




过去一周可谓是小模型战场最疯狂的一周,商业巨头们纷纷改变赛道,向大模型say 88~。
OpenAI、Apple、Mistral等各大公司“百花齐放”,竞相推出自家性能优越的轻量化小模型。
小模型相较于大模型有以下几大优势:
计算资源需求低:小模型对计算资源的需求较低,适合在资源受限的设备上运行,如移动设备和边缘计算设备。
部署成本低:由于对硬件要求较低,小模型的部署成本更低,适合中小企业和个人开发者使用。
响应速度快:小模型通常具有更快的推理速度,可以提供更及时的响应,提升用户体验。
易于训练和更新:小模型所需的训练数据和时间较少,更新更为频繁和灵活,有助于快速迭代和优化模型。
能耗低:由于计算量减少,小模型的能耗更低,有助于节能环保,延长设备的续航时间。
适应性强:小模型更适合特定任务或领域,可以针对具体应用进行优化,提升准确性和效果。
隐私保护:在设备端运行的小模型可以减少数据传输量,有助于提高数据隐私和安全性。
这些优势使得小模型在特定场景下具有显著的竞争力,成为各大技术公司和开发者关注的焦点。

虽然小模型在效率方面具有独特的优势,但由于参数量的限制,它们在许多任务上的处理能力可能无法与大语言模型匹敌。
各类模型都有其独特的优劣势。在未来的AI发展中,无论是大模型还是小模型,都有其不可替代的作用。关键在于找到模型规模、性能和具体应用需求之间的平衡,从而充分发挥它们的最大价值。
下面重点看看,苹果公司的人工智能团队和华盛顿大学等多家机构合作,推出一款名叫 DCLM的开源语言模型。
DCLM-Baseline-7B 是在 DCLM-Baseline 数据集上训练的 70 亿参数语言模型,该数据集是作为 DataComp for Language Models (DCLM) 基准测试的一部分进行策划的。该模型旨在展示系统数据管理技术在提高语言模型性能方面的有效性。

首次安装open_lm
pip install git+https://github.com/mlfoundations/open_lm.git
from open_lm.hf import *from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("apple/DCLM-Baseline-7B")model = AutoModelForCausalLM.from_pretrained("apple/DCLM-Baseline-7B")inputs = tokenizer(["Machine learning is"], return_tensors="pt")gen_kwargs = {"max_new_tokens": 50, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}output = model.generate(inputs['input_ids'], **gen_kwargs)output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)print(output)
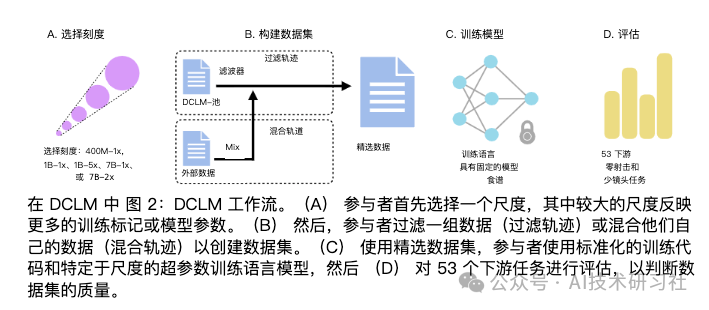
引入了 DataComp for Language Models (DCLM),这是一个用于受控数据集实验的测试平台,旨在改进语言模型。
作为 DCLM 的一部分,我们提供从 Common Crawl 中提取的 240T 令牌的标准化语料库、基于 OpenLM 框架的有效预训练配方,以及一套包含 53 个下游评估的广泛套件。
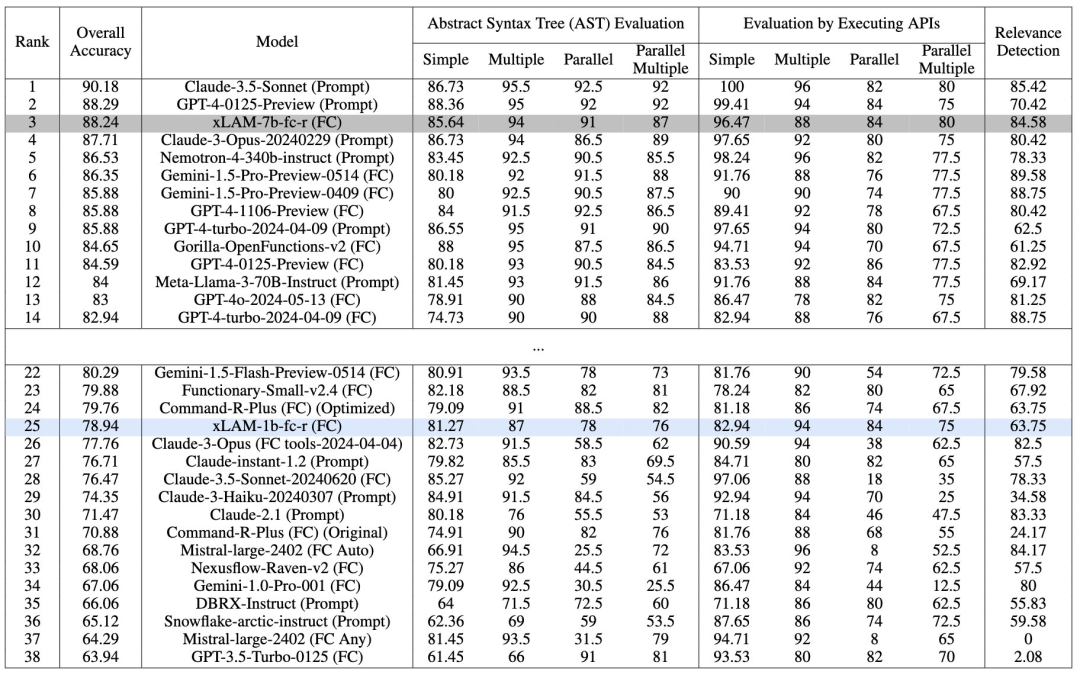
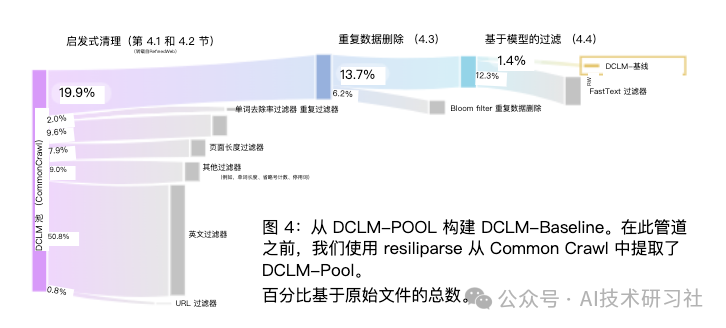
DCLM 基准测试的参与者可以在 412M 到 7B 参数的模型规模上试验数据管理策略,例如重复数据删除、过滤和数据混合。作为 DCLM 的基线,我们进行了大量的实验,发现基于模型的过滤是组装高质量训练集的关键。
由此产生的数据集 DCLMBASELINE 可以使用 2.6T 训练令牌在 MMLU 上从头开始训练 7B 参数语言模型,达到 64% 的 5 次准确率。与MAP-Neo(以前最先进的开放数据语言模型)相比,DCLM-BASELINE 比 MMLU 提高了 6.6 个百分点,同时训练的计算量减少了 40%。
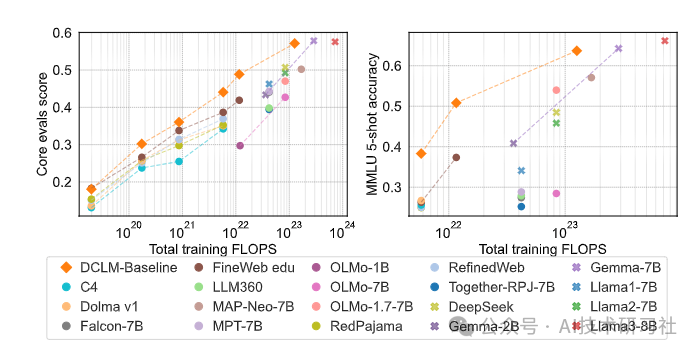
我们的基线模型也与MMLU上的Mistral-7B-v0.3和Llama 3 8B相当(63%和66%),并且在平均53个自然语言理解任务中执行相似,同时接受训练的计算能力比Llama 3 8B少6.6×。
我们的研究结果强调了数据集设计对于训练语言模型的重要性,并为进一步研究数据管理提供了一个起点。
我们在 https://datacomp.ai/dclm 发布 DCLM 基准、框架、模型和数据集。
由于计算限制,我们只能单独消融设计维度,无法在更大的规模上测试所有方法。此外,DCLM-Baseline还有许多我们没有探索的变体。
例如,更详细地了解分片重复数据删除的影响非常重要,并且有更多方法可以训练过滤模型,无论是在其架构方面还是在训练数据方面。我们还只使用一个标记器(GPT-NeoX)进行了大部分实验,其他标记器可能在多语言任务或数学上表现更好。
另一个限制是,我们无法充分探索不同随机种子的运行间变化。尽管如此,我们仍然希望这篇论文是进一步研究数据管理的起点,将最先进的技术推向DCLM-BASELINE之外。
虽然我们在DCLM-Baseline上训练的模型在通用语言理解评估中具有竞争力,但它们目前在代码和数学方面的表现不如预期。

