初始化环境
studio-conda -t lmdeploy -o pytorch-2.1.2
conda create -n lmdeploy python=3.10
conda activate lmdeploy
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
使用 Conda 来创建和配置一个专门的 Python 环境以便部署深度学习模型,特别是使用 PyTorch 框架。
# 如果是InternStudio 可以直接使用
:# studio-conda -t lmdeploy -o pytorch-2.1.2
:-t lmdeploy
可能表示使用一个名为 "lmdeploy" 的模板,-o pytorch-2.1.2
指定了使用 PyTorch 版本 2.1.2 。
创建新的 Conda 环境:
conda create -n lmdeploy python=3.10
:这个命令用于创建一个名为lmdeploy
的新的 Conda 环境,并指定环境中的 Python 版本为 3.10。这是为了确保环境中的软件包依赖能正确工作在指定的 Python 版本上。
激活 Conda 环境:
conda activate lmdeploy
:激活刚创建的lmdeploy
环境。确保后续的所有包安装和操作都在这个虚拟环境中进行,避免影响系统中的其他 Python 环境。
安装 PyTorch 和相关包:
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
:安装指定版本的 PyTorch 及其相关库(torchvision 和 torchaudio)。同时,指定了pytorch-cuda=12.1
来安装对应版本的 CUDA 支持,使 PyTorch 能够在 NVIDIA 的 GPU 上运行。-c pytorch -c nvidia
将从 PyTorch 官方的 channel 和 NVIDIA 的 channel 安装,确保软件包的官方来源和兼容性。
pip install -U lmdeploy[all]
使用 pip 来安装 "lmdeploy" 的包,并且通过 [all]
指定了安装包的额外选项。
[all]
是一种 pip 支持的附加语法,用于指定安装额外的依赖项,通常是一些可选的或额外的功能。在这种情况下,[all]
可能表示安装 "lmdeploy" 包的所有附加组件或依赖项,以确保包的完整功能可用。这种使用方式可能源于 "lmdeploy" 包的作者将一些额外的功能或依赖项,并通过 [all]
标记提供了一种便捷的方式来安装所有内容。
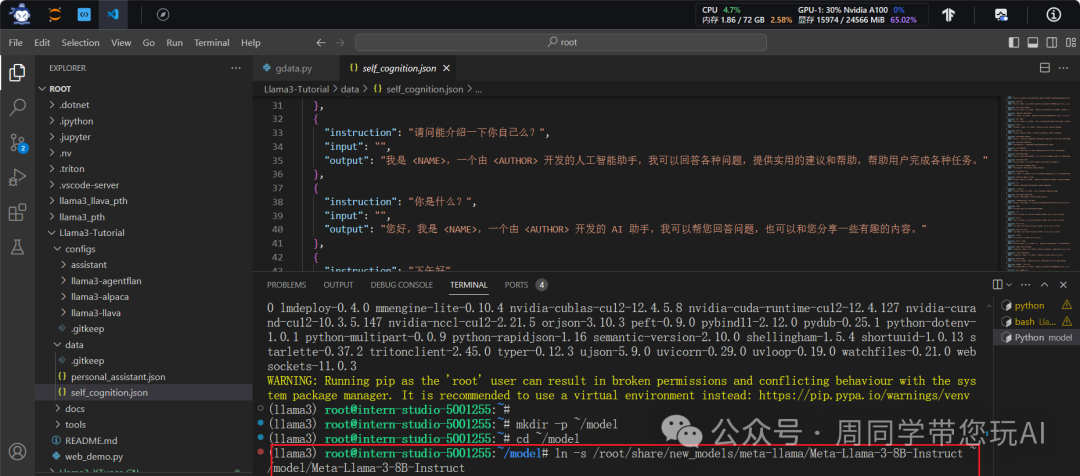
mkdir -p ~/model
cd ~/model
ln -s root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
在 Linux 系统中创建一个符号链接(symbolic link),将 /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct
这个文件或目录链接到 /root/model/Meta-Llama-3-8B-Instruct
这个位置。
ln -s
:创建符号链接的命令。-s
选项表示创建一个符号链接,而不是硬链接。/root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct
:这是源文件或目录的路径,即要创建符号链接指向的位置。~/model/Meta-Llama-3-8B-Instruct
:这是符号链接的目标路径,即新创建的符号链接将被命名为Meta-Llama-3-8B-Instruct
,并位于~/model/
目录下(~
表示当前用户的家目录)。
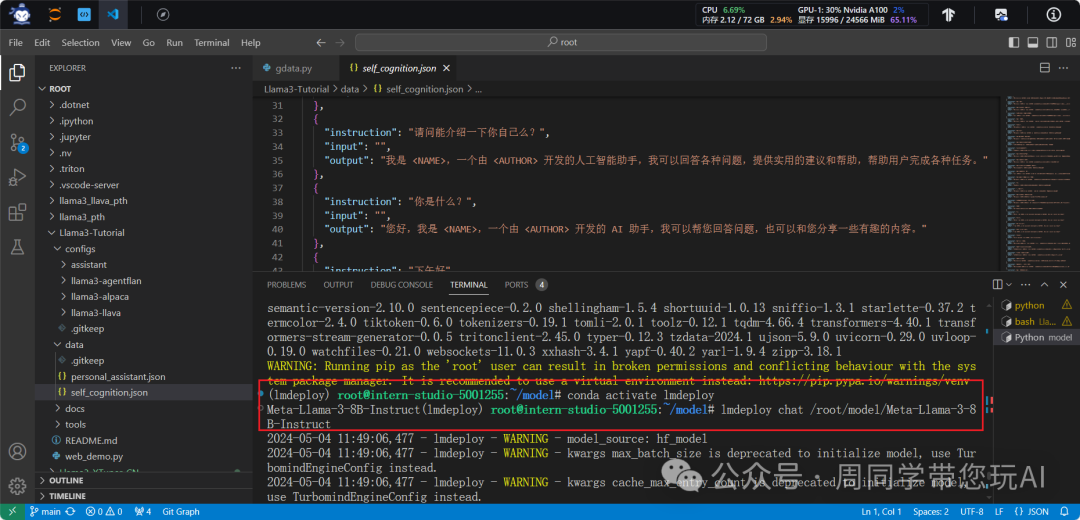
conda activate lmdeploy
lmdeploy chat root/model/Meta-Llama-3-8B-Instruct
conda activate lmdeploy
:激活了 "lmdeploy" 的 Conda 环境。确保后续执行的命令都在该环境中进行,以防止与其他环境的冲突。lmdeploy chat root/model/Meta-Llama-3-8B-Instruct
:调用了 "lmdeploy" 的命令行工具,并向其传递了两个参数,分别是 "chat" 和/root/model/Meta-Llama-3-8B-Instruct
。用于执行某种与 "Meta-Llama-3-8B-Instruct" 相关的操作。
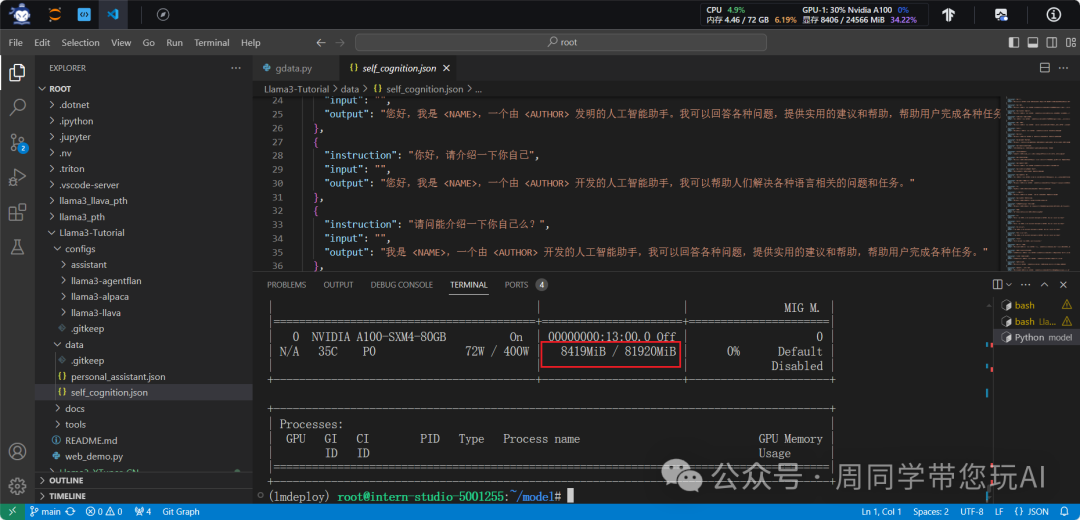
nvidia-smi
命令可以列出系统中安装的所有 NVIDIA GPU 的详细信息
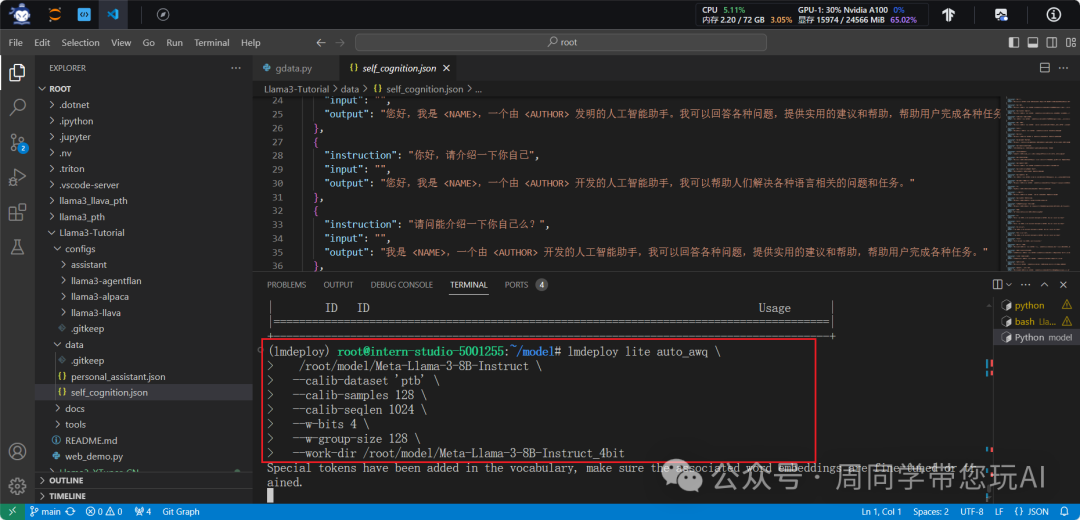
lmdeploy lite auto_awq \
root/model/Meta-Llama-3-8B-Instruct \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir root/model/Meta-Llama-3-8B-Instruct_4bit
lite auto_awq
:用于指定执行 "auto_awq"(自动混合精度量化)操作。 "lite" 是针对轻量级模型的。/root/model/Meta-Llama-3-8B-Instruct
:要执行操作的模型文件或目录的路径,即 Meta-Llama-3-8B-Instruct 模型所在的位置。--calib-dataset 'ptb'
:指定了用于量化校准(calibration)的数据集。在这种情况下,'ptb' 是一个代表数据集的标识符。--calib-samples 128
:指定了用于量化校准的样本数。--calib-seqlen 1024
:指定了用于量化校准的序列长度。--w-bits 4
:指定了权重的位宽,即量化后的权重将使用 4 位表示。--w-group-size 128
:指定了权重分组的大小,是为了优化量化算法。--work-dir root/model/Meta-Llama-3-8B-Instruct_4bit
:指定了工作目录,是为了保存量化后的模型和其他相关文件。
lmdeploy chat root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
量化工作结束后,新的HF模型被保存到Meta-Llama-3-8B-Instruct_4bit
目录。下面使用Chat功能运行W4A16量化后的模型。
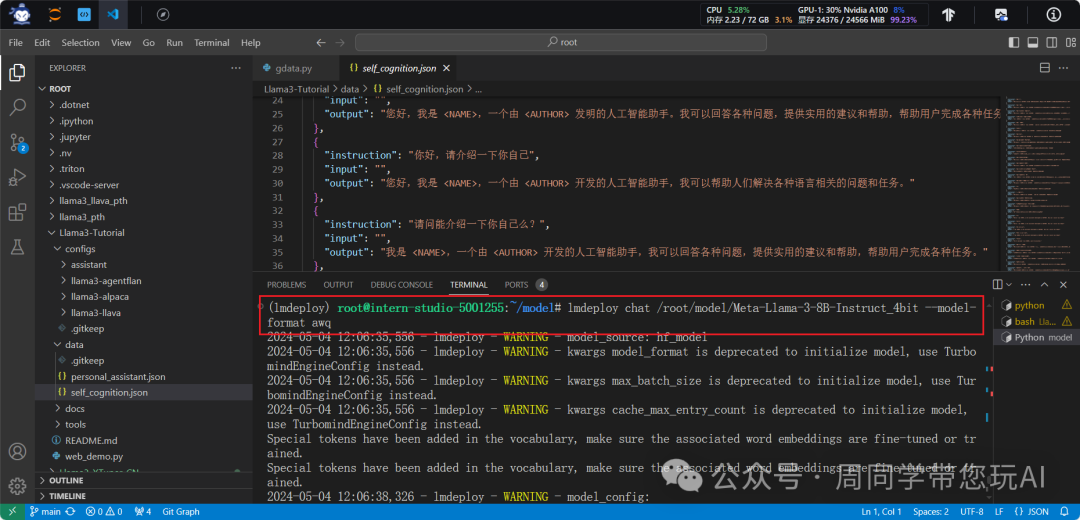
lmdeploy chat root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01
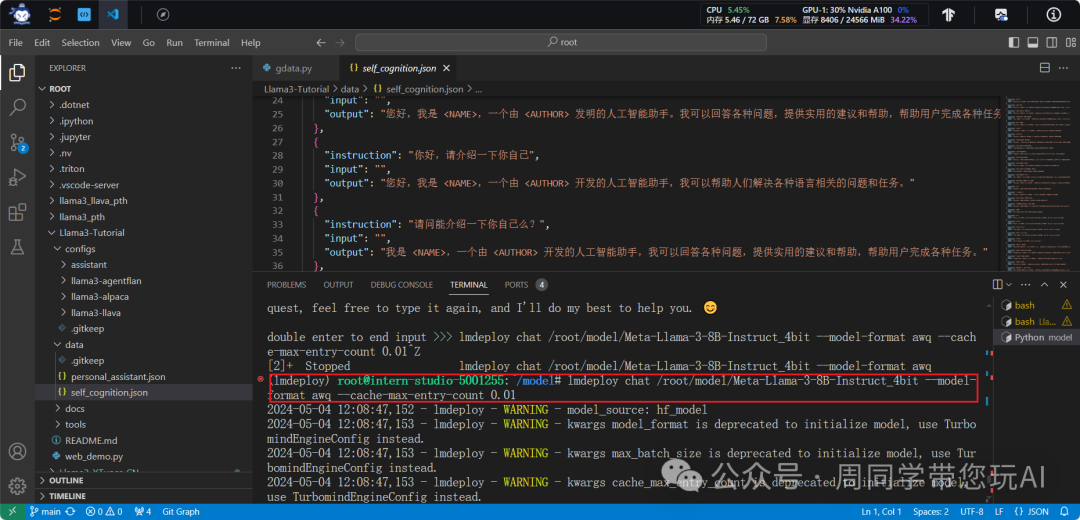
为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。
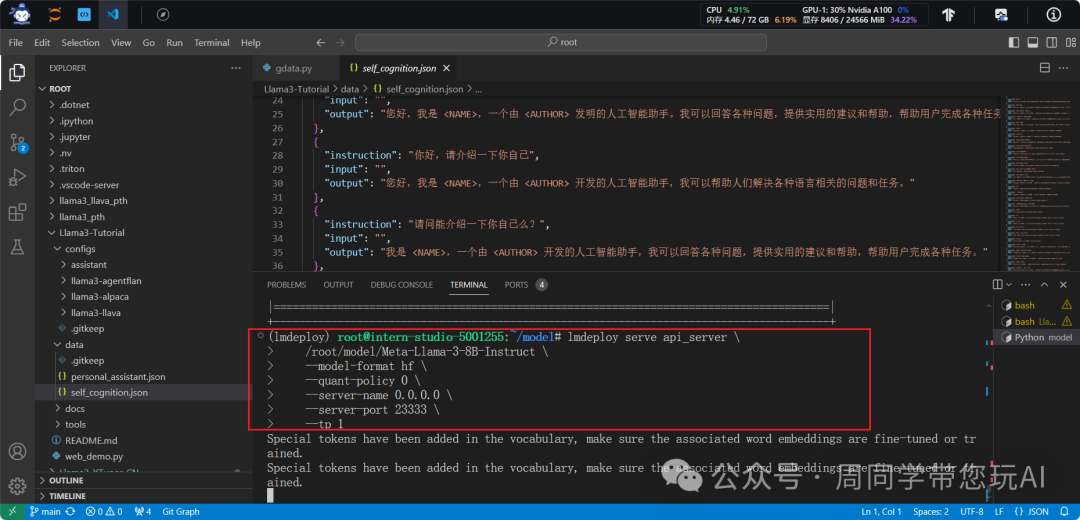
lmdeploy serve api_server \
root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
serve api_server
:是命令的子命令或参数,用于指定要启动的服务类型,这里是一个 API 服务器。/root/model/Meta-Llama-3-8B-Instruct
:指定要部署的模型文件或目录的路径,即 Meta-Llama-3-8B-Instruct 模型所在的位置。--model-format hf
:指定了模型的格式,是 "hf",表示模型使用 Hugging Face 模型仓库的格式。--quant-policy 0
:指定了量化策略,这里的 "0" 预定义的策略标识符。--server-name 0.0.0.0
:指定了服务器的名称,这里设置为 "0.0.0.0",表示服务器将监听所有可用的网络接口。--server-port 23333
:指定了服务器的端口号,这里设置为 23333。--tp 1
:指定了服务器的线程池大小,即同时处理的请求数量。
conda activate lmdeploy
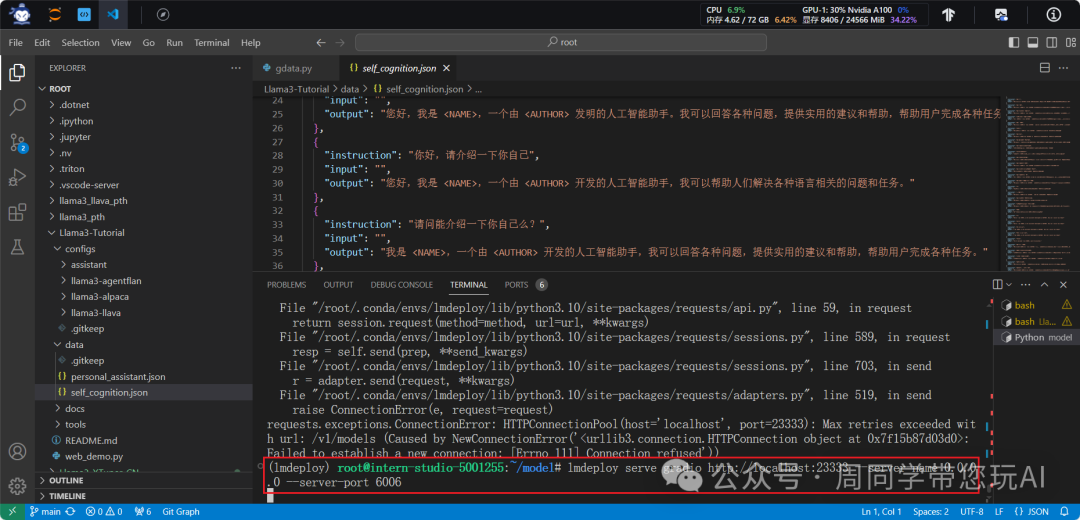
lmdeploy serve api_client http://localhost:23333
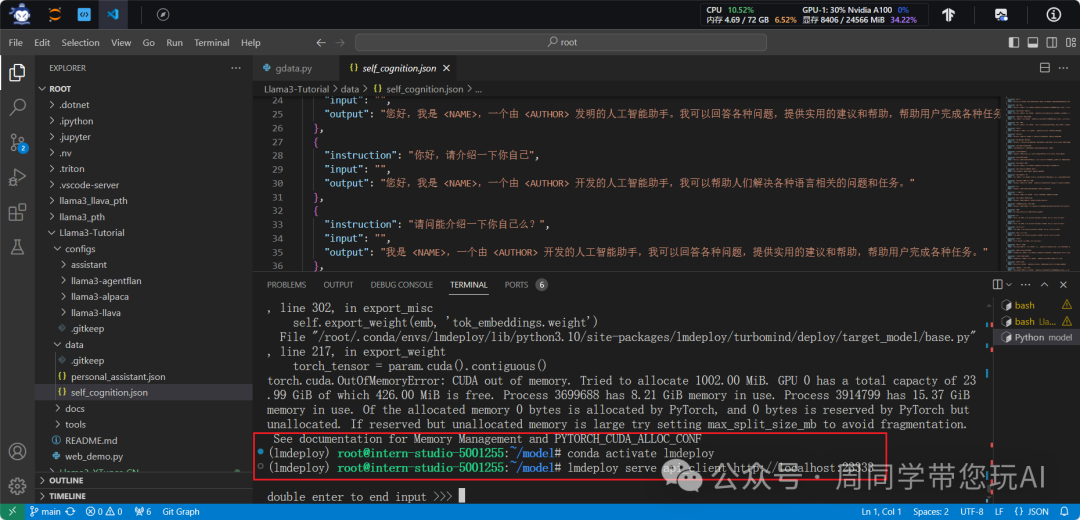
pip install gradio==3.50.2
conda activate lmdeploy
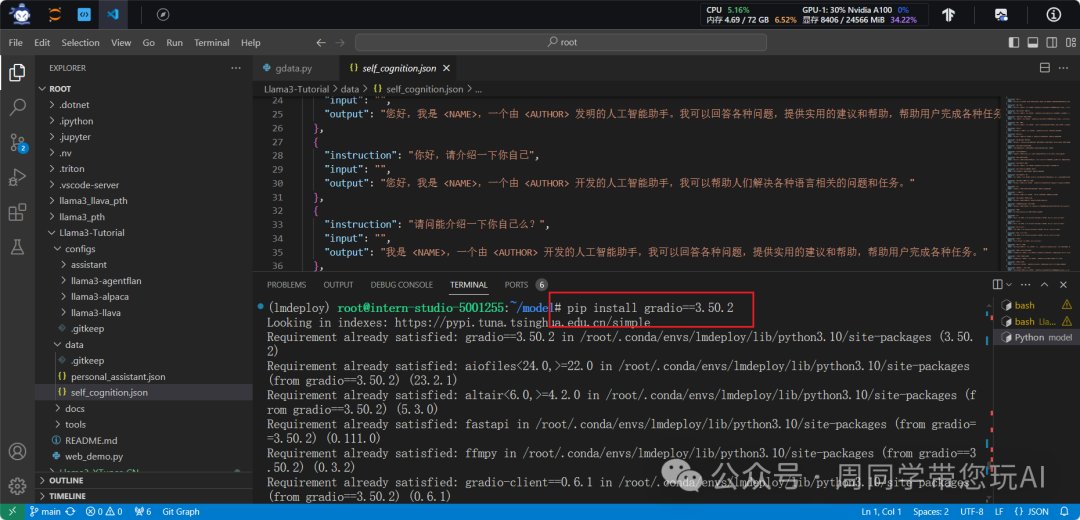
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
serve gradiohttp://localhost:23333
:用于指定要启动的服务类型,这里是一个 Gradio 服务器,并指定了 Gradio 服务器要调用的模型服务的地址,这里是 http://localhost:23333。--server-name 0.0.0.0
:指定了服务器的名称,这里设置为 "0.0.0.0",表示服务器将监听所有可用的网络接口。--server-port 6006
:指定了服务器的端口号,这里设置为 6006。
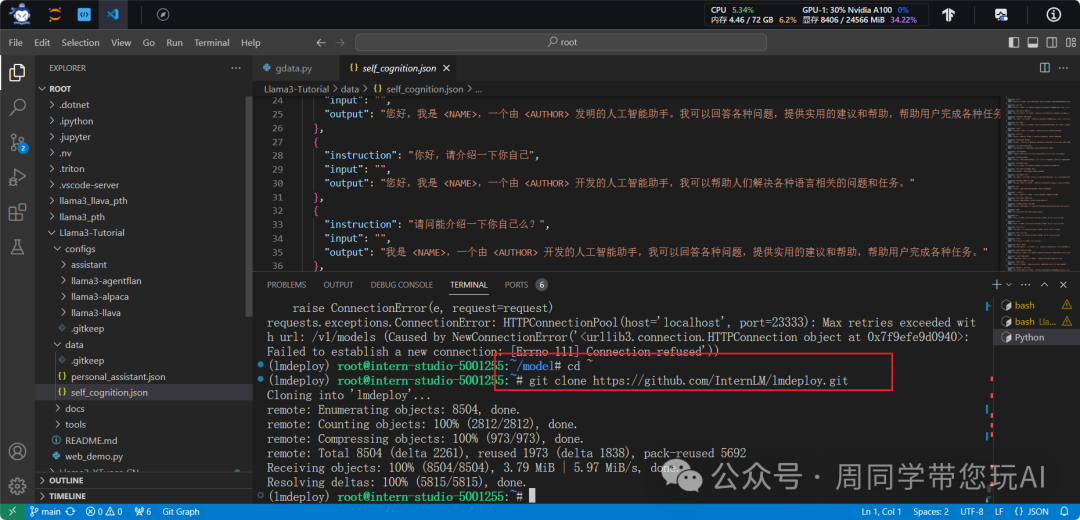
cd ~
git clone https://github.com/InternLM/lmdeploy.git
cd root/lmdeploy
wget https://hf-mirror.com/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
wgethttps://hf-mirror.com/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
:wget
命令从指定的 URL 下载了一个名为ShareGPT_V3_unfiltered_cleaned_split.json
的 JSON 文件。wget
是一个用于在命令行中下载文件的工具,后面的 URL 是要下载的文件的地址。
python benchmark/profile_throughput.py \
ShareGPT_V3_unfiltered_cleaned_split.json \
root/model/Meta-Llama-3-8B-Instruct \
--cache-max-entry-count 0.8 \
--concurrency 256 \
--model-format hf \
--quant-policy 0 \
--num-prompts 10000
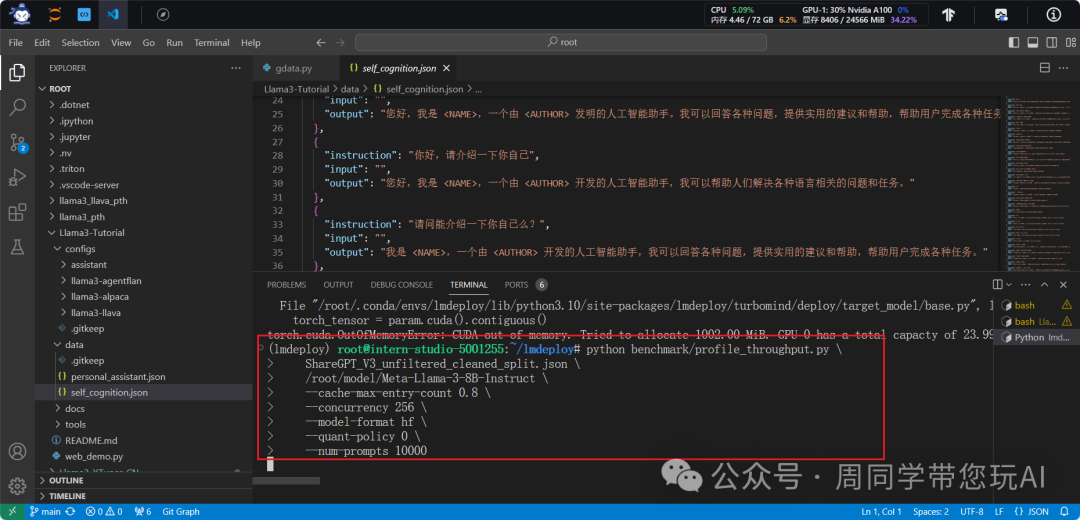
benchmark/profile_throughput.py
:执行的 Python 脚本,用于执行性能测试并输出结果。ShareGPT_V3_unfiltered_cleaned_split.json
:用于性能测试的数据集文件的路径。/root/model/Meta-Llama-3-8B-Instruct
: Meta-Llama-3-8B-Instruct 模型文件或目录的路径,测试将使用该模型进行推理。--cache-max-entry-count 0.8
:指定了缓存的最大条目数占总数据集大小的比例,这里设置为 0.8。--concurrency 256
:指定了并发数,即同时进行推理的请求数量,这里设置为 256。--model-format hf
:指定了模型的格式,是 "hf",表示模型使用 Hugging Face 模型仓库的格式。--quant-policy 0
:指定了量化策略,这里的 "0" 是预定义的策略标识符。--num-prompts 10000
:指定了要进行推理的提示(prompt)数量,这里设置为 10000。
pip install git+https://github.com/haotian-liu/LLaVA.git
from lmdeploy import pipeline, ChatTemplateConfig
from lmdeploy.vl import load_image
pipe = pipeline('xtuner/llava-llama-3-8b-v1_1-hf',
chat_template_config=ChatTemplateConfig(model_name='llama3'))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response.text)
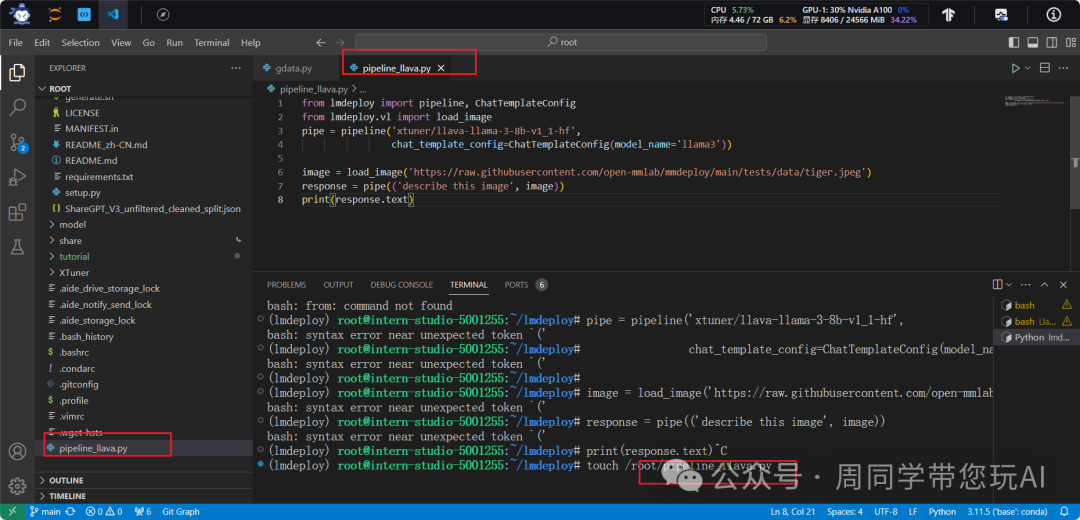
from lmdeploy import pipeline, ChatTemplateConfig
:导入语句引入了 lmdeploy 库中的 pipeline 和 ChatTemplateConfig 类,用于构建模型 pipeline 和配置聊天模板。from lmdeploy.vl import load_image
:导入语句引入了 lmdeploy 库中的 load_image 函数,用于加载图像数据。pipe = pipeline('xtuner/llava-llama-3-8b-v1_1-hf', chat_template_config=ChatTemplateConfig(model_name='llama3'))
:创建了一个 pipeline 对象,使用了 'xtuner/llava-llama-3-8b-v1_1-hf' 这个模型,并且配置了聊天模板的参数,模型名称为 'llama3'。image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
:使用 load_image 函数从指定的 URL 加载了一张图片。response = pipe(('describe this image', image))
:调用了 pipeline 对象的方法,将描述图片的请求和加载的图片作为参数传递给它,然后得到了一个 response 对象。print(response.text)
:这行代码打印了 response 对象的文本内容,即模型对图片的描述结果。