




一、动手实践GraphRAG
GraphRAG 是一种结构化、分层的检索增强生成(RAG)方法,与传统的纯文本片段语义搜索方法不同。它通过以下过程实现:
知识图谱提取:从原始文本中提取知识图谱,捕捉文本中的关键实体及其关系。这一步帮助系统理解文本的结构和内容。
构建社区层级:利用知识图谱构建社区层级。社区层级通常描述个体、群体及它们之间的关系,帮助理解信息在社区内的传播、知识的共享以及权力和影响力的分布。
生成社区摘要:为每个社区层级生成摘要,提取关键信息。这些摘要提供了对社区内容的浓缩概览。
利用结构化信息执行 RAG 任务:在执行基于 RAG 的任务时,利用前面生成的结构化信息。这种方法提高了信息检索的精准度和生成的可靠性。
GraphRAG 通过引入知识图谱和社区层级,提升了对复杂信息的理解和处理能力,克服了传统语义搜索方法在纯文本处理中的局限性。

以下是使用 GraphRAG 系统的简单端到端示例。它展示了如何使用系统对一些文本进行索引,然后使用索引数据来回答关于文档的问题。
pip install graphrag
首先让我们准备一个示例数据集:
mkdir -p ./ragtest/input
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt
为了初始化你的工作区,让我们首先运行graphrag.index --init命令。由于我们已经在上一步中配置了一个名为.ragtest`的目录,我们可以运行以下命令:
python -m graphrag.index --init --root ./ragtest
这将在./ragtest目录中创建两个文件:.env和settings.yaml。

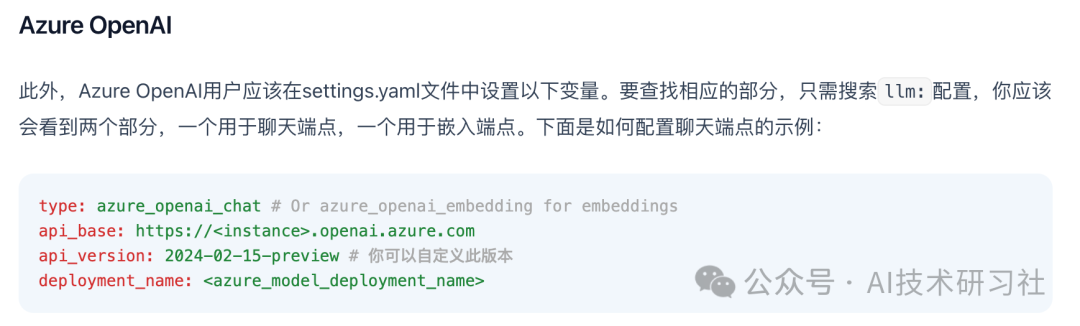
最后我们来运行流程!
python -m graphrag.index --root ./ragtest
这个过程需要一些时间来运行。这取决于你的输入数据大小,你使用的模型以及正在使用的文本块大小(可以在.env文件中进行配置)。一旦流程完成,你应该会看到一个名为./ragtest/output/<timestamp>/artifacts的新文件夹,其中包含一系列parquet文件。
使用全局搜索来提出一个高层次问题的示例:
python -m graphrag.query \--root ./ragtest \--method global \"这个故事的主题是什么?"
使用局部搜索来提出一个关于特定角色的更具体的问题的示例:
python -m graphrag.query \--root ./ragtest \--method local \"Scrooge 这个故事的主人公是谁,他的主要关系是什么?"
二、对大型视觉语言模型的攻击汇总
随着大型模型的飞速发展,大型视觉语言模型(LVLMs)在广泛的多模态理解和推理任务中表现出了卓越的能力。与传统的大型语言模型(LLMsLVLMs)相比,LVLMs因其更接近多资源现实世界的应用和多模态处理的复杂性而具有巨大的潜力和挑战。然而,LVLM的脆弱性相对未得到充分的探索,在日常使用中存在潜在的安全隐患。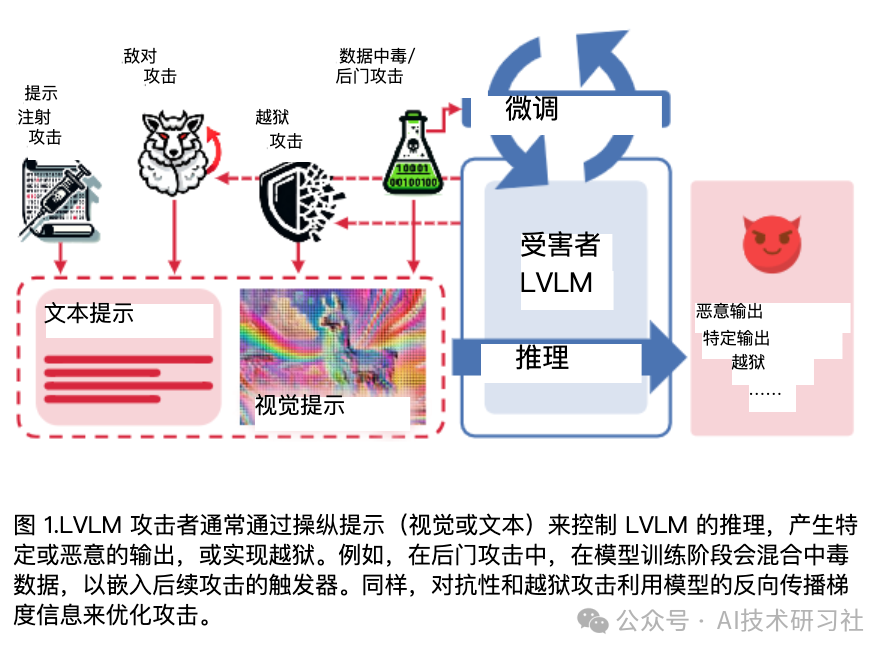
在本文中,我们对现有各种形式的 LVLM 攻击进行了全面回顾。具体来说,我们首先介绍了针对LVLM的攻击背景,包括攻击的初步情况、攻击挑战和攻击资源。
然后,系统梳理了LVLM攻击方法的发展历程,如操纵模型输出的对抗性攻击、利用模型漏洞进行非法操作的越狱攻击、设计提示类型和模式的提示注入攻击、影响模型训练的数据中毒等。
最后,我们讨论了未来有前途的研究方向。我们相信,我们的调查提供了对 LVLM 漏洞当前状况的洞察,激励更多研究人员探索和缓解 LVLM 开发中的潜在安全问题。
现有的LVLM攻击者通常可以分为四种类型:对抗攻击、越狱攻击、提示注入攻击和数据投毒/后门攻击。每种类别对应的代表性论文如下图所示:
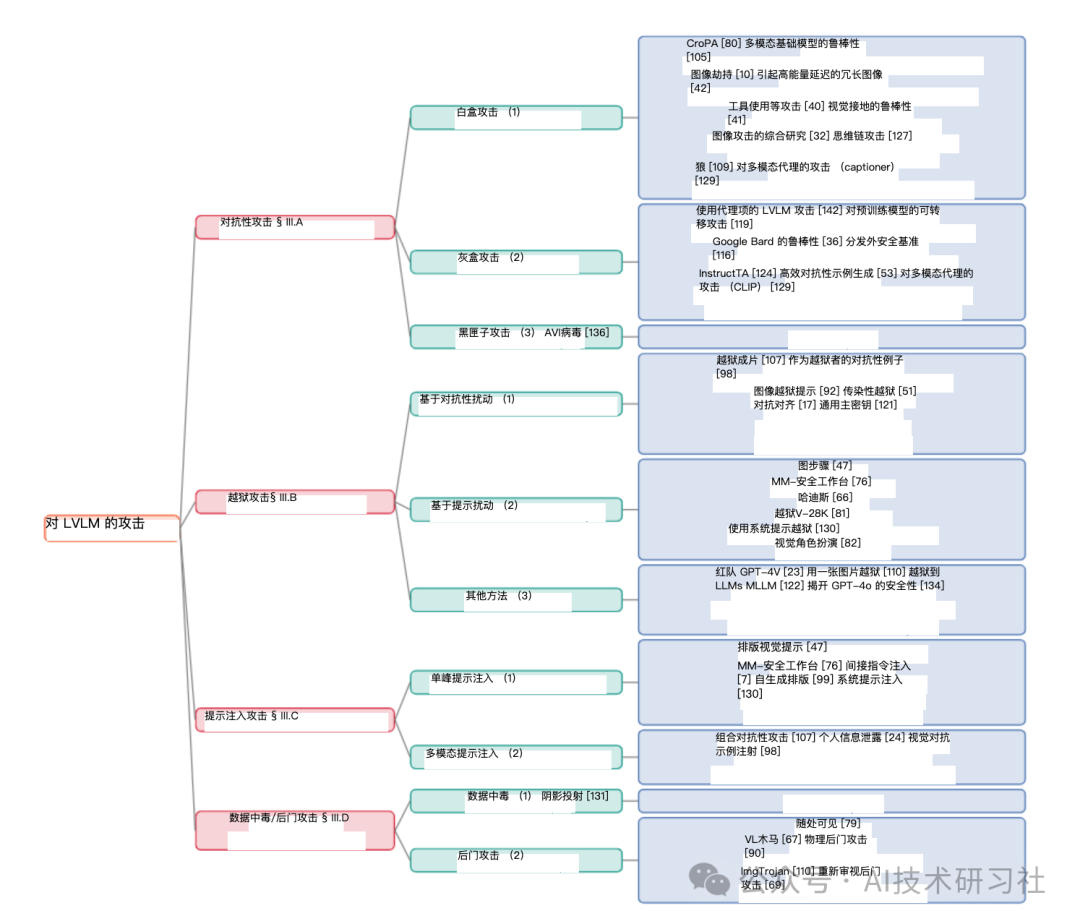
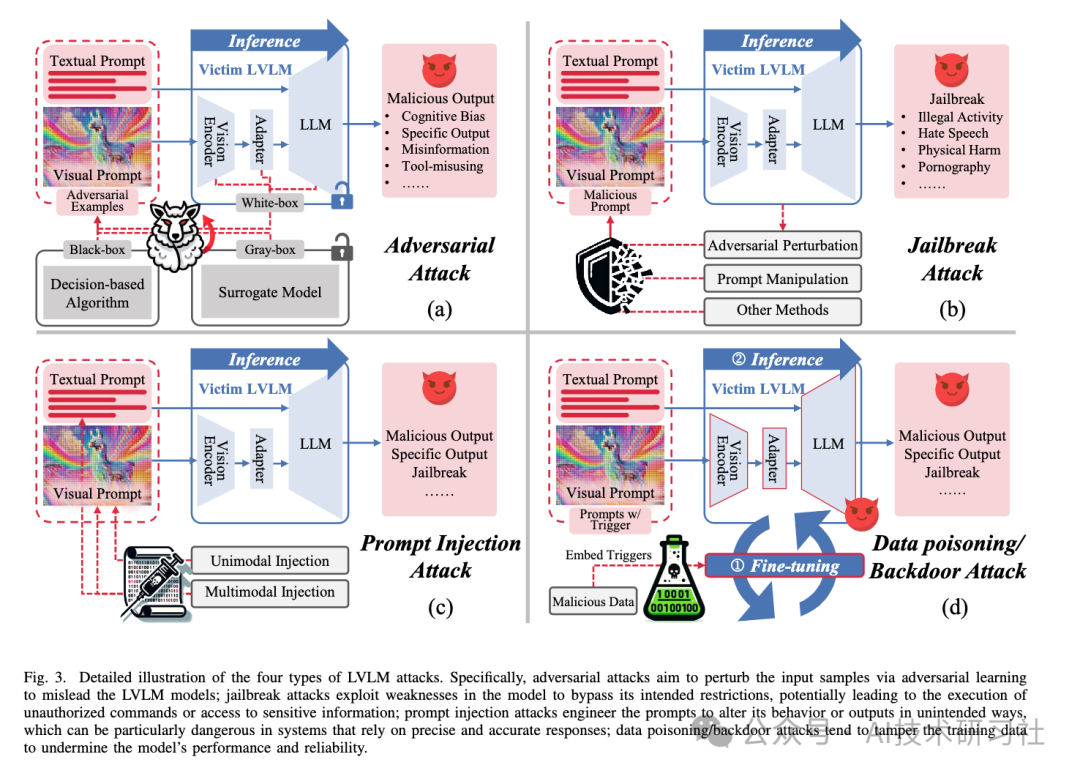
4种方法的对比图:
当前LVLM攻击多局限于数字环境,忽略了现实世界中人类与AI系统的交互性。为此,结合人类智能与AI能力成为实施新型攻击的有效路径。
比如(1)人机协作攻击:结合人类智慧和AI能力,人类发现并利用模型弱点,AI则优化攻击策略,两者协同工作以增强攻击效果。(2)利用社会工程学原理,结合用户行为和心理,设计欺骗性输入,同时影响模型和用户,达到操纵目的。
三、LLM攻击方法总结
对于LLM攻击方法,通常可以分为以下几个类别:
数据污染攻击:通过向训练数据注入恶意数据,影响模型的决策过程。
模型逆向工程:尝试从模型的输出推断训练数据或内部结构信息。
对抗性攻击:生成特定的输入样本,使得模型以错误的方式进行分类或决策。
模型窃取攻击:通过查询模型来复制其功能,实现模型的非法复制。
多模态攻击:针对处理多种类型数据(如文本、图像、音频)的模型,利用不同模态间的相互作用进行攻击。
这些攻击方法的共性可能包括但不限于:
隐蔽性:攻击者试图使攻击行为不易被发现。
有效性:攻击能够在有限的查询或数据注入下成功影响模型。
可转移性:攻击方法能够在不同的模型或数据集上复现。
对于新手来说,了解这些攻击方法的分类和特点,可以帮助他们更好地理解LLM的潜在风险,并学习如何设计和实施有效的防御措施。同时,这也为研究人员提供了一个框架,以系统地探索和改进模型的安全性。
四、大模型最新、有趣的事
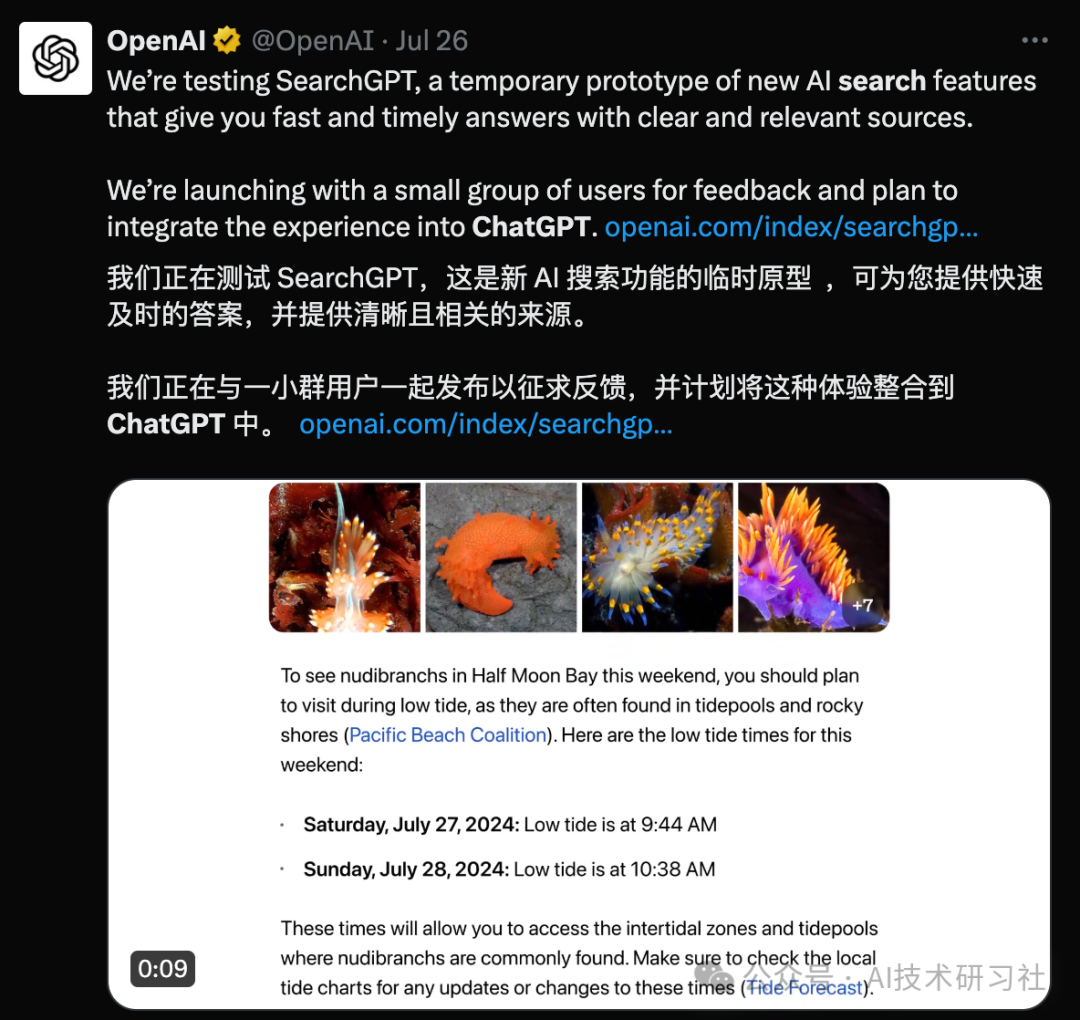
SearchGPT,这是新 AI 搜索功能的临时原型,可为您提供快速及时的答案,并提供清晰且相关的来源。
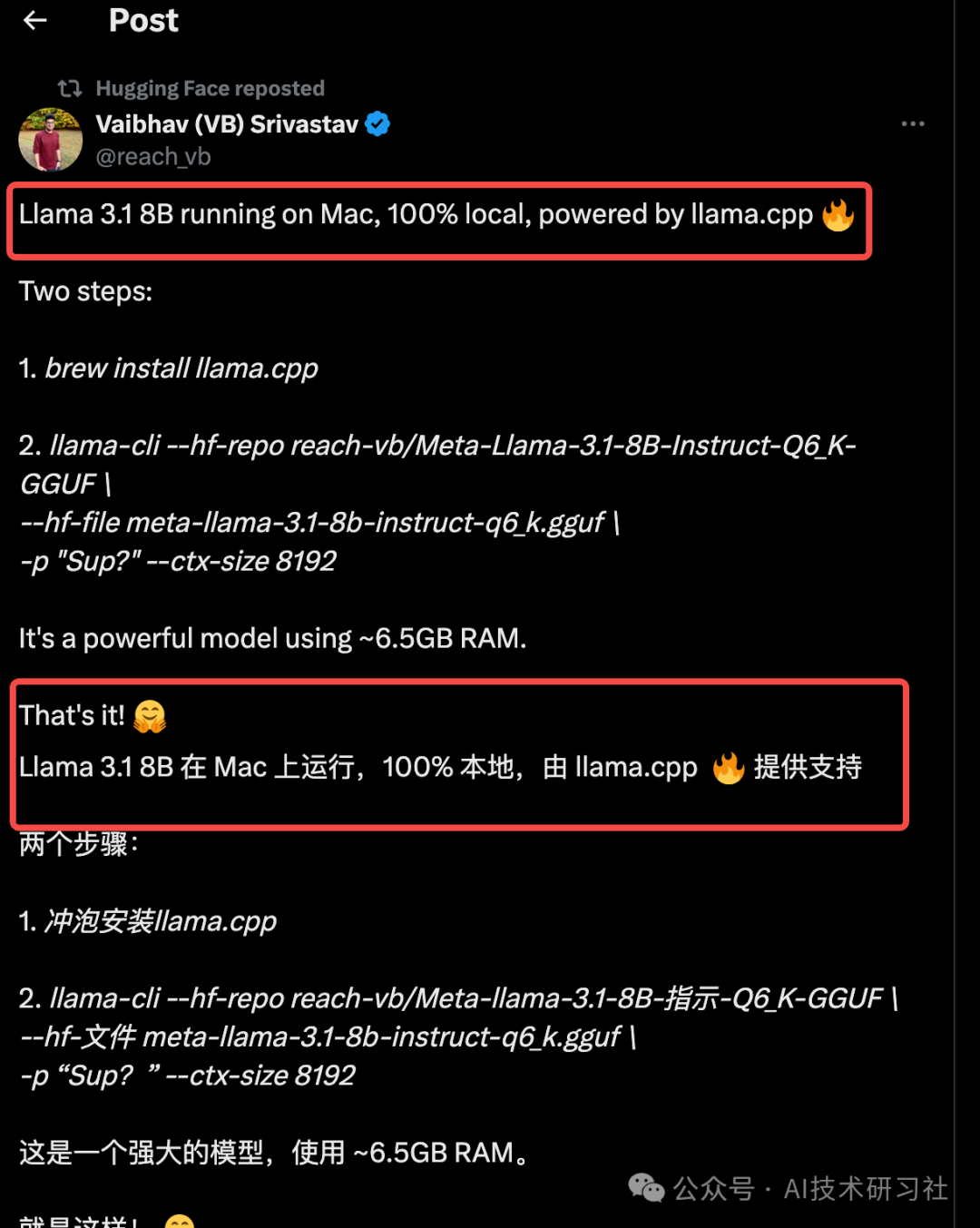
Llama 3.1 8B 在 Mac 上运行,100% 本地,由 llama.cpp  提供支持
提供支持
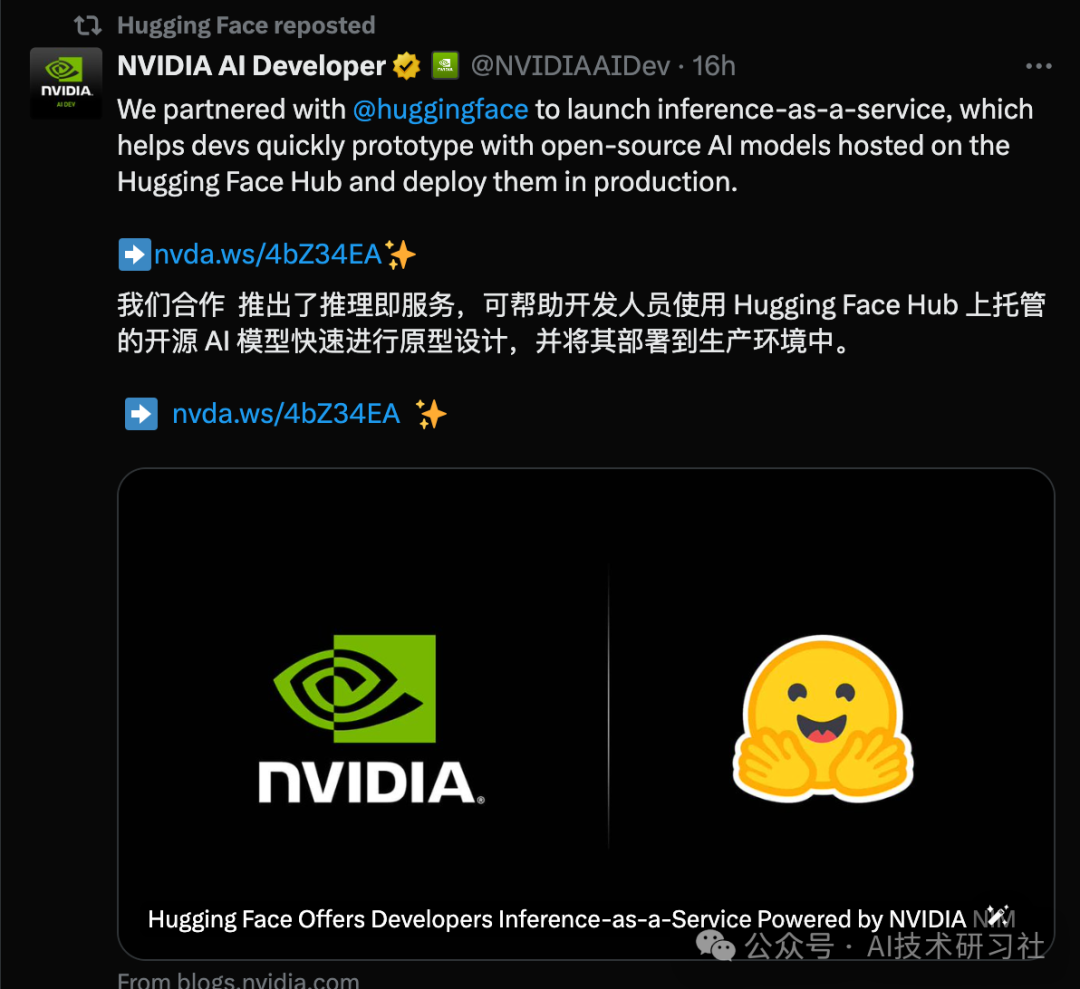
真的很不错的开发 推出由 NVIDIA NIM 提供支持的 Hugging Face 推理即服务,这是 Hugging Face Hub 上的一项新服务。
因此, NVIDIA NIM 是一种推理微服务, 它以优化容器的形式提供模型, 部署在云端, 数据中心或工作站上, 使他们能够在几分钟而不是几周内轻松为副驾驶、聊天机器人等构建生成式 AI 应用程序。
最大限度地提高基础设施投资和计算效率。例如,在 NIM 中运行 Meta Llama 3-8B 在加速基础设施上产生的生成式 AI 代币比没有 NIM 多 3 倍。
NIM 容器是预构建的,可加快 GPU 加速推理的模型部署,并可包括 NVIDIA CUDA® 软件、NVIDIA Triton 推理服务器™和 NVIDIA TensorRT™LLM 软件。
许多社区模型都可以作为 ai.nvidia. com 上的 NIM 端点进行体验,包括 Meta Llama 3.1、Databricks DBRX、Google 的开放模型 Gemma、Meta Llama 3、Microsoft Phi-3、Mistral Large、Mixtral 8x22B 和 Snowflake Arctic。
参考资料:
https://microsoft.github.io/graphrag/posts/get_started/
https://github.com/microsoft/graphrag
https://x.com/rohanpaul_ai/status/1818124434852712503
