





👆 立即咨询 TiDB 企业版 👆

TiKV 是一个支持事务的分布式 Key-Value 数据库,目前已经是 CNCF 基金会的顶级项目。它通过 Raft 协议实现数据的高可用性和强一致性,是 TiDB 分布式数据库系统的重要组成部分。本文将从代码层面,深入解读 TiDB 新版本中 TiKV 的关键特性与原理。
TiKV 内存可观测性实践
TiDB 8.1 新特性解析
背景
在过去的一段时间内,TiKV 碰到了一些内存泄露导致 OOM 的问题。虽然最终都得以一一解决,但排查过程有些情况需要依赖猜测,很难直观确定问题所在。生产场景中必须及时定位问题,因此,提升内存的可观测性、及时发现和解决内存泄露问题,显得尤为重要。
而内存泄露导致的 OOM 问题总是非常棘手:
内存泄露难以察觉
缺乏排查现场
难以复现问题
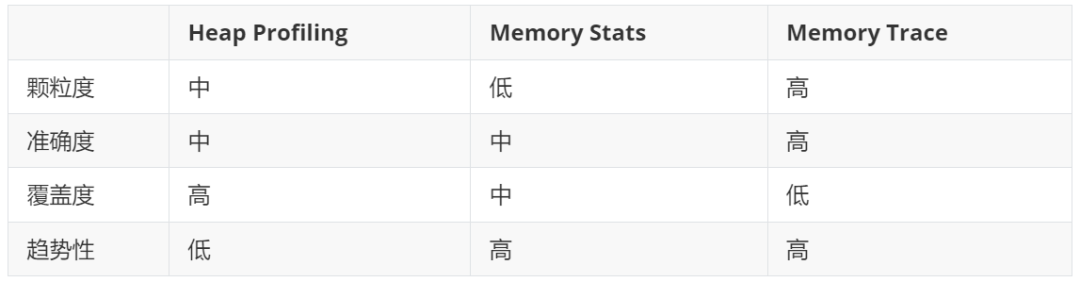
所以针对内存可观测性,我们需要的不仅仅是单一的 Heap Profiling,多维度的交叉参考才能让内存泄露无所遁形。这里可以归纳为三个维度:点线面,分别针对不同维度的信息。
面:Heap Profiling 提供全局内存分配的即时快照。
线:Metrics 追踪各模块线程内存使用量,反映使用趋势。
点:Memory Trace 手动定位内存消耗关键区域,实现精确监控和使用率管理。
面——Heap Profiling
Heap Profiling 指对应用程序的堆分配进行收集或采样,来向我们报告程序的内存使用情况,以便分析内存占用原因或定位内存泄漏根源。前面提到了 TiKV 可以通过 Jemalloc 进行 Heap Profiling,但是实用性上很差。
针对以上问题,那优化的最终期望是:
默认开启,那统计的就是全量的已有内存占用,通过全量做差也可以知道增量的变化
不依赖 binary 进行解析,不需要额外命令一键式获取火焰图
线——Memory Stats
Heap Profiling 在缺乏持续监控时难以捕获 OOM 现场数据。为解决此问题,需借助 Metrics 追踪历史趋势。虽Jemalloc 提供 mapped、retained 等指标并已集成至 Grafana,但细节粒度仍需提高。

为提升监控精度,我们按功能模块细分。即使无 Heap Profiling,这也助于问题排查。Jemalloc 的线程统计需深入其内存管理模型,以精确反映内存使用情况。
点——Memory Trace
内存分配可能跨线程转移,导致 Heap Profiling 和 Memory Stats 难以准确定位内存泄漏。对于复杂线程如 raftstore,需 Memory Trace 以精确诊断。
目前的 Memory Trace 主要基于增量变化,需要在 raftstore 等关键路径上手动进行记录和追踪:
覆盖有限且不精确,无法探测未知内容。
维护成本高,代码更新需手动集成内存追踪。
增量容易遗漏,可能导致累积误差。
总结
通过对 Heap Profiling、Memory Stats 和 Memory Trace 的深入分析和实践,我们可以更全面地提升 TiKV 的内存可观测性。
点击此处丨阅读原文
TiKV Raft 快照全流程
TiKV 源码解读
背景
在 TiKV 中,数据空间被切分成各个连续的范围,称为 Region。每个 Region 由一个单独的 Raft 组管理,基于 Raft 协议保证容错性。每个 Raft 组包含多个 Peer,每个 Peer 在不同的 TiKV 节点上运行。
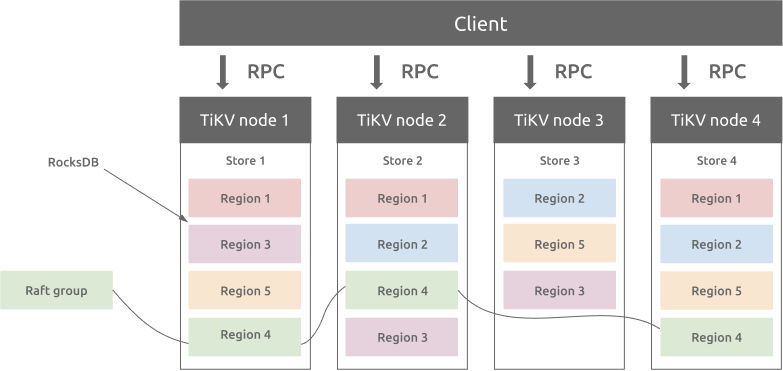
图 1. TiKV 中的 Region 和 Raft 组
在 Raft 协议中,Leader 通过 Append RPC 更新 Followers 的日志以保持数据一致性,并定期清理旧日志以节省磁盘空间。如果 Follower 落后,Leader 将使用快照机制在 Region 初始化、分裂或扩展时同步状态,确保数据一致性和系统稳定。
概述
TiKV 中的 Raft 快照过程大致分为四个阶段:
生成:Raft Leader 生成一份快照,记录下 Raft 和 RocksDB 在当前时间点的状态。
发送:Raft Leader 通过网络把快照发送给 Follower。
接收:Raft Follower 接收快照并暂时存储。
应用:Raft Follower 将快照应用到 Raft 状态机和 RocksDB 数据中。
核心原理
这个部分将介绍核心环节的设计思路。
快照元数据和数据的分离
为了避免阻塞正常的 Raft 消息处理逻辑,TiKV 选择将 Raft 快照消息(MsgSnapshot)仅包含元数据,而将实际的快照数据存储为文件在磁盘上。这些数据通过专用的 gRPC 流连接由 Snap Worker 发送,使用流式传输将数据分成小块以提高传输效率(见步骤7和8)。
从 ApplyFsm 调度 RegionTask::Gen
PeerStorage不直接调度 RegionTask::Gen ,而是通过 ApplyFsm 来调度,以控制快照生成时间,确保其包含最新数据。Raft 批处理系统先将同批次的写入任务交给 Apply 批处理系统处理,再分派快照任务(ApplyTask::Snapshot),利用 ApplyFsm 依次处理任务,确保快照任务在同批次写入完成后执行。
代码路径详解
快照生成
步骤 1: GenSnapTask
步骤 2: ApplyTask::Snapshot
步骤 3: RegionTask::Gen
步骤 4 和 5: do_snapshot() and notify
快照发送
步骤 6 和 7: MsgSnapshot and send_snap()
快照接收
步骤 8 和 9: recv_snap() and MsgSnapshot
快照应用
步骤 10 到 12: apply_snapshot()和 apply_snap()
点击此处丨阅读原文
TiKV 新架构:
Partitioned Raft KV 原理解析
架构

图 1 TiKV 架构 —— 逻辑数据分区
一个 TiKV 集群由许多数据分区(也称为 Region)组成。每个 Region 负责特定的数据片段,由其起始和结束键范围决定。它在不同的 TiKV 节点上拥有 3 个或更多的副本,并通过 raft 协议进行同步。在旧的 raft 引擎中,每个 TiKV 中只有一个 RocksDB 实例用于存储所有 Region 的数据。partitioned-raft-KV 特性引入了一个新的物理数据布局:每个 Region 都有自己的 RocksDB 实例。
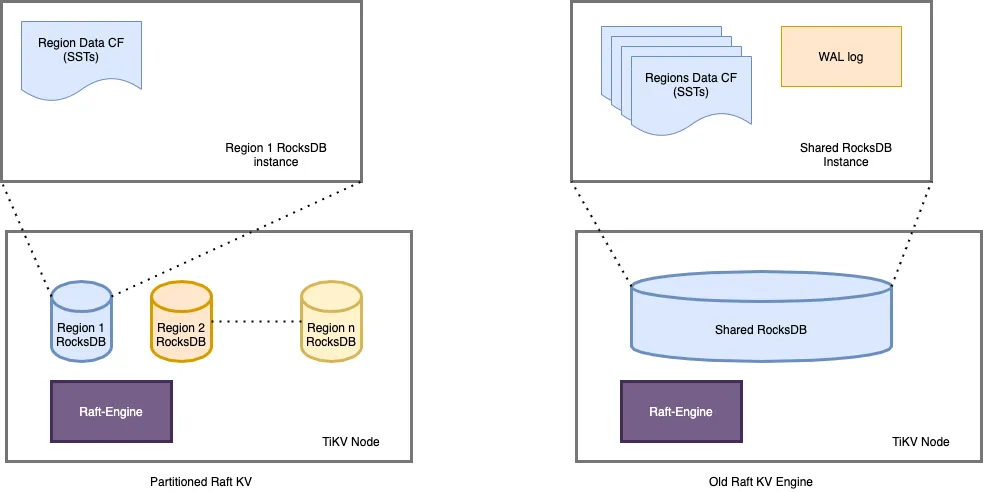
图 2:物理数据布局比较
旧 raft KV 面临的挑战
"Region" 是 TiKV 中的逻辑规模单元。每个数据访问和管理操作,如负载均衡、扩展和缩小都由 Region 进行分区。然而,在当前架构中,它是一个纯逻辑概念,物理上没有清晰的区域边界。
因此,在旧的 raft KV 引擎中,我们可能会遇到以下问题:
扩展速度慢:需多次扫描数据。
写入受限:RocksDB写入为单线程。
延迟波动:大规模数据压缩影响流量稳定性。
Partitioned-raft-KV
引擎的改进
专用RocksDB实例:每个Region拥有独立RocksDB,实现高效负载均衡,减少读放大。
独立压缩控制:热点Region触发压缩不影响其他Region,降低读写放大。
无锁并行写入:线程独立写入不同RocksDB,消除写入瓶颈,写操作仅涉及内存。
性能隔离:单个RocksDB性能问题不影响其他Region,确保存储性能独立性。
扩展容量支持:Region支持最大15GB容量,显著降低Region相关开销,提升效率。
因此,使用 partitioned-raft-KV,TiDB 在扩展或缩小数据方面的速度大约快 5 倍,并且由于压缩的影响要小得多,其性能总体上更加稳定。
未来展望
虽然增加的 RocksDB 实例带来了更高的内存需求,需额外 5GB 至 10GB 以平衡性能,这在内存受限时可能不利,但它为拥有充足内存资源并追求可扩展性和高性能写入的场景提供了显著优势。展望未来,这项功能有望在资源允许的情况下,为 TiKV 用户带来更加强大的性能体验。
点击此处丨阅读原文
👇 立即咨询 TiDB 企业版 👇
