





模型内存消耗的具体比重在不同的模型和配置下会有很大差异,但可以提供一个大致的概览来帮助理解各部分的相对重要性:
1. 模型参数:这部分通常占据相对固定的内存,根据模型的大小(层数、参数数量)而定。对于较大的模型,这部分可以占据显著的内存比例,尤其是在模型参数多的情况下。在推理场景,内存的主要消耗就是模型参数加载。
2. 激活:在推理时,激活不是内存消耗的主要部分。但在训练场景,尤其是当批量大小较大或模型深度较大时。这部分内存消耗很大。
3. 优化器状态:在推理过程中,如果不进行模型更新,则优化器状态的内存消耗可以忽略。但在训练场景,这部分内存消耗很大。
4. 框架开销:这通常占据较小的内存比例,但在内存管理不当或框架本身较为复杂的情况下,也可能成为一个不容忽视的因素。
在训练过程中,我们需要存储所有层的激活值,以便进行反向传播和梯度计算。这就需要更多的内存。而在推理过程中,我们只需要逐层进行计算,并且在每一层计算完成后,就可以释放该层的激活值,从而节省内存。
我们需要知道以下信息来估计激活内存消耗:
· s:最大序列长度(输入中的令牌数量)
· b:批处理大小
· h:模型的隐藏维度
· a:注意力头的数量
一个标准的 Transformer 层由一个自注意力块和一个 MLP 块组成,每个块通过两个层规范化连接。
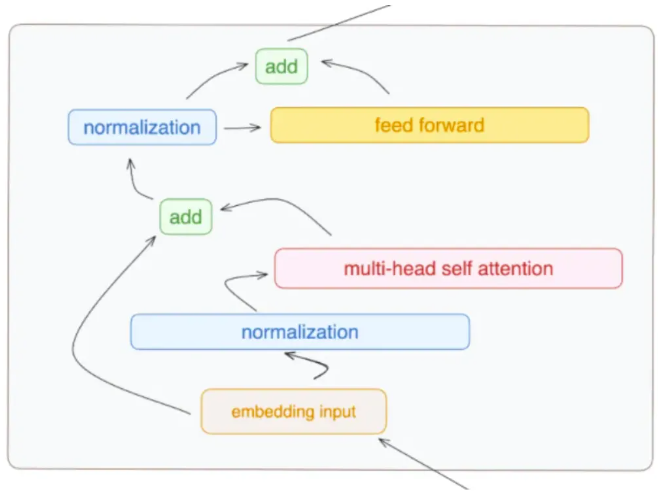
在上图中,标记为 “feed forward” 的黄色部分代表了MLP(多层感知器)块。这个 MLP 块是 Transformer 层结构中的一个关键组成部分,它在多头自注意力机制(标记为"multi-head self attention"的红色部分)之后对数据进行进一步的处理和变换。这张图中显示的“feed forward”部分虽然用单个方框表示,但实际上,在常规的 Transformer 模型中,这个 “feed forward” 网络包含两个线性层,这两个线性层之间有一个激活函数。
“feed forward” 部分通常是这样构成的:
1. 第一个线性层(全连接层):扩展输入特征的维度。
2. 激活函数:通常是 ReLU 或 GELU ,用于引入非线性。
3. 第二个线性层:将特征维度从扩展后的维度恢复到原始维度。
这样的结构使得 MLP 块能够对输入数据进行更深层次的处理,增强模型的学习能力。图示中可能未详细分解这些组件,但它们是 MLP 块标准配置的关键部分。
每个组件的内存消耗估计如下:
自注意力
注意力块包括自注意力机制和线性投影。
内存需求包括: (注意:当我写“sbh”,请将其解释为乘法“sbh”。)
• 线性投影(Linear Projection)保留其输入激活,大小为 2sbh。
• 线性投影和自注意力输入激活,每个需要 2sbh。
• 自注意力的查询(Q)和键(K)矩阵,总共需要 4sbh。
• Softmax 需要 2as²b。
• 存储应用于自注意力的值(V)的注意力,总计为2as²b + 2sbh。
注意力块总共需要的内存为 10sbh + 4as²b。
MLP块
MLP 块包含两个线性层:
• 线性层存储输入,需要 2sbh 和 8sbh,GeLU 非线性同样需要 8sbh。注意:我们可能不需要为推理存储 GeLU 的激活,但我仍将其计入以估计最坏情况下的内存消耗,以防用于推理的框架存储了这些激活。
总的来说,MLP块需要18sbh的存储空间。
层规范
每个层规范存储其输入,每个需要 2sbh
两个规范总共需要 4sbh。
整个层
存储一个 Transformer 层激活所需的总内存为来自注意力块的10sbh + 4as²b,来自 MLP 块的 18sbh,以及来自层规范的4sbh。
每层的激活内存消耗 = 32 sbh + 4as²b
如果我们使用16位数据类型,我们需要将这个数字乘以2,因为每个激活参数将消耗2字节。
16位数据类型
• 每个激活参数消耗2字节。
• 如果我们使用16位数据类型,需要将参数个数乘以2来计算总内存消耗。
32位数据类型
• 每个激活参数消耗4字节。
• 如果我们使用32位数据类型,需要将参数个数乘以4来计算总内存消耗。
8位数据类型
• 每个激活参数消耗1字节。
• 如果我们使用8位数据类型,需要将参数个数乘以1来计算总内存消耗。
4位数据类型
• 每个激活参数消耗0.5字节。
• 如果我们使用4位数据类型,需要将参数个数乘以0.5来计算总内存消耗。
结论:推理过程中,激活的内存开销:
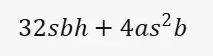
是用来估计在推理过程中,一个 Transformer 层激活所需的总内存。这里的各个符号代表的含义是:
• s:序列长度
• b:批大小
• h:隐藏层的大小
• a:注意力头的数量
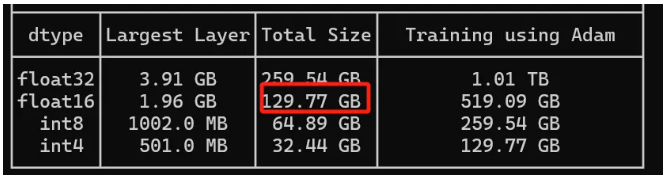
举例而言,要计算 Llama 3 70B 模型加载需要的 GPU RAM,我们可以遵循以下步骤:
1.确定参数数量:
Llama 3 70B 模型有 70 billion(即 70 亿或 70,000,000,000)个参数。
2. 计算参数所需的总内存:
每个参数使用 16 位(或 2 字节)的内存(由于参数采用 bfloat16 格式存储,16 位等于 2 字节)。
因此,总内存 = 参数数量 x 每个参数的内存 w
总内存 = 70,000,000,000 参数 x 2 字节/参数 = 140,000,000,000 字节
3. 将字节转换为GB:
1 GB = 1,073,741,824 字节(注意这里使用的是二进制转换,即 2^30)
总内存(GB)= 140,000,000,000 字节 ÷ 1,073,741,824 字节/GB ≈ 130.4 GB
这个数值与HF工具的结果很接近:
我们需要估计模型的大小,并且为一个层添加激活的大小。这些估计是针对标准情况计算的,在这种情况下,模型的参数和激活都是16位的。我们还需要设置解码的超参数。我使用的是:s = 512(序列长度)b = 8(批大小),将数值滴入公式32 sbh + 4as²b。
最终得到如下结果:
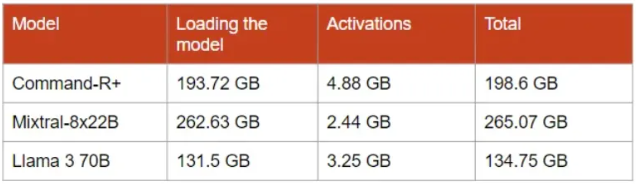
从上表可以看到,在推理场景中,与模型在内存中的大小相比,激活的大小可以忽略不计。然而,随着批大小和序列长度的增加,它们的大小会迅速增长。
推理过程中的大部分内存消耗来自模型的参数。最近的量化算法可以显著减少这种内存消耗。它们通过减少大多数参数的位宽来压缩模型,同时尝试保持其精度。8位量化几乎是无损的,而4位量化只会轻微降低性能。4位量化使模型的内存消耗减少了4倍,因为大多数参数都是4位,即0.5字节而不是2字节。我推荐使用 AWQ 进行4位量化,它运行简单并且模型运行速度快。然而,对于参数超过100B的非常大的模型,使用更低精度的量化,例如2.5位或3位,仍然可以获得精确的模型。例如,AQLM 在应用于 Mixtral-8x7B 的2位量化时表现良好。AQLM 的问题在于量化模型的成本非常高。在云端对非常大的模型进行量化可能需要几周的时间。
对于 LLMs 的微调,估算内存模型权重和激活外,对于所有层,我们还需要存储优化器状态。
优化器状态的内存消耗
AdamW 是一种常用的优化器,它的特点是在调整模型参数的同时,还会考虑参数的历史更新情况。这就像一个经验丰富的工程师在调整机器时,不仅会考虑当前的表现,还会参考过去的调整记录,以便更精确地进行调整。
然后,我们来看看内存消耗。在使用 AdamW 优化器时,每个模型参数都会有两个额外的信息被记录下来:动量和方差。
• 动量:这反映了参数在之前训练过程中的变化趋势,帮助优化器了解在调整时应该如何平滑地改变参数。
• 方差:这帮助优化器了解每个参数在不同训练阶段的稳定性,使得调整更加稳健。
这两种额外的信息需要额外的内存来存储,因为对于每一个模型参数,优化器都要记录这两种信息。
接下来,我们来看看微调模型时的内存消耗。以 Mixtral-8x22B 模型为例,优化器会为模型的每个参数创建并存储2个新参数(动量和方差),这就需要额外的内存。具体来说:
• 模型参数的副本:我们有141B(即141亿)的参数,每个参数都是 float32 类型,占用4字节的内存。所以,模型参数的副本总共占用的内存可以通过以下公式计算:
内存=参数数量×每个参数的字节大小
把具体的数值代入公式,我们得到:
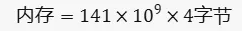
这个结果是以字节为单位的,我们通常会把它转换为 GB 以便于理解。1GB等于10243字节,所以我们可以得到模型参数的副本总共占用了约525.27 GB的内存。
• 梯度:我们有141B的梯度,每个梯度都是 float16 类型,占用2字节的内存。同样,我们可以通过以下公式计算梯度总共占用的内存:
内存=梯度数量×每个梯度的字节大小
把具体的数值代入公式,我们得到:
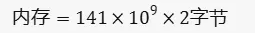
转换为GB,我们得到梯度总共占用了约262.63 GB的内存。
• 优化器创建的新参数:这包括了动量和方差,我们有282B的这些新参数,每个参数都是 float32 类型,占用4字节的内存。同样,我们可以通过以下公式计算优化器创建的新参数总共占用的内存:
内存=新参数数量×每个新参数的字节大小
把具体的数值代入公式,我们得到:
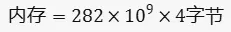
转换为 GB,我们得到优化器创建的新参数总共占用了约1050.53 GB的内存。
因此,优化器在训练过程中会增加的内存主要包括以下三部分:
1. 模型参数的副本:约525.27 GB
2. 梯度:约262.63 GB
3. 优化器创建的新参数(动量和方差):约1050.53 GB
所以,优化器在训练过程中一共会增加约 1838.43 GB 的内存。这是一个大概的估计,实际的内存消耗可能会因为具体的训练设置和硬件环境有所不同。
这个计算训练内存消耗的方法适用于微调和预训练两种情况。无论是微调还是预训练,优化器都需要为模型参数创建副本,计算梯度,并存储额外的参数(如动量和方差)。因此,这些内存消耗的计算方法对两者都适用。
但是,需要注意的是,预训练和微调的具体内存消耗可能会有所不同,因为它们可能使用不同大小的模型,不同的批次大小,甚至不同的优化器。此外,一些特定的训练策略,如梯度累积,也可能影响内存消耗。
训练中的激活内存:用于计算梯度所需的计算内存
Memory Required to Compute the Gradients:这是指在训练过程中,为了计算梯度(即参数更新的方向和大小),需要存储的内存。这部分内存主要用于存储模型的激活值,因为梯度的计算需要用到这些激活值。
与推理相比,我们只需要存储单个层的激活然后传递给下一个层,微调需要存储在前向传递期间创建的所有激活。这是必要的,以计算梯度,然后用于反向传播错误并更新模型的权重。
要估算计算梯度所需的内存,我们可以使用推理时使用的相同公式,然后将结果乘以层数。我们还需要考虑自注意力和 MLP 模块的 dropout 掩码,它们增加了2 sbh。
如果L是层数,那么计算梯度所消耗的内存是
L(34sbh + 5as²b)
是用来估计在训练过程中,所有 Transformer 层激活所需的总内存。这里的各个符号代表的含义是:
• L:模型的层数
• s:序列长度
• b:批大小
• h:隐藏层的大小
• a:注意力头的数量
所以,所有 Transformer 层在训练过程中的激活内存消耗可以通过这个公式来估计。这个公式考虑了自注意力、MLP 块和层规范等各个组件的内存需求。
公式上看,训练中的激活计算公式和推理中的激活计算公式确实相差不大。然而,在训练过程中,我们需要存储所有层的激活值,以便进行反向传播和梯度计算。这就需要更多的内存。而在推理过程中,我们只需要逐层进行计算,并且在每一层计算完成后,就可以释放该层的激活值,从而节省内存。
我设置了以下超参数进行微调:
s = 512(序列长度)
b = 8(批次大小)
对于优化器状态,我假设它们是 float32。通过计算得到如下数值:
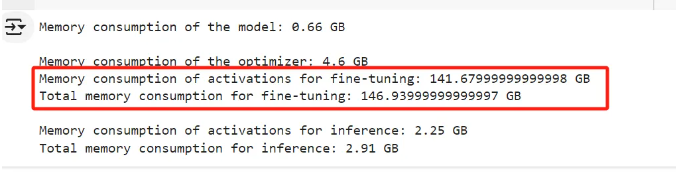
最终的结果是:
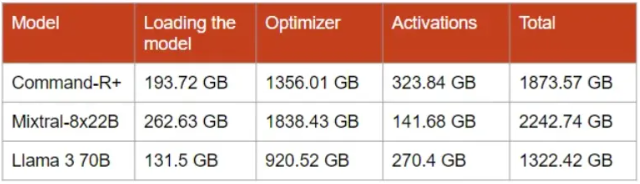
这是最坏情况下的内存消耗,即没有使用任何优化来减少它。我们离一个可负担的硬件配置还很远。幸运的是,有许多优化措施可以我们可以应用来减少内存需求。
由于优化器状态消耗大量内存,已经进行了大量研究来减少它们的内存占用,例如:
• LoRA:冻结整个模型并添加一个具有几百万参数的可训练适配器。使用 LoRA,我们只存储适配器参数的优化器状态。
• QLoRA:LoRA,但模型量化到4位或更低精度。
• AdaFactor和AdamW-8bit:内存效率更高的优化器,性能接近AdamW。AdaFactor在训练期间可能不稳定。
• GaLore:将梯度投影到低秩子空间,可以减少优化器状态的大小达80%。
内存的另一个重要部分由激活消耗。为了减少它,通常使用梯度检查点。它在需要计算梯度时重新计算某些激活。它减少了内存消耗,但也减慢了微调速度。
最后,有一些框架,如 Unsloth,针对使用 LoRA 和 QLoRA 的微调进行了极致优化。另外 DeepSpeed ZeRO 可以进一步针对内存进行优化。
参考文章:
https://kaitchup.substack.com/p/estimate-the-memory-consumption-of

魏新宇
微软AI全球黑带技术专家
(AI GBB)

著有:《大语言模型原理、训练及应用:基于GPT》、《OpenShift 在企业中的实战: PaaS DevOps 微服务》、《金融级 IT 架构与运维》、《云原生应用构建》。在 AI、深度学习方面有着丰富的经验。欢迎关注他的 github 获取更多 AI 知识。



