





前言
相比于本地部署的PostgreSQL而言,云上的PG,自动化管理程度稍高些。但是如果云上PG出了问题,尤其是一些比较隐晦或者不明显的问题,解决起来,就不是很容易。有的时候不光是要解决问题,还必须得找以出问题的根本原因,才能避免将来再出现类似的问题。
最近,熊二的StrongBear作为乙方,在替甲方服务的Hyperscaler PG环境,就出现了存储容量耗尽的问题。
实例分析
事情原委
整个事情的大致情况这样的:
云上的某PG实例,几个月以来,一直很稳定。因为都是比较简单的业务数据,纯数据量的大小并不大。总共也就20G左右,并且一直很稳定。当时给这个实例初始化时申请的总容量也就150G大小。Hyperscaler要求容量大小必须是5的整数倍。
可是突然某一天,存储容量急剧上升,很快就97%, 98%, 最后100%了。
到了100%以后,估计是触发了PG实例的重启,最后,存储容量又恢复到正常的23/150 左右。
在监控的面板里看到的大概就是下图这个样子:
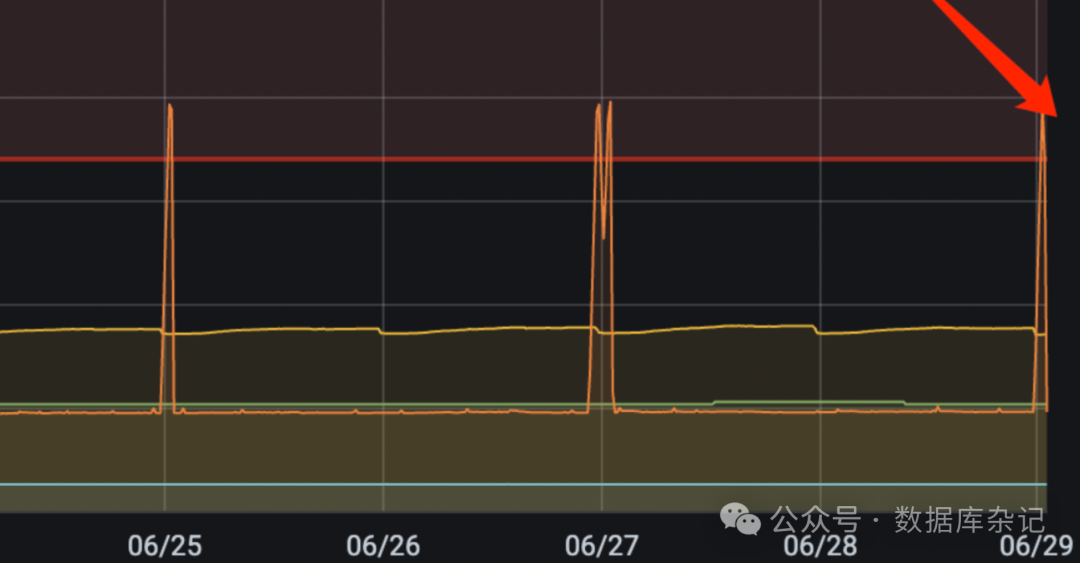
自25日起,差不多每隔两天甚至一天就发作一回。此图中的指标计算,用的是dynatrace中定义的指标,相关指标因为是绑定了RDS PG,应该是它们之间协议定义好了的指标,从这个角度来讲,对外界是一个“黑盒子”。
造成的后果不言而喻,在存储空间猛增的时候,I/O量急剧增大,系统响应时间会变慢,甚至变得不可访问,一些相关业务的访问就受损严重。也就是说提供相关SaaS服务的APP就会出现拒绝服务的问题。
诊断过程
毕竟Hyperscaler PG本质上底层来源于RDS。首先得弄明白,这个storage的计算方法。
本地部署的PG里头,一个数据库的存储空间,大概也就这样计算:
postgres=# select pg_size_pretty(pg_database_size(current_database()));
pg_size_pretty
----------------
21 GB
(1 row)
提示: 在Hyperscaler环境当中,每个PostgreSQL service实例,也只会给客户创建一个可用的Database。因此如果计算数据库消耗空间,也比较简单。上边可以看到,它消耗的空间大小21G。远不到150G的总消耗。因此,哪个地方必有猫腻。
存储空间消耗,除了DB本身的消耗(主要是存储表、索引等消耗的大小)以外,应该还有一些别的文件存储的消耗,包括哪些呢?
会包括WAL log (archive部分)的当前大小吗?
结果一查:
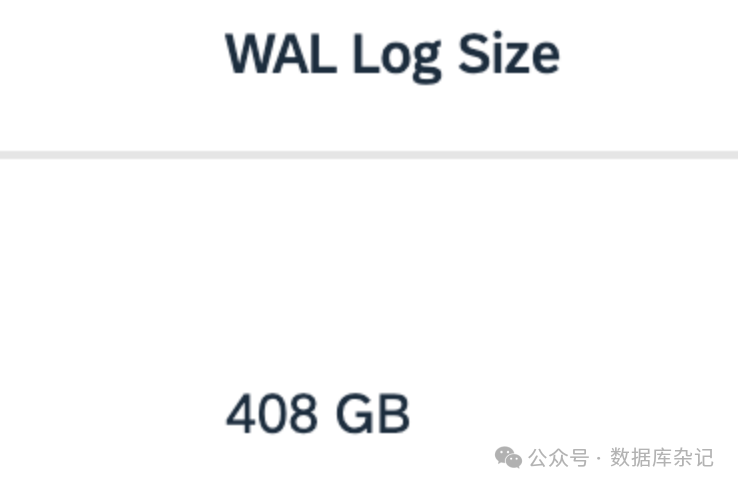
select pg_size_pretty(archived_count * 16384*1024::bigint) as wal_log_size from pg_stat_archiver;
AWS RDS底层也算是良心,并未把这部分放到存储容量计算里头。熊二清楚的记得GCP当初是把WAL log (包括archive wal log)也算在容量计算里头,导致存储开销一度猛增,最后逼迫GCP修改存储容易计算规则。
当前wal log,总量可以从下边三个参数弄到最大上限。
| max_wal_size | 2048 | MB |
|---|---|---|
| wal_keep_size | 2048 | MB |
| min_wal_size | 192 | MB |
充其量,最多也就4GB。
那么到底是哪一部分导致容量消耗激增呢?
弄清楚容量计算
为了真正弄清楚,熊二干脆直接找上了AWS的相关人员,这个storage到底是如何计算的?除了数据库本身的数据大小以外,是不是还有WAL log大小,是不是还有别的什么文件存储消耗,为何平时都没有?
这个确实是一股股疑团,在打圈圈。。。。。。
AWS那边的回复是:有可能是临时文件占据了存储空间。。。。。。。,注意,他们的回复是:“有可能”。他们自己都不能肯定。。
熊二不禁心里骂了一句:“擦。。。,这还是有可能。。。” 看来赚钱真不嫌多,里边的秘密是真的不愿意公开哈。。。“。
拨云见雾
带着这个思路,抱着一线希望,熊二还是抓住日常监控慢SQL的思路,开搞。。。。。。
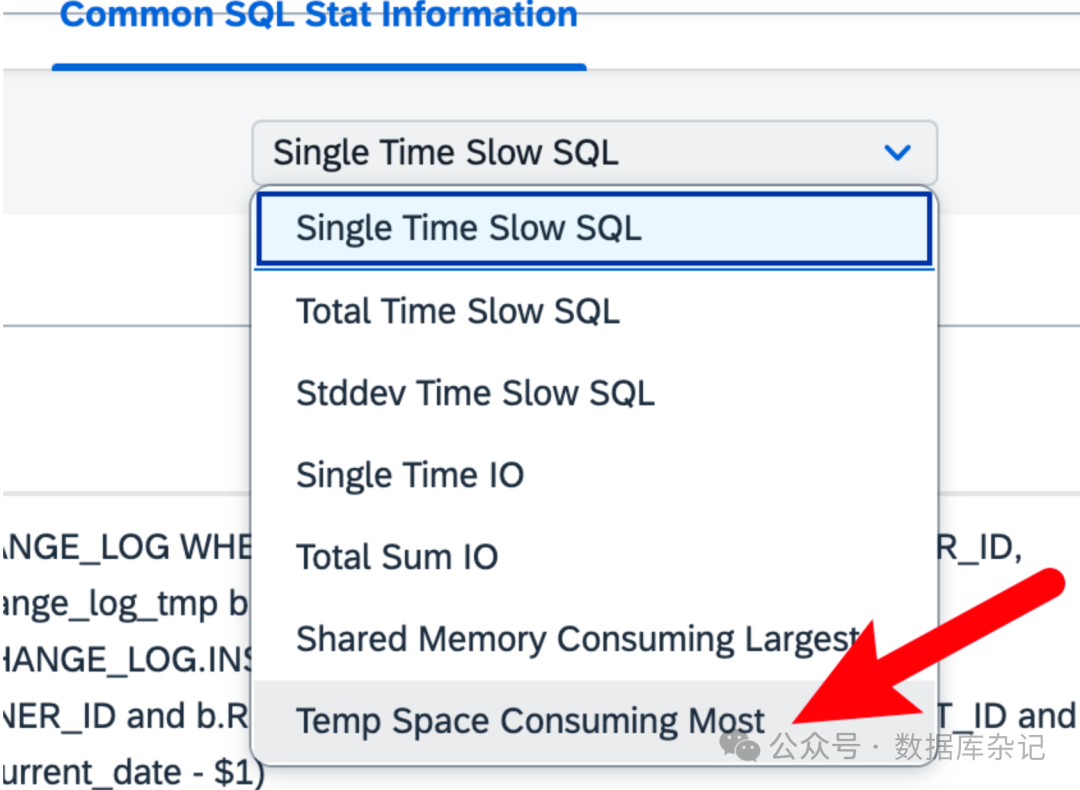
日常监控的有7类SQL指标,反正云上的PG中的扩展: pg_stat_statement是常开的。于是顺着这个思路去找,先就找最后一个: "temp space consuming most",消耗临时空间最多的SQL:
由于pg_stat_statement是累积量,可能也不太准确。于是把"Single Time IO"也列一下。最后找到了疑似出问题的几条SQL:
共有大概3条。
经过分析,这3条语句的前两条,实际上可以完全不用调用。于是在解决问题的第一天,熊二先跟开发人员沟通,让他们去掉前2条的调用。最后一条,必须经过模拟重现。
没办法,熊二快速搭建一个sandbox数据环境,让数据量、记录数、表结果跟实际的环境完全在同等规模上(事后吐槽,关键性业务,提前建一个sandbox环境,还是有用的)。
为了拿到更准确的定位结果,熊二又使用伪superuser将pg_stat_statement初始化了一下。这样在后来的一天重现的时候,又能拿到temp space consuming most的结果,那个来得更准确。
熊二在sandbox里头,将定位的SQL进行分析,也就找到了根本原因。下边只是简单的列出一个差不多类似的示例。实际语句要复杂的多。
mydb=# explain analyze select * from customer where col2 like 'Btt%';
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Seq Scan on customer (cost=0.00..3961.00 rows=20 width=25) (actual time=21.797..21.798 rows=0 loops=1)
Filter: ((col2)::text ~~ 'Btt%'::text)
Rows Removed by Filter: 2000000
Planning Time: 1.891 ms
Execution Time: 890.821 ms
(5 rows)
explain (analyze, buffers, timing, costs) select * from xxx_device d1 where d1.username like 'anonymous_%' and exists (select 1 from xxx_device d2 where d2.tenant_name = d1.tenant_name
and d2.xdeviceid=d1.xdeviceid and d2.username not like 'anonymous_%');
......
总之,就是原来在varchar上建的索引,压根就用不上。
为啥?因为实例创建的时候用的是:
lc_collate:en_US.UTF-8
解决方法类似于:
create index idx2_customer_col2 on customer(col2 varchar_pattern_ops);
还有一些别的复合索引。
经此调整之后,存储空间激增的问题再也没有出现过。
为了加固临时文件方面的监控,熊二又增加了临时文件的监控:
select temp_bytes as total_tmp_size FROM pg_stat_database where datname = current_database();
select temp_files as total_tmp_files_count FROM pg_stat_database where datname = current_database();

通过这个量的变化,也可以判断是不是tmp文件增长过快。
总结:
云上的PostgreSQL有很多地方都完全控制在provider手上,作为相关的维护管理人员,很可能你就是戴着镣铐在跳舞。但是基本的管理思虑不变,一些重大的异常指标一定要引起重视,出现的时候,除了解决问题,还要争取找到出问题的根源。
这里边,dynatrace的APM监控,应该是与AWS尝试绑定了,对外界,有一些指标并未明确告诉你对应PostgreSQL当中哪些具体的参数或者查询。这个就需要用户自己跟AWS充分沟通甚至要自己动手实验验证了。
从不认为云上的数据库管理与维护就简单,有时候需要更多更全面的综合分析判断,才能找到症结。毕竟,很多操作,你是不能直接进行的。

往期导读:
1. PostgreSQL中配置单双向SSL连接详解
2. 提升PSQL使用技巧:PostgreSQL中PSQL使用技巧汇集(1)
3. 提升PSQL使用技巧:PostgreSQL中PSQL使用技巧汇集(2)
4. PostgreSQL SQL的基础使用及技巧
5. PostgreSQL开发技术基础:过程与函数
6. PostgreSQL中vacuum 物理文件truncate发生的条件
7. PostgreSQL中表的年龄与Vacuum的实验探索:Vacuum有大用
8. PostgreSQL利用分区表来弥补AutoVacuum的不足
9. 也聊聊PostgreSQL中的空间膨胀与AutoVacuum
10. 正确理解SAP BTP中hyperscaler PG中的IOPS (AWS篇)
