




Embedding 是一种将高维稀疏数据映射到低维稠密空间的技术。这种技术广泛应用于自然语言处理(NLP)、推荐系统、图像处理等领域,用于将离散的、稀疏的输入数据(如词汇、用户ID、物品ID)转化为密集的、连续的向量表示。
在使用RAG(Retrieval-Augmented Generation)技术时,我们常常会遇到一个关于如何选择合适的中文Embedding模型的问题。中文Embedding模型在RAG技术中非常关键,因为它们直接影响到信息检索的效果和生成文本的质量。
当你去搜索中文Embedding模型时,你会在哪儿搜索呢?会发现市面上有很多种选择,该如何选择适合的中文Embedding模型呢?
其实,选择的过程就是一个软件选型的过程,值得重视。
下面,我将在本文详细介绍通过Huggingface筛选中文Embedding的过程。
第一步:打开Huggingface官网:https://huggingface.co/,进入首页。
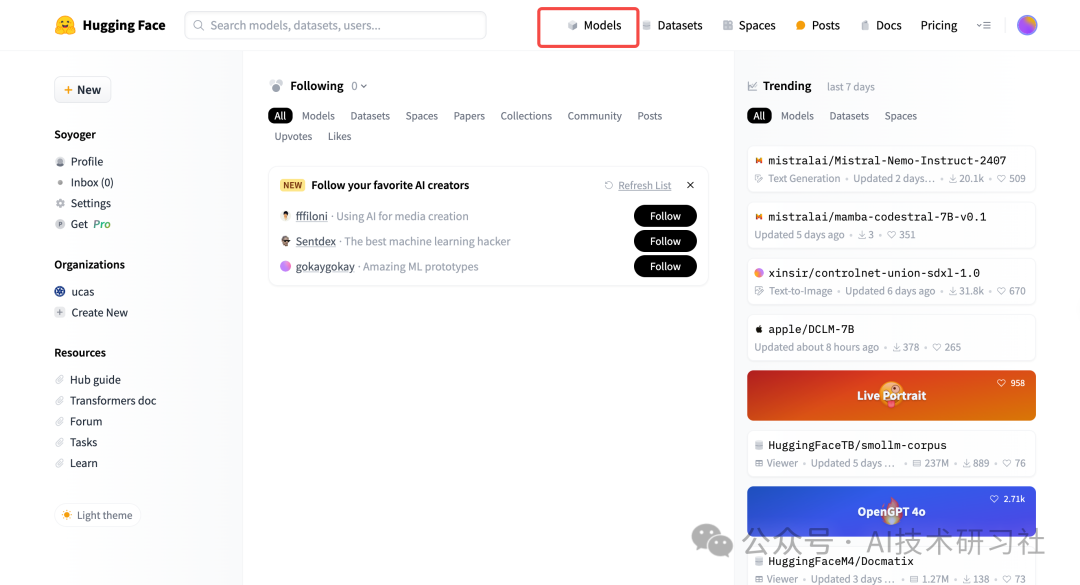
第二步:点击Models,这里包含Huggingface上所有的开源模型。
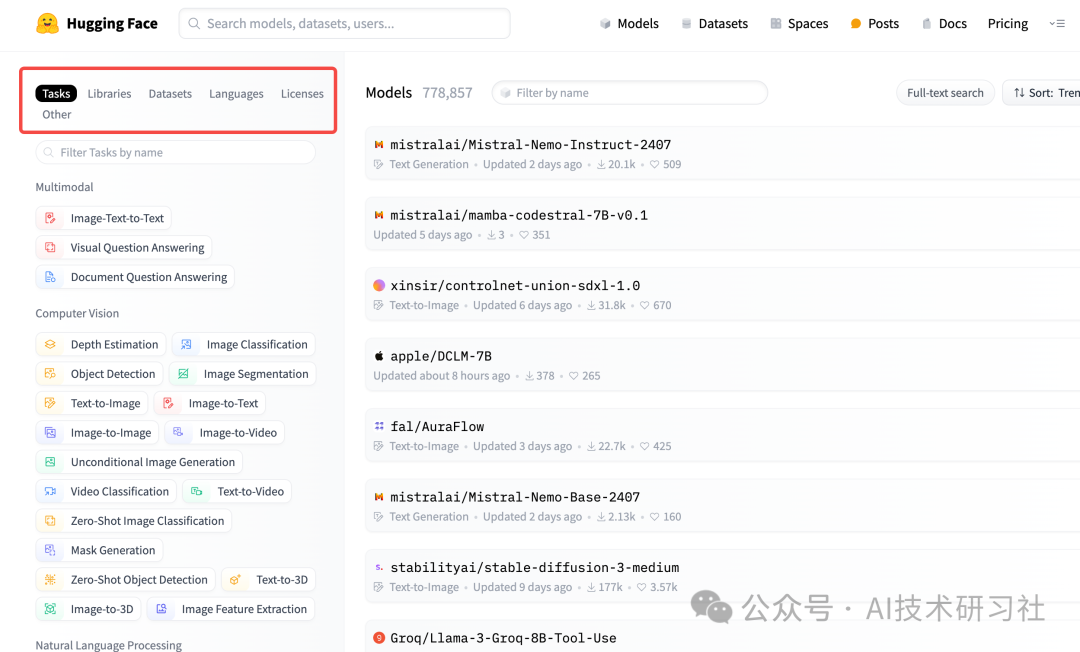
第三步:在Languages中选择 chinese 中文。
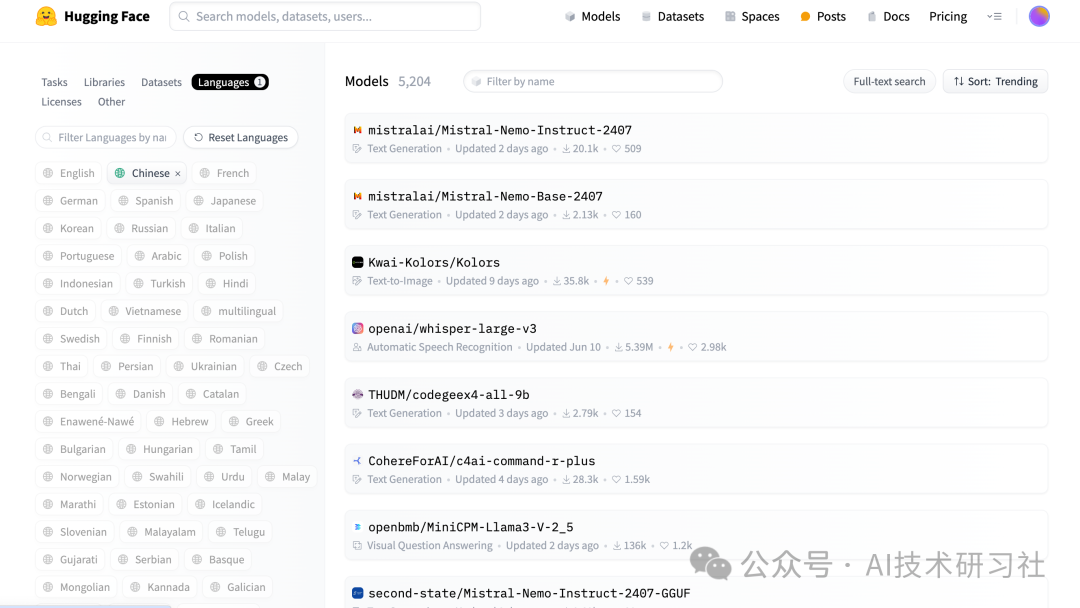
第四步:搜索embedding,可以看到很多开源的中文Embedding模型。
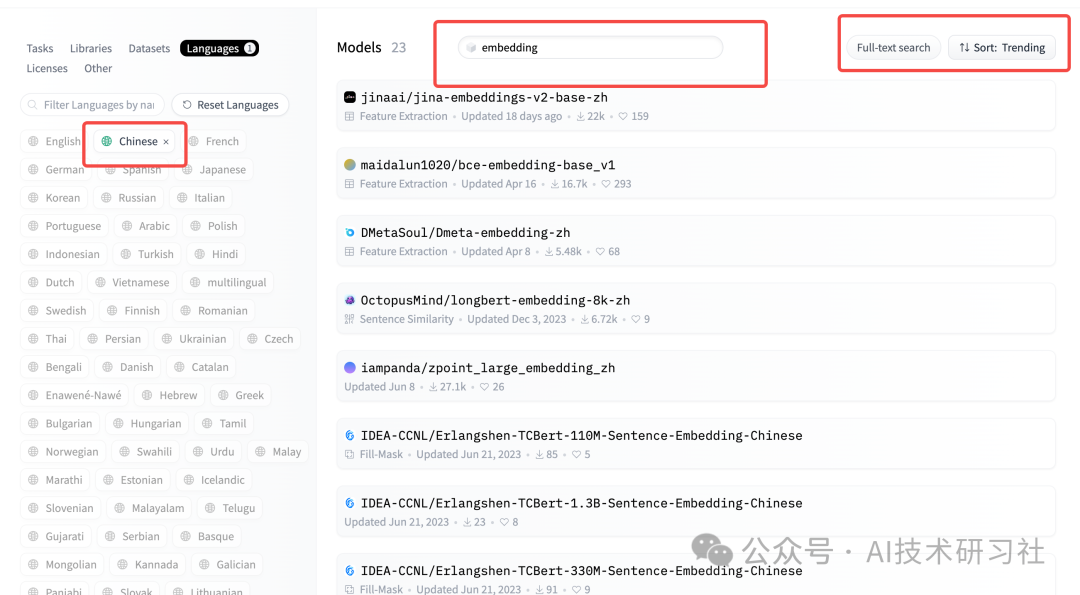
第5步:排序。
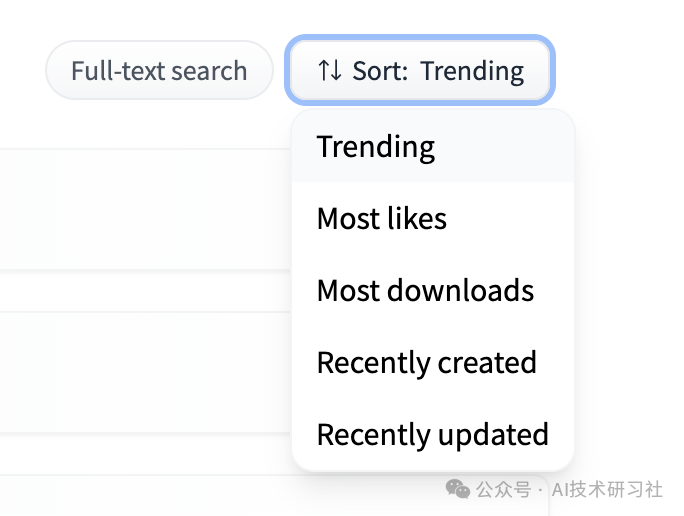
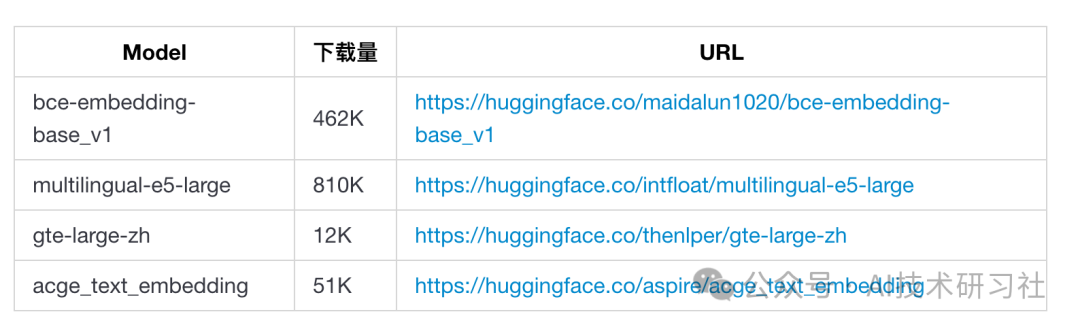
第6步:我们根据下载量来选择下载量比较大的embedding模型。(根据大数据来说,下载量最多的,被大多数人认可,效果理论上还可以。)
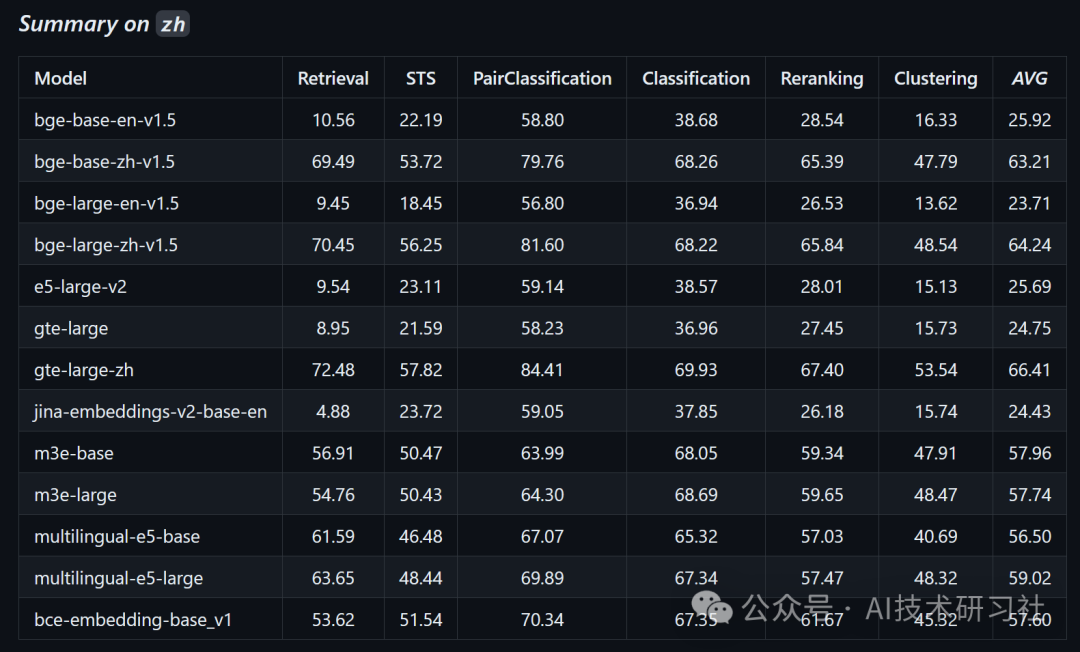
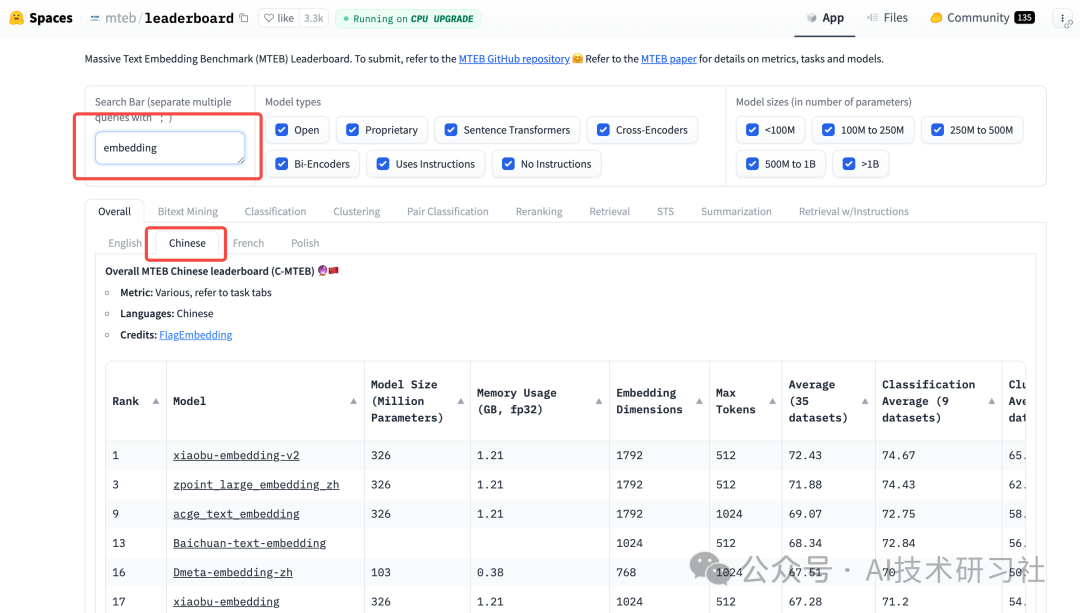
第7步:依据HuggingFace的测评榜上进行选择。
打开测评榜:https://huggingface.co/spaces/mteb/leaderboard
这里既包含开源,也包含API,鱼目混杂,需要进一步验证和确认。
当然除了按照下载量和测评结果,还需要考量比如模型的性能、处理速度,vector维度大小等。下面我总结了一些不同维度进行选型的标准,主要包括以下几个方面:
模型性能:这是最重要的标准之一。性能优异的Embedding模型能够提供更准确的向量表示,从而提高信息检索的准确性和生成文本的质量。
处理速度:模型的计算效率也非常关键。处理速度快的模型可以在实际应用中显著提升系统的响应速度,从而改善用户体验。
向量维度大小:Embedding向量的维度大小直接影响到模型的存储和计算成本。较高的维度可以捕捉更多的细节信息,但也会增加计算开销。因此,需要在维度大小和性能之间找到一个平衡点。
适用性:不同的Embedding模型在不同的应用场景下表现各异。选择适合具体任务的模型可以显著提升效果。例如,对于文本生成任务,某些模型可能比其他模型表现更优。
训练数据和方法:Embedding模型的训练数据和方法也会影响其性能和适用性。基于大规模、高质量语料训练的模型通常具有更好的泛化能力。
可扩展性:在处理大量数据或需要频繁更新模型的场景中,模型的可扩展性至关重要。可扩展性好的模型可以更方便地进行扩展和更新。
兼容性:考虑Embedding模型与现有系统和工具的兼容性,以确保模型能够无缝集成到现有工作流中。
社区和支持:选择有活跃社区和良好支持的Embedding模型,可以更方便地获取帮助和资源,解决使用过程中遇到的问题。
m3e-base 是我早期在生产环境使用过的一个Embedding开源模型,下面演示如何在本地化加载和运行。要使用 Hugging Face 加载开源模型 m3e-base 并进行本地化部署,可以按照以下步骤进行:
安装依赖:确保安装了必要的 Python 包,如 transformers 和 torch。
加载模型:使用 Hugging Face 的 transformers 库来加载模型。
进行推理:使用模型进行嵌入生成。
本地部署:可以使用 Flask 或 FastAPI 等框架进行本地部署。
完整的代码如下:
from transformers import AutoModel, AutoTokenizer# 加载 tokenizer 和模型tokenizer = AutoTokenizer.from_pretrained("m3e-base")model = AutoModel.from_pretrained("m3e-base")# 示例文本text = "这是一个测试句子。"# 对输入文本进行编码inputs = tokenizer(text, return_tensors="pt")# 生成嵌入with torch.no_grad():outputs = model(**inputs)embeddings = outputs.last_hidden_state.mean(dim=1)print(embeddings)
通过上述步骤,你可以加载 Hugging Face 的 m3e-base 模型,并进行本地化部署。你可以根据实际需求进一步优化和扩展这些代码。
参考:
1. https://huggingface.co/spaces/mteb/leaderboard
2. https://qanything.ai/docs/architecture
如果这些内容对你有用,可以关注我:

