




论文概述
随着深度学习和大语言模型在生产环境的广泛部署,越来越多的高维向量数据被生产出来。管理和使用大规模的向量数据带来了巨大的时间和空间成本。

关键算法
索引结构
Elpis采用树+图的索引结构。首先由一棵树形索引快速将空间分区,数据在此时被聚类成合适大小的簇;此后Elpis在每个簇的数据上建HNSW图。
查询时,Elpis首先找到包含query的叶子节点,并在其对应的HNSW图上进行搜索获得初始结果。之后继续在树索引中使用优先级队列进行遍历:优先搜索距离query更近的分区,通过控制搜索节点的个数来控制召回与查询时延的trade-off。
Hercules树索引
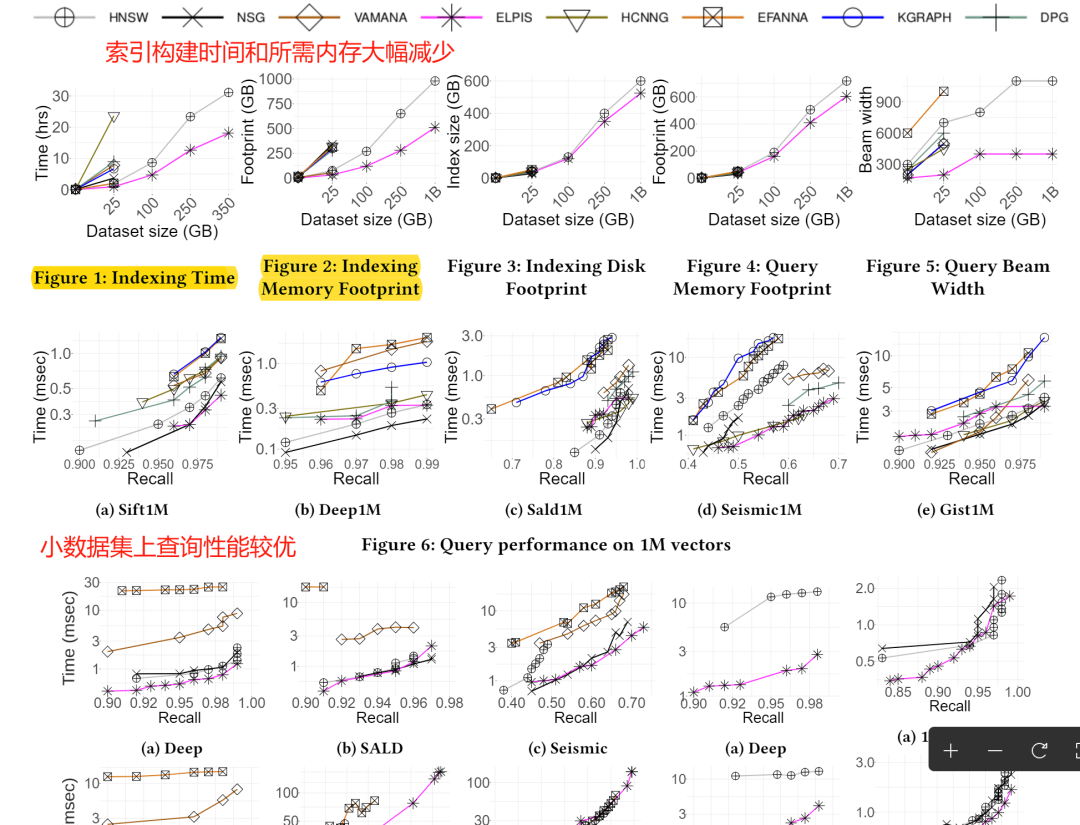
树+图索引结构的核心思想是可以降低单个图的规模:从全量降低至聚类簇的大小。由于图索引的构建复杂度是超线性的,分拆构建可以降低整体时延,而且可以提高并行度。
然而,由于查询候选只局限于一个数据子集中,树索引的聚类效果会直接影响到查询精度。因此本文选择了一个精心设计的树索引Hercules (VLDB'22)。
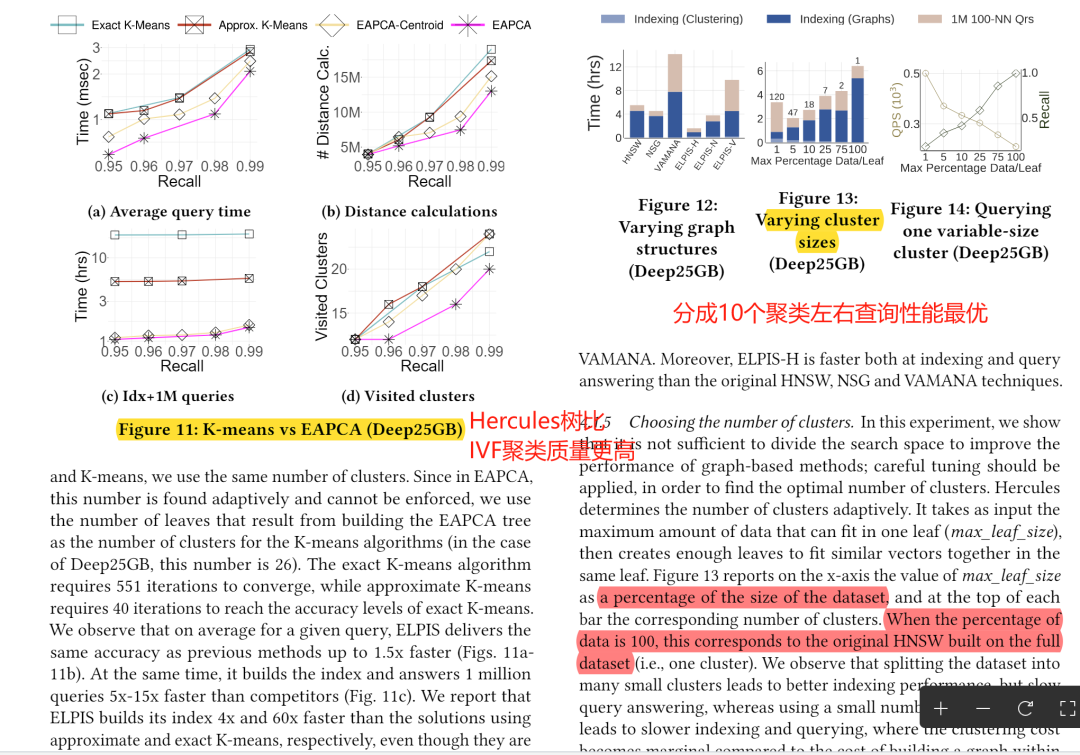
Hercules基于数据分布的特征,自适应地将数据分段,并在所有分段中,找出最适合代表聚类特征的某一个子段,根据在该子段上的数据均值或标准差进行空间分割。
相比于IVF/K-means等算法,Hercules不需要迭代训练,而是在构建索引时根据局部数据分布自适应寻找空间分割方式,使得Hercules构建速度快、分割质量更好。
并行算法
精彩段落

<<< 左右滑动见更多 >>>
总结
本文设计了一个针对十亿级数据集的向量索引Elpis,在图索引的上层引入了Hercules树,首先对大数据集分区,再在分区中建图索引。Elpis在大数据集上获得了突出的性能提升。
文章给予的一个重要启示是图索引的可伸缩性,即随着数据量增长,图索引的查询性能并未获得期望的对数级别增长,反而更接近线性,这使得其存在明显的性能缺口和改善空间。
延伸阅读
[1] VLDB'22:Hercules树索引 Hercules against data series similarity search (https://arxiv.org/pdf/2212.13297)
[2] VLDB'13:DSTree树索引 A data-adaptive and dynamic segmentation index for whole matching on time series (https://vldb.org/pvldb/vol6/p793-wang.pdf)
[3] PPoPP'24: 十亿级图索引并行算法与性能比较 ParlayANN: Scalable and Deterministic Parallel Graph-Based Approximate Nearest Neighbor Search Algorithms (https://www.cs.ucr.edu/~ygu/papers/PPoPP24/parlayann.pdf)
编者简介

王泽宇
个人主页:https://zeyuwang.top/
谷歌学术:https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ
