




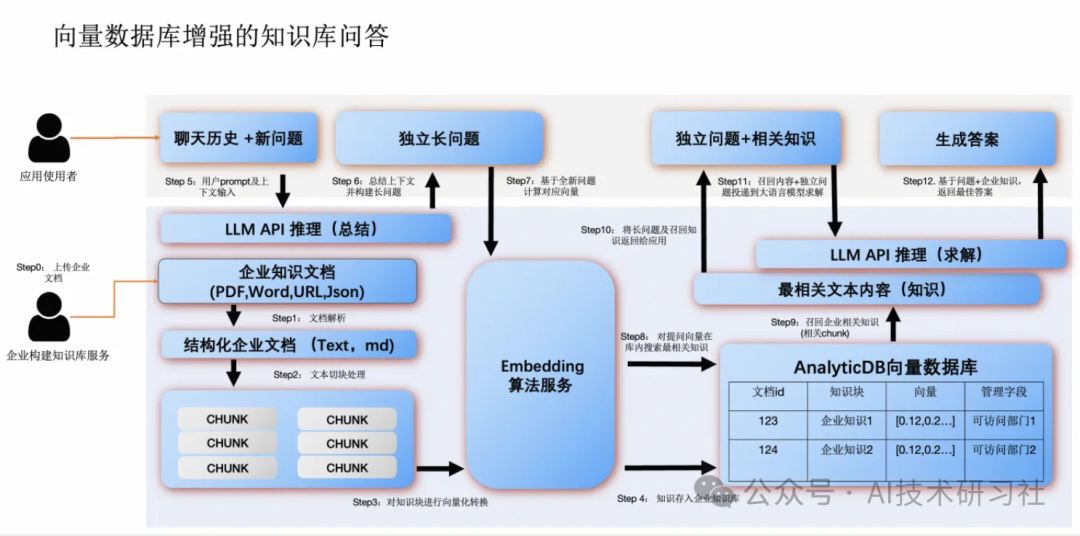
企业为什么需要向量数据库?
在AIGC时代,企业需要向量数据库扮演什么样的角色?首先看下向量数据库和 LLM的分层,最底下是一个通用大语言模型层,它能回答的问题是一些通用的问题。比如说你让它回答零售的定义是什么,它能够很清晰的告诉你这个答案。
再往上面一层是行业模型,它是模型提供商为行业专门定制的一些行业的大语言模型,比如说它可以对金融、安全或者零售行业去定制一些大语言模型,它会把一些特定的行业知识的语料去喂给这个模型来加强训练。举个例子,行业模型能回答这样的问题,比如说零售行业的具体业务流程是什么,它能够回答得非常精确,这个是普通的大语言模型没法回答的。
在行业模型上面就会进到了企业它自己私有模型的领域,企业私有的模型它也分为两层。第一层是企业专属模型,它是企业通过在行业模型基础之上,用自己的专有的内部知识去 fine-tune 的结果。它能回答的一个问题是,比如说,我们公司的主售的是一些什么样的一些产品。但是 fine-tune 有一个问题,就是 fine-tune 的代价其实是非常高的,并且每一次 fine-tune 的时间比较久,企业无法经常去做这个事情,因为它的 cost 非常高。
在大数据规模爆炸的时代背景下,企业数据知识源源不断地流入,所以这种场景下我们就需要第四层,也就是企业的一个专属知识库,这个专属知识库通常是由向量数据库来实现的,通过向量数据库,它能回答的问题是,比如我们公司最近三天被搜索得最多的产品是什么?以及我们公司最近卖得最火的产品是什么?它有实时性这样一个特性。很多时候你也可以用向量数据库这一层去修正大语言模型的幻觉问题。
 HNSW向量检索算法
HNSW向量检索算法
首先讲一下 NSW 的搜索和插入算法的实现,这里我写了一段伪代码,它其实非常简单,就是你随机选一个节点,然后把它扔入一个优先级队列里面,用来bootstrap。
然后你不断地从这个优先级队列里面去拿节点。然后去看如果说它离你要搜索的节点的距离已经大于所有你已知的这些答案的距离的时候,这时候就做一个贪心的裁剪,不继续搜索下去了。否则的话,我会把它的所有的邻居都标记成已经访问过,并且也加入到这个 candidate 的优先级队列里面去,并且把它们也都加到结果集里面去。
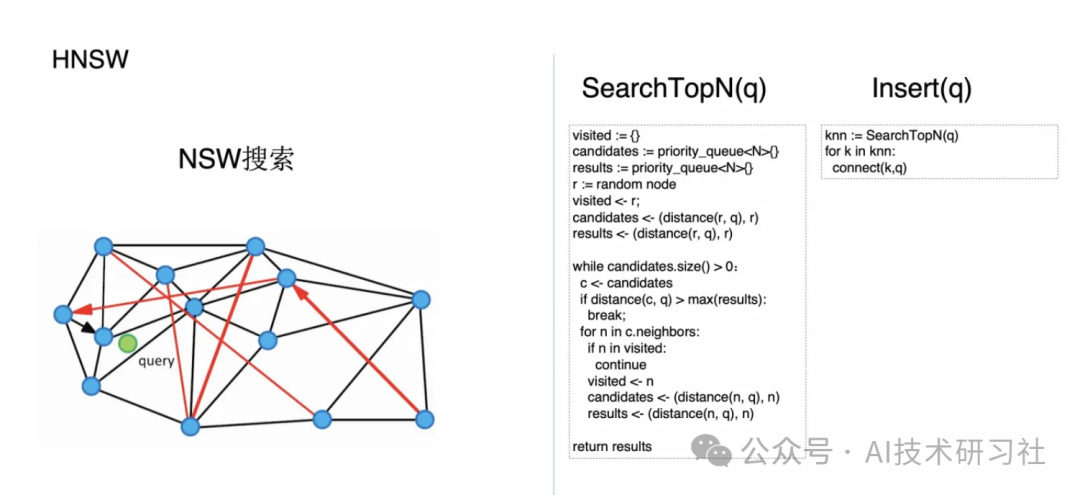
当我完成这个步骤的时候,要么我是把所有的节点都访问过或者裁剪掉了,要么是我达到了规定的访问的节点的个数上限,那这时算法就返回,这样的话我就得到了离这个节点最近的近似的 k 个节点。插入的流程也非常简单,插入的时候其实就是运行一遍找离它最近的 k 个节点的算法,然后跟它们都建立连接就可以了。
HNSW 本质上是在 NSW 上做一个阶层的叠加,它本质上其实就是一个类似于 skip list 的数据结构,它能通过上面的那些层去加速进到离查询节点最近的那个点的步骤。
那具体它是怎么做的?搜索的时候其实非常简单,在搜索的时候我只需要从最顶上开始搜索,然后每一个都搜索离它最近的节点,直到倒数第二层。然后到了倒数第二层之后,就通过那个节点作为最后一层的起始节点,然后在最后一层的这个节点开始去进行 NSW 的查询,具体就是用到前面一页 PPT 讲的那个搜索方法。
那插入的时候它是怎么做的?插入的时候还有些不一样,因为像 skip list 这种数据结构,插入的时候你必须要保证就是我要把这个节点在最底下的 lc 层都插入。
这种情况下本质上我相当于是先掷一个硬币,由这个硬币的结果来决定要插入到最高的是哪一层。具体插入的时候,对于上面从最顶层到要插入的这一层的上面一层,算法仍然是一样的,就是找到离它最近的节点,然后从要插入这一层到最底层开始,对于每一层我都会去找它的这个离它最近的 top n 个,那这里跟前面的 NSW 算法不同的是我们多加了称之为 SelectNeighbors 的这个函数。
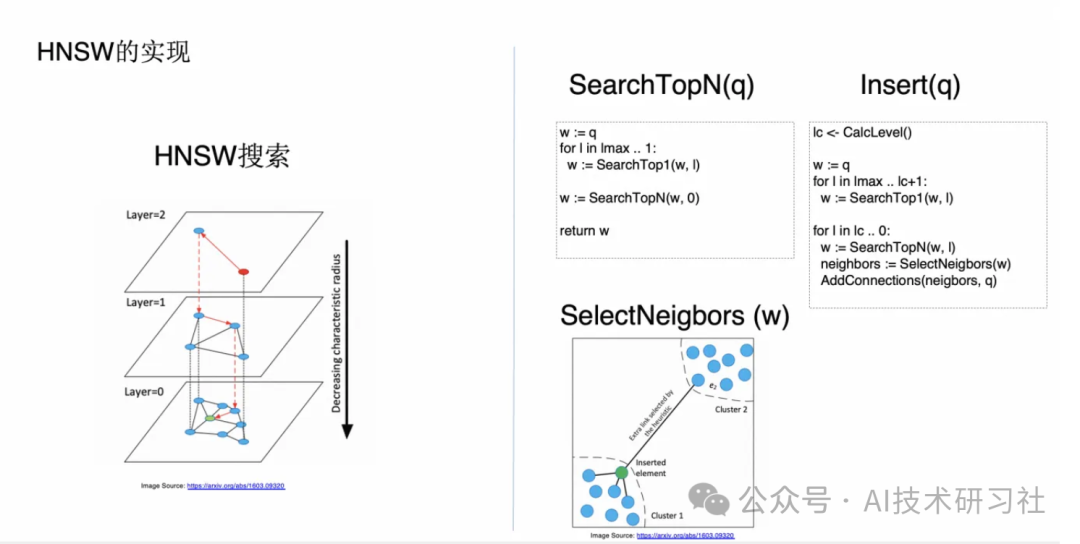
这个函数的作用是做一些 heuristic 的,也就是启发式的搜索。那引入它是为了避免一个什么问题?它是为了避免就是如这个图所示的,形成的两个 cluster 的孤岛。我们希望这个 HNSW 的图里面这两个 cluster 是连接起来的。
那这个时候它采用的算法是什么呢?假如有某一个候选节点,我计算离这个节点到目标节点的距离,那它已经比到之前的某一个添加的节点的距离是更远的话,那我就跳过暂时跳过这个节点,因为这个节点也可以通过那个节点来相连。
所以如果你用常规算法的话,这里面的所有的节点都会被加到我的 candidate 里面去,但是如果你用刚才我说的那个算法的话,会跳过一些节点,那这样的话这个比较远的另一个 cluster 的节点它就有机会被加进去,因为对于它来说,它离这个绿色节点的距离比它离其他已经加进去的这些节点距离都要近,所以这个节点会被加入,部分概率上解决了孤岛的问题。
向量数据库与向量检索技术实践
偶然间从一位同行业的技术大佬那里得知,本月在北京将召开中国数据库技术大会。我决定寻找一些途径,看看能否参与其中。经过网上搜索,找到了以下信息。
大会官网:https://dtcc.it168.com/yicheng.html
2024年8月22~24日,由IT168联合旗下ITPUB、ChinaUnix两大技术社区主办的第15届中国数据库技术大会(DTCC2024)将在朗丽兹西山花园酒店隆重召开。
大会以“自研创新 数智未来”为主题,紧跟时代步伐,引领前沿技术,设置2大主会场,20+技术专场,将邀请超百位行业专家,为广大数据领域从业人士提供一场年度的饕餮盛宴。作为顶级的数据领域技术盛会,DTCC2024将继续秉承一贯的干货分享和最佳实践砥砺前行。
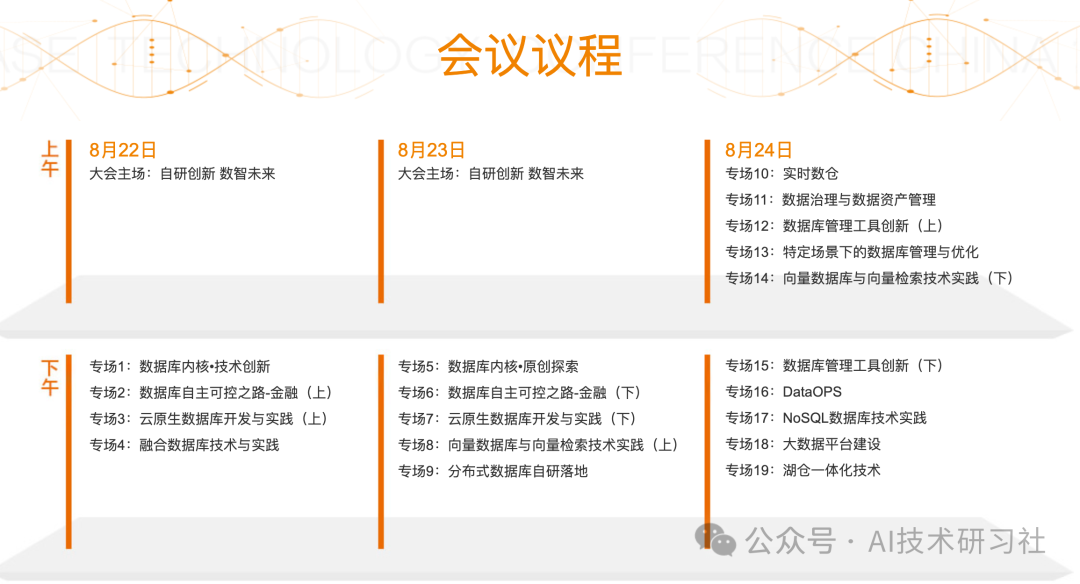
本次,我将重点关注行业向量数据库的动向。如果有对其他数据库感兴趣的朋友,可以自行前往官网计划行程。以下是我整理的向量数据库的相关行程信息。
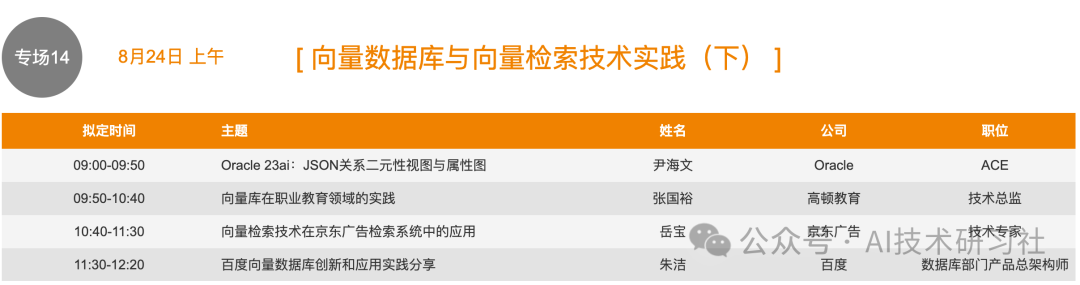
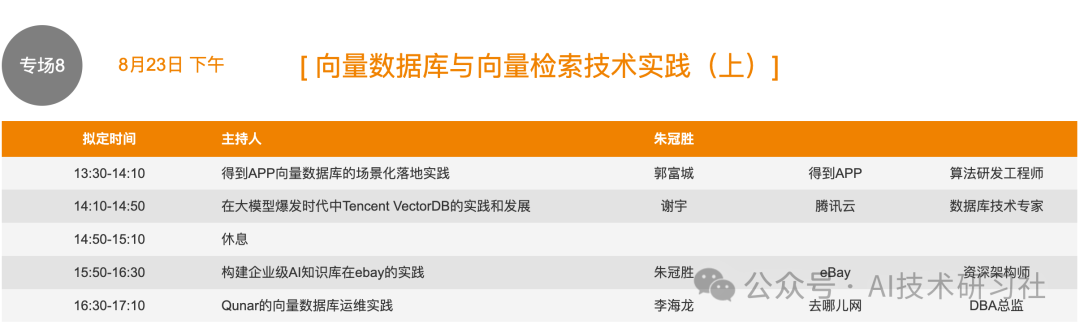
通过国内大厂在向量数据库方面的实践,我们可以获得许多宝贵的经验和见解。向量数据库在处理高维数据、图像识别、自然语言处理等方面表现出色,其性能和效率对企业的智能化转型至关重要。了解最新的技术动向和应用案例,不仅有助于我们掌握先进的技术,还能启发我们在自己的业务中如何更好地应用这些技术。
参加此次大会,可以直接接触到行业的最新研究成果和发展趋势,了解大厂在向量数据库技术上的创新和实践。通过交流,我们可以学习到他们在解决实际问题时的经验和方法,借鉴他们的成功案例,从而提升我们的技术水平和竞争力。
大会也是一个难得的机会,可以结识业内专家和同行,扩展我们的人脉网络,促进行业内的合作与交流。
大会亮点纷呈:
超百位行业专家齐聚一堂:大会将邀请超过百位数据库领域的顶尖专家和学者,分享他们在数据库技术创新与应用实践中的最新成果和宝贵经验。这些嘉宾来自国内外知名企业、高校及研究机构,他们的真知灼见将为参会者带来深刻的行业洞察和技术启发。
前沿技术深度解析:随着人工智能、大数据、云计算等新技术的不断发展和应用,数据库技术也迎来了新的变革。本次大会将围绕数据库内核技术、向量数据库、分布式数据库、云原生数据库等前沿领域展开深入探讨,为参会者揭示未来数据库技术的发展方向。
实践案例广泛分享:大会还将邀请多位来自知名企业的嘉宾分享他们在数据库应用实践中的成功案例。这些案例涵盖了金融、互联网、大数据处理、云计算等多个领域,为参会者提供了丰富的实践经验和借鉴价值。
深入交流与互动:大会设置了多个交流环节,包括主题演讲、技术研讨、圆桌论坛等,为参会者提供与专家学者、业界精英面对面交流和互动的机会。这种深入交流的方式将有助于参会者更好地了解行业动态和技术趋势,拓展人脉资源,提升自身的专业素养和技术水平。
参考资料:
https://developer.aliyun.com/article/1326874
https://www.doit.com.cn/p/515130.html
