




背景
随着业务的不断增涨,至使现有的单节点DG环境的连接已经无法满足当前业务需求,并且随着业务的重要性,同时也要求数据库的高可用性,减少数据库故障对业务的影响。于是规划迁移方案。
- 迁移方案如下:
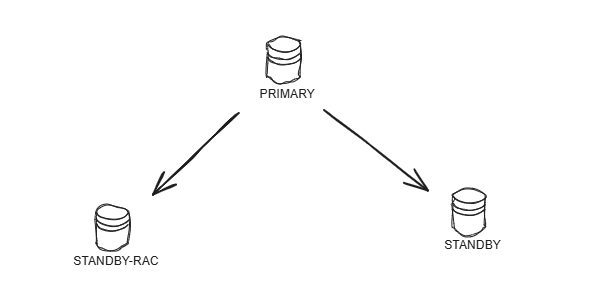
因PRIMARY库本地磁盘空间已达到80%决定弃用,搭建高可用2个节点的RAC做为PRIMARY,重新部署一套Standby(磁盘空间配置高)。
搭建DG-Rac
- Failover前架构
- 搭建步骤-下载:Standby-RAC.pdf
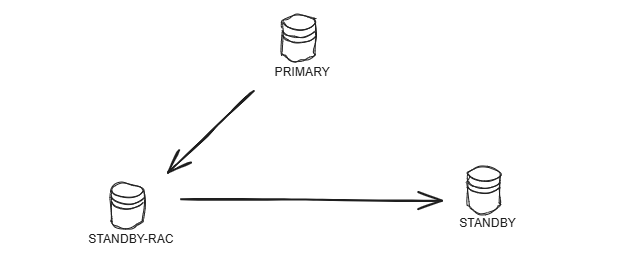
DG-主备备调整
- 调整为主备备架构
1、Primary 断开与 Standby 连接
- 将Standby 在参数LOG_ARCHIVE_CONFIG 移除
alter system set LOG_ARCHIVE_CONFIG='DG_CONFIG=(Primary,standby_rac)' scope=both;
- 禁用log_archive_dest_state_2 参数
alter system set log_archive_dest_state_2='defer' scope=both;
- 设置为log_archive_dest_2 空串
alter system set log_archive_dest_2='' scope=both;
2、Standby-Rac 各节点创建TNS
- 创建tns
standby =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.5.100)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = standby)
)
)
- 测试连接性
[oracle@dbrac admin]$ tnsping standby
TNS Ping Utility for Linux: Version 11.2.0.3.0 - Production on 08-AUG-2024 11:39:29
Copyright (c) 1997, 2011, Oracle. All rights reserved.
Used parameter files:
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.5.100)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = standby)))
OK (10 msec)
3、Standby-Rac 调整
3.1 关闭集群
[grid@dbrac ~]$ srvctl stop database -d twodb
3.2 单节点操作
- 启库到mount
SQL> startup mount;
- 调整参数
-- 主、备RAC、备库的DB_UNIQUE_NAME 全部填写
alter system set LOG_ARCHIVE_CONFIG='DG_CONFIG=(primary,standby_rac,standby)' scope=both;
-- 设置参数:log_archive_dest_2 往 standby 传输归档日志
alter system set log_archive_dest_2='SERVICE=standby LGWR ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=standby';
-- 启用参数:log_archive_dest_state_2
alter system set log_archive_dest_state_2='enable';
- 注参数定义,否则归档传输有问题
VALID_FOR属性由2部分组成:
- archive_source(online_logfile,standby_logfile,all_logfiles)
online_logfile: 表示归档联机重做日志
standby_logfile:表示归档备用数据库的重做日志/接受来自主库的重做日志
all_logfiles: online_logfile && standby_logfile - database_role(primary_role,standby_role,all_role)
primary_role: 仅当数据库角色为主库时候生效
standby_role: 仅当数据库角色为备库时候生效
all_role: 任意角色均生效
4、Standby 调整
- 创建tns
standby_rac =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.5.101)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = standby_rac)
)
)
- 参数调整
-- 仅设置:standby_rac,standby
alter system set LOG_ARCHIVE_CONFIG='DG_CONFIG=(standby_rac,standby)' scope=both;
-- REDO文件对应
alter system set LOG_FILE_NAME_CONVERT='+REDO1/twodb','/u01/oradata/twodb','+REDO2/twodb/datafile','/u01/oradata/twodb' scope=spfile;
-- 数据文件对应
alter system set DB_FILE_NAME_CONVERT ='+DATA/multiple','/u01/oradata/twodb','+DATA/multiple/datafile','/u01/oradata/twodb' scope=spfile;
-- 增加thread 2 standby redo
alter system set STANDBY_FILE_MANAGEMENT=MANUAL;
alter database add standby logfile thread 2
group 201 ('/u01/oradata/twodb/standby_201.log') size 500M,
group 202 ('/u01/oradata/twodb/standby_202.log') size 500M,
group 203 ('/u01/oradata/twodb/standby_203.log') size 500M,
group 204 ('/u01/oradata/twodb/standby_204.log') size 500M,
group 205 ('/u01/oradata/twodb/standby_205.log') size 500M,
group 206 ('/u01/oradata/twodb/standby_206.log') size 500M,
group 207 ('/u01/oradata/twodb/standby_207.log') size 500M,
group 208 ('/u01/oradata/twodb/standby_208.log') size 500M,
group 209 ('/u01/oradata/twodb/standby_209.log') size 500M,
group 210 ('/u01/oradata/twodb/standby_210.log') size 500M,
group 211 ('/u01/oradata/twodb/standby_211.log') size 500M;
alter system set STANDBY_FILE_MANAGEMENT=auto;
-- fal_server
alter system set fal_server='standby_rac' scope=both;
-- 关库
shutdown immediate;
5、启动集群
- 集群启库
[grid@dbrac ~]$ srvctl start database -d twodb
- 启动应用进程,查看同步情况
– 注:standby 会延迟1个归档日志,RAC切主后就可以实时了
alter database recover managed standby database using current logfile disconnect from session;
set line 800
col NAME for a10
col VALUE for a20
select * from v$dataguard_stats where name='apply lag';
DG-Failover操作
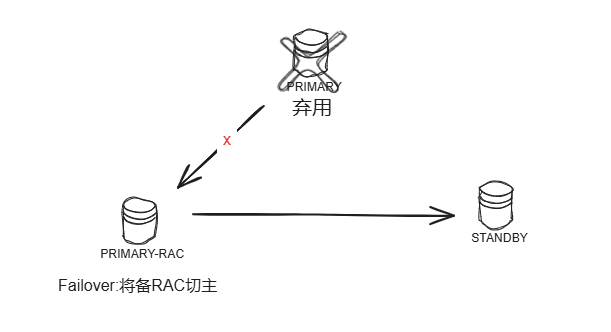
- 弃用原主,将备RAC升级为主,保留主备模式
1、Primary 查看用户连接
- 停应用,保证无用户连接方可操作
select username,count(*) from v$session group by username;
- 切归档,并关闭
alter system switch logfile;
shutdown immediate;
2、Standby-Rac 查看同步状态
set line 800
col NAME for a10
col VALUE for a20
select * from v$dataguard_stats where name='apply lag';
3、Failover 切库
注:Failover 操作后并不会破坏它下面的备库关系,断开的原主无法再挂回到Standby-RAC 当备库(SWITCHOVER可避免)
- 集群关库:
[grid@dbrac1 ~]$ srvctl stop database -d twodb
- 启单节点:Failover
startup mount;
alter database recover managed standby database finish force;
alter database commit to switchover to primary;
alter database open;
shutdown immediate;
- 集群启库:
[grid@dbrac1 ~]$ srvctl start database -d twodb
4、Standby 同步状态
set line 800
col NAME for a10
col VALUE for a20
select * from v$dataguard_stats where name='apply lag';
总结
- 操作很熟悉,但是还要注意细节,尤其参数很容易调做乱;
- 数据库在操作前一定要确定应用无连接,否则数据错乱就是大锅;
- 能SWITCHOVER操作尽量SWITCHOVER操作,避免重复搭建备库;
- 此次记录Failover,是因为原主库计划弃用,并且切换要求时间卡的很紧,尽量减少操作时间;
- 另注:我们Failover切换前1小时突然收到了alert日志疯狂报:《direct connection failure with ASM》,最后排查幸亏是虚惊一场,但也是因为操作前准备细节不到位导致的,分享给大家供大家参考。
欢迎赞赏支持或留言指正

最后修改时间:2024-08-20 17:23:59
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
