




随着AI的快速发展,开发者往往面临一个选择的悖论:如何选择正确的提示,如何权衡LLM质量与成本?评估可以通过结构化的流程来做出这些决策,从而加速开发。
下面介绍如何使用LangSmith进行评估,并讨论工作流程的每一部分。
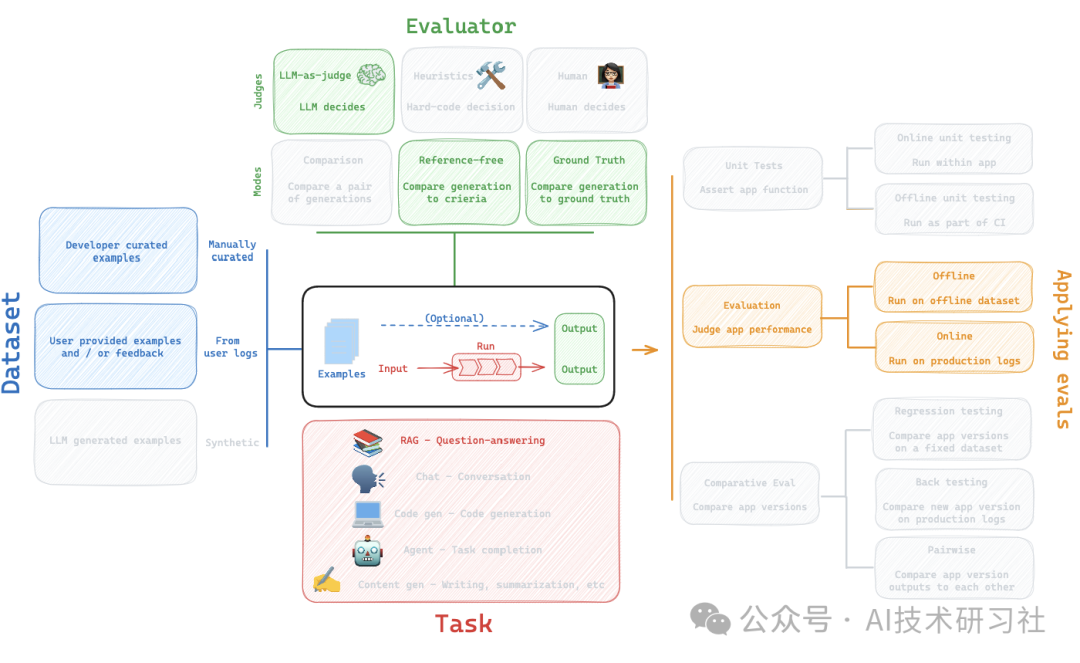
一、准备数据集
在 LangSmith UI 中使用 csv 上传创建的数据集。
https://smith.langchain.com/public/730d833b-74da-43e2-a614-4e2ca2502606/d
在这里,我们确保设置了 OpenAI 和 LangSmith 的 API 密钥。
import getpassimport osdef _set_env(var: str):if not os.environ.get(var):os.environ[var] = getpass.getpass(f"{var}: ")_set_env("OPENAI_API_KEY")os.environ["LANGCHAIN_TRACING_V2"] = "true"os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" # Update appropriately for self-hosted installations or the EU region_set_env("LANGCHAIN_API_KEY")
指定数据集的名称。
### Dataset namedataset_name = "LCEL-QA"
二、创建Task任务
接下来,使用LangChain来创建检索器并检索相关文档。
### INDEXfrom bs4 import BeautifulSoup as Soupfrom langchain_community.vectorstores import Chromafrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitter# Load docsurl = "https://python.langchain.com/v0.1/docs/expression_language/"loader = RecursiveUrlLoader(url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text)docs = loader.load()# Split into chunkstext_splitter = RecursiveCharacterTextSplitter(chunk_size=4500, chunk_overlap=200)splits = text_splitter.split_documents(docs)# Embed and store in Chromavectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# Indexretriever = vectorstore.as_retriever()
创建聊天机器人。
### RAG botimport openaifrom langsmith import traceablefrom langsmith.wrappers import wrap_openaiclass RagBot:def __init__(self, retriever, model: str = "gpt-4-0125-preview"):self._retriever = retriever# Wrapping the client instruments the LLMself._client = wrap_openai(openai.Client())self._model = model@traceable()def retrieve_docs(self, question):return self._retriever.invoke(question)@traceable()def invoke_llm(self, question, docs):response = self._client.chat.completions.create(model=self._model,messages=[{"role": "system","content": "You are a helpful AI code assistant with expertise in LCEL."" Use the following docs to produce a concise code solution to the user question.\n\n"f"## Docs\n\n{docs}",},{"role": "user", "content": question},],)# Evaluators will expect "answer" and "contexts"return {"answer": response.choices[0].message.content,"contexts": [str(doc) for doc in docs],}@traceable()def get_answer(self, question: str):docs = self.retrieve_docs(question)return self.invoke_llm(question, docs)rag_bot = RagBot(retriever)
response = rag_bot.get_answer("How to build a RAG chain in LCEL?")response["answer"][:150]
def predict_rag_answer(example: dict):"""Use this for answer evaluation"""response = rag_bot.get_answer(example["input_question"])return {"answer": response["answer"]}def predict_rag_answer_with_context(example: dict):"""Use this for evaluation of retrieved documents and hallucinations"""response = rag_bot.get_answer(example["input_question"])return {"answer": response["answer"], "contexts": response["contexts"]}
三、创建评估器
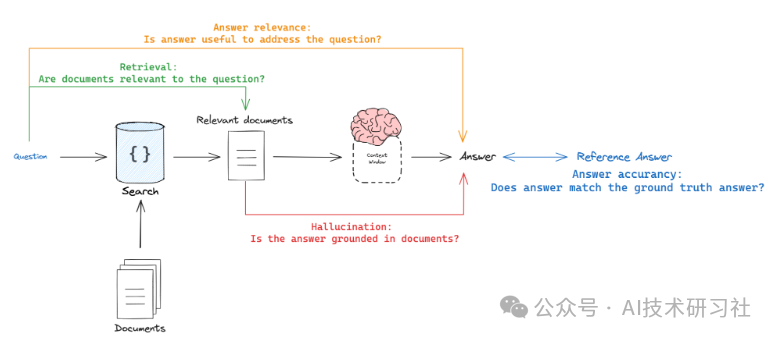
下面介绍4 种类型的 RAG 评估。
1. 响应与参考答案
目标:衡量“RAG 链答案相对于真实答案的相似/正确程度”。
模式:使用通过数据集提供的真值(参考)答案。
评判:使用 LLM-as-judge 来评估答案的正确性。
参考:https://smith.langchain.com/hub/langchain-ai/rag-answer-vs-reference
from langchain import hubfrom langchain_openai import ChatOpenAI# Grade promptgrade_prompt_answer_accuracy = prompt = hub.pull("langchain-ai/rag-answer-vs-reference")def answer_evaluator(run, example) -> dict:"""A simple evaluator for RAG answer accuracy"""# Get question, ground truth answer, RAG chain answerinput_question = example.inputs["input_question"]reference = example.outputs["output_answer"]prediction = run.outputs["answer"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_answer_accuracy | llm# Run evaluatorscore = answer_grader.invoke({"question": input_question,"correct_answer": reference,"student_answer": prediction})score = score["Score"]return {"key": "answer_v_reference_score", "score": score}
from langsmith.evaluation import evaluateexperiment_results = evaluate(predict_rag_answer,data=dataset_name,evaluators=[answer_evaluator],experiment_prefix="rag-answer-v-reference",metadata={"version": "LCEL context, gpt-4-0125-preview"},)
响应与输入
目标:衡量“生成的响应对初始用户输入的处理程度”。
模式:无引用,因为它会将答案与输入问题进行比较。
评判:使用 LLM-as-judge 来评估答案的相关性、帮助性等。
参考:https://smith.langchain.com/hub/langchain-ai/rag-answer-helpfulness
# Grade promptgrade_prompt_answer_helpfulness = prompt = hub.pull("langchain-ai/rag-answer-helpfulness")def answer_helpfulness_evaluator(run, example) -> dict:"""A simple evaluator for RAG answer helpfulness"""# Get question, ground truth answer, RAG chain answerinput_question = example.inputs["input_question"]prediction = run.outputs["answer"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_answer_helpfulness | llm# Run evaluatorscore = answer_grader.invoke({"question": input_question,"student_answer": prediction})score = score["Score"]return {"key": "answer_helpfulness_score", "score": score}
experiment_results = evaluate(predict_rag_answer,data=dataset_name,evaluators=[answer_helpfulness_evaluator],experiment_prefix="rag-answer-helpfulness",metadata={"version": "LCEL context, gpt-4-0125-preview"},)
响应与检索到的文档
目标:衡量“生成的响应与检索到的上下文在多大程度上一致”。
模式:无引用,因为它会将答案与检索到的上下文进行比较。
评判:使用 LLM-as-judge 来评估忠诚度、幻觉等。
参考:https://smith.langchain.com/hub/langchain-ai/rag-answer-hallucination
# Promptgrade_prompt_hallucinations = prompt = hub.pull("langchain-ai/rag-answer-hallucination")def answer_hallucination_evaluator(run, example) -> dict:"""A simple evaluator for generation hallucination"""# RAG inputsinput_question = example.inputs["input_question"]contexts = run.outputs["contexts"]# RAG answerprediction = run.outputs["answer"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_hallucinations | llm# Get scorescore = answer_grader.invoke({"documents": contexts,"student_answer": prediction})score = score["Score"]return {"key": "answer_hallucination", "score": score}
检索到的文档与输入
目标:衡量“我对此查询检索到的结果有多好”。
模式:无引用,因为它会将问题与检索到的上下文进行比较。
评判:使用 LLM-as-judge 评估相关性。
参考:https://smith.langchain.com/hub/langchain-ai/rag-document-relevance
# Grade promptgrade_prompt_doc_relevance = hub.pull("langchain-ai/rag-document-relevance")def docs_relevance_evaluator(run, example) -> dict:"""A simple evaluator for document relevance"""# RAG inputsinput_question = example.inputs["input_question"]contexts = run.outputs["contexts"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_doc_relevance | llm# Get scorescore = answer_grader.invoke({"question":input_question,"documents":contexts})score = score["Score"]return {"key": "document_relevance", "score": score}
experiment_results = evaluate(predict_rag_answer_with_context,data=dataset_name,evaluators=[docs_relevance_evaluator],experiment_prefix="rag-doc-relevance",metadata={"version": "LCEL context, gpt-4-0125-preview"},)
四、评估中间步骤
虽然在许多情况下,评估任务的最终输出就足够了,但在某些情况下,你可能想要评估管道的中间步骤。
例如,对于检索增强生成 (RAG),您可能希望:
评估检索步骤,以确保在输入查询中检索到正确的文档。
评估生成步骤,以确保在检索到的文档中生成正确的答案。
from langsmith.schemas import Example, Runfrom langsmith.evaluation import evaluatedef document_relevance_grader(root_run: Run, example: Example) -> dict:"""A simple evaluator that checks to see if retrieved documents are relevant to the question"""# Get specific steps in our RAG pipeline, which are noted with @traceable decoratorrag_pipeline_run = next(run for run in root_run.child_runs if run.name == "get_answer")retrieve_run = next(run for run in rag_pipeline_run.child_runs if run.name == "retrieve_docs")contexts = "\n\n".join(doc.page_content for doc in retrieve_run.outputs["output"])input_question = example.inputs["input_question"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_doc_relevance | llm# Get scorescore = answer_grader.invoke({"question":input_question,"documents":contexts})score = score["Score"]return {"key": "document_relevance", "score": score}def answer_hallucination_grader(root_run: Run, example: Example) -> dict:"""A simple evaluator that checks to see the answer is grounded in the documents"""# RAG inputrag_pipeline_run = next(run for run in root_run.child_runs if run.name == "get_answer")retrieve_run = next(run for run in rag_pipeline_run.child_runs if run.name == "retrieve_docs")contexts = "\n\n".join(doc.page_content for doc in retrieve_run.outputs["output"])# RAG outputprediction = rag_pipeline_run.outputs["answer"]# LLM graderllm = ChatOpenAI(model="gpt-4-turbo", temperature=0)# Structured promptanswer_grader = grade_prompt_hallucinations | llm# Get scorescore = answer_grader.invoke({"documents": contexts,"student_answer": prediction})score = score["Score"]return {"key": "answer_hallucination", "score": score}experiment_results = evaluate(predict_rag_answer,data=dataset_name,evaluators=[document_relevance_grader, answer_hallucination_grader],metadata={"version": "LCEL context, gpt-4-0125-preview"},)
分享一个很好的RAG课程:https://www.youtube.com/watch?v=wd7TZ4w1mSw&list=PLfaIDFEXuae2LXbO1_PKyVJiQ23ZztA0x&index=1
参考文档:
https://docs.smith.langchain.com/tutorials/Developers/rag
https://docs.smith.langchain.com/how_to_guides/evaluation/evaluate_on_intermediate_steps
https://github.com/langchain-ai/rag-from-scratch
