




能下载到的模型普遍都是6/7B(小)、13B(中)、大(130B) 三种,比如ChatGLM 和Llama2 等。这个在数学上有什么讲究吗?
答案很简单,模型大小的设计主要是为了匹配显存。
6B参数的模型可以在12G、16G或24G显存的消费级显卡上进行部署和训练。如果一个公司的模型不打算在消费级显卡上部署,通常不会选择训练6B规模的模型。此外,还有一些1.4B或2.8B参数的模型,这些模型大小适合在手机、车载端进行量化部署。
13B模型在使用4k长度的数据进行训练时,数据并行度为2,刚好可以充分利用一个8卡机的显存,并且可以量化部署在A10甚至是4090显卡上。
更大规模的模型不仅限于130B。目前,常见的更大模型包括16B、34B、52B、56B、65B、70B、100B、130B、170B和220B等。这些模型的规模设计基本上是为了刚好匹配某种规格的算力,无论是用于训练还是推理。如果需要加快训练速度,只需倍增显卡数量即可。例如,我们训练7B模型时以8卡为单位,使用8x8卡进行训练;而训练70B模型时则以80卡为单位,使用80x6卡进行训练。
将大语言模型设计成6/7B、13B和130B等几个档次,是在性能、计算资源、应用场景、训练调优、市场需求和研究实验等多方面综合考虑的结果。这种设计方法不仅满足了多样化的需求,还促进了技术的进步和市场的竞争。以下是一些原因和考量:
1. 性能与计算资源的平衡
计算资源限制:较大的模型(如130B参数)需要更多的计算资源和存储空间。设计成不同档次可以平衡性能和计算资源的需求,满足不同应用场景的要求。
性能提升:随着参数量增加,模型的性能和生成能力通常会提升,但这种提升有时会出现边际效益递减。通过选择几个典型的档次,可以在性能和资源间找到最佳平衡点。
2. 应用场景的多样性
小模型应用:6/7B参数的模型适合部署在资源受限的环境中,如移动设备或需要低延迟响应的应用。
中等规模模型应用:13B参数的模型提供了较好的性能与资源消耗平衡,适合大多数中型应用场景。
大模型应用:130B参数的模型用于需要最高生成质量和复杂任务的场景,如高端研究和企业级应用。
3. 训练与调优的便利
渐进训练:通过从较小的模型开始,然后逐步训练更大的模型,可以更有效地利用计算资源,并逐步优化模型性能。
调优过程:不同大小的模型允许在不同阶段和需求下进行针对性调优,提升整体系统效率。
4. 市场需求与竞争
多样化需求:市场上有不同的需求,从个人开发者到大型企业,各种规模的模型可以满足不同的用户群体。
竞争策略:不同大小的模型可以覆盖更多市场,增强竞争力,吸引更多用户和客户。
5. 研究与实验目的
对比研究:通过设置不同大小的模型,可以进行对比研究,了解参数量对模型性能的影响,帮助优化模型设计。
实验验证:不同大小的模型可以用于验证理论假设和实验结果,推动
最新消息:利用AI大模型、数字人技术,培育消费新增长点
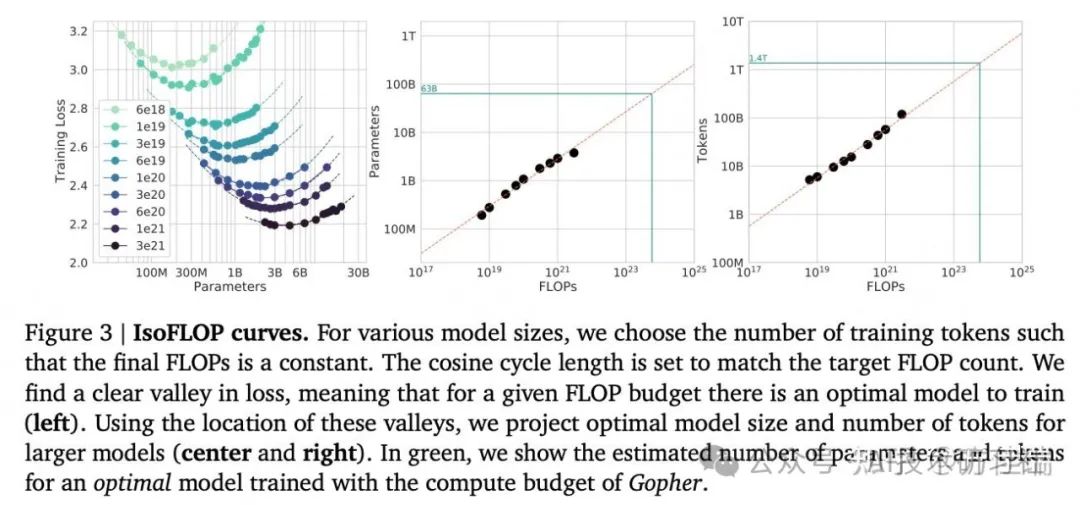
推荐阅读论文:https://arxiv.org/pdf/2203.15556
