




背景
同事中午时反馈一个环境速度很慢.
我通过grafana简单看了下应用的
jvm信息还有hikari都很正常.
没有大量FullGC,也没有很多失败的提示.
感觉很奇怪.
当时已经过了中午,想着下午再看.
1点时想起来, 应用没问题, 可能是数据库的异常.
才发现自己被一个地方给坑了.
问题现象
11点四十时同事反馈应用白屏.
grafana查看jvm的堆区,还有hikari,以及fullGC信息
发现并没有很明显的瓶颈.
查看node/sar 进行简单查看
发现并没有 虚拟机层面的瓶颈
因为已经接近中午, 就先吃饭了.
吃饭时想起来, 自己在半年前调整过数据库.
数据库在一个SSD的虚拟机上面.
转而上去查看. 发现机器压力上课
sar 发现有大量的iowait. 当时就懵逼了.
然后使用iotop查看,发现 神通的进程有 150MB/S的流量无比震惊.
问题分析
通过sar 和 iotop 很确认 是数据库的io存在问题.
但是虚拟机在SSD 上面并且 20k io.s 以及 300MB/s 的速度几乎是很强大的存在了.
此时联系了数据库的工程师. 怀疑是参数不正确.
自己记得安装时调整过但是一查才发现, 自己这次非常low
isql 输入密码
show data ;
然后发现
BUF_DATA_BUFFER_PAGES | 8192
需要注意, 神通数据库使用page 进行表示大小
8k个 8K大小的页面,合计就是 64MB的 buff区域
自己无比震惊 (默认值也太小了吧.)
自己发现自己一直在
/opt/ShenTong/admin/oscar.conf
进行修改.
但是工程师告诉我 这其实是 模板文件.
真正的文件是数据库实例名.conf 也就是
/opt/ShenTong/admin/OSRDB.conf
增加配置并且重启
XMLOPTION=1
BUF_DATA_BUFFER_PAGES=819200
SORT_MEM=409600
HOTSTANDBY_DATABASE_TYPE=0
ENABLE_HA_SINGLE_ALIVE=false
HA_SINGLE_ALIVE_KEEP_ELECTION_MS=180000
DATEFORMAT='YYYY-MM-DD HH24:MI:SS'
HA_ELECTION_TIMEOUT_MS=10000
HA_HEARTBEAT_PERIOD_MS=1000
HA_SLAVE_WRITE_BUFFER_BLOCK_NUM=655350
HA_SLAVE_QUERY_WAIT_TIMEOUT=0
BUF_GROUP_WRITE_SIZE=512
HA_GATEWAY=''
HA_SUB_MASK=''
HA_SERVER_IP_ADDRESS=''
HA_LOCAL_NET_DEV_NAME=''
ENABLE_GUID_GROUP=true
ONLY_FULL_GROUP_BY=false
NAME_CASE_SENSITIVE=true
ENABLE_SORT_WM_CONTACT=FALSE
FORCE_EXPAND_AEXPR_IN_NUM=100
MAX_OR_EXPR_USING_MULTI_INDEX=101
ENABLE_SCALARARRAYOPEXPR_TO_VALUES=true
ENABLE_EXPAND_AEXPR_IN=false
LOADBUFFERLEVEL=3
ENABLE_SQL_STAT=true
ENABLE_TIME_STAT=true
配置说明
将buffer区域修改为 6.4G
其他的都是一些正常处理的过程.
然后自己还关闭了测试环境的归档, 避免磁盘占用
alter database noarchivelog;
然后重启 脚本一般为:
/etc/init.d/oscardb_OSRDBd start
/etc/init.d/oscardb_OSRDBd stop
前后资源使用情况对照
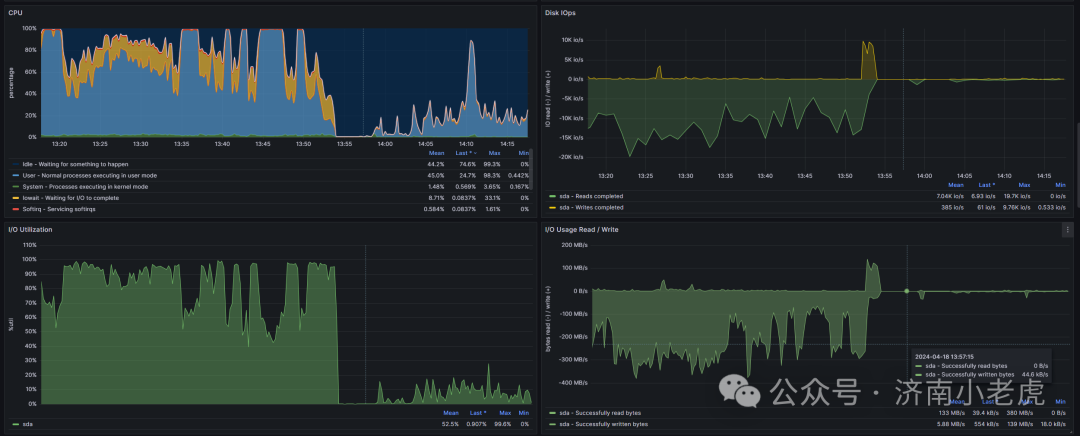
总结
一定注意配置文件的正确性
设置完后一定要通过命令号进行检查.
要时刻注意虚拟机的异常情况. 尤其是这个如此大IO的场景
虽然是大量的读没有写入. 但是依旧对系统有很大的损害
感谢原厂工程师的大力帮助.
情况对照页说明, 内存的配置对 CPU的使用情况有着非常巨大的影响
CPU 其实是最难进行调优的. 一般需要对内存 IO, 以及代码进行调整
来实现对CPU的无用消耗.
文章转载自济南小老虎,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
