




在当前人工智能快速发展的时代,掌握大模型技术已成为许多技术爱好者和专业人士的目标。然而,理论知识固然重要,真正让你脱颖而出的是动手实践。通过实际操作,你不仅能更深入地理解这些技术,还能开发出有价值的应用。
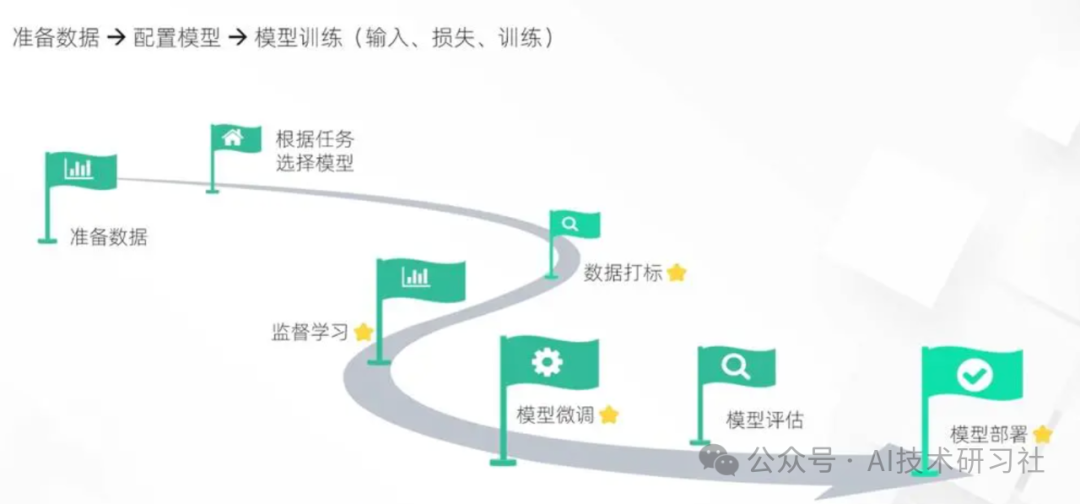
学习大模型的相关知识以来,我一直都想从头训练一个1B以下的模型,感觉这样才算是真的掌握了大模型。然而,考虑到手头的资源,我只能玩玩迷你的小模型。
首先,面对日新月异的技术发展,我们需要树立一个清晰的学习目标,而不能迷失和沉溺于技术的表面。掌握大模型的关键在于动手实践,通过实际操作,才能真正理解和运用这些先进的技术。只有这样,才能在技术的浪潮中站稳脚跟,并不断提升自己的能力。

理论知识固然重要,但实践更能让你真正掌握大模型技术。通过动手操作,你不仅能理解模型的工作原理,还能开发出有实际应用价值的项目。以下是一些具体的实践建议:
试用不同的大语言模型:从OpenAI的GPT系列到Google的BERT和T5,再到MetaAI的LAMMA系列,大语言模型种类繁多。试用这些模型,了解它们各自的优缺点和适用场景,是你迈出实践的第一步。
要试用ChatGPT,你可以使用OpenAI的API,并通过Python代码与模型进行交互。以下是一个简单的例子,演示如何使用Python与ChatGPT进行对话:
import openai# 设置OpenAI API密钥openai.api_key = '你的API密钥'# 定义一个函数来与ChatGPT交互def chat_with_gpt(prompt):response = openai.Completion.create(engine="text-davinci-003", # 选择一个模型,例如text-davinci-003prompt=prompt,max_tokens=150, # 响应中生成的最大令牌数n=1, # 响应的数量stop=None, # 何时停止生成temperature=0.7, # 控制输出的随机性)return response.choices[0].text.strip()# 输入提示词并获取响应prompt = "解释一下大模型的工作原理。"response = chat_with_gpt(prompt)print("ChatGPT的回答:", response)创建一个AI智能体:从简单的对话机器人入手,逐步增加复杂度,加入自然语言处理、情感分析等功能。通过这个过程,你可以提升自己的编程和开发能力。
class SimpleAgent:def __init__(self, name):self.name = namedef greet(self):return f"Hello, I'm {self.name}. How can I help you today?"def respond(self, input_text):if "hello" in input_text.lower():return "Hi there!"elif "how are you" in input_text.lower():return "I'm good, thank you!"elif "bye" in input_text.lower():return "Goodbye!"else:return "Sorry, I don't understand that."# 创建一个名为Bob的简单智能体实例agent = SimpleAgent("Bob")# 与智能体互动print(agent.greet()) # 打印问候语user_input = input("User: ") # 接收用户输入response = agent.respond(user_input) # 智能体回应print("Agent:", response) # 打印智能体的回应了解目前LLM和AI的局限性:虽然大模型在许多任务中表现出色,但它们也有明显的局限性,例如生成看似真实但实际上不合理的内容。了解这些局限性,可以帮助你在实际应用中规避问题。
数据偏见和数据限制:大语言模型依赖于大量的数据进行训练,如果这些数据存在偏见或者不完整,模型生成的内容可能会反映这些问题。例如,性别、种族、文化偏见可能会在生成的文本中得到体现。理解能力不足:尽管大语言模型能够生成连贯和语义合理的文本,但它们并不真正理解文本背后的含义。这意味着它们在处理复杂的推理、逻辑或者抽象概念时可能会出现误解或者错误的表达。社会和伦理问题:大语言模型的使用引发了一系列社会和伦理问题,包括隐私保护、信息误导、内容生成的责任归属等。这些问题需要综合考虑和解决,以确保模型的应用能够符合社会的期望和法律法规的要求。创建一个简单的RAG系统:通过结合检索和生成的优势,创建一个RAG(Retrieval-Augmented Generation)系统,可以提升你的技术水平,并为你的项目增添实用价值。
创建一个简单的RAG(Retrieval-Augmented Generation)模型涉及到结合信息检索和生成模型,通常使用Hugging Face的
transformers
库和相关的检索库。以下是一个基本的示例代码,展示如何使用Python创建一个简单的RAG模型:from transformers import RagTokenizer, RagRetriever, RagSequenceForGenerationfrom transformers import pipeline# 加载RAG模型和检索器tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")retriever = RagRetriever.from_pretrained("facebook/rag-token-base")model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-base")# 输入查询文本query = "Who is the president of the United States?"# 使用RAG模型进行文本生成def generate_answer(query):input_dict = tokenizer.prepare_seq2seq_batch(query, return_tensors="pt")retriever_output = retriever(input_dict["input_ids"].numpy())generator_input = {"retrieved_documents": retriever_output,"inputs": input_dict["input_ids"],}generated = model.generate(**generator_input)return tokenizer.batch_decode(generated, skip_special_tokens=True)[0]# 生成答案answer = generate_answer(query)print(f"Query: {query}")print(f"Answer: {answer}")微调一个LLM:选择一个你感兴趣的领域,使用相关数据对大语言模型进行微调,可以极大地提升模型的性能。
微调(fine-tuning)一个大语言模型(LLM)通常涉及使用预训练的模型作为起点,并在特定任务或数据集上进一步调整模型参数,以使其适应特定的应用场景。以下是一个基本的Python示例,展示如何微调一个Hugging Face Transformers库中的预训练语言模型,例如GPT-2,在自定义数据集上进行情感分类任务的微调:
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification, Trainer, TrainingArgumentsfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scoreimport torchimport datasets# 加载预训练模型和分词器model_name = "gpt2"tokenizer = GPT2Tokenizer.from_pretrained(model_name)model = GPT2ForSequenceClassification.from_pretrained(model_name, num_labels=2)# 加载自定义数据集(示例使用datasets库中的情感分析数据集)dataset = datasets.load_dataset("emotion")# 数据预处理函数def preprocess_function(examples):return tokenizer(examples["text"], padding=True, truncation=True)# 数据集划分为训练集和验证集train_dataset, eval_dataset = dataset["train"], dataset["validation"]train_dataset = train_dataset.map(preprocess_function, batched=True)eval_dataset = eval_dataset.map(preprocess_function, batched=True)# 定义训练参数和Trainer对象training_args = TrainingArguments(per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,logging_dir="./logs",logging_steps=100,evaluation_strategy="epoch",save_strategy="epoch",report_to="tensorboard",)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=lambda pred: {"accuracy": accuracy_score(pred.label_ids, pred.predictions.argmax(-1))},)# 开始微调trainer.train()# 评估模型results = trainer.evaluate()print("Evaluation Results:", results)
由于大模型动辄耗费巨大的资源,我一直希望有小规模的模型能够自己研究学习。
最近,我在网上搜集了不少资料,主要是GitHub上的仓库和Arxiv上的论文,并将其记录在这里,供大家参考和学习。
从零训练1B以下的小模型,对于资源有限的开发者来说,从零开始训练一个小模型是一个可行且有益的实践项目。以下是一些有用的资源和建议:
nanoGPT是由大神Andrej Karpathy编写的GPT-2的极简实现。尽管小巧,它却功能完备。GPT-2作为大型模型的鼻祖,许多研究论文都以nanoGPT为基准进行改进或作为对比实验。nanoGPT提供了从0.1B到1.5B不同规模的四个版本选择。
项目地址:https://github.com/karpathy/nanoGPT
代码参考资料:https://zhuanlan.zhihu.com/p/678155640
Qwen1.5阿里出品的大模型,参数最小达到0.5B。根据网上的评价,这款模型被认为是目前在中文领域表现最优秀的大型语言模型之一。
项目地址:https://github.com/QwenLM/Qwen1.5
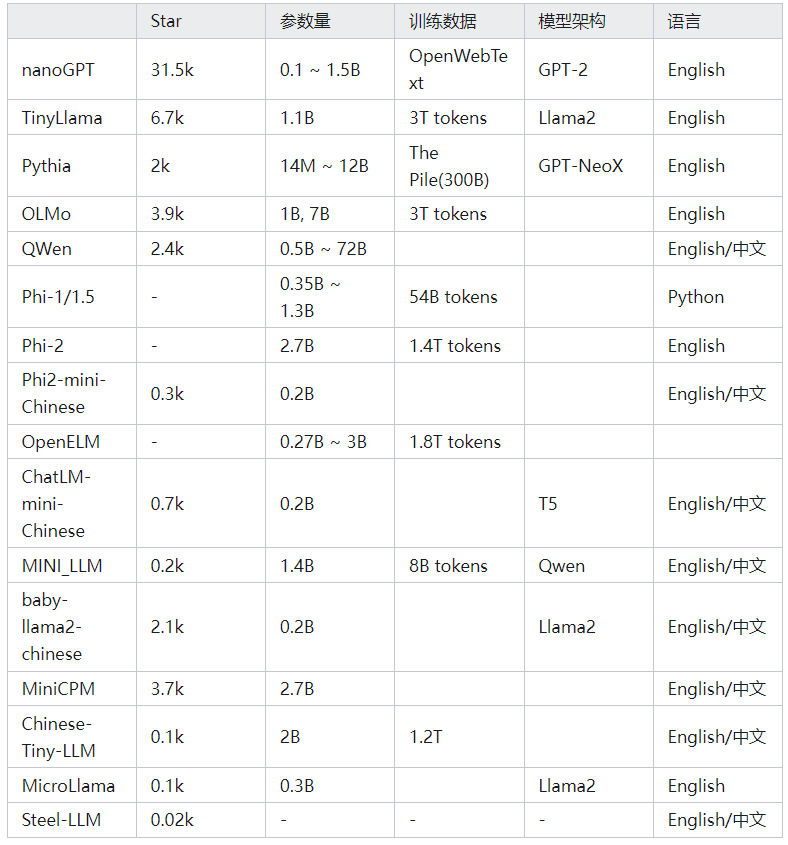
小模型在机器学习和深度学习领域中具有重要的意义和价值。它们通常具有较少的参数和更低的计算复杂度,适合于资源受限的环境和设备,例如移动设备、嵌入式系统或边缘计算设备。
小模型的优势包括更快的推理速度、更低的功耗消耗以及更易于部署和维护。此外,小模型还能够在保持相对较高性能的同时,提供高效的解决方案,为广泛的应用场景带来了灵活性和可行性选择。
最后提供一下小模型供大家参考,如下图所示:
长按下图前往本公众号领取更多学习资料:

