




在本指南中,我们将深入探讨构建强大的数据管道,用 Kafka 进行数据流处理、Spark 进行处理、Airflow 进行编排、Docker 进行容器化、S3 进行存储,Python 作为主要脚本语言。
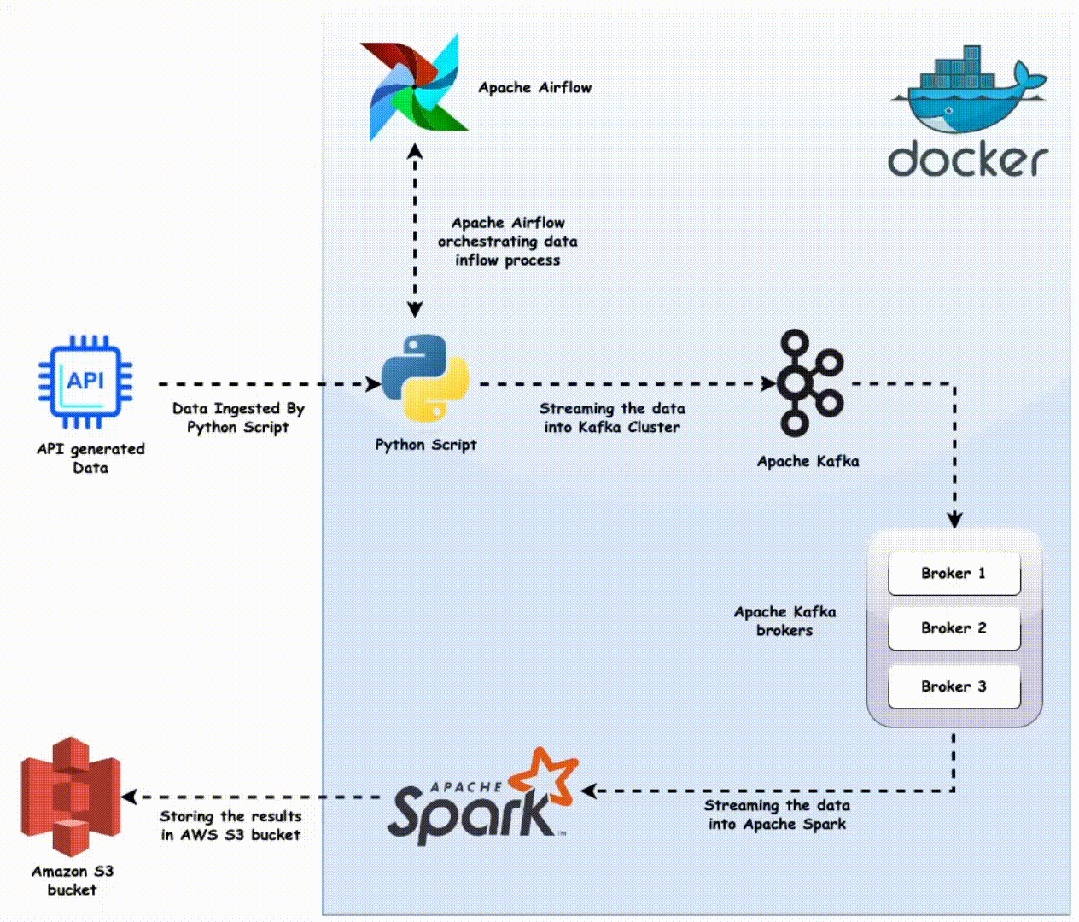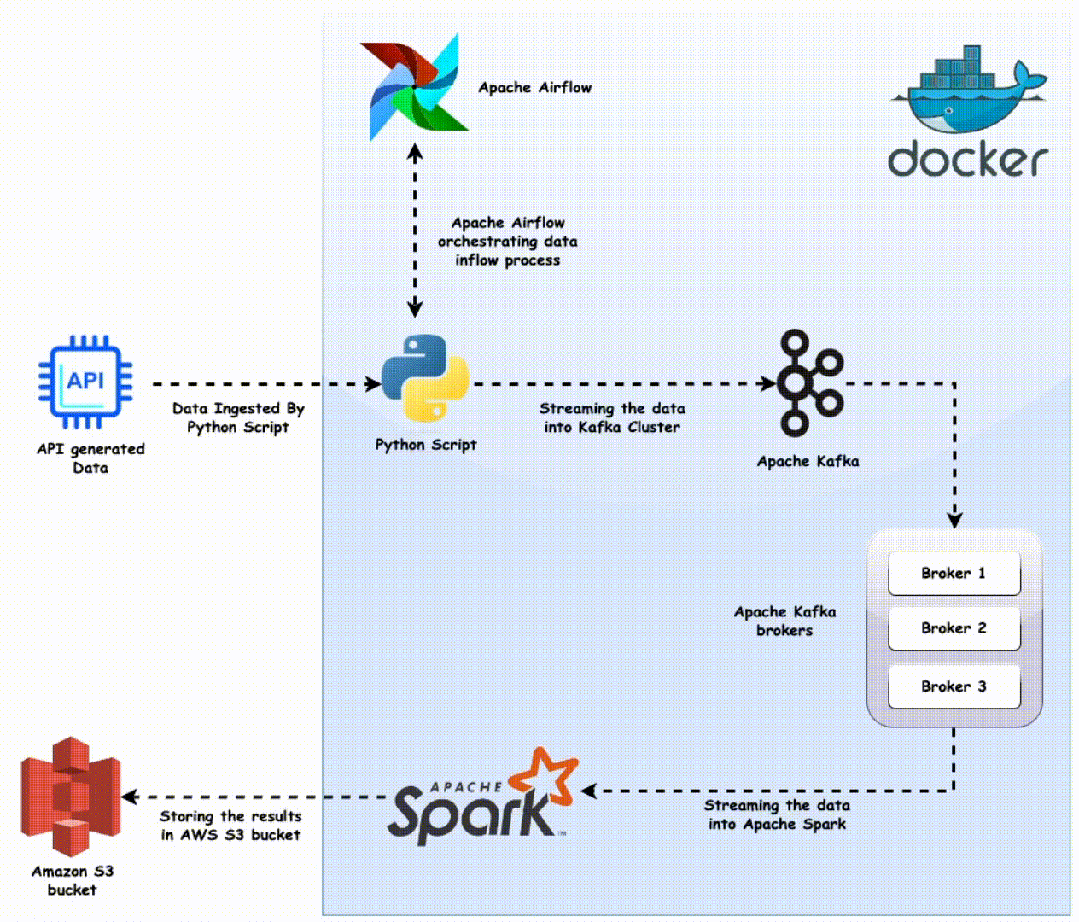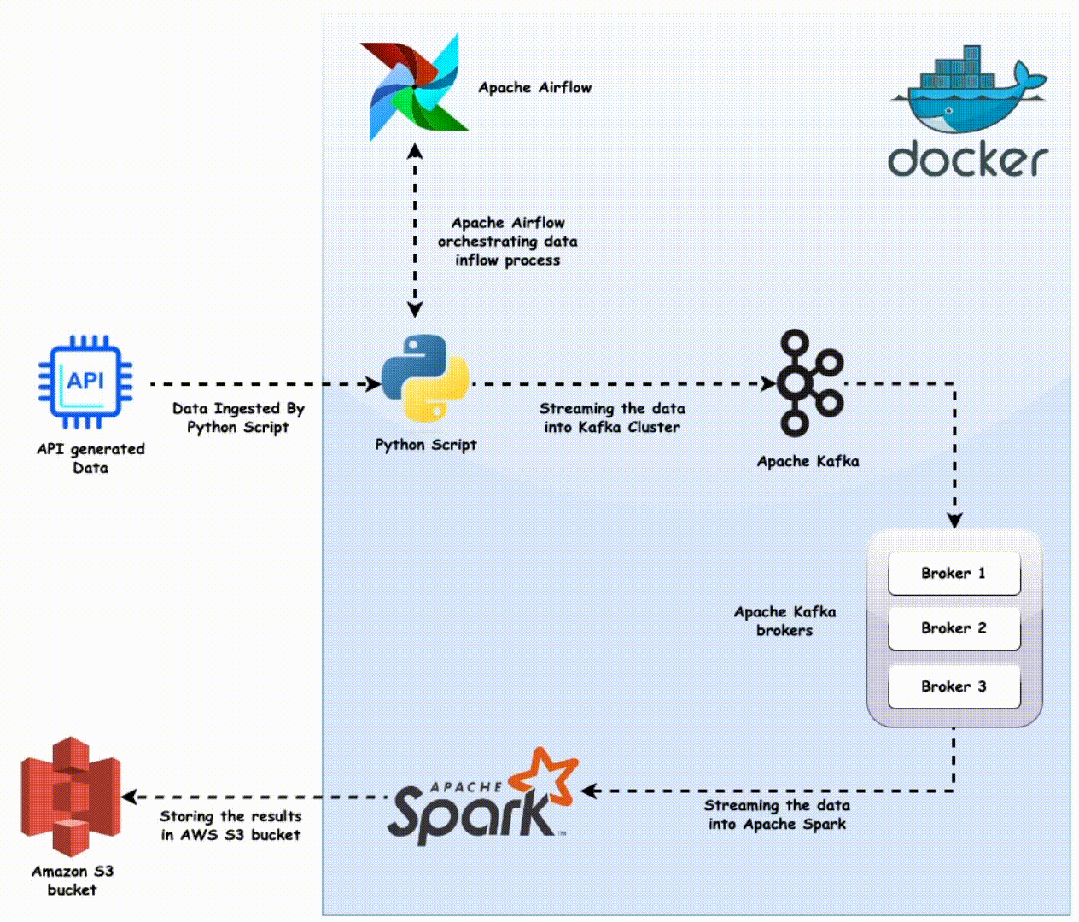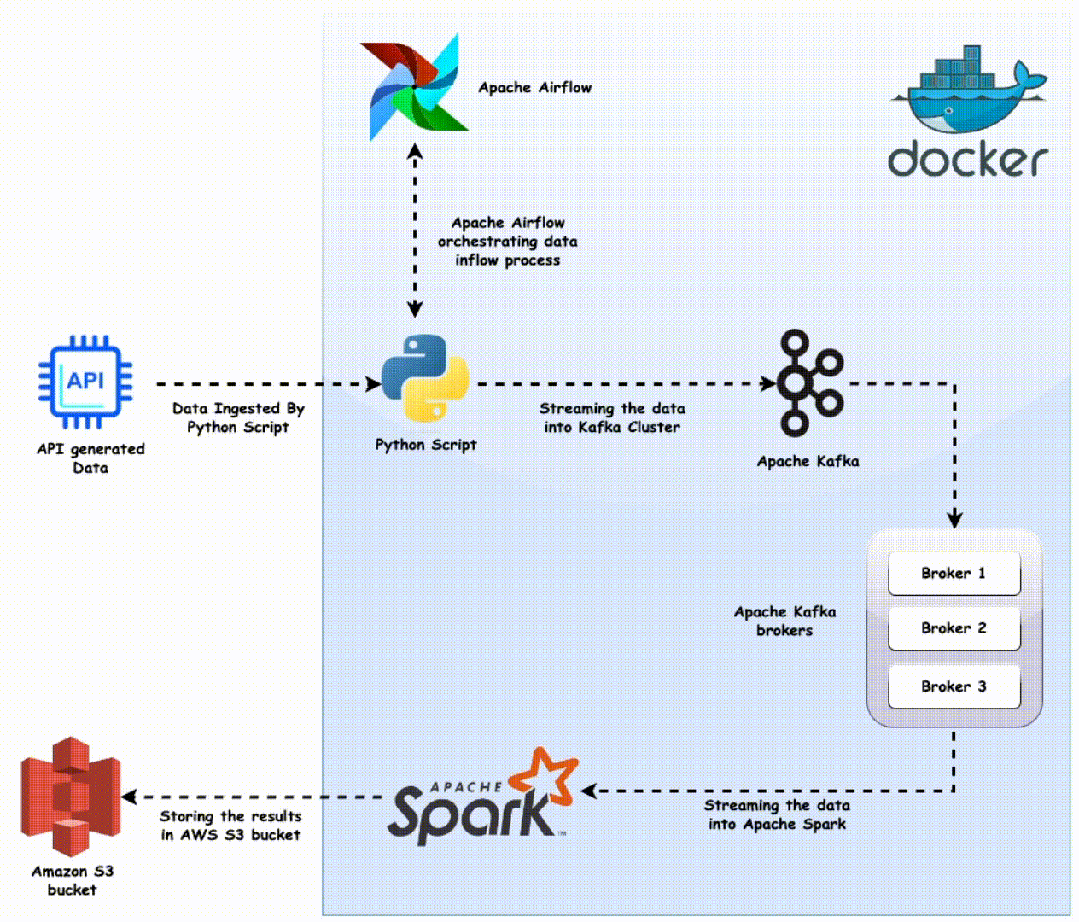
项目的一个重要方面是其模块化架构。得益于 Docker 容器,每个服务,无论是 Kafka、Spark 还是 Airflow,都在隔离的环境中运行。不仅确保了平滑的互操作性,还简化了可扩展性和调试。
入门:先决条件和设置
对于这个项目,我们利用GitHub存储库来托管我们的整个设置,使任何人都可以轻松开始。
A、Docker:Docker 将成为我们编排和运行各种服务的主要工具。
安装:访问 Docker 官方网站,下载并安装适合您操作系统的 Docker Desktop。
验证:打开终端或命令提示符并执行 docker --version 以确保安装成功。
B、S3:AWS S3 是我们数据存储的首选。
设置:登录 AWS 管理控制台,导航到 S3 服务,然后建立一个新存储桶,确保根据您的数据存储首选项对其进行配置。
C、设置项目:
克隆存储库:首先,您需要使用以下命令从 GitHub 存储库克隆项目:
git clone <https://github.com/simardeep1792/Data-Engineering-Streaming-Project.git>
导航到项目目录:
cd Data-Engineering-Streaming-Project
使用以下方式部署服务
docker-compose
:在项目目录中,您将找到一个
docker-compose.yml
文件。该文件描述了所有服务。docker network create docker_streamingdocker-compose -f docker-compose.yml up -d该命令协调 Docker 容器中所有必要服务的启动,例如 Kafka、Spark、Airflow 等。
分解项目文件
1、docker-compose.yml
version: '3.7'services:# Airflow PostgreSQL Databaseairflow_db:image: postgres:16.0environment:- POSTGRES_USER=${POSTGRES_USER}- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}- POSTGRES_DB=${POSTGRES_DB}logging:options:max-size: 10mmax-file: "3"# Apache Airflow Webserverairflow_webserver:command: bash -c "airflow db init && airflow webserver && airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin"image: apache/airflow:latestrestart: alwaysdepends_on:- airflow_dbenvironment:- LOAD_EX=${LOAD_EX}- EXECUTOR=${EXECUTOR}- AIRFLOW__CORE__SQL_ALCHEMY_CONN=postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@airflow_db:5432/${POSTGRES_DB}logging:options:max-size: 10mmax-file: "3"volumes:- ./dags:/opt/airflow/dags- ./requirements.txt:/opt/airflow/requirements.txtports:- "8080:8080"healthcheck:test: ["CMD-SHELL", "[ -f usr/local/airflow/airflow-webserver.pid ]"]interval: 30stimeout: 30sretries: 3# Zookeeper for Kafkakafka_zookeeper:image: confluentinc/cp-zookeeper:latestports:- "2181:2181"environment:- ZOOKEEPER_CLIENT_PORT=${ZOOKEEPER_CLIENT_PORT}- ZOOKEEPER_SERVER_ID=${ZOOKEEPER_SERVER_ID}- ZOOKEEPER_SERVERS=kafka_zookeeper:2888:3888networks:- kafka_network- default# Kafka Broker Instanceskafka_broker_1:extends:service: kafka_baseenvironment:- KAFKA_BROKER_ID=1- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_1:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://host.docker.internal:29092kafka_broker_2:extends:service: kafka_baseenvironment:- KAFKA_BROKER_ID=2- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_2:19093,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093,DOCKER://host.docker.internal:29093kafka_broker_3:extends:service: kafka_baseenvironment:- KAFKA_BROKER_ID=3- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_3:19094,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094,DOCKER://host.docker.internal:29094kafka_base:image: confluentinc/cp-kafka:latestenvironment:- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=${KAFKA_LISTENER_SECURITY_PROTOCOL_MAP}- KAFKA_INTER_BROKER_LISTENER_NAME=${KAFKA_INTER_BROKER_LISTENER_NAME}- KAFKA_ZOOKEEPER_CONNECT=kafka_zookeeper:2181- KAFKA_LOG4J_LOGGERS=${KAFKA_LOG4J_LOGGERS}- KAFKA_AUTHORIZER_CLASS_NAME=${KAFKA_AUTHORIZER_CLASS_NAME}- KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND=${KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND}networks:- kafka_network- default# Kafka Connectkafka_connect:image: confluentinc/cp-kafka-connect:latestports:- "8083:8083"environment:- CONNECT_BOOTSTRAP_SERVERS=${CONNECT_BOOTSTRAP_SERVERS}- CONNECT_REST_PORT=${CONNECT_REST_PORT}- CONNECT_GROUP_ID=${CONNECT_GROUP_ID}- CONNECT_CONFIG_STORAGE_TOPIC=${CONNECT_CONFIG_STORAGE_TOPIC}- CONNECT_OFFSET_STORAGE_TOPIC=${CONNECT_OFFSET_STORAGE_TOPIC}- CONNECT_STATUS_STORAGE_TOPIC=${CONNECT_STATUS_STORAGE_TOPIC}- CONNECT_KEY_CONVERTER=${CONNECT_KEY_CONVERTER}- CONNECT_VALUE_CONVERTER=${CONNECT_VALUE_CONVERTER}- CONNECT_INTERNAL_KEY_CONVERTER=${CONNECT_INTERNAL_KEY_CONVERTER}- CONNECT_INTERNAL_VALUE_CONVERTER=${CONNECT_INTERNAL_VALUE_CONVERTER}- CONNECT_REST_ADVERTISED_HOST_NAME=${CONNECT_REST_ADVERTISED_HOST_NAME}- CONNECT_LOG4J_ROOT_LOGLEVEL=${CONNECT_LOG4J_ROOT_LOGLEVEL}- CONNECT_LOG4J_LOGGERS=${CONNECT_LOG4J_LOGGERS}- CONNECT_PLUGIN_PATH=${CONNECT_PLUGIN_PATH}networks:- kafka_network- default# Kafka Schema Registrykafka_schema_registry:image: confluentinc/cp-schema-registry:latestports:- "8081:8081"environment:- SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS=${SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS}- SCHEMA_REGISTRY_HOST_NAME=${SCHEMA_REGISTRY_HOST_NAME}- SCHEMA_REGISTRY_LISTENERS=${SCHEMA_REGISTRY_LISTENERS}networks:- kafka_network- default# Kafka User Interfacekafka_ui:container_name: kafka-ui-1image: provectuslabs/kafka-ui:latestports:- 8888:8080depends_on:- kafka_broker_1- kafka_broker_2- kafka_broker_3- kafka_schema_registry- kafka_connectenvironment:- KAFKA_CLUSTERS_0_NAME=${KAFKA_CLUSTERS_0_NAME}- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=${KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS}- KAFKA_CLUSTERS_0_SCHEMAREGISTRY=${KAFKA_CLUSTERS_0_SCHEMAREGISTRY}- KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME=${KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME}- KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS=${KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS}- DYNAMIC_CONFIG_ENABLED=${DYNAMIC_CONFIG_ENABLED}networks:- kafka_network- default# Apache Spark Master Nodespark_master:image: bitnami/spark:3container_name: spark_masterports:- 8085:8080environment:- SPARK_UI_PORT=${SPARK_UI_PORT}- SPARK_MODE=${SPARK_MODE}- SPARK_RPC_AUTHENTICATION_ENABLED=${SPARK_RPC_AUTHENTICATION_ENABLED}- SPARK_RPC_ENCRYPTION_ENABLED=${SPARK_RPC_ENCRYPTION_ENABLED}volumes:- ./:/home- spark_data:/opt/bitnami/spark/datanetworks:- default- kafka_network#volumes for datavolumes:spark_data:#network for Kafkanetworks:kafka_network:driver: bridgedefault:external:name: docker_streaming
1)版本
使用 Docker Compose 文件格式版本“3.7”,确保与服务兼容。
项目包含多项服务:
Airflow:
数据库 ( airflow_db):使用 PostgreSQL 1。
Web 服务器 ( airflow_webserver):启动数据库并设置管理员用户。
Kafka:
Zookeeper ( kafka_zookeeper):管理 broker 元数据。
Brokers:三个实例(kafka_broker_1、2 和 3)。
基本配置 ( kafka_base):Broker的常见设置。
Kafka Connect(kafka_connect):促进流处理。
架构注册表 ( kafka_schema_registry):管理 Kafka 架构。
用户界面 ( kafka_ui):Kafka 的可视化界面。
spark:
主节点 ( spark_master):Apache Spark 的中央控制节点。
利用持久卷spark_data来确保 Spark 的数据一致性。
服务有两个网络:
Kafka Network ( kafka_network):专用于 Kafka。
默认网络 ( default):外部命名为docker_streaming。
2、kafka_stream_dag.py
# Importing required modulesfrom datetime import datetime, timedeltafrom airflow import DAGfrom airflow.operators.python_operator import PythonOperatorfrom kafka_streaming_service import initiate_stream# Configuration for the DAG's start dateDAG_START_DATE = datetime(2018, 12, 21, 12, 12)# Default arguments for the DAGDAG_DEFAULT_ARGS = {'owner': 'airflow','start_date': DAG_START_DATE,'retries': 1,'retry_delay': timedelta(seconds=5)}# Creating the DAG with its configurationwith DAG('name_stream_dag', # Renamed for uniquenessdefault_args=DAG_DEFAULT_ARGS,schedule_interval='0 1 * * *',catchup=False,description='Stream random names to Kafka topic',max_active_runs=1) as dag:# Defining the data streaming task using PythonOperatorkafka_stream_task = PythonOperator(task_id='stream_to_kafka_task',python_callable=initiate_stream,dag=dag)kafka_stream_task
1)进口
2)配置
DAG 开始日期 ( DAG_START_DATE):设置 DAG 开始执行的时间。
默认参数 ( DAG_DEFAULT_ARGS):配置 DAG 的基本参数,例如所有者、开始日期和重试设置。
将创建一个名为 的新 DAG name_stream_dag,配置为每天凌晨 1 点运行。它的设计目的是不运行任何错过的间隔(带有catchup=False),并且一次只允许一次活动运行。
单个任务 kafka_stream_task 是使用 PythonOperator 定义的。此任务调用该initiate_stream函数,在 DAG 运行时有效地将数据流式传输到 Kafka。
3、kafka_streaming_service.py
# Importing necessary libraries and modulesimport requestsimport jsonimport timeimport hashlibfrom confluent_kafka import Producer# Constants and configurationAPI_ENDPOINT = "https://randomuser.me/api/?results=1"KAFKA_BOOTSTRAP_SERVERS = ['kafka_broker_1:19092','kafka_broker_2:19093','kafka_broker_3:19094']KAFKA_TOPIC = "names_topic"PAUSE_INTERVAL = 10STREAMING_DURATION = 120def retrieve_user_data(url=API_ENDPOINT) -> dict:"""Fetches random user data from the provided API endpoint."""response = requests.get(url)return response.json()["results"][0]def transform_user_data(data: dict) -> dict:"""Formats the fetched user data for Kafka streaming."""return {"name": f"{data['name']['title']}. {data['name']['first']} {data['name']['last']}","gender": data["gender"],"address": f"{data['location']['street']['number']}, {data['location']['street']['name']}","city": data['location']['city'],"nation": data['location']['country'],"zip": encrypt_zip(data['location']['postcode']),"latitude": float(data['location']['coordinates']['latitude']),"longitude": float(data['location']['coordinates']['longitude']),"email": data["email"]}def encrypt_zip(zip_code):"""Hashes the zip code using MD5 and returns its integer representation."""zip_str = str(zip_code)return int(hashlib.md5(zip_str.encode()).hexdigest(), 16)def configure_kafka(servers=KAFKA_BOOTSTRAP_SERVERS):"""Creates and returns a Kafka producer instance."""settings = {'bootstrap.servers': ','.join(servers),'client.id': 'producer_instance'}return Producer(settings)def publish_to_kafka(producer, topic, data):"""Sends data to a Kafka topic."""producer.produce(topic, value=json.dumps(data).encode('utf-8'), callback=delivery_status)producer.flush()def delivery_status(err, msg):"""Reports the delivery status of the message to Kafka."""if err is not None:print('Message delivery failed:', err)else:print('Message delivered to', msg.topic(), '[Partition: {}]'.format(msg.partition()))def initiate_stream():"""Initiates the process to stream user data to Kafka."""kafka_producer = configure_kafka()for _ in range(STREAMING_DURATION PAUSE_INTERVAL):raw_data = retrieve_user_data()kafka_formatted_data = transform_user_data(raw_data)publish_to_kafka(kafka_producer, KAFKA_TOPIC, kafka_formatted_data)time.sleep(PAUSE_INTERVAL)if __name__ == "__main__":initiate_stream()
1)导入和配置
2)用户数据检索
3)数据转换
4)Kafka 配置与发布
configure_kafka 设置 Kafka 生产者。 publish_to_kafka 将转换后的用户数据发送到 Kafka 主题。 delivery_status 提供有关数据是否成功发送到 Kafka 的反馈。
5)主要流功能
6)执行
4、spark_processing.py
import loggingfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import from_json, colfrom pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType# Initialize logginglogging.basicConfig(level=logging.INFO,format='%(asctime)s:%(funcName)s:%(levelname)s:%(message)s')logger = logging.getLogger("spark_structured_streaming")def initialize_spark_session(app_name, access_key, secret_key):"""Initialize the Spark Session with provided configurations.:param app_name: Name of the spark application.:param access_key: Access key for S3.:param secret_key: Secret key for S3.:return: Spark session object or None if there's an error."""try:spark = SparkSession \.builder \.appName(app_name) \.config("spark.hadoop.fs.s3a.access.key", access_key) \.config("spark.hadoop.fs.s3a.secret.key", secret_key) \.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \.getOrCreate()spark.sparkContext.setLogLevel("ERROR")logger.info('Spark session initialized successfully')return sparkexcept Exception as e:logger.error(f"Spark session initialization failed. Error: {e}")return Nonedef get_streaming_dataframe(spark, brokers, topic):"""Get a streaming dataframe from Kafka.:param spark: Initialized Spark session.:param brokers: Comma-separated list of Kafka brokers.:param topic: Kafka topic to subscribe to.:return: Dataframe object or None if there's an error."""try:df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", brokers) \.option("subscribe", topic) \.option("delimiter", ",") \.option("startingOffsets", "earliest") \.load()logger.info("Streaming dataframe fetched successfully")return dfexcept Exception as e:logger.warning(f"Failed to fetch streaming dataframe. Error: {e}")return Nonedef transform_streaming_data(df):"""Transform the initial dataframe to get the final structure.:param df: Initial dataframe with raw data.:return: Transformed dataframe."""schema = StructType([StructField("full_name", StringType(), False),StructField("gender", StringType(), False),StructField("location", StringType(), False),StructField("city", StringType(), False),StructField("country", StringType(), False),StructField("postcode", IntegerType(), False),StructField("latitude", FloatType(), False),StructField("longitude", FloatType(), False),StructField("email", StringType(), False)])transformed_df = df.selectExpr("CAST(value AS STRING)") \.select(from_json(col("value"), schema).alias("data")) \.select("data.*")return transformed_dfdef initiate_streaming_to_bucket(df, path, checkpoint_location):"""Start streaming the transformed data to the specified S3 bucket in parquet format.:param df: Transformed dataframe.:param path: S3 bucket path.:param checkpoint_location: Checkpoint location for streaming.:return: None"""logger.info("Initiating streaming process...")stream_query = (df.writeStream.format("parquet").outputMode("append").option("path", path).option("checkpointLocation", checkpoint_location).start())stream_query.awaitTermination()def main():app_name = "SparkStructuredStreamingToS3"access_key = "ENTER_YOUR_ACCESS_KEY"secret_key = "ENTER_YOUR_SECRET_KEY"brokers = "kafka_broker_1:19092,kafka_broker_2:19093,kafka_broker_3:19094"topic = "names_topic"path = "BUCKET_PATH"checkpoint_location = "CHECKPOINT_LOCATION"spark = initialize_spark_session(app_name, access_key, secret_key)if spark:df = get_streaming_dataframe(spark, brokers, topic)if df:transformed_df = transform_streaming_data(df)initiate_streaming_to_bucket(transformed_df, path, checkpoint_location)# Execute the main function if this script is run as the main moduleif __name__ == '__main__':main()
1. 导入和日志初始化
导入必要的库,并创建日志记录设置以更好地调试和监控。
initialize_spark_session:此函数使用从 S3 访问数据所需的配置来设置 Spark 会话。
get_streaming_dataframe:从 Kafka 获取具有指定代理和主题详细信息的流数据帧。
transform_streaming_data:将原始 Kafka 数据转换为所需的结构化格式。
initiate_streaming_to_bucket:此函数将转换后的数据以 parquet 格式流式传输到 S3 存储桶。它使用检查点机制来确保流式传输期间数据的完整性。
该 main 函数协调整个过程:初始化 Spark 会话、从 Kafka 获取数据、转换数据并将其流式传输到 S3。
如果脚本是正在运行的主模块,它将执行该 main 函数,启动整个流处理过程。
构建数据管道:逐步
1. 设置Kafka集群
使用以下命令启动 Kafka 集群:
docker network create docker_streamingdocker-compose -f docker-compose.yml up -d
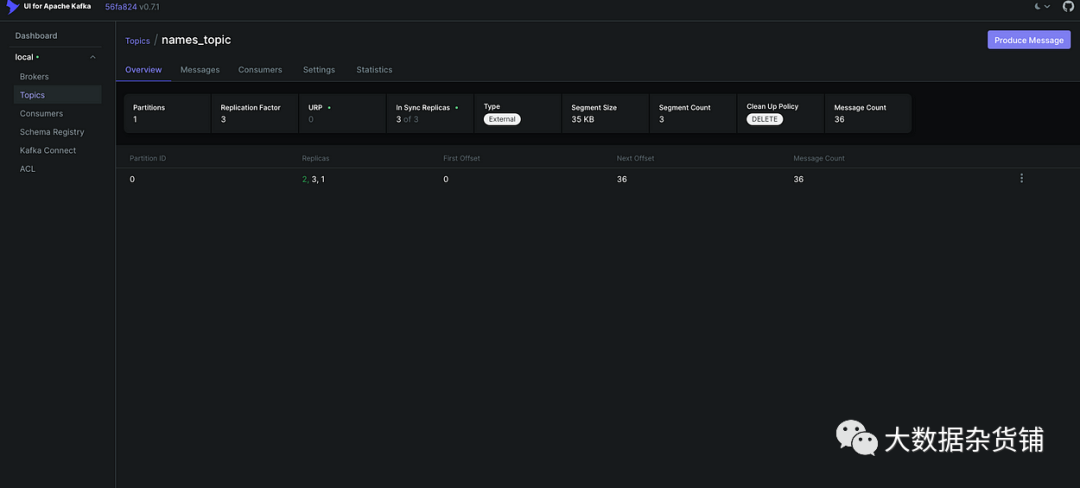
2. 为 Kafka 创建主题(http://localhost:8888/)
通过http://localhost:8888/访问 Kafka UI 。
观察活动集群。
导航至“主题”。
创建一个名为“names_topic”的新主题。
将复制因子设置为 3。
3. 配置 Airflow 用户
docker-compose run airflow_webserver airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
4. 访问 Airflow Bash 并安装依赖项
我们应该将脚本移动kafka_stream_dag.py到文件夹下以便能够运行 DAG 使用提供的脚本访问 Airflow bash 并安装所需的软件包:kafka_streaming_service.py dags
./airflow.sh bashpip install -r ./requirements.txt
5. 验证 DAG
airflow dags list
6. 启动 Airflow 调度程序
airflow scheduler
7. 验证数据是否上传到 Kafka 集群
访问 Kafka UI:http://localhost:8888/并验证该主题的数据是否已上传
8. 传输 Spark 脚本
将 Spark 脚本复制到 Docker 容器中:
docker cp spark_processing.py spark_master:/opt/bitnami/spark/
9.启动 Spark Master 并下载 JAR
docker exec -it spark_master bin/bashcd jarscurl -O <https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.8.1/kafka-clients-2.8.1.jar>curl -O <https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.13/3.3.0/spark-sql-kafka-0-10_2.13-3.3.0.jar>curl -O <https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar>curl -O <https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-s3/1.11.375/aws-java-sdk-s3-1.11.375.jar>curl -O <https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.8.0/commons-pool2-2.8.0.jar>cd ..spark-submit \\--master local[2] \\--jars /opt/bitnami/spark/jars/kafka-clients-2.8.1.jar,\\/opt/bitnami/spark/jars/spark-sql-kafka-0-10_2.13-3.3.0.jar,\\/opt/bitnami/spark/jars/hadoop-aws-3.2.0.jar,\\/opt/bitnami/spark/jars/aws-java-sdk-s3-1.11.375.jar,\\/opt/bitnami/spark/jars/commons-pool2-2.8.0.jar \\spark_processing.py
执行这些步骤后,检查您的 S3 存储桶以确保数据已上传
挑战和故障排除
配置挑战:确保docker-compose.yaml 正确设置环境变量和配置(如文件中的)可能很棘手。不正确的设置可能会阻止服务启动或通信。 服务依赖性:像 Kafka 或 Airflow 这样的服务依赖于其他服务(例如,Kafka 的 Zookeeper)。确保服务初始化的正确顺序至关重要。 Airflow DAG 错误:DAG 文件 ( kafka_stream_dag.py) 中的语法或逻辑错误可能会阻止 Airflow 正确识别或执行 DAG。 数据转换问题:Python 脚本中的数据转换逻辑可能并不总是产生预期的结果,特别是在处理来自随机名称 API 的各种数据输入时。 Spark 依赖项:确保所有必需的 JAR 可用且兼容对于 Spark 的流作业至关重要。JAR 丢失或不兼容可能会导致作业失败。 Kafka 主题管理:使用正确的配置(如复制因子)创建主题对于数据持久性和容错能力至关重要。 网络挑战:在 docker-compose.yaml 中设置的 Docker 网络必须正确地促进服务之间的通信,特别是对于 Kafka 代理和 Zookeeper。 S3 存储桶权限:写入 S3 时确保正确的权限至关重要。权限配置错误可能会阻止 Spark 将数据保存到存储桶。 弃用警告:提供的日志显示弃用警告,表明所使用的某些方法或配置在未来版本中可能会过时。
结论:
在整个旅程中,我们深入研究了现实世界数据工程的复杂性,从原始的未经处理的数据发展到可操作的见解。从收集随机用户数据开始,我们利用 Kafka、Spark 和 Airflow 的功能来管理、处理和自动化这些数据的流式传输。Docker 简化了部署,确保了环境的一致性,而 S3 和 Python 等其他工具发挥了关键作用。
原文作者:Simardeep Singh
