




一、简单思考
-- 准备两个SCHEMA CREATE SCHEMA schema_a;
CREATE SCHEMA schema_b;-- 创建三个func函数 CREATE OR REPLACE FUNCTION schema_a.func()
RETURNS TEXT
AS $$
DECLARE
va text DEFAULT 'schema_a';
BEGIN
RAISE NOTICE 'schema_a.func()';
RETURN va;
END $$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION schema_b.func()
RETURNS TEXT
AS $$
DECLARE
va text DEFAULT 'schema_b';
BEGIN
RAISE NOTICE 'schema_b.func()';
RETURN va;
END $$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION schema_b.func(aa TEXT)
RETURNS TEXT
AS $$
DECLARE
BEGIN
RAISE NOTICE 'schema_a.func(TEXT)';
RETURN aa;
END $$ LANGUAGE plpgsql;
set search_path = 'schema_a','schema_b';
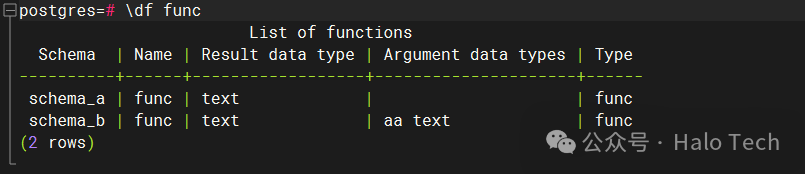
-- \df func 出来几条数据、出来的数据内容大概是什么
好了,不卖关子了,谜底揭晓。如果此时使用\df func查询,最终出来将会是两条数据,分别是schema_a.func()和schema_b.func(aa text),实际运行如下图所示
SELECT proname,pronamespace::regnamespace,proargtypes,prorettype::regtype FROM pg_proc WHERE proname = 'func';
如下图,可以看到在系统表中确确实实有三条数据,和之前的创建语句一一对应

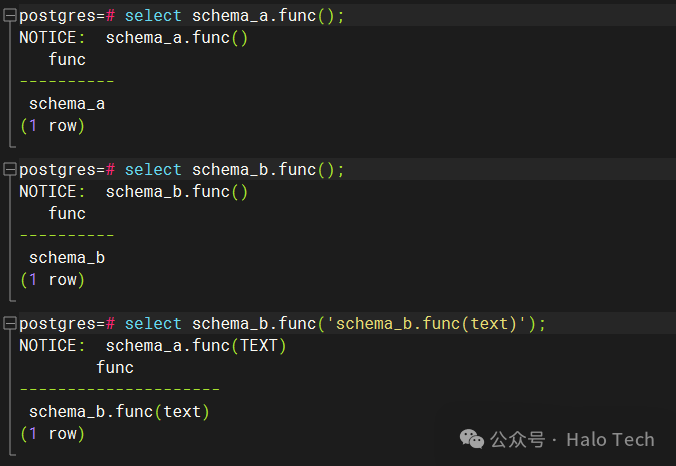
可以看到数据实际上并没有丢失,并且能正常按照逻辑运行。而出现使用\df func只出来两条数据这种情况是由psql工具中隐含的search_path和某些可见性规则决定的。考虑到可能有部分同学对于search_path不熟悉或者正在学习阶段,所以接下来我会介绍和描述如何使用search_path,对于此处的显示问题的实际分析在第五节,熟悉search_path的同学可以直接快进到第五节。
3、第三方应用的对象可以放在独立的模式中,这样它们就不会与其他对象的名称发生冲突。
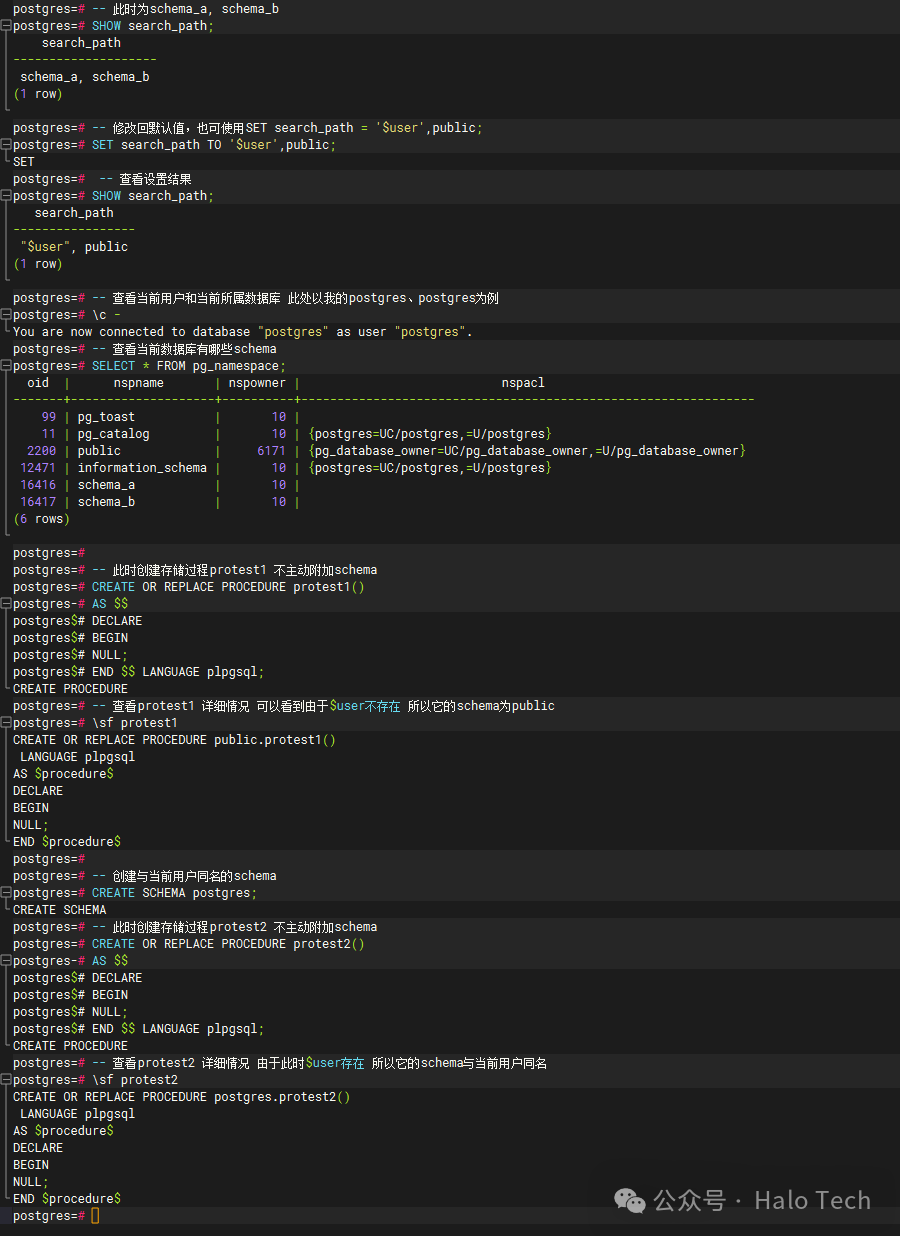
-- 此时为schema_a, schema_b
SHOW search_path;
-- 修改回默认值,也可使用SET search_path = '$user',public;
SET search_path TO '$user',public;
-- 查看设置结果
SHOW search_path;
-- 查看当前用户和当前所属数据库 此处以我的postgres、postgres为例
\c -
-- 查看当前数据库有哪些schema
SELECT * FROM pg_namespace;
-- 此时创建存储过程protest1 不主动附加schema
CREATE OR REPLACE PROCEDURE protest1()
AS $$
DECLARE
BEGIN
NULL;
END $$ LANGUAGE plpgsql;
-- 查看protest1 详细情况 可以看到由于$user不存在 所以它的schema为public
\sf protest1
-- 创建与当前用户同名的schema
CREATE SCHEMA postgres;
-- 此时创建存储过程protest2 不主动附加schema
CREATE OR REPLACE PROCEDURE protest2()
AS $$
DECLARE
BEGIN
NULL;
END $$ LANGUAGE plpgsql;
-- 查看protest2 详细情况 由于此时$user存在 所以它的schema与当前用户同名
\sf protest2
结果如下
阅读到此处应该对search_path的使用有了一个大概的了解。那么在PostgreSQL内部,以此处的函数或存储过程(在内部其实一样的处理逻辑)的创建为例,研究下search_path是如何辅助pg数据库确认该使用哪个schema的呢?
-- 删除与用户同名的schema
DROP SCHEMA postgres;
-- 此时创建存储过程protest3 不主动附加schema
CREATE OR REPLACE PROCEDURE protest3()
AS $$
DECLARE
BEGIN
NULL;
END $$ LANGUAGE plpgsql;
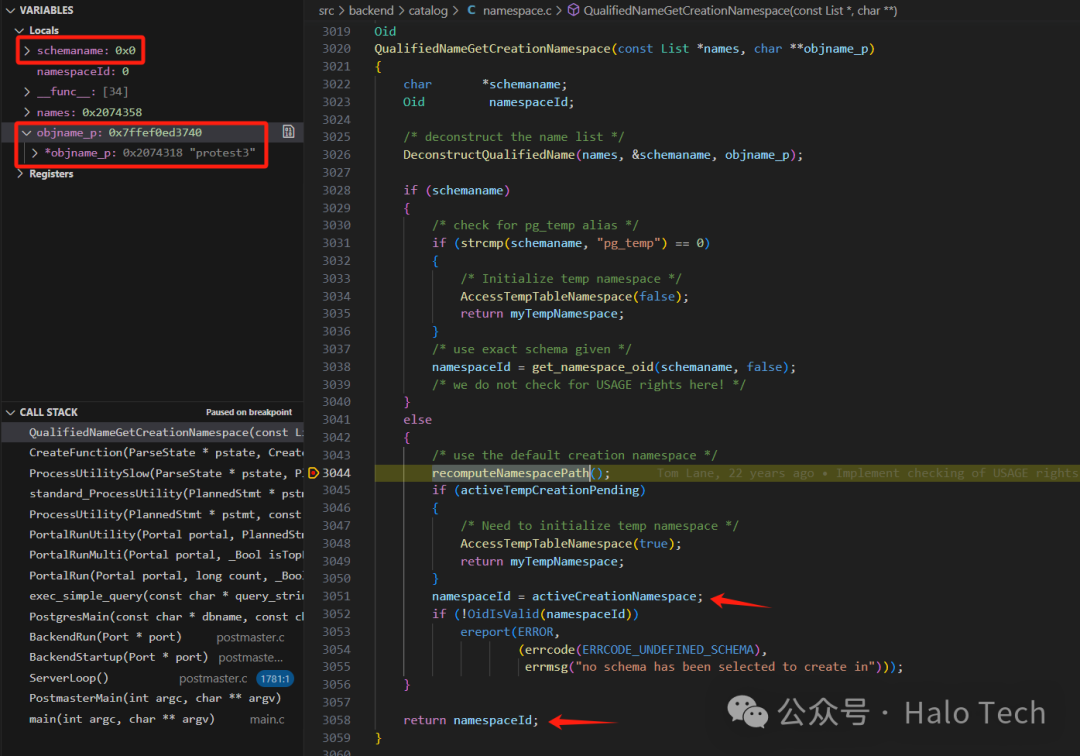
接着查看recomputeNamespacePath ,开头就看见熟悉的身影,这个rawname拷贝了namespace_search_path,然后按","分割存储在namelist中,而他的数据又是那么亲切,那么有没有一种可能它就是search_path在内部的表现,所以先查看下namespace_search_path
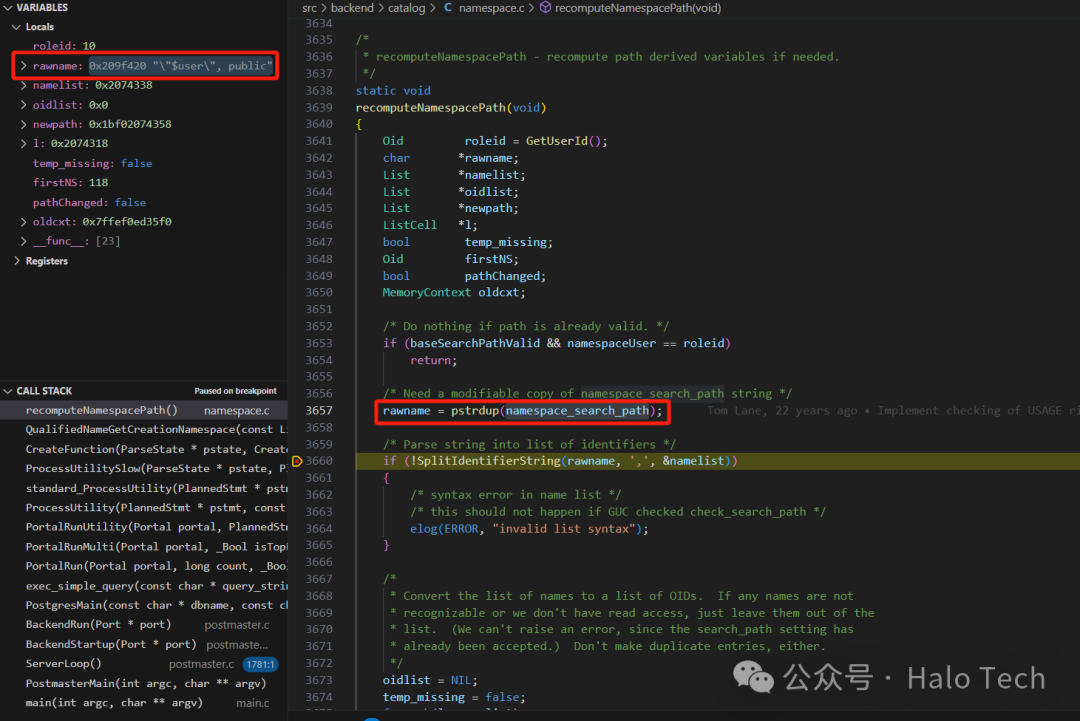
在src/backend/utils/misc/guc_tables.c 我们可以看见这麽一段,所以在外部是search_path,在内部为namespace_search_path
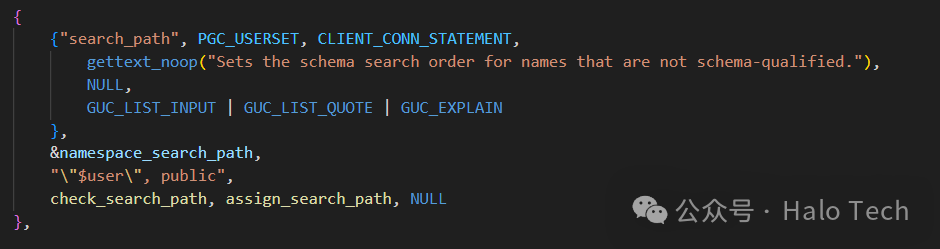
接着我们回到recomputeNamespacePath 函数接着查看,紧接着它对namelist进行一个foreach操作,从代码的逻辑不难看出
主要针对三类进行处理
1、$user,根据当前的roleid获取到用户名,依据用户名查询pg_namespace是否存在同名schema,如果存在获取oid数据 判断是否有效 进行acl检查 将其存储在oidlist当中
2、pg_temp,此处不涉及 感兴趣后续可自行阅读
3、其他的常规schema,直接按照设定的schema 如:public 查询pg_namespace中的数据,如果存在获取oid数据 判断是否有效 进行acl检查 将其存储在oidlist当中
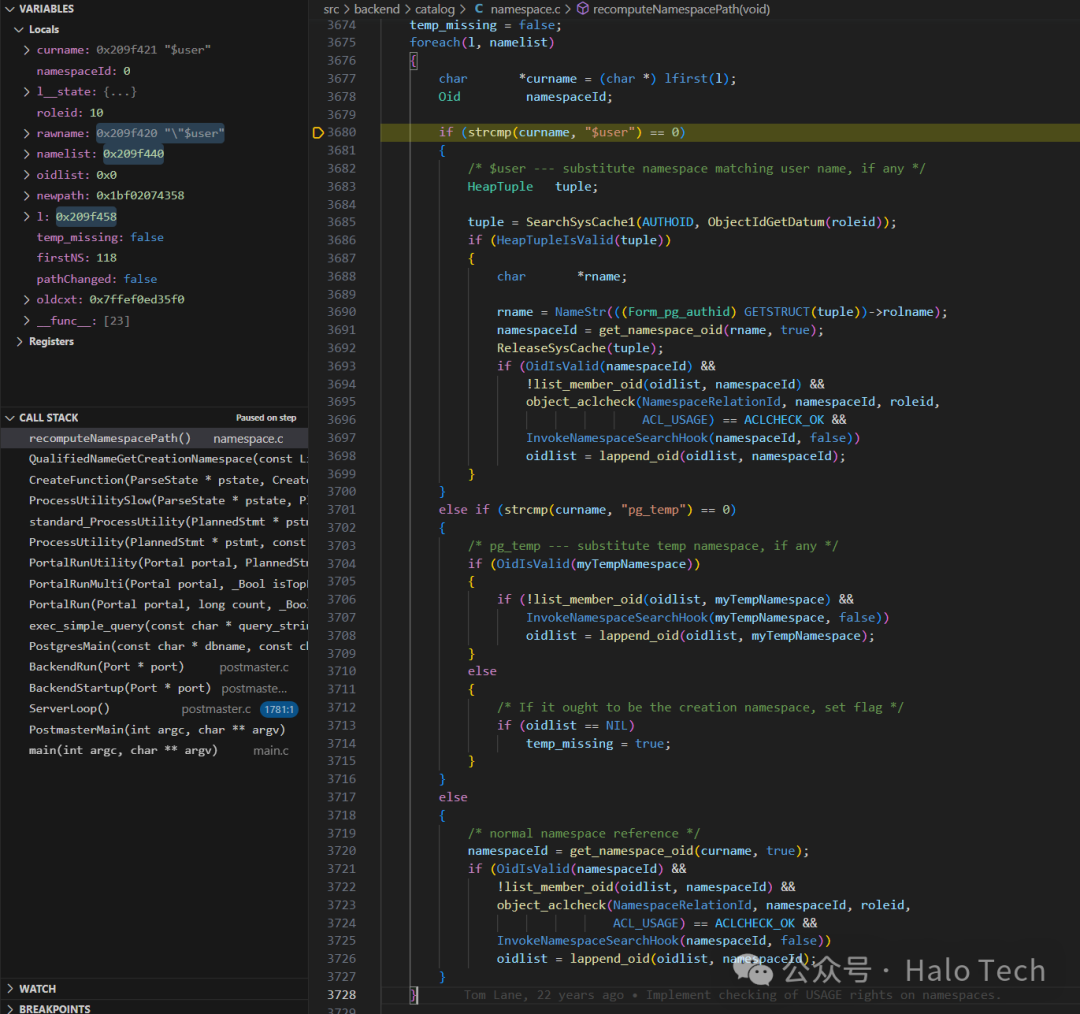
接着就是处理oidlist 而我们不需要注意太多的东西 最开始说到,我们实际上只要关注activeCreationNamespace是如何被赋值的,因为activeCreationNamespace就是最终的namespace,而如图所示,它取到了oidlist中的第一个也就是public的oid,所以最终protest3会被创建在public这个公共模式下。
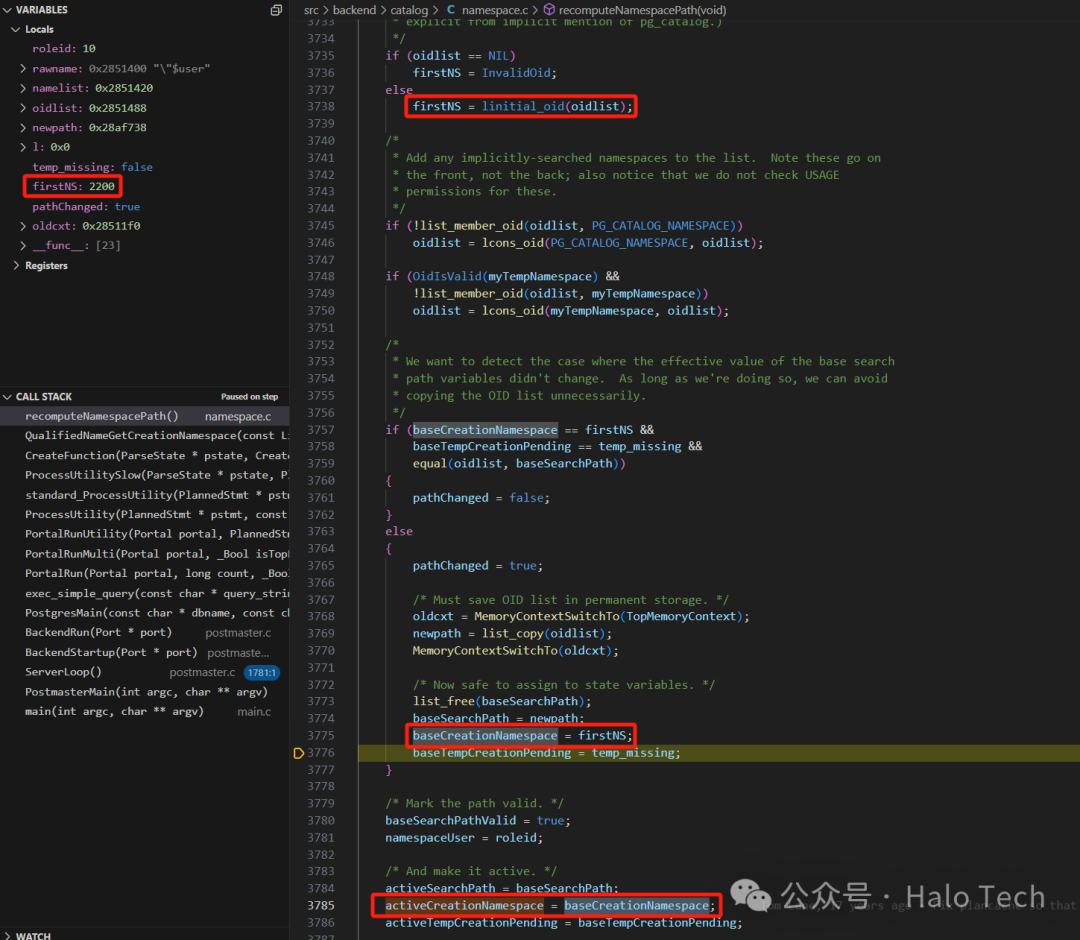
由于此次baseSearchPathValid置为了true,当search_path没有发生变化的时候,将不再执行这些操作,直接获取这个activeCreationNamespace即可。如果你也想这样子调试的话,需要注意一下。
-- 重新设置回去进行分析
set search_path = 'schema_a','schema_b';
-- 可以使以"\"开头的命令对应的实际执行SQL语句打印出来
\set ECHO_HIDDEN on
-- 再次查看
\df func
\set ECHO_HIDDEN off
运行结果如下
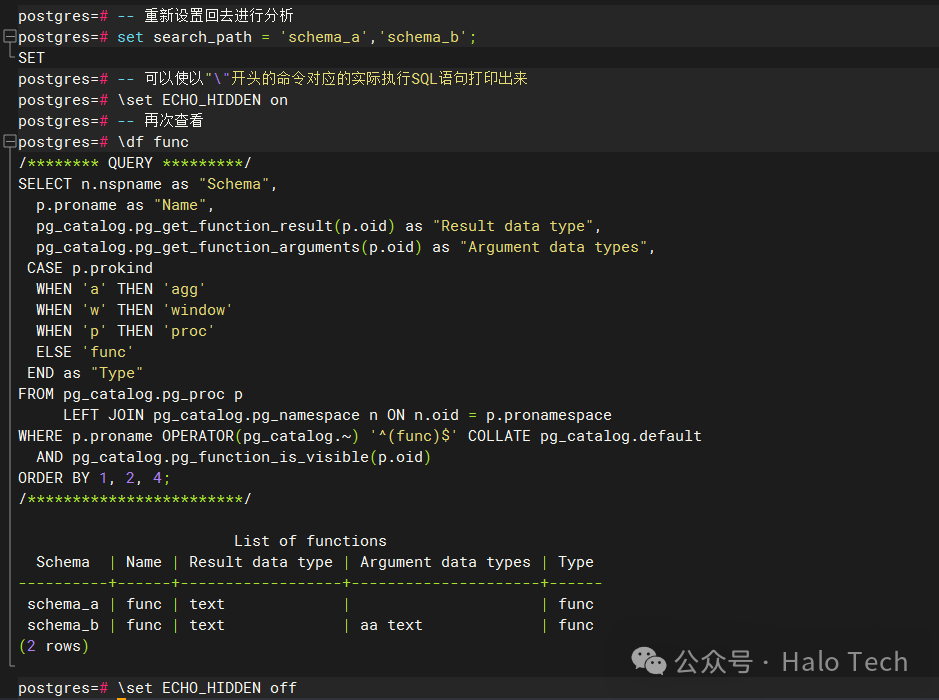
通过开启ECHO_HIDDEN,我们可以看到\df func实际执行的SQL语句,而在这段SQL语句中令人最为在意的一个点就在于pg_catalog.pg_function_is_visible这个函数,难道有个func函数被隐藏了,简单改写下这个实际运行SQL语句,将pg_function_is_visible从where条件去除,添加至查询列中
SELECT n.nspname as "Schema",
p.proname as "Name",
pg_catalog.pg_get_function_result(p.oid) as "Result data type",
pg_catalog.pg_get_function_arguments(p.oid) as "Argument data types",
CASE p.prokind
WHEN 'a' THEN 'agg'
WHEN 'w' THEN 'window'
WHEN 'p' THEN 'proc'
ELSE 'func'
END as "Type",
pg_catalog.pg_function_is_visible(p.oid) as "is_visible"
FROM pg_catalog.pg_proc p
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = p.pronamespace
WHERE p.proname OPERATOR(pg_catalog.~) '^(func)$' COLLATE pg_catalog.default
ORDER BY 1, 2, 4;
运行结果如下
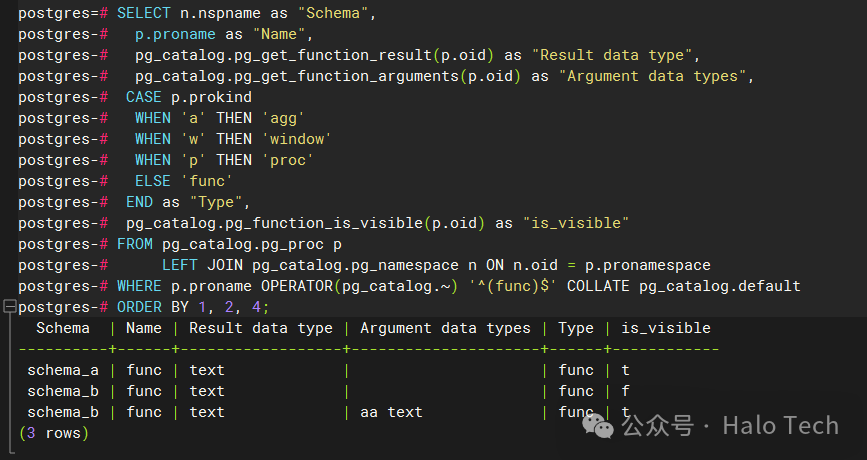
果不其然,schema_b.func()被隐藏了,为当前上下文不可见状态。都看到这了,干脆再翻一翻代码看看,这里面到底是怎么处理的。找到pg_function_is_visible对应的内部函数pg_function_is_visible
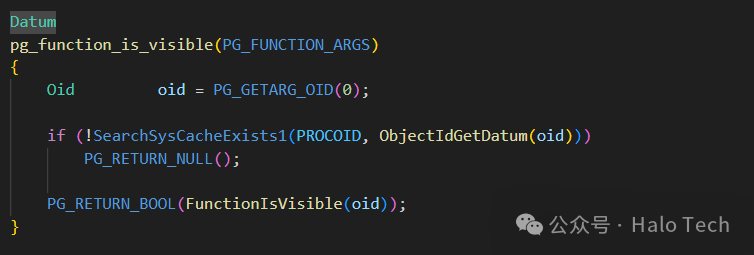
显而易见的,我们需要关注的是FunctionIsVisible函数,依旧是namespace.c文件
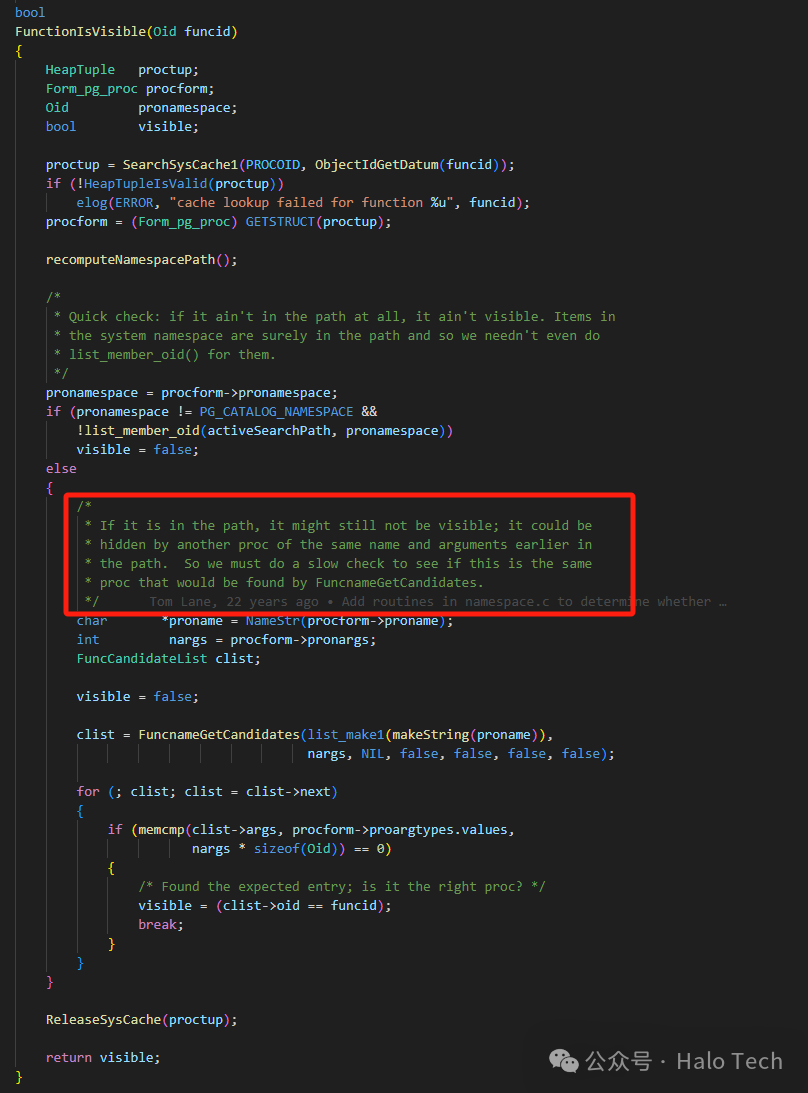
其实此处注释也说得很清楚了,就算是schema在search_path中,当函数名和参数完全一致时,会存在隐藏的情况,更加详细需要看FuncnameGetCandidates函数。而FuncnameGetCandidates关于此处的逻辑如注释所言(不想再将细节展开了已经太长了,第一次写有点缺经验),当前search_path中内容为schema_a,schema_b,而这两个schema中存在了一个一模一样(函数名和参数完全匹配)的func()对象,它内部会选择将schema_b.func()隐藏,再加上schema_b.func(aa text),最终呈现出两条记录。
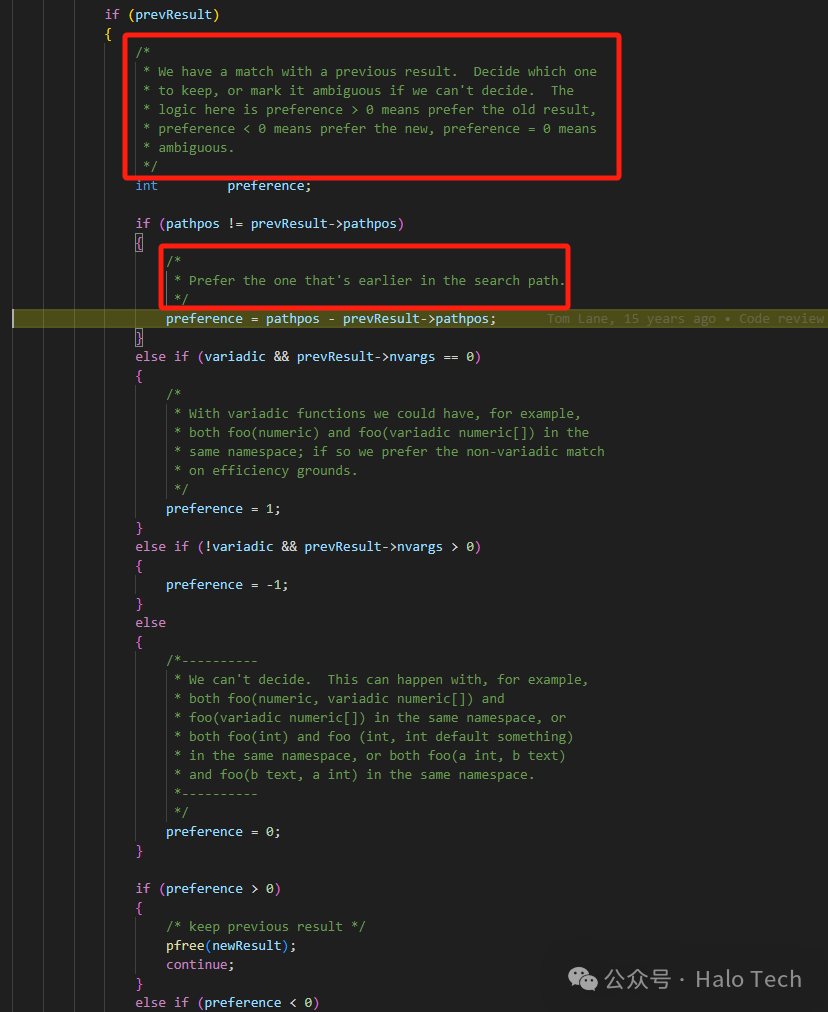
SELECT proname FROM pg_proc WHERE proname LIKE '%is_visible';
运行结果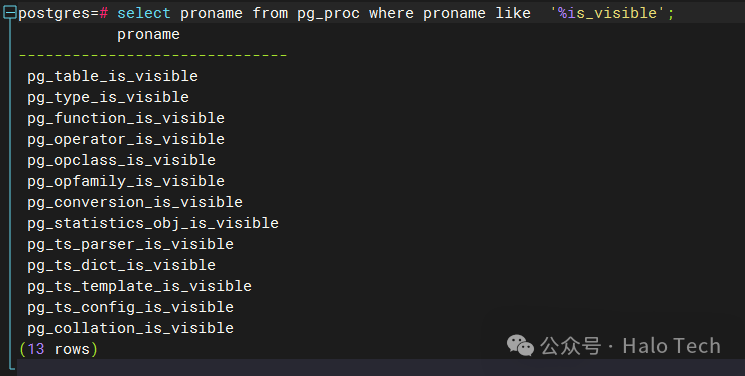
可以看到像表、类型等等这些个对象都会存在这种情况,由于在PostgreSQL中函数、存储过程这些存在多态的性质,所以实际上如果你去查看表对应的pg_table_is_visible这种函数其实理解起来更为简单,如下图:
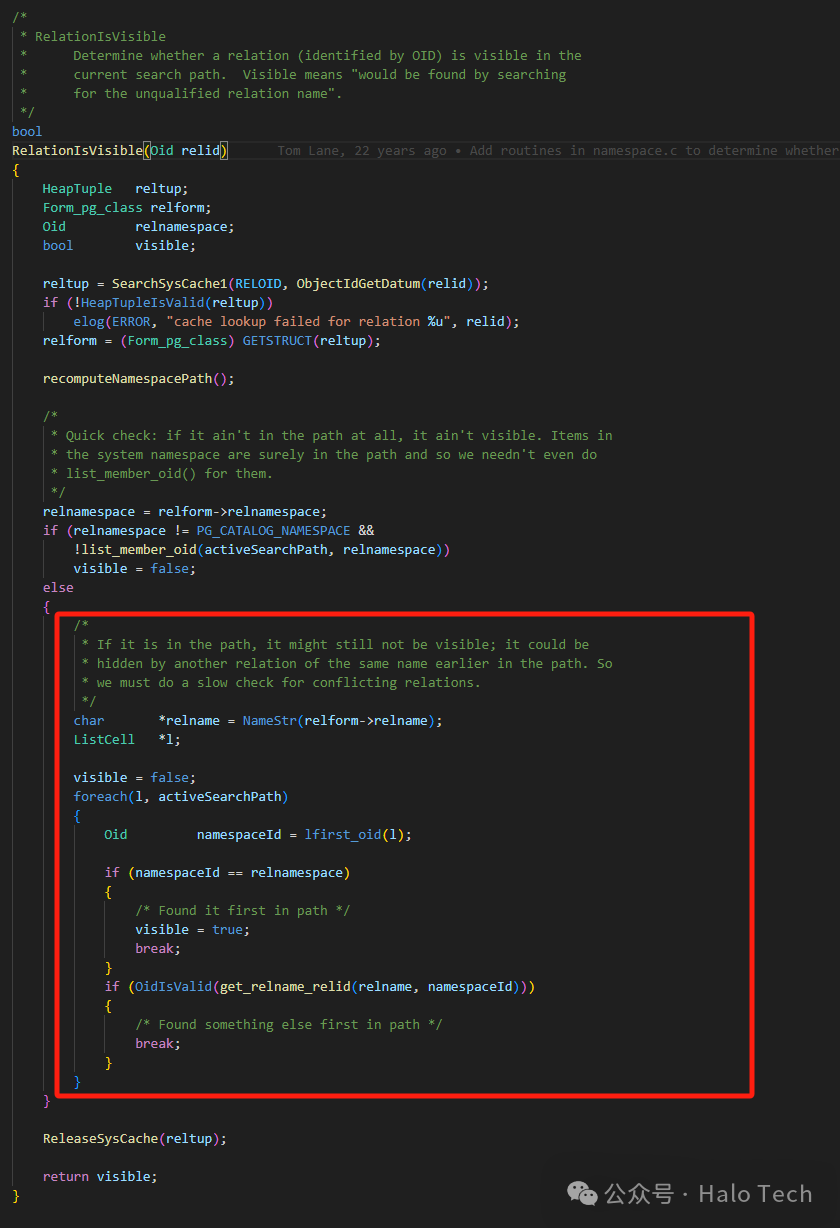
在PostgreSQL中,用户通过设置search_path ,来指定当前应该使用哪些schema,以及这些个schema的先后顺序。在创建的其他对象的时候,如果没有手动附加schema信息,那么将会按照search_path的规则(一般是第一个,$user这种存在额外的处理,如果不存在与当前用户同名的schema,则会选择下一个在路径中的schema),作为当前创建对象的模式。如果使用带有"\"的psql命令(如\df、\do、\dt等等,可以根据上述的is_visible相关函数推敲一下)去查找对象时,如果在search_path中的各个schema下有着能够完全匹配的对象,则有可能会隐藏部分数据,其实也就是数据库认为在当前search_path下,如果不附加schema信息,最优先的选择。
由于篇幅的原因诸多细节未完全展开,若文中存在错误或不当之处,敬请指出,以便我进行修正和完善。希望这篇文章能够帮助到你。此为PostgrSQL系列第一期,后续会陆续更新,同时后续可能还会新增PostgreSQL的plpgsql或ORACLE的PL/SQL的使用系列(新手向),敬请期待。
