刊发表多篇论文,并担任审稿人。 个人主页: https://zeyuwang.top/ 谷歌学术: https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ 技术博客: htt ps://www.jianshu.com/u/d015902c6d09 👆 关注 AI 搜索引擎 ,获取更多专业技术分享 ~