




昨天流传一张图很经典,都没眼看了……9.11和9.9哪个大?,这样简单的问题,大模型居然都翻车了!!!

如下图,网友的测试记录:
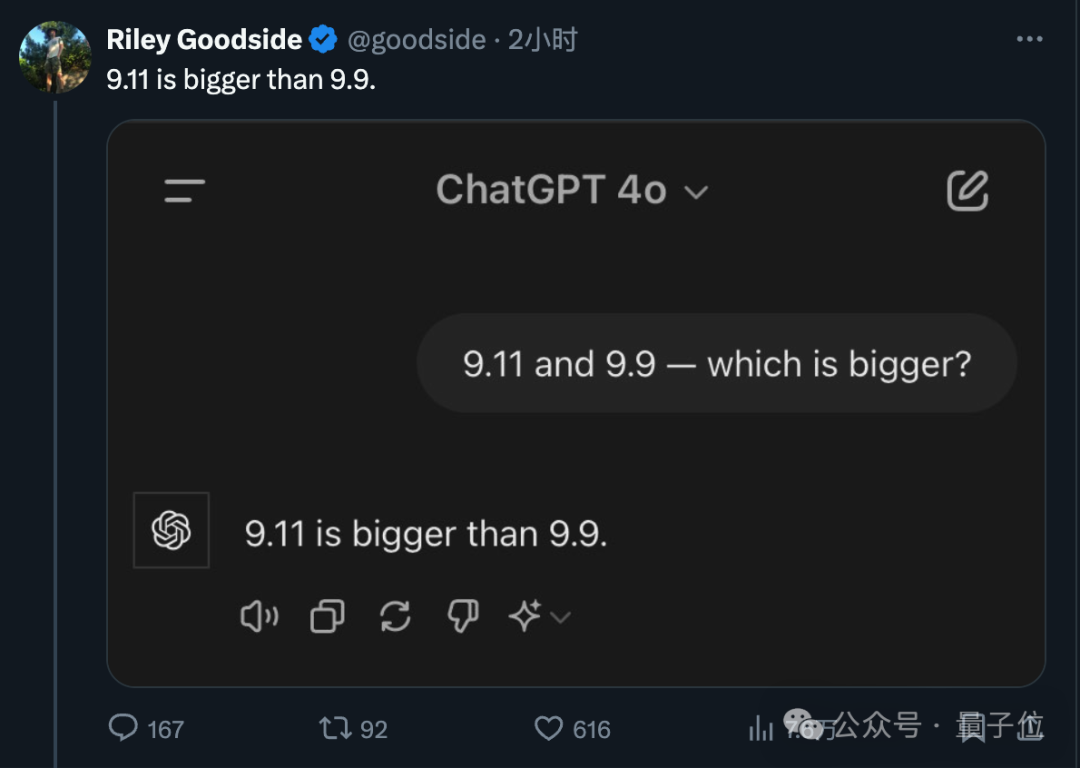
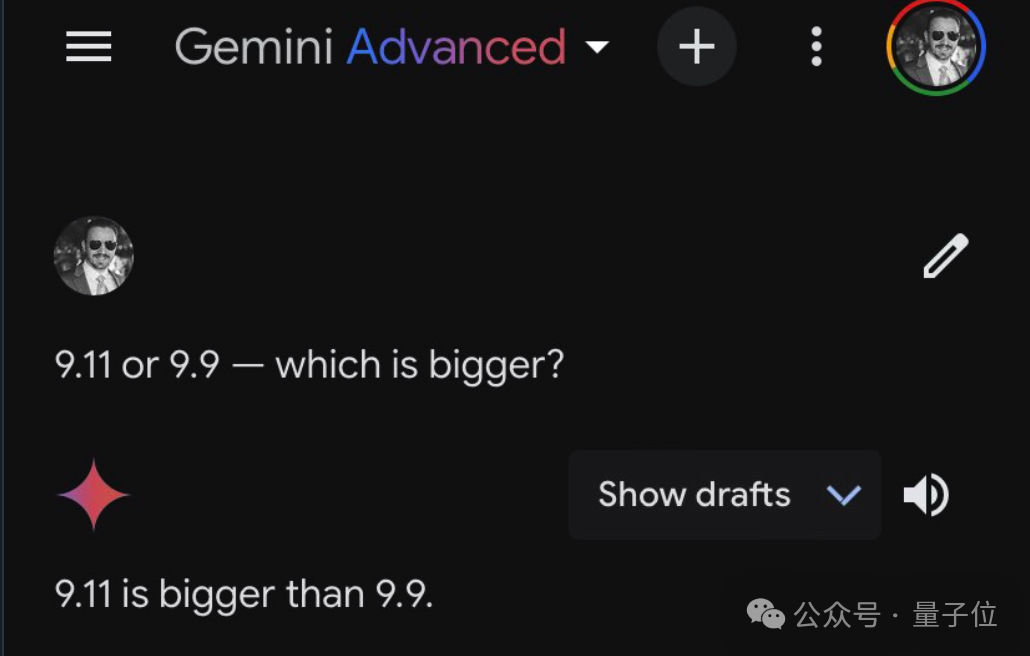
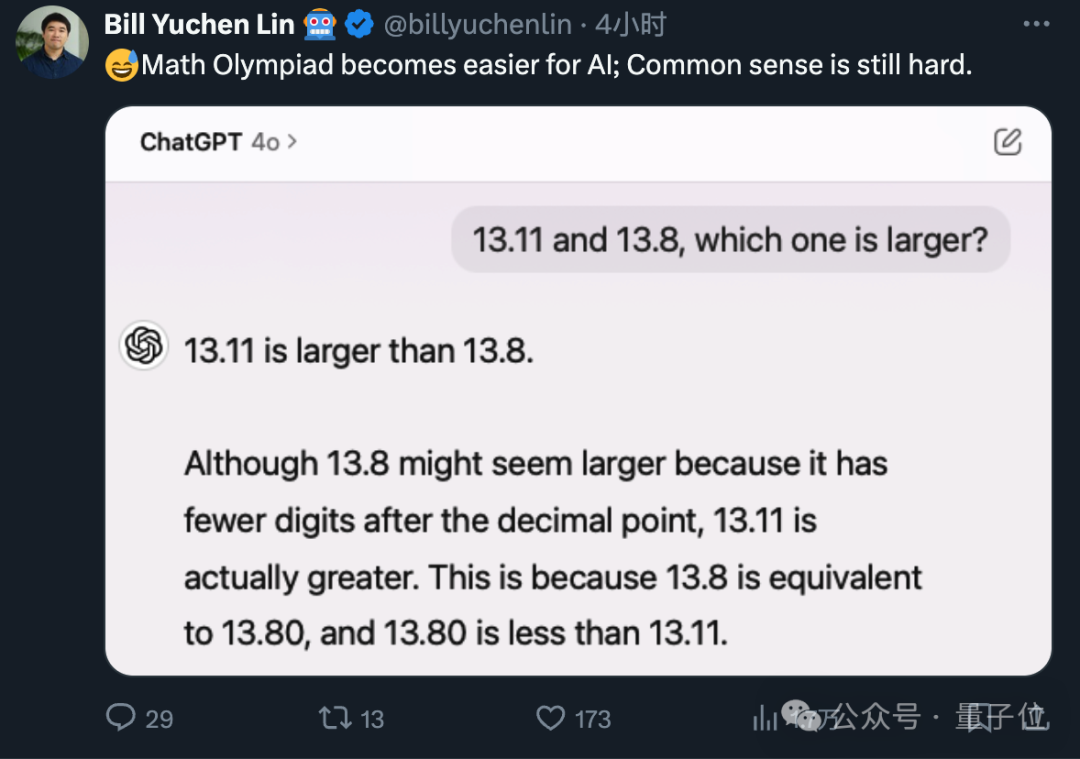
哈哈,吃瓜群众们,瓜吃得差不多了,该干活了!作为技术人,咱们可不能让大模型在比较两个数大小这种简单问题上掉链子。为了避免大模型犯这种低级错误,我们需要采取一系列技术措施来确保模型的准确性。

能想到的有以下几点,如果你有更好的点子,记得留言哦!
使用function call解决
使用langchain的链解决
使用Agent解决
使用微调技术
下面,我们依次来介绍以下具体技术的原理和使用:
1. 使用function call解决
大语言模型的function call(函数调用)功能是指模型能够解释和执行嵌入在输入文本中的函数调用指令。这种功能使得大语言模型不仅仅局限于生成文本,还可以执行更复杂的操作,如调用API、执行计算、获取实时数据等。
Function Call的实现原理
识别函数调用指令:
解析输入文本: 模型首先需要能够识别输入文本中的函数调用指令。这通常涉及自然语言理解(NLU)技术,模型可以从上下文中识别特定的调用模式或关键词。
函数格式识别: 例如,输入文本可能包含类似于“calculate(5, 10)”或“get_weather('New York')”的指令,模型需要能够正确解析这些调用格式。
映射到实际函数:
函数库映射: 一旦识别出函数调用指令,模型需要将其映射到预定义的函数库中的具体函数。这些函数可以是预先定义好的,也可以是通过扩展接口动态加载的。
参数处理: 模型需要从指令中提取参数,并将这些参数传递给相应的函数。例如,从“calculate(5, 10)”中提取参数5和10,并传递给对应的计算函数。
函数执行:
调用实际函数: 模型通过编程接口或嵌入的执行环境调用实际的函数,并获得返回值。例如,通过调用API或执行嵌入的脚本来获取结果。
处理返回结果: 函数执行后,模型需要处理返回结果,并将其整合到生成的文本中。例如,将计算结果或API返回的数据嵌入到回复中。
生成响应:
整合结果: 模型将函数调用的结果整合到最终的输出文本中,生成包含计算结果或外部数据的回复。
自然语言生成: 使用自然语言生成技术(NLG)确保整合后的回复自然流畅,符合上下文要求。
应用示例
计算功能:
输入: “What is the result of calculate(5, 10)?”
处理: 模型识别出“calculate(5, 10)”为函数调用,调用相应的计算函数并获得结果15。
响应: “The result of calculate(5, 10) is 15.”
API 调用:
输入: “What is the current weather in New York?”
处理: 模型识别出需要调用天气API,格式化API请求并获取实时天气数据。
响应: “The current weather in New York is 25°C with clear skies.”
数据库查询:
输入: “How many users signed up last week?”
处理: 模型识别需要查询数据库,执行相应的SQL查询并获得结果。
响应: “Last week, 150 users signed up.”
下面是一个示例,展示如何使用一个预训练的大语言模型(例如OpenAI的GPT-3或GPT-4)来实现一个函数调用功能,用于比较两个数的大小。在这个示例中,我们将模拟一个虚拟的函数调用,通过解析输入字符串并调用实际的比较函数。
import openai# 假设我们有一个OpenAI的API密钥openai.api_key = 'your-api-key-here'def compare_numbers(a, b):"""比较两个数的大小。参数:a (int or float): 第一个数b (int or float): 第二个数返回:str: 比较结果的字符串描述"""if a > b:return f"{a} is greater than {b}"elif a < b:return f"{a} is less than {b}"else:return f"{a} is equal to {b}"def function_call(prompt):"""模拟大模型的函数调用,解析输入并调用实际函数。参数:prompt (str): 输入提示,包含函数调用指令返回:str: 函数调用的结果"""# 解析输入提示,假设格式为 "compare_numbers(a, b)"if "compare_numbers(" in prompt:try:# 提取参数params = prompt.split("compare_numbers(")[1].split(")")[0]a, b = map(float, params.split(","))# 调用实际的比较函数result = compare_numbers(a, b)return resultexcept Exception as e:return f"Error parsing input: {e}"else:return "Function not recognized."# 示例使用大语言模型接口def use_model_for_function_call(prompt):"""使用大语言模型接口来处理函数调用。参数:prompt (str): 输入提示,包含函数调用指令返回:str: 模型生成的结果"""response = openai.Completion.create(engine="text-davinci-003", # 使用适当的模型引擎prompt=prompt,max_tokens=50)return response.choices[0].text.strip()# 主程序if __name__ == "__main__":# 示例输入prompt = "compare_numbers(10, 5)"# 直接调用函数print("Direct function call result:")print(function_call(prompt))# 使用大语言模型进行函数调用print("\nUsing model for function call result:")model_prompt = f"Please call the following function: {prompt}"model_output = use_model_for_function_call(model_prompt)print(model_output)
2. 使用langchain的链解决
LangChain 是一个用于构建语言模型应用的强大框架,可以帮助我们简化与预训练语言模型的集成。下面是一个示例,展示如何使用 LangChain 来实现一个比较两个数大小的功能。
接下来,我们将使用 LangChain 来实现一个功能,用于比较两个数的大小。
from langchain import LLMChain, PromptTemplate, OpenAI# 配置OpenAI API密钥openai.api_key = 'your-api-key-here'# 定义函数比较两个数def compare_numbers(a, b):"""比较两个数的大小。参数:a (int or float): 第一个数b (int or float): 第二个数返回:str: 比较结果的字符串描述"""if a > b:return f"{a} is greater than {b}"elif a < b:return f"{a} is less than {b}"else:return f"{a} is equal to {b}"# 定义 LangChain 提示模板prompt_template = """You are an assistant who compares two numbers and tells which one is greater or if they are equal.Given the function call: compare_numbers({a}, {b})"""# 创建 LangChain 的 PromptTemplateprompt = PromptTemplate(input_variables=["a", "b"], template=prompt_template)# 创建 OpenAI 接口的 LLMChainllm = OpenAI(model="text-davinci-003") # 使用适当的模型引擎chain = LLMChain(prompt_template=prompt, llm=llm)# 函数,用于调用 LangChaindef function_call_with_langchain(a, b):"""使用 LangChain 调用比较两个数的函数。参数:a (int or float): 第一个数b (int or float): 第二个数返回:str: 比较结果的字符串描述"""# 调用 LangChain 生成结果result = chain.run({"a": a, "b": b})return result.strip()# 主程序if __name__ == "__main__":# 示例输入a = 10b = 5# 直接调用函数print("Direct function call result:")print(compare_numbers(a, b))# 使用 LangChain 进行函数调用print("\nUsing LangChain for function call result:")langchain_result = function_call_with_langchain(a, b)print(langchain_result)
3. 使用Agent解决
下面是一个简单的示例,展示如何使用 LangChain 构建一个 Agent 来实现比较两个数大小的功能。
from langchain import LLMChain, PromptTemplate, OpenAIfrom langchain.agents import initialize_agent, Toolfrom langchain.agents.agent_types import AgentType# 配置OpenAI API密钥openai.api_key = 'your-api-key-here'# 定义比较函数def compare_numbers(a: float, b: float) -> str:"""比较两个数的大小。参数:a (float): 第一个数b (float): 第二个数返回:str: 比较结果的字符串描述"""if a > b:return f"{a} is greater than {b}"elif a < b:return f"{a} is less than {b}"else:return f"{a} is equal to {b}"# 创建一个工具,用于调用比较函数compare_tool = Tool(name="compare_numbers",func=compare_numbers,description="Compares two numbers and returns which one is greater or if they are equal.")# 初始化OpenAI的LLMllm = OpenAI(model="text-davinci-003")# 创建一个Prompt模板prompt_template = """You are an assistant who compares two numbers and tells which one is greater or if they are equal.Given the numbers: {a} and {b}"""# 创建LangChain的PromptTemplateprompt = PromptTemplate(input_variables=["a", "b"], template=prompt_template)# 创建LangChain的LLMChainchain = LLMChain(prompt_template=prompt, llm=llm)# 初始化Agentagent = initialize_agent(tools=[compare_tool],llm=llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,verbose=True)# 主程序if __name__ == "__main__":# 示例输入a = 10b = 5# 使用Agent进行函数调用prompt = f"compare_numbers({a}, {b})"result = agent.run(prompt)print("Agent result:")print(result)
4. 使用微调技术
为了使用微调技术让大模型比较两个数的大小,我们需要以下步骤:
准备数据:生成或收集大量的训练数据,包含两个数及其比较结果。
数据预处理:将数据转换为模型可以接受的格式。
微调模型:使用包含标注数据的预训练模型进行微调。
评估和验证:评估微调后的模型性能。
这里我们将使用Hugging Face的Transformers库,它提供了便捷的API来进行模型微调和使用。
首先,我们生成一些训练数据。每条数据包含两个数以及它们的比较结果。
import randomimport jsondef generate_data(num_samples):data = []for _ in range(num_samples):a = random.uniform(-100, 100) # 生成随机数b = random.uniform(-100, 100)if a > b:label = f"{a} is greater than {b}"elif a < b:label = f"{a} is less than {b}"else:label = f"{a} is equal to {b}"data.append({"input": f"compare_numbers({a}, {b})", "label": label})return data# 生成 1000 条训练数据train_data = generate_data(1000)# 保存为 JSON 文件with open("train_data.json", "w") as f:json.dump(train_data, f)
使用 datasets 库来加载和预处理数据。
from datasets import load_dataset# 加载数据集dataset = load_dataset('json', data_files='train_data.json')# 打印部分数据print(dataset['train'][0])
使用 transformers 库来微调预训练模型。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments# 加载预训练的 tokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 数据预处理函数def preprocess_function(examples):return tokenizer(examples['input'], truncation=True, padding='max_length', max_length=128)# 应用数据预处理tokenized_dataset = dataset.map(preprocess_function, batched=True)# 加载预训练的模型model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3)# 定义训练参数training_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,weight_decay=0.01,logging_dir="./logs",)# 定义 Trainertrainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["train"],)# 开始微调trainer.train()
微调完成后,我们可以使用模型来比较两个数的大小。
from transformers import pipeline# 加载微调后的模型model_path = "./results"classifier = pipeline("text-classification", model=model_path, tokenizer=tokenizer)# 测试比较函数def compare_numbers_with_model(a, b):input_text = f"compare_numbers({a}, {b})"result = classifier(input_text)return result[0]['label']# 测试a = 10b = 5result = compare_numbers_with_model(a, b)print(f"Comparison result: {result}")
通过上述步骤,我们使用微调技术让大模型能够比较两个数的大小。这个过程包括准备和生成训练数据、数据预处理、模型微调和测试模型。通过微调预训练模型,我们可以让模型适应特定任务(如比较两个数的大小),从而提高模型在该任务上的性能。

哈哈,看完这篇文章,大家有没有感觉到技术的奇妙和幽默的碰撞?如果你还有更好的点子,或者在实践中遇到什么有趣的问题,不要犹豫,赶快留言告诉我们吧!技术的进步离不开大家的互动和分享,让我们一起在这个技术瓜田里,吃好每一口瓜,解决每一个问题!期待你的创意和反馈哦!🍉🚀
长按下图前往本公众号领取更多学习资料:

