




在AI的世界里,变革总是在不经意间到来。最近,一个名为TTT的全新架构横空出世,由斯坦福、UCSD、UC伯克利和Meta的研究人员共同提出,颠覆了Transformer和Mamba,为语言模型带来了革命性的改变。
TTT(Test-Time-Training layers)
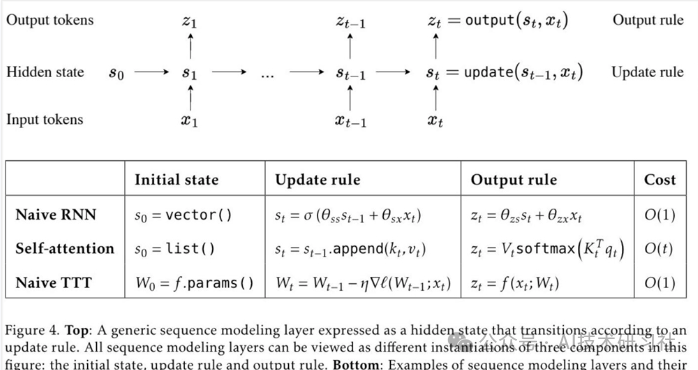
TTT,全称Test-Time-Training layers,是一种全新的架构,通过梯度下降压缩上下文,直接替代了传统的注意力机制。这一方法不仅提高了效率,更解锁了具有表现力记忆的线性复杂度架构,使得我们能够在上下文中训练包含数百万甚至数十亿个token的LLM。
原理
梯度下降压缩上下文:TTT在推理过程中,利用梯度下降方法动态调整模型参数,以便更好地理解和生成上下文。传统的Transformer通过注意力机制捕捉输入序列中不同位置的相关性,而TTT通过在推理时进行训练,压缩上下文信息,提高模型的理解和生成能力。
线性复杂度架构:TTT的架构设计使得模型的复杂度从传统Transformer的二次方复杂度降低到线性复杂度。这意味着模型在处理长序列时,计算开销大大减少,使得处理更长的上下文成为可能。
表现力记忆:通过Test-Time-Training,TTT能够记住并利用大规模上下文信息。与传统方法相比,这种方法可以更有效地处理和生成长文本,提升模型在各种任务上的表现。
研究团队引入两个简单的实例:TTT-Linear 和 TTT-MLP,其中隐藏状态分别是线性模型和两层 MLP。TTT 层可以集成到任何网络架构中并进行端到端优化,类似于 RNN 层和自注意力。

为了让 TTT 层更加高效,该研究采用了以下改进方法:
首先,在TTT期间使用小批量的token进行操作,就像常规训练期间对小批量序列采取梯度步骤一样,从而提高了并行性。
其次,该研究为每个TTT小批量内的操作开发了一种双重形式。虽然双重形式的输出与简单实现等效,但它能够更好地利用现代GPU和TPU,使训练速度提高了5倍以上。
优势
效率提升:TTT的线性复杂度架构使得模型在处理长序列时更加高效,减少了计算资源的消耗。
更长的上下文处理:通过在推理过程中进行训练,TTT能够更好地利用长上下文信息,提高模型的生成和理解能力。
动态适应性:TTT在推理时进行训练,使得模型能够动态适应不同的输入,提高了模型的灵活性和鲁棒性。
示例代码
下面是一个简化的TTT架构的示例代码,展示了如何在推理过程中进行训练:
import torchimport torch.nn as nnclass TTTLayer(nn.Module):def __init__(self, hidden_size):super(TTTLayer, self).__init__()self.linear1 = nn.Linear(hidden_size, hidden_size)self.linear2 = nn.Linear(hidden_size, hidden_size)self.optimizer = torch.optim.Adam(self.parameters(), lr=0.001)def forward(self, x, target):# 初始前向传播output = self.linear1(x)output = torch.relu(output)output = self.linear2(output)# 计算损失loss = nn.functional.mse_loss(output, target)# 反向传播和梯度更新self.optimizer.zero_grad()loss.backward()self.optimizer.step()return outputclass TTTModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(TTTModel, self).__init__()self.embedding = nn.Embedding(input_size, hidden_size)self.ttt_layer = TTTLayer(hidden_size)self.output_layer = nn.Linear(hidden_size, output_size)def forward(self, input_ids, target):embeds = self.embedding(input_ids)context = self.ttt_layer(embeds, target)output = self.output_layer(context)return output# 示例:创建和使用TTT模型input_size = 30522 # 词汇表大小hidden_size = 768 # 隐藏层大小output_size = 30522 # 输出大小model = TTTModel(input_size, hidden_size, output_size)# 输入数据input_ids = torch.randint(0, 30522, (2, 20)) # 示例输入target = torch.randn(2, 20, hidden_size) # 示例目标# 前向传播output = model(input_ids, target)print(output)
这项研究是团队五年磨一剑的成果,从Yu Sun博士的博士后时期就开始酝酿。他们坚持探索,不断尝试,最终实现了这一突破性的成果。TTT层的成功,是团队不懈努力和创新精神的结晶。

TTT层的问世,为AI领域带来了新的活力和可能性。它不仅改变了我们对语言模型的认识,更为未来的AI应用开辟了新的道路。让我们一起期待TTT层在未来的应用和发展,见证AI技术的进步和突破。
论文地址:https://arxiv.org/abs/2407.04620
温馨提示:关注我,在菜单栏领取大模型书籍和640套报告。
