




什么是 Apache Doris ?
Apache Doris 同时支持批量导入和流式写入。可以与 Apache Spark、Apache Hive、Apache Flink、Airbyte、DBT 和 Fivetran 很好地集成。还可以连接到 Apache Hive、Apache Hudi、Apache Iceberg、Delta Lake 和 Apache Paimon 等数据湖。

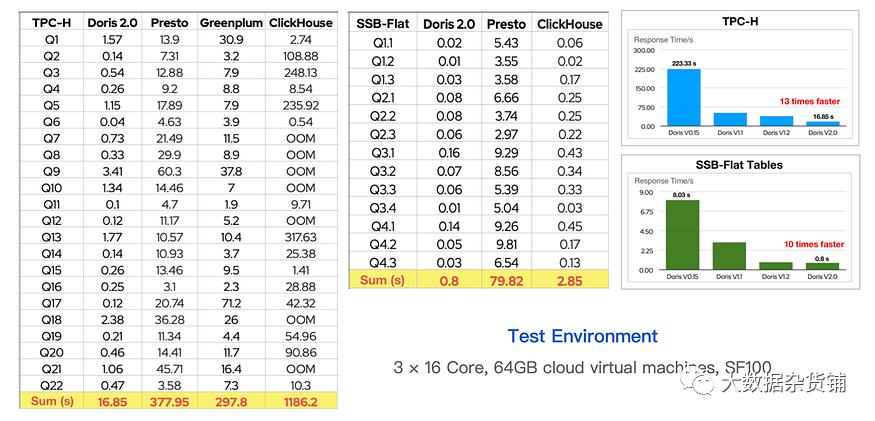
表现
作为实时 OLAP引擎,Apache Doris 在查询速度上具有竞争优势。根据TPC-H和SSB-Flat基准测试结果,Doris可以提供比Presto、Greenplum和ClickHouse更快的性能。
至于其自我进化,过去两年无论是复杂查询还是平表分析,速度都提高了10倍以上。
架构设计
Apache Doris 如此快的速度背后是有助于其性能的架构设计、特性和机制。
首先,Apache Doris 有一个基于成本的优化器(CBO),可以为复杂的大查询找出最有效的执行计划。具有完全矢量化的执行引擎,可以减少虚拟函数调用和缓存未命中的问题。基于MPP(大规模并行处理),可以充分发挥用户的机器和内核。在 Doris 中,查询执行是数据驱动的,意味着查询是否被执行取决于其相关数据是否准备好,这可以更有效地利用 CPU。
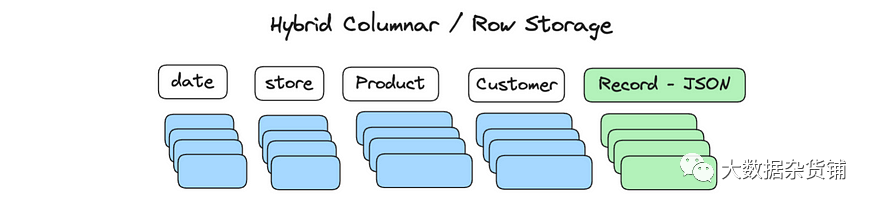
面向列的数据库的快速点查询
Apache Doris 是一个面向列的数据库,因此它可以使数据压缩和数据分片变得更容易更快。但这可能不适合诸如面向客户的服务之类的情况。在这些情况下,数据平台必须同时处理大量用户的请求(这些请求称为“高并发点查询”),而拥有列式存储引擎将放大每秒的 I/O 操作,尤其是当数据排列在平面表中时。
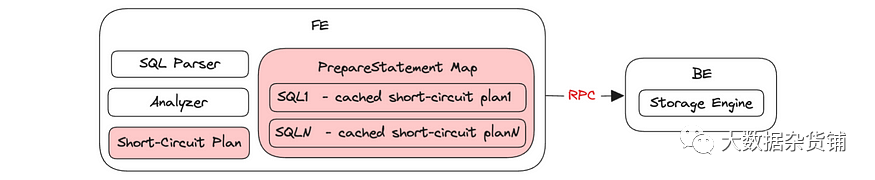
数据摄取
Apache Doris 提供了一系列数据摄取方法。
实时流写入:
Stream Load:可以应用此方法通过 HTTP 写入本地文件或数据流。具有线性可扩展性,在某些用例中可以达到每秒 1000 万条记录的吞吐量。 Flink-Doris-Connector:通过内置的 Flink CDC,该连接器将 OLTP 数据库中的数据提取到 Doris。至此,我们已经实现了MySQL、Oracle的数据自动同步到Doris。 例程加载:这是从 Kafka 消息队列订阅数据。 Insert Into:当您尝试在 Doris 内部进行 ETL 时(例如将数据从一个 Doris 表写入另一个 Doris 表)尤其有用。
Spark Load:通过这种方法,您可以在写入 Doris 之前利用 Spark 资源对来自 HDFS 和对象存储的数据进行预处理。 Broker Load:支持 HDFS 和 S3 协议。
insert into <internal table> select from <external table>:这个简单的语句允许您将 Doris 连接到各种存储系统、数据湖和数据库。
数据更新
对于数据更新,Apache Doris 需要提供的是,它同时支持 Merge on Read 和 Merge on Write,前者用于低频批量更新,后者用于实时写入。使用Merge on Write,当您执行查询时,最新的数据就已经准备好了,因此与Merge on Read相比,它可以将查询速度提高5到10倍。
从实现的角度来看,以下是一些常见的数据更新操作,Doris 都支持:
Upsert:替换或更新整行 部分列更新:仅更新一行中的几列 条件更新:通过组合几个条件过滤掉一些数据,以便替换或删除它 Insert Overwrite:重写表或分区
服务可用性和数据可靠性
从架构上来说,Doris 有两个进程:前端和后端。它们都很容易扩展。前端节点管理集群、元数据并处理用户请求;后端节点执行查询并能够自动数据平衡和自动恢复。支持集群升级和扩展,避免服务中断。

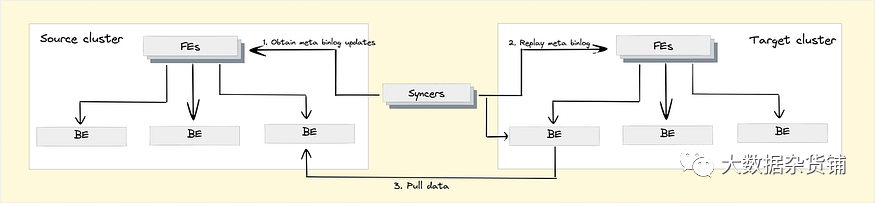
跨集群复制
灾难恢复:用于快速恢复数据服务 读写分离:主集群+从集群;一本用于阅读,一本用于写作 集群隔离升级:对于集群扩展,CCR允许用户预先创建备份集群进行试运行,以便清除可能的不兼容问题和错误。
测试表明 Doris CCR 可以达到几分钟的数据延迟。最好的情况下可以达到硬件环境的速度上限。
多租户管理
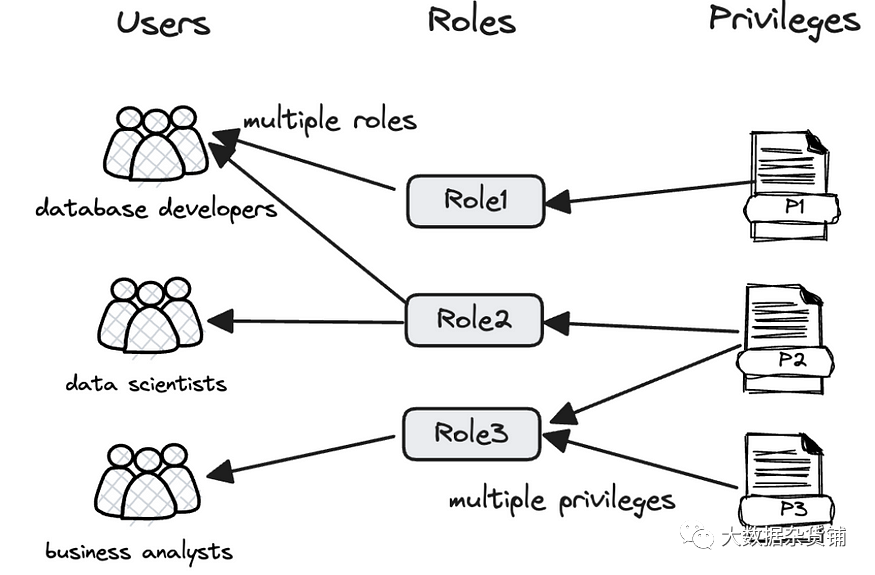
Apache Doris 具有复杂的基于角色的访问控制,它允许在数据库、表、行和列级别进行细粒度的权限控制。
对于资源隔离,Doris 曾经实施了一个硬隔离方案,将后端节点划分为资源组,并将资源组分配给不同的工作负载。这个硬隔离计划简单又整洁。但有时用户需要更充分地利用其计算资源,因为某些资源组处于空闲状态。
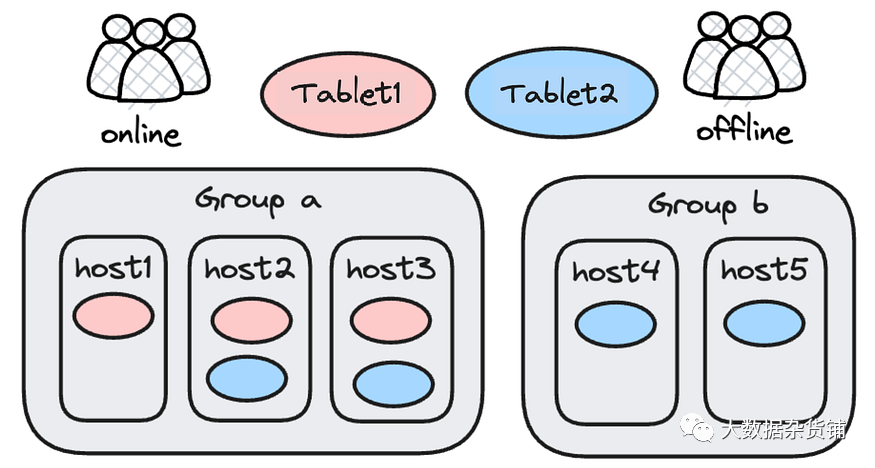
因此,Doris 2.0 引入了工作负载组,而不是资源组。为工作负载组设置了关于其可以使用的资源数量的软限制。当达到该软限制时,同时有一些空闲资源可用。空闲资源将在工作负载组之间共享。用户还可以根据对空闲资源的访问来确定工作负载组的优先级。

便于使用
Apache Doris 提供了许多功能,而且也易于使用。它支持标准SQL,并兼容MySQL协议和市场上大多数BI工具。
我们为提高可用性所做的另一项努力是称为“轻架构更改”的功能。这意味着如果用户需要添加或删除表中的某些列,他们只需要更新前端的元数据,而不必修改所有数据文件。光模式更改可以在几毫秒内完成。它还允许更改索引和列的数据类型。Light Schema Change 与 Flink-Doris-Connector 的结合意味着上游表的毫秒级同步。
半结构化数据分析
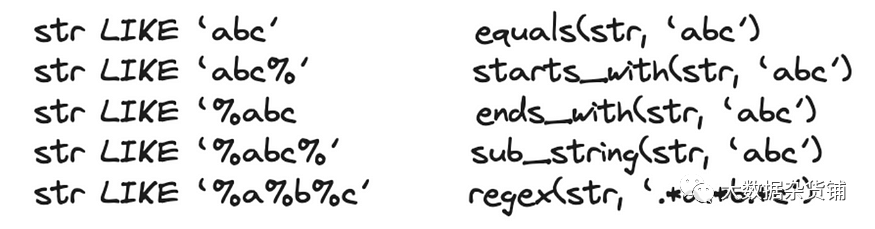
我们还引入了用于文本标记化的倒排索引。它是模糊关键字搜索、全文搜索、等价查询和范围查询的强大工具。
据仓一体
为了让用户构建高性能的数据湖和统一的查询网关,Doris 可以映射、缓存和自动刷新来自外部源的元数据。它支持 Hive Metastore 和几乎所有开放数据 Lakehouse 格式。您可以将其连接到关系数据库、Elasticsearch 和许多其他来源。它允许您在外部表上重用自己的身份验证系统,例如 Kerberos 和 Apache Ranger。
基准测试结果显示,Apache Doris 在 Hive 表的查询中比 Trino 快 3~5 倍。它是以下几个特征的共同结果:
高效的查询引擎 热数据缓存机制
计算节点 Doris 视图
计算节点是 2.0 版本中新引入的数据湖解决方案。与普通后端节点不同,计算节点是无状态的,不存储任何数据。它们也不参与集群扩展期间的数据平衡。这样,他们就可以在计算高峰期灵活、轻松地加入集群。
另外,Doris还允许将外部表的计算结果写入Doris中形成视图。这与物化视图的思路类似:用空间换取速度。对外部表执行查询后,可以将结果放入Doris内部。当后续有类似的查询时,系统可以直接从 Doris 读取先前查询的结果,从而加快速度。
分层存储
分层存储的主要目的是省钱。分层存储是指将热数据和冷数据分离到不同的存储中,热数据是经常访问的数据,冷数据是不经常访问的数据。它允许用户将热数据放入快速但昂贵的磁盘(例如SSD和HDD)中,将冷数据放入对象存储中。
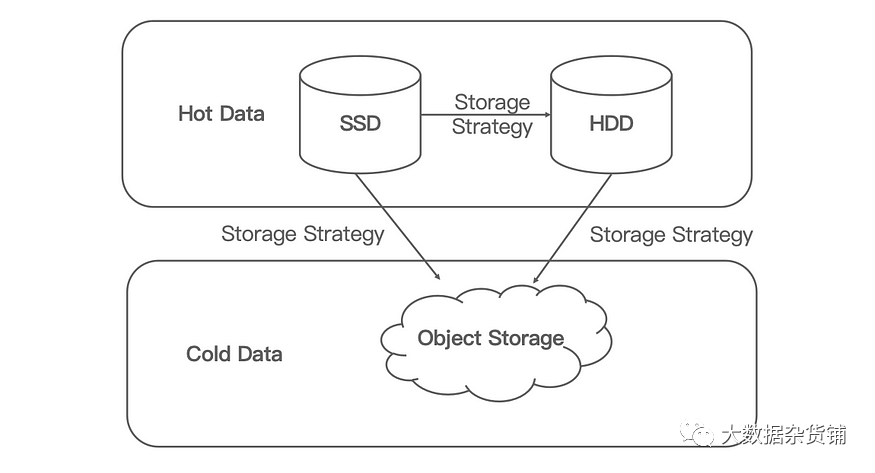
粗略来说,对于80%冷数据组成的数据资产,分层存储可以降低您70%的存储成本。
Apache Doris 社区
这是对开源实时数据仓库 Apache Doris 的概述。它正在按照敏捷的发布计划积极发展,社区欢迎任何问题、想法和反馈。
原文作者:Apache Doris
