





前言
最开始学习数据库的时候都会被问到一个问题:“数据库系统相比与文件系统最大的优势是什么?”。具体的优势有很多,其中一个很重要的部分是:数据库系统能够进行更好的并发访问控制。
那么,数据库系统到底是怎么进行并发访问控制的?
本系列文章以 MySQL 8.0.35 代码为例,分为上、下两篇尝试对 MySQL 中的并发访问控制进行整体介绍。上篇文章主要介绍了表级别的并发访问控制,本篇为下篇,将重点介绍页级别、行级别的并发访问控制。
页级别的并发访问控制
B+tree的基本结构
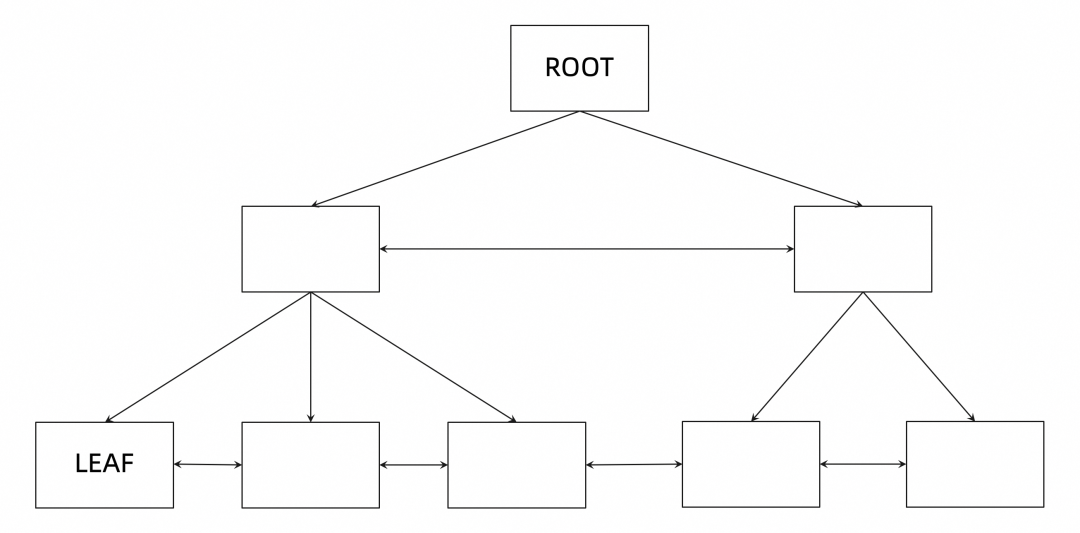
最上层的为根节点(ROOT),每个 B+tree 都只会有一个根节点; 最下层的为叶子节点(LEAF),叶子节点也是实际保存数据的节点; 中间层为非叶子节点(根节点也其实也是非叶子节点),保存索引数据,根据 B+tree 本身的大小,可能有 0 到多个中间层。
B+tree的加锁过程
页级别的并发访问控制主要通过 index 和 page 上的锁来实现,其实也就是 B+tree 的加锁过程。在介绍加锁过程前,先结合数据看一下 B+tree 的访问路径。
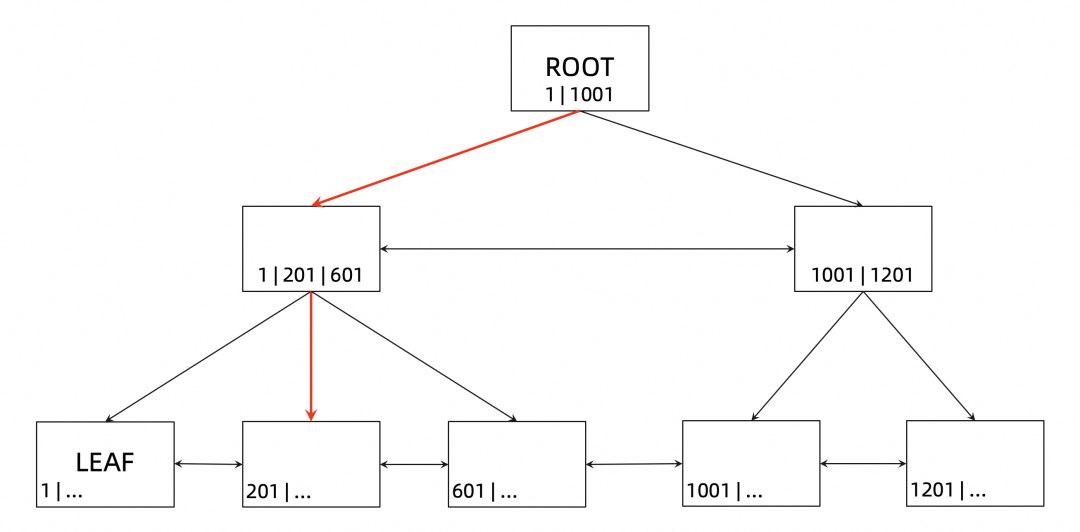
事实上,B+tree 的加锁过程其实也是按照上述访问路径进行的。还是以上述的查询为例,B+tree 上加锁的过程如下图所示:
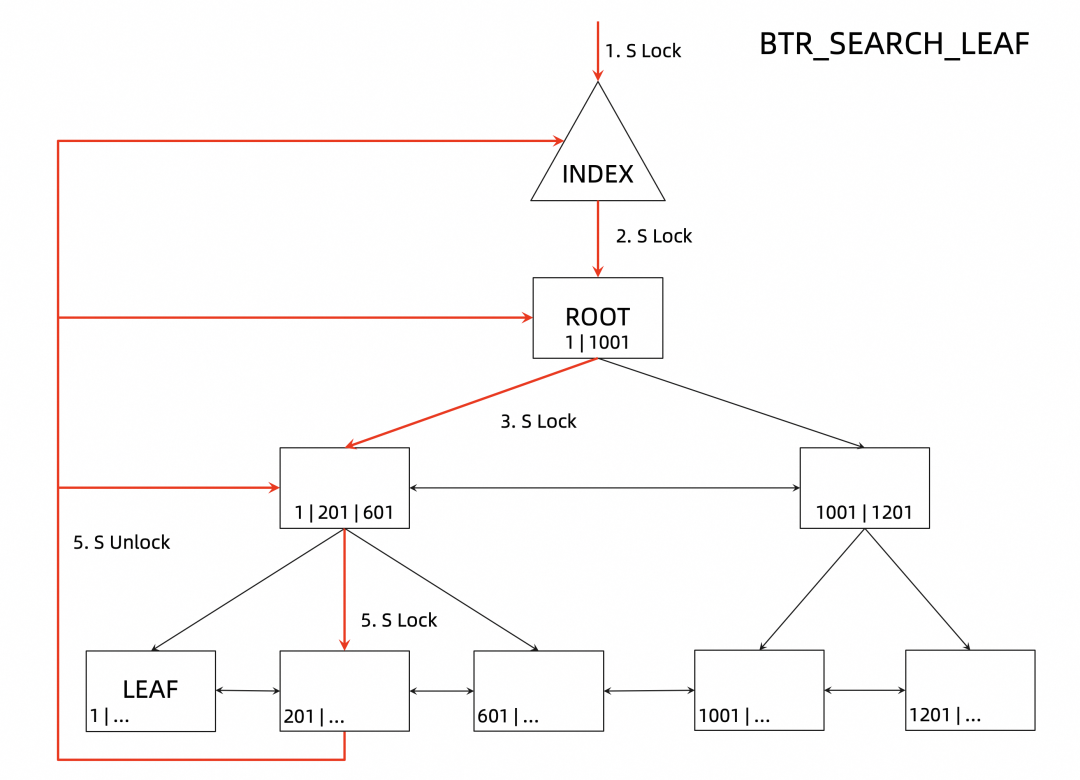
加 index 上的 S 锁;
加根节点上的 S 锁;
加非叶子节点上的 S 锁;
加叶子节点上的 S 锁;
释放 index 和所有非叶子节点上的 S 锁;
类似的,如果是页上的乐观更新(或者是页内的插入),那么 B+tree 上加锁的过程如下图所示:
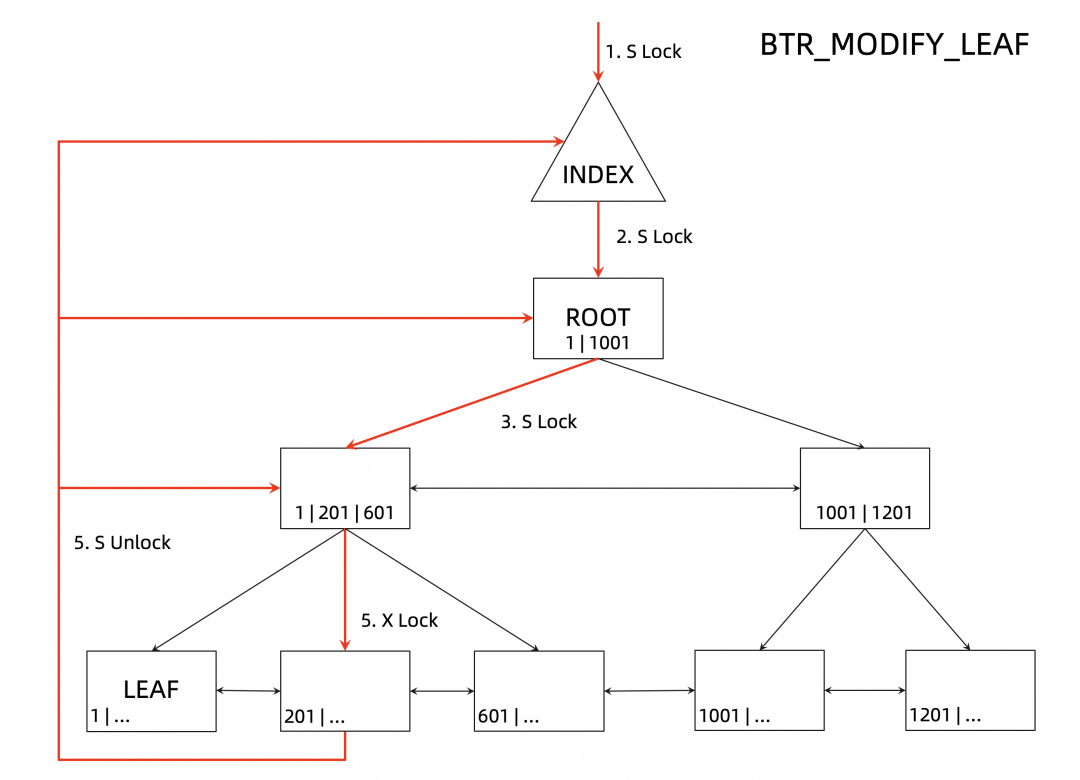
加 index 上的 S 锁;
加根节点上的 S 锁;
加非叶子节点上的 S 锁;
加叶子节点上的 X 锁;
释放 index 和所有非叶子节点上的 S 锁;
SMO问题
InnDB 在执行数据更新操作时,会首先尝试使用乐观更新(MODIFY LEAF),如果乐观更新失败,那么会进入到悲观更新(MODIFY TREE)的逻辑,悲观更新的加锁过程如下图所示:
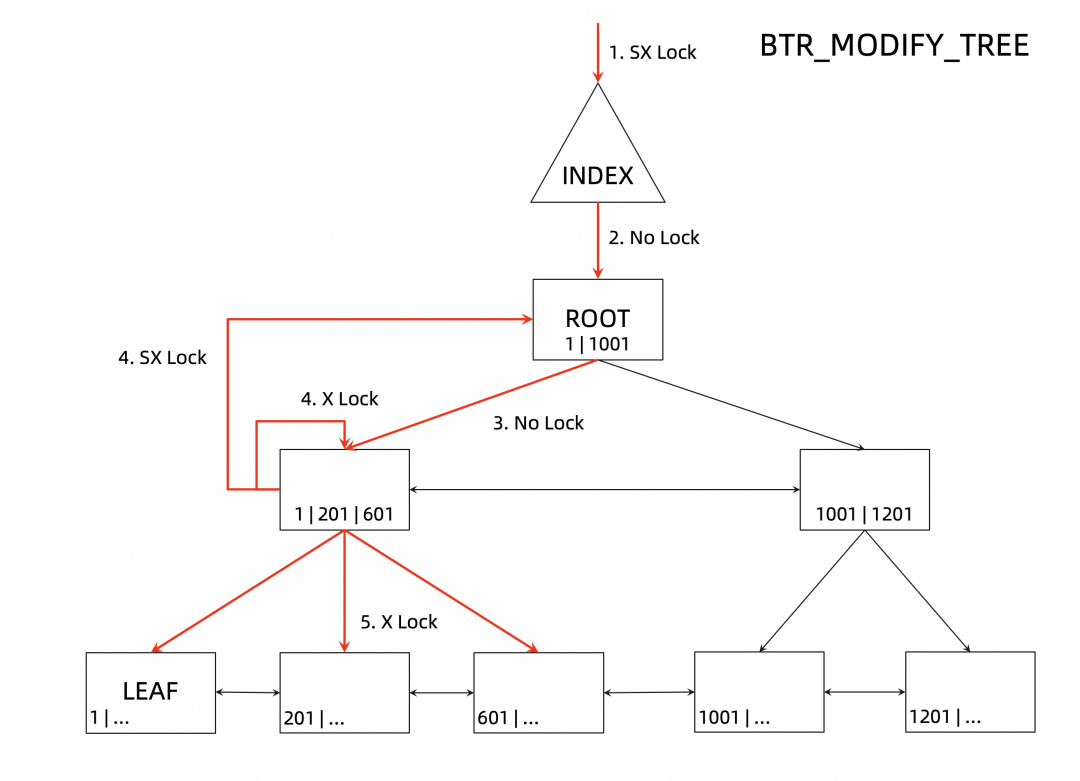
加 index 上的 SX 锁;
根节点不加锁
非叶子节点上不加锁,但是会搜索所有经过的节点;
判断可能修改的非叶子节点加 X 锁,根节点加 SX 锁;
叶子节点,包括前后叶子节点加 X 锁;
一个写入过程中的B+tree加锁过程
|--> row_ins_clust_index_entry| |--> row_ins_clust_index_entry_low(..., BTR_MODIFY_LEAF, ...) 乐观| | |--> pcur.open(index, ...)| | | |--> btr_cur_search_to_nth_level 遍历 b+tree| | | | |--> switch (latch_mode)| | | | |--> default| | | | |--> mtr_s_lock(dict_index_get_lock(index), ...) index 上加 S 锁| | | | |--> btr_cur_latch_for_root_leaf| | | | || | | | |--> search_loop| | | | |--> retry_page_get| | | | |--> buf_page_get_gen(..., rw_latch, ...)| | | | | |--> mtr_add_page 按类型对 page 加锁| || |--> row_ins_clust_index_entry_low(..., BTR_MODIFY_TREE, ...) 悲观| | |--> pcur.open(index, ...)| | | |--> btr_cur_search_to_nth_level 遍历 b+tree| | | | |--> switch (latch_mode)| | | | |--> BTR_MODIFY_TREE| | | | |--> mtr_sx_lock(dict_index_get_lock(index), ...) index 上加 SX 锁| | | | |--> btr_cur_latch_for_root_leaf| | | | || | | | |--> search_loop| | | | |--> retry_page_get| | | | |--> buf_page_get_gen(..., rw_latch, ...)| | | | | |--> mtr_add_page 按类型对 page 加锁
B+tree加锁过程总结
页级别的并发访问控制发生在 B+tree 的遍历过程,也就是 B+tree 的加锁过程; 加锁的对象包括了 index 和 page; 加锁的类型包括了 S,SX 和 X,其中 S 锁和 SX 锁不互斥; 查询过程只加 S 锁; 修改过程,根据修改的类型加锁过程有所区别。如果是页内的数据修改,走乐观更新的逻辑,只有被修改的叶子节点加 X 锁;如果是悲观更新的逻辑,index 和根节点要加 SX 锁,索引可能被修改的节点都要加 X 锁。
行级别的并发访问控制
一个有趣的死锁问题
在介绍行级别的并发访问控制前,先一起看一个有意思的问题:
CREATE TABLE `t1` (`id` int NOT NULL,`c1` int DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;INSERT INTO t1 VALUES (1, 10);INSERT INTO t1 VALUES (2, 20);INSERT INTO t1 VALUES (3, 30);
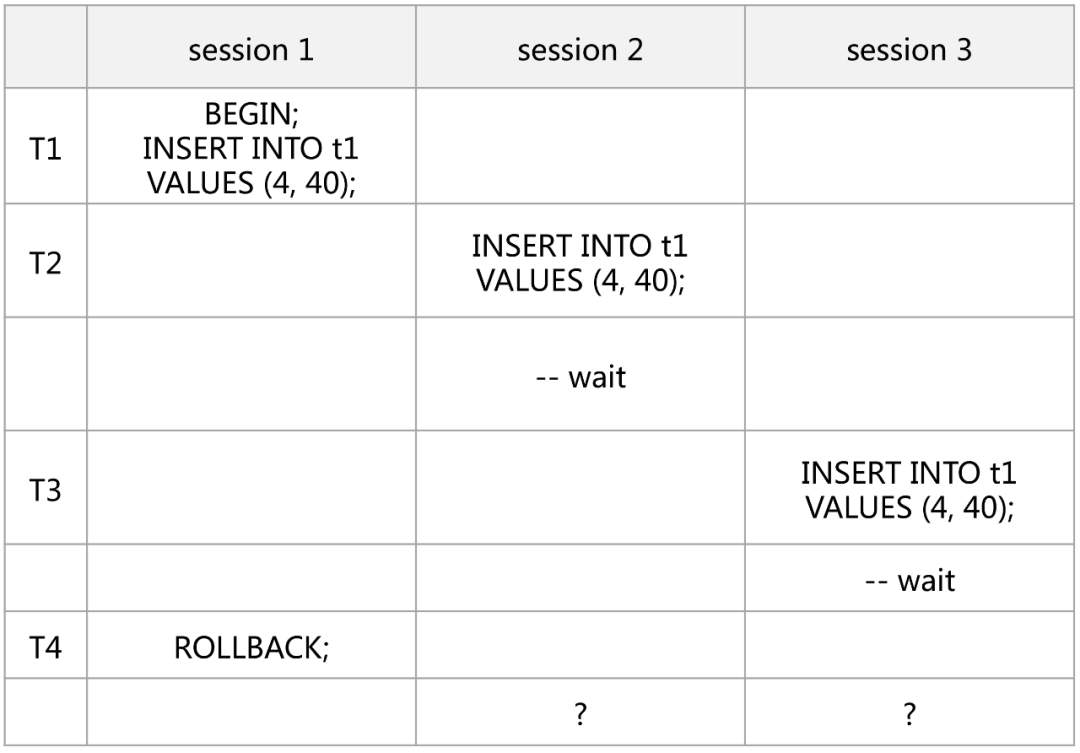
[session 2] 执行结果:
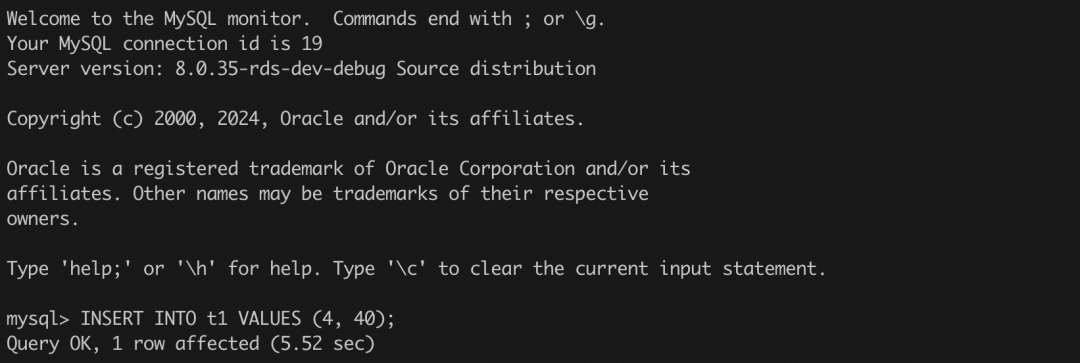
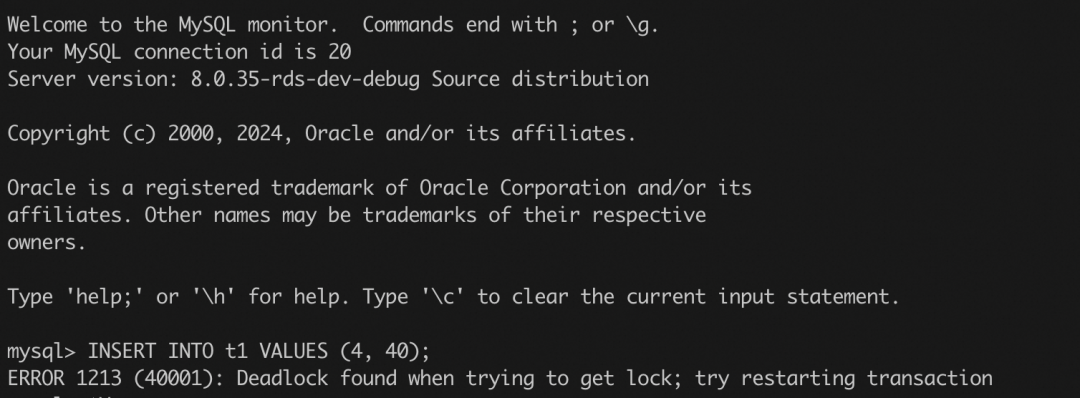
为了搞清楚这个问题,笔者关闭 MySQL 上的死锁检查逻辑(innodb_deadlock_detect设置为 OFF),然后再次尝试了上述的操作。结果发现,session 2 和 session 3 确实卡住了,结果前面提到的 performance_schema 下的 data_locks 表进行查看:

通过 data_locks 表中的锁等待关系发现,session 2(THREAD_ID = 69)和 session 3(THREAD_ID = 70)都在等待意向锁,隐含的语义是都持有了 Gap 锁,所以造成了死锁。
所以,通过上面的例子可以知道,即使是 RC 隔离级别下简单的主键插入,也并不只是对单行记录加锁,并且还可能造成死锁。
行锁的基本概念
1. 记录锁(Rec Lock),即对单行记录上加的锁,官方代码中的名字是 LOCK_REC_NOT_GAP;从加锁类型上来说,记录锁优又可以分为记录读锁(S 锁)和记录写锁(X)锁;
2. 间隙锁(Gap Lock),对行记录的间隙加的锁,官方代码中的名字是 LOCK_GAP;(补充一句,网上有很多文章都说 Gap 锁是为了解决 RR (REPEATABLE-READ,可重复读)隔离级别写的幻读问题,其实并不完全是,前面的插入死锁的例子也能说明。关于事务隔离级别的问题,不是本文讨论的重点,这里不再展开。)
3. 下键锁(Next-Key Lock),可以简单的理解就是记录锁和间隙锁的组合(记录前的间隙),官方代码中的名字是 LOCK_ORDINARY;
一个写入过程中的加锁过程
在进入案例分析前,还是以一个写入过程为例,结合代码进行一个主要逻辑的说明,主要的代码堆栈如下:
|--> ha_innobase::write_row| |--> row_insert_for_mysql| | |--> row_insert_for_mysql_using_ins_graph| | | |--> // run_again| | | |--> row_ins_step| | | | |--> row_ins| | | | | |--> row_ins_index_entry_step| | | | | | |--> row_ins_index_entry| | | | | | | |--> row_ins_clust_index_entry // 插入主键| | | | | | | | |--> row_ins_clust_index_entry_low| | | | | | | || | | | | | | |--> row_ins_sec_index_entry // 插入二级索引| | | || | | |--> row_mysql_handle_errors| | | | |--> lock_wait_suspend_thread // 锁等待,唤醒后进入 run_again|--> row_ins_clust_index_entry_low| |--> btr_pcur_t::open // 遍历 b+tree| || |--> row_ins_duplicate_error_in_clust // 第一次插入不会进入(隐式锁)| | |--> row_ins_set_rec_lock| | | |--> lock_clust_rec_read_check_and_lock| | | | |--> lock_rec_convert_impl_to_expl // 隐式锁转显式锁| | | | | |--> lock_rec_convert_impl_to_expl_for_trx| | | | | | |--> lock_rec_add_to_queue| | | | | | | |--> rec_lock.create // RecLock::create| | | | | | | | |--> lock_alloc| | | | | | | | |--> lock_add| | | | | | | | | |--> // 不等待| | | | | | | | | |--> lock_rec_insert_to_granted| | | | | | | | | |--> locksys::add_to_trx_locks| | | | |--> lock_rec_lock // 构造锁等待| | | | | |--> lock_rec_lock_fast| | | | | | |--> rec_lock.create // RecLock::create| | | | | |--> lock_rec_lock_slow| | | | | | |--> lock_rec_has_expl| | | | | | |--> lock_rec_other_has_conflicting // 检查冲突| | | | | | |--> rec_lock.add_to_waitq| | | | | | | |--> create // RecLock::create| | | | | | | | |--> lock_alloc| | | | | | | | |--> lock_add| | | | | | | | | |--> // 等待| | | | | | | | | |--> lock_rec_insert_to_waiting| | | | | | | | | |--> locksys::add_to_trx_locks| | | | | | | | | |--> lock_set_lock_and_trx_wait| || |--> btr_cur_optimistic_insert // 乐观插入| | |--> btr_cur_ins_lock_and_undo| | | |--> lock_rec_insert_check_and_lock // 插入前的锁冲突检查| | | | |--> lock_rec_other_has_conflicting| | | | |--> rec_lock.add_to_waitq| | | |--> trx_undo_report_row_operation| |--> btr_cur_pessimistic_insert // 悲观插入
从上述代码来看,最开始的例子中的插入过程应该是这样的:
2、session 2 进行插入时,在 row_ins_duplicate_error_in_clust函数中进行冲突检查时:
发现记录已经存在,并且对应的事务是一个活跃事务,这个时候会触发隐式锁转显示锁的逻辑,简单来说就是 session 2 为 session 1(准确的说是 trx 1)创建一个 Rec X Lock,因为这个时候还不存在任何等到关系,所以可以直接获取到锁; 继续为自己创建一个 Rec S Lock,由于和前面的 Rec X Lock 冲突,所以会加入到等待队列,跳过后续的插入操作,最后进入到lock_wait_suspend_thread函数中进行等待;

session 1 在回滚的时候,并不是简单的释放 Rec X Lock,然后唤醒 session 2 和 session 3; session 1 的回滚逻辑里面有一个非常重要的步骤lock_rec_inherit_to_gap,该函数会把 session 2 和 session 3 上的 Rec Lock 转换为 Gap Lock; session 2 和 session 3 被唤醒后,不论是哪个线程先进入到插入逻辑,都会在插入前的锁冲突检查中(lock_rec_insert_check_and_lock)发现对方的 Gap 锁,然后生成插入意向锁。
典型死锁问题
DROP TABLE IF EXISTS `t1`;CREATE TABLE `t1` (`id` int NOT NULL AUTO_INCREMENT,`a` int DEFAULT NULL,`b` int DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `uk_a` (`a`)) ENGINE=InnoDB;INSERT INTO t1 values (1, 10, 0);INSERT INTO t1 values (2, 20, 0);INSERT INTO t1 values (3, 30, 0);INSERT INTO t1 values (4, 40, 0);INSERT INTO t1 values (5, 50, 0);
注:需关闭 MySQL 上的死锁检查逻辑(innodb_deadlock_detect设置为 OFF)。


场景 2


注意:这里其实有一个很有意思的问题,为什么 UK 上的更新需要加两个下键锁,感兴趣的同学可以参考文章。
场景 3

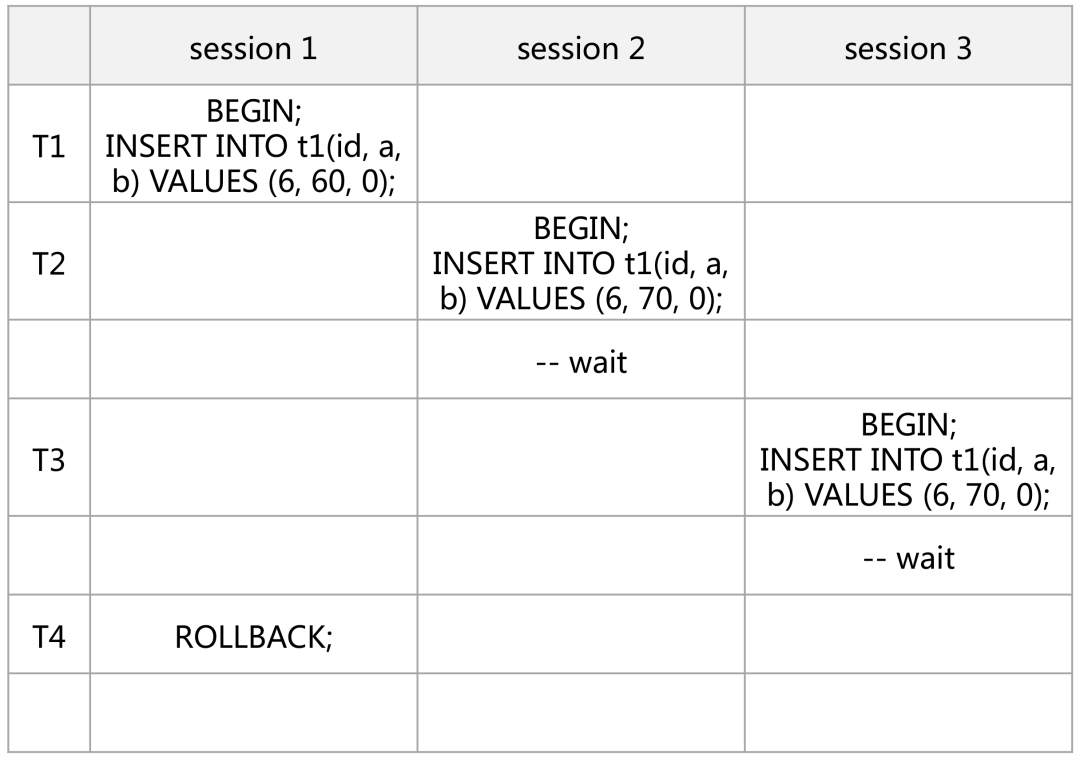
死锁问题的排查
MySQL 8.0 默认开启了死锁检测(innodb_deadlock_detect),原则上不建议手动关闭;此外 innodb_lock_wait_timeout 参数也不建议设置过大;
当出现死锁时,如果开启了 performance_schema,可以通过查询 performance_schema 下的 data_locks 表查看所等待关系,然后手动进行处理;和 MDL 锁等到处理的逻辑类似,如果实在不想分析锁等待的关系,可以把 data_locks 表中所有涉及的连接全部 kill;
如有真的出现了死锁,在 MySQL 的错误日志中会打印出锁等待关系,可以通过锁等待关系进行分析,优化业务侧的写入逻辑。
行级别的加锁过程总结
行锁并不只是行记录上的锁,行锁的类型包括了:记录锁(Rec Lock)、间隙锁(Gap Lock)、下键锁(Next-Key Lock)和插入意向锁(Insert Intention Lock);
行锁是按需创建的,如果是第一次插入,默认不加锁(隐式锁),只有出现冲突时才会升级为显式锁;
记录锁(Rec Lock)上只有 S 锁和 S 锁兼容;
间隙锁(Gap Lock)上 S 锁和 X 锁可以兼容,X 锁和 X 锁也可以兼容;
下键锁(Next-Key Lock)就是记录锁和间隙锁的组合,处理的时候也是分开的;
插入意向锁(Insert Intention Lock)的产生一定是因为有其他事务持有个待插入间隙的间隙锁;
所有锁的释放都是在事务提交时,所以为了减少死锁的产生,建议事务尽快提交。
总结
表、页、行其实就是 MySQL 数据处理的基本流程; 表上的并发控制,或者说表锁主要保护的是表结构,在 MySQL 8.0 版本中,表结构的保护都是由 MDL 锁完成;非 InnDB 表(CSV 表)还会依赖 Server 层的表锁进行并发控制,InnoDB 表不需要 Server 层加表锁; 页上的并发控制,或者说 index 和 page 上的锁主要是为了保护 B+tree 的安全性,乐观写入下,只有叶子节点上需要加 X 锁;悲观写入下(SMO),索引可能修改的节点上都需要加 X 锁。引入 SX 锁增加了读写并发,但是 SMO 操作依然不能并发; 行上的并发控制,或者说行锁主要是为了保护行记录的一致性,其实行上的并发控制还有一个很重要的点是 MVCC,本文没有对这部分内容进行展开,感兴趣的同学可以自行学习。
作者有话说
在写这篇文章之前,关于 MySQL 内部各种锁的介绍文章已经很多了,其实只要是稍微了解数据库、了解 MySQL 的同学,都会有自己对于各种锁的认知。
至于为什么要写这篇文章,一是觉得网上很多文章都太偏重于概念,一上来就是共享锁与互斥锁、乐观锁与悲观锁、显式锁与隐式锁,要不就是一个表格告诉你各种锁的互斥与兼容关系,而没有结合实际的例子来说明为什么要这么加锁,一看一个不吱声;
二是最近刚好碰到了几个线上问题,所以趁此机会把之前分散整理的一些文档统一梳理了一遍,更多的还是自己的理解,如果文章中有描述错误的地方,欢迎批评指正。
想了下,标题叫做《MySQL中的锁分析》好像不是很合适,所以叫做《MySQL如何实现并发控制》。当然,MySQL 中的并发控制远不止这些,有机会的话将继续补充。
福利TIME:云栖来啦,赢取VIP优享票
2024云栖大会将于9月19日-21日在杭州举办。
🎁 为感谢小伙伴们对瑶池数据库的支持,我们将抽取10张云栖大会VIP优享票,点击下方小程序即可参与抽奖~快来试试你的手气吧👋




点击了解 云数据库RDS MySQL

