





Scaling Large-Language-Model-based Multi-Agent Collaboration
论文摘要
提出了MACNET架构:设计了一个基于有向无环图(DAG)的拓扑结构,用于多智能体协作网络(MACNET)。在这个架构中,每条边由指导者管理,每个节点由执行助手支持,从而实现智能体之间的功能分工和协作。 优化了交互推理过程:通过拓扑排序来安排智能体的交互顺序,确保信息在网络中有序传递。每轮交互中,相邻的两个智能体会优化之前的解决方案,并将优化后的结果传递给下一个邻居,而不是传递整个对话,从而避免全局广播,减少上下文的冗长。 提高了系统的可扩展性:这种方法避免了冗长的上下文和全局广播,使得MACNET能够在几乎任何大规模网络中进行可扩展的协作。 实现了功能二分化:通过引入指导者和执行助手的角色,MACNET成功地在智能体之间引入了功能分工,并将静态拓扑与专门化的智能体无缝整合,提升了协作效率。
多Agent协作网络
网络构建
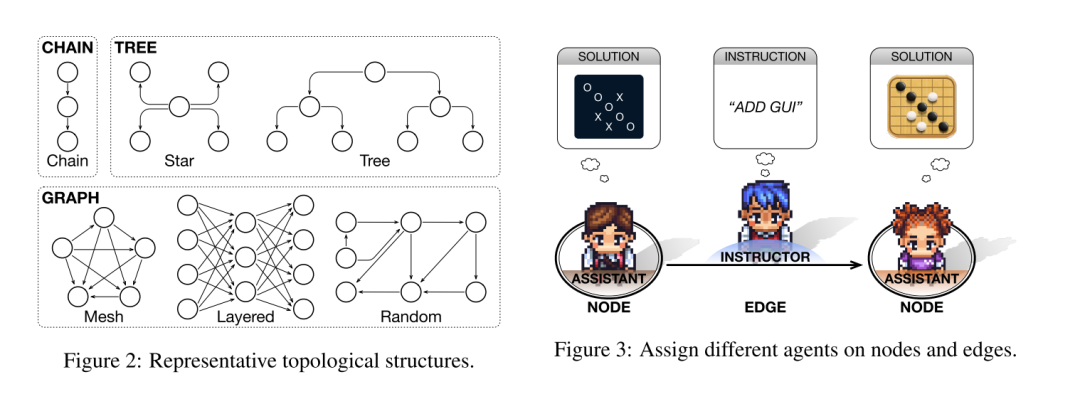
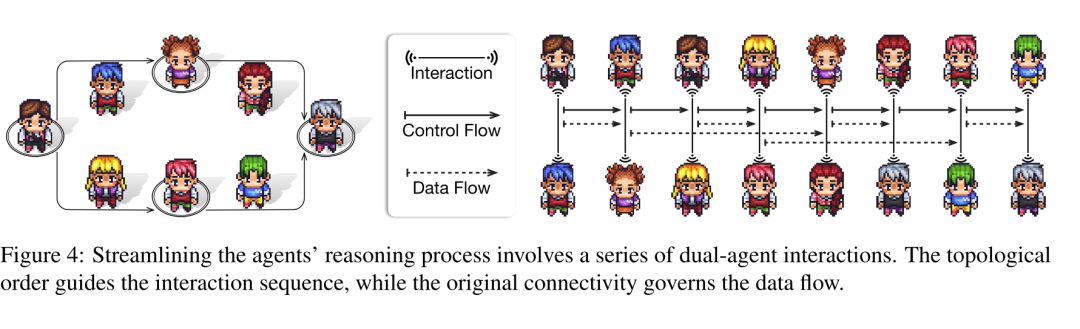
拓扑结构设计:网络被设计为一个有向无环图,用来组织智能体之间的交互。DAG由一组节点和一组边组成,其中节点代表智能体,边表示智能体之间的交互关系。由于DAG没有循环,信息可以在网络中顺畅地传递而不会发生死锁。 拓扑类型选择:文章重点研究了三种常见的拓扑类型-链状、树状和图状,每种类型又进一步细分为六种结构(如下图左侧): 链状拓扑:类似于瀑布模型,智能体之间的交互沿着线性结构进行。 树状拓扑:智能体可以向不同方向分支,形成独立的交互路径,分为“更宽”的星形结构和“更深”的树形结构。 图状拓扑:支持任意的交互依赖关系,节点可以有多个子节点和父节点,形成发散和收敛的交互,进一步分类为全连接网格结构、多层感知机(MLP)结构和不规则的随机结构。 功能二分化设计:在网络中,每条边分配一个指导者,负责发出指令;每个节点分配一个执行助手,负责提供定制化解决方案。指导者和执行助手的角色分工使得智能体能够专注于各自的功能,从而促进高效的信息传递和任务解决。例如下图右侧中,节点1代表一个不带GUI的结果,边代表添加GUI指令,由节点2生成带GUI的结果。 确保信息流的有序性:有向边的“指向性”使得智能体之间的交互能够被有效地协调,而“无环”配置则避免了信息传播中的死锁问题。
交互推理
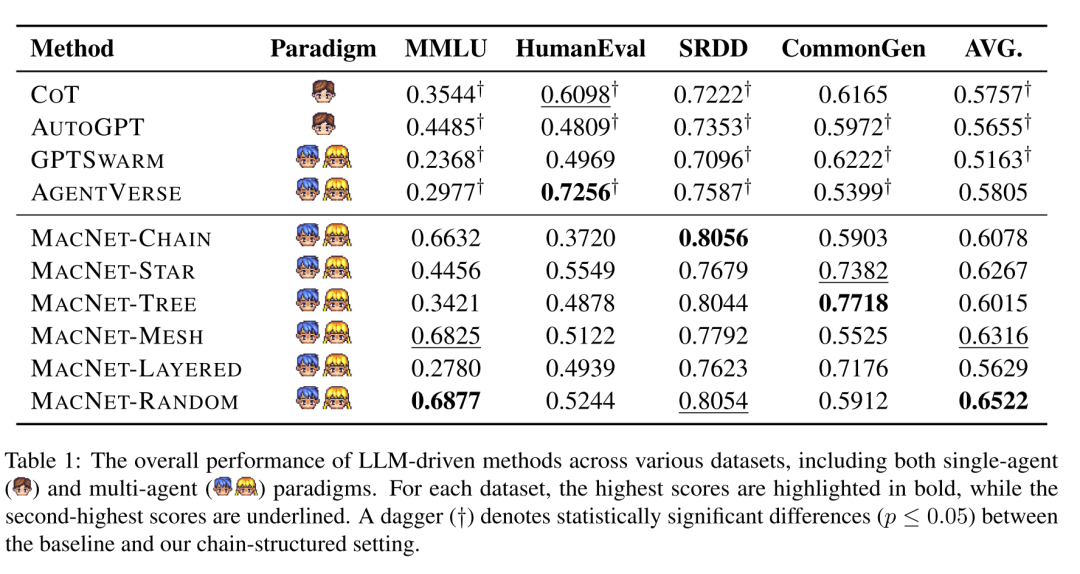
拓扑排序:在推理过程中,首先对图中的智能体进行拓扑排序。这种排序方法确保在访问某个节点(智能体)之前,必须先访问所有与之相关的依赖节点。这意味着智能体必须在与其相连的边上的智能体之前被访问,而 又必须在节点之前被访问。这样可以保证信息在网络中的传递是有序的。 交互顺序:在确定了全局的拓扑顺序后,每一对相邻的、由边连接的智能体开始进行交互。具体来说,每个图形结构中涉及的智能体总数为,需要进行轮交互。每一轮交互都是在相邻的智能体之间进行的。 多轮交互模式:在每条边上,智能体之间进行多轮指令响应的交互。具体交互模式为: 向提出请求,提供优化建议并请求进一步的改进。 接收到优化后的建议后,提供最终的解决方案。这个过程在每一条边上迭代进行,从而逐步优化解决方案。 控制流与数据流:拓扑排序不仅决定了交互的顺序,还明确了多智能体协作过程中的控制流。数据流则沿着图中的依赖关系传播,确保信息的传递与图形拓扑结构中的固有依赖关系一致。
内存控制
短期记忆: 功能:在每次双智能体交互过程中,短期记忆捕捉交互中的工作记忆,确保在每次交互中进行上下文感知的决策。 作用:帮助智能体在当前交互中保持对话的上下文,确保决策与当前信息相关。 长期记忆: 功能:长期记忆用于保持交互之间的上下文连续性,但只传递对话中的最终解决方案,而不是整个对话历史。 作用:通过只传递最终解决方案,而非所有对话历史,长期记忆确保了前序智能体的上下文保持马尔可夫性质,从而减少了上下文信息过载的风险。 上下文管理: 目的:通过将信息传播限制在相邻智能体之间,而非所有前序对话之间,上述记忆机制减小了上下文过载的风险,同时保持了上下文的连续性。 结果:这种方法使得多智能体系统能够在大规模网络中进行可扩展的协作,而不受到上下文长度的限制。
解决方案的优化与聚合
解决方案的传播和优化:原始解决方案在网络中传播时,通过各个智能体的连续优化,其质量会随着时间的推移不断提高。
分支与聚合:在网络的分支节点,解决方案通过并行传播进行扩展;在汇合节点,通过聚合机制来综合各个解决方案的优势,丢弃其劣势,从而产生更优质的聚合结果。这种非线性的决策机制确保了解决方案的质量提升。
实验
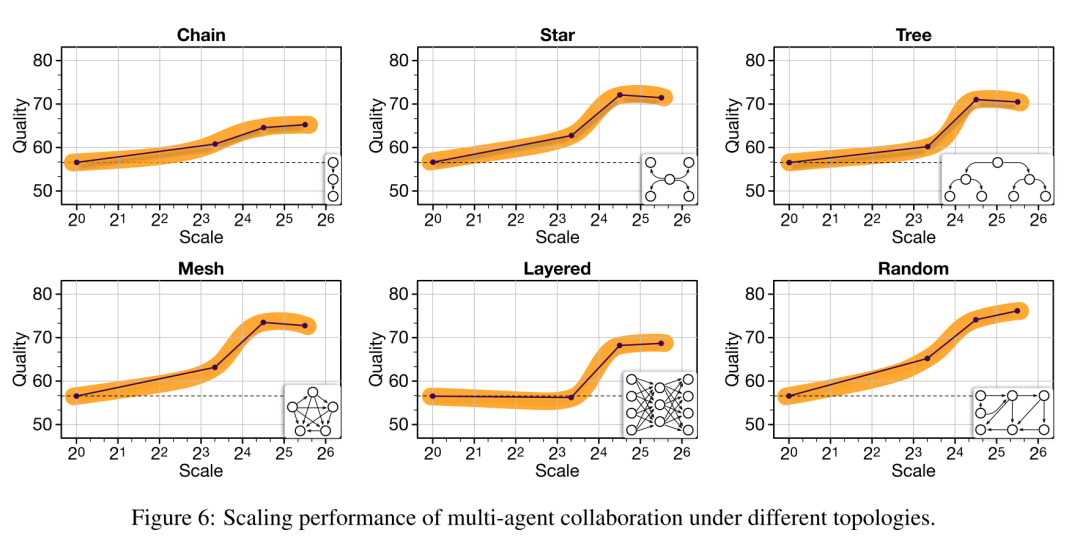
实验方法:通过从1个节点逐步增加到50个节点(对应到一个网格设置中的1275个智能体),对不同拓扑进行扩展。 结果与现象: 小世界协作现象:在高密度网络中达到了最佳结果。这表明,适当的网络密度可以优化智能体之间的协作效果。 反向退化现象:在某些配置下,随着规模的扩大,整体质量出现了2.27%到6.24%的下降。 性能趋势:随着拓扑规模的扩大,系统性能初期迅速上升,随后达到饱和点(或略有下降)。这种趋势可以用sigmoid函数进行近似:,其中、、 和 是参数,根据具体的拓扑配置而有所不同。 对比神经扩展定律: 神经扩展定律:神经扩展需要大规模的神经元增加(约在 到 之间)才能显现显著趋势。 协作扩展:在MACNET中,大多数拓扑在规模为24到25时就会出现性能饱和,较神经扩展显著更快。这是因为神经元协调需要从零开始训练以融入广泛的世界知识,而智能体协调依赖于预训练的语言模型,通过语言交互来理解和优化文本信息,通常不需要如此大的规模。 结合两种机制: 将神经扩展和智能体协作扩展机制结合,可能会产生更高质量的结果,因为它们在不同层次上实现了扩展和优化。
总结
编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。作为核心研发工程师参与向量数据库、RAG等产品的研发。代表公司参加DTCC、WAIM等会议进行主题分享。
文章转载自向量检索实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
